本文属于【Azure 架构师学习笔记】系列。
本文属于【Azure Data Factory】系列。
接上文【Azure 架构师学习笔记】-Azure Data Factory (4)-触发器详解-事件触发器
前言
Azure Data Factory, ADF 是微软Azure 的ETL 首选服务之一, 是Azure data platform中的一种PaaS, 托管的, Serverless的服务。通过把ETL功能封装在各种类型的Pipeline中并按需执行,从而实现数据的传输和转换。
我们常说的ADF,准确的叫法是ADF instance, 常规用法是搭配装有Self-hosted integration runtime(SHIR) 服务的VM,进行源和目的地之间的数据传输, 但是也支持不用SHIR 的情况,就是使用自带的Azure IR, 由于ADF 本身并不能完全实现所有功能,或者没有必要重复造轮子,所以很多时候ADF 是通过某些特定的activity去调用外部服务,完成一些需要更加专业的服务才能实现的功能。比如借助Databricks activity调用Azure Databricks来实现数据科学方面的需求。
除此之外,上面提到的SHIR 有自身的限制,它主要支持ADF 里面的copy 活动,简单来说就是实现ETL中的E 和L 部分,如果需要实现T, 那么就要用到ADF 里面其他的activity,这些activity大部分都不支持SHIR, 需要使用Azure Integration Runtime Azure IR/AIR) 来实现。
简而言之:
SHIR-> Copy data活动
Azure IR-> Data Flow 活动。
如下图所示:
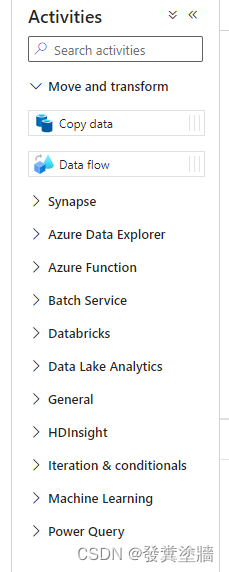
Data Flow
Data Flow 活动和Copy Data活动在使用方面大同小异,只是Data Flow能支持更多的功能,它们其中一个明显的区别就在于Integration Runtime上。前面提到SHIR 和AIR,SHIR通过把服务安装在Windows VM上从而搭建一个对外操作的桥梁。而Azure IR(AIR)则借助Azure自己的IR 来操作,这个AIR 有个缺点就是只能操作Azure内的资源,如果要访问外部,则需要使用SHIR 或者第三种不常用的IR:SSIS IR。
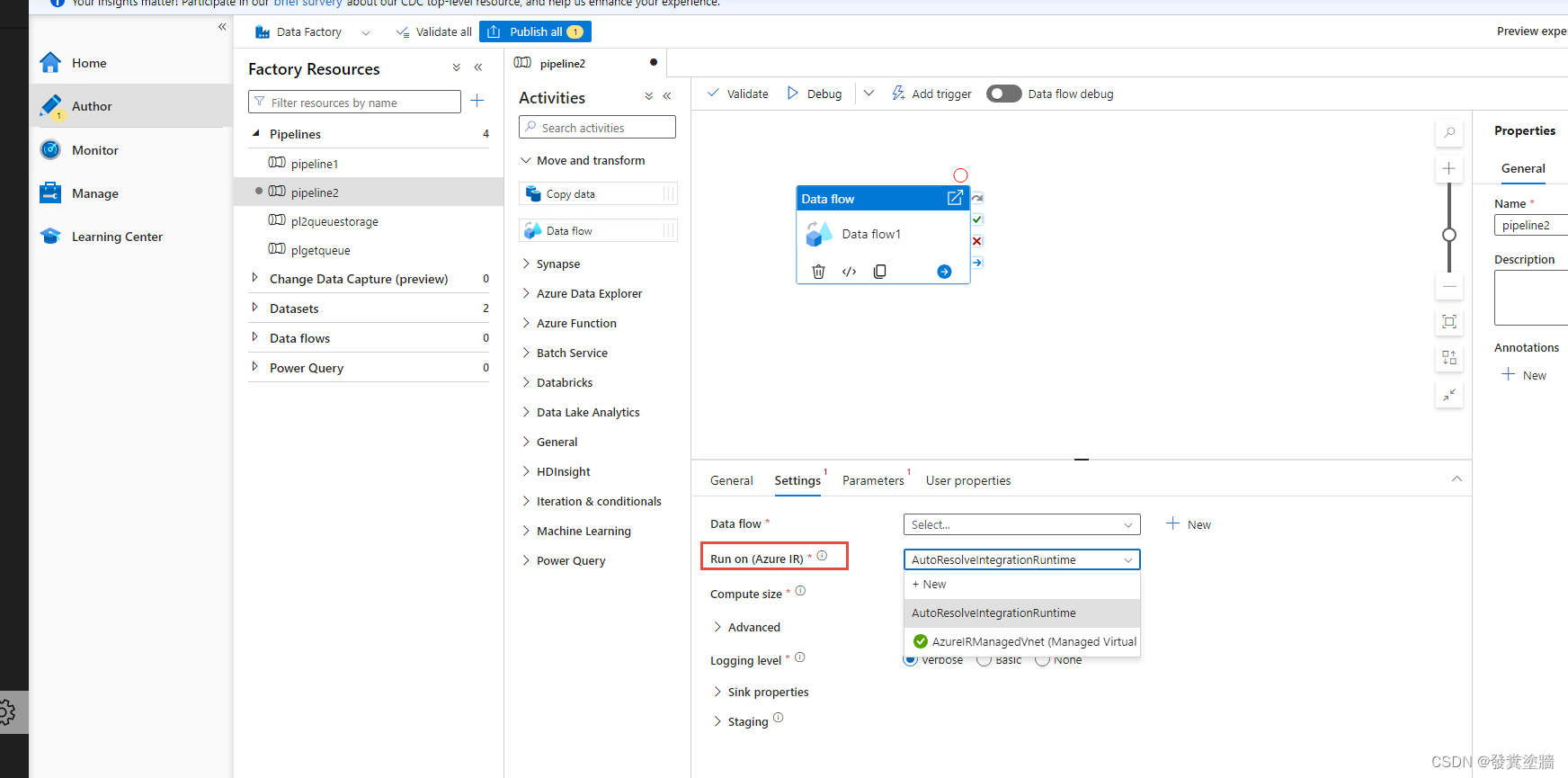
如下图所示,当使用Data Flow时,可以选的都是AIR, ADF 有个默认的AutoResolveIntgrationRuntime的AIR, 也可以自己创建,如下面的Managed Virtual Network。 然后选择Compute Size,也就是集群大小。顺带说一句,AIR 底层就是使用Azure Databricks的集群来进行运算。
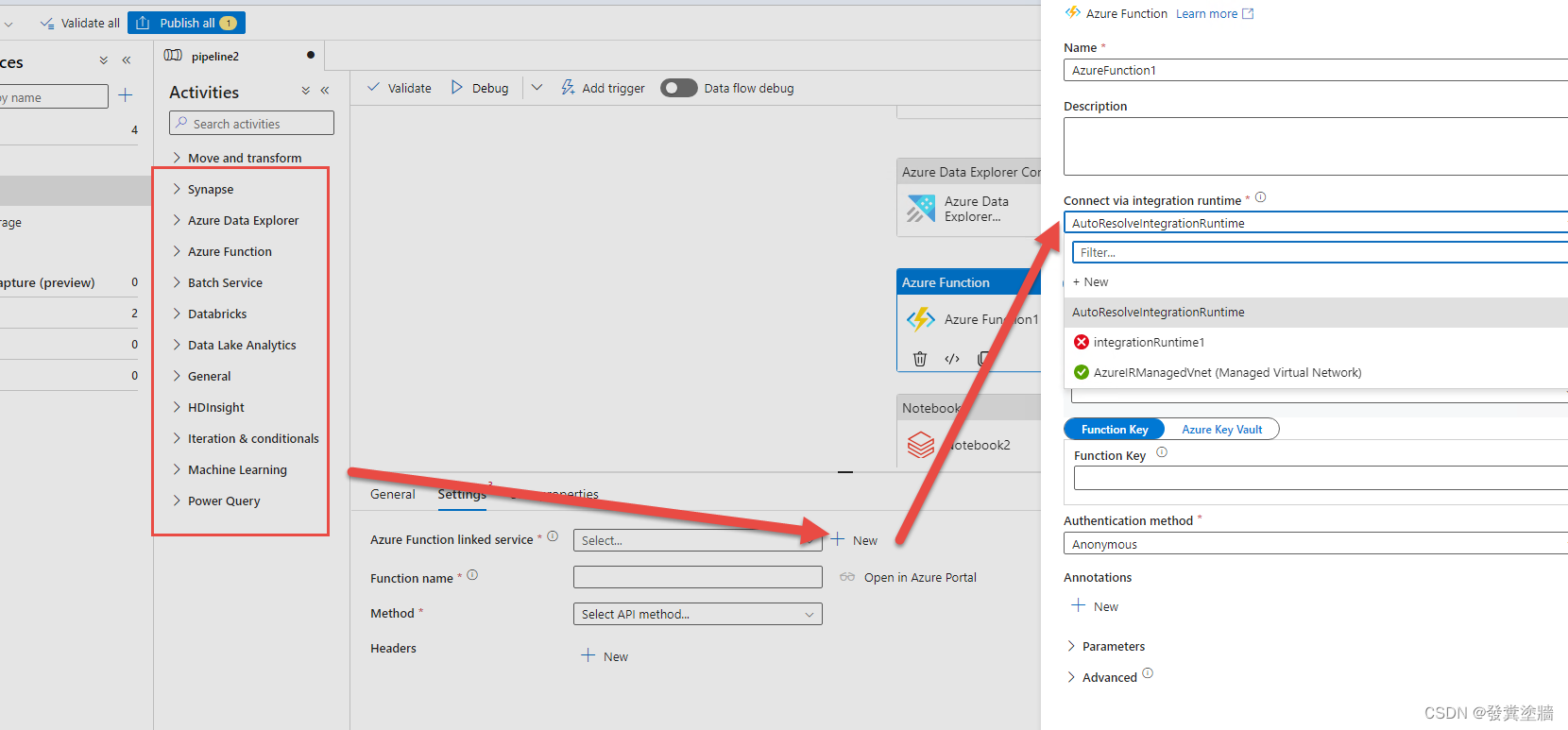
当然当你浏览下图中其他活动时,可以从箭头放下去查看对应的可选IR, 每个活动都有一些不一样的配置。
Data Flow注意事项
费用
由于Data Flow使用AIR ,也就是Databricks 集群,一旦使用了集群,费用就是一个关键点。集群如果选择不对或者没有在闲时及时关闭,那么扣费相当可观。本人就见过几百美金一夜用光的情况。
由于Data Flow集群用的是ADB的集群,所以跟Databricks的配置类似,不需要用的时候及时停掉,这样可以很大程度降低费用。
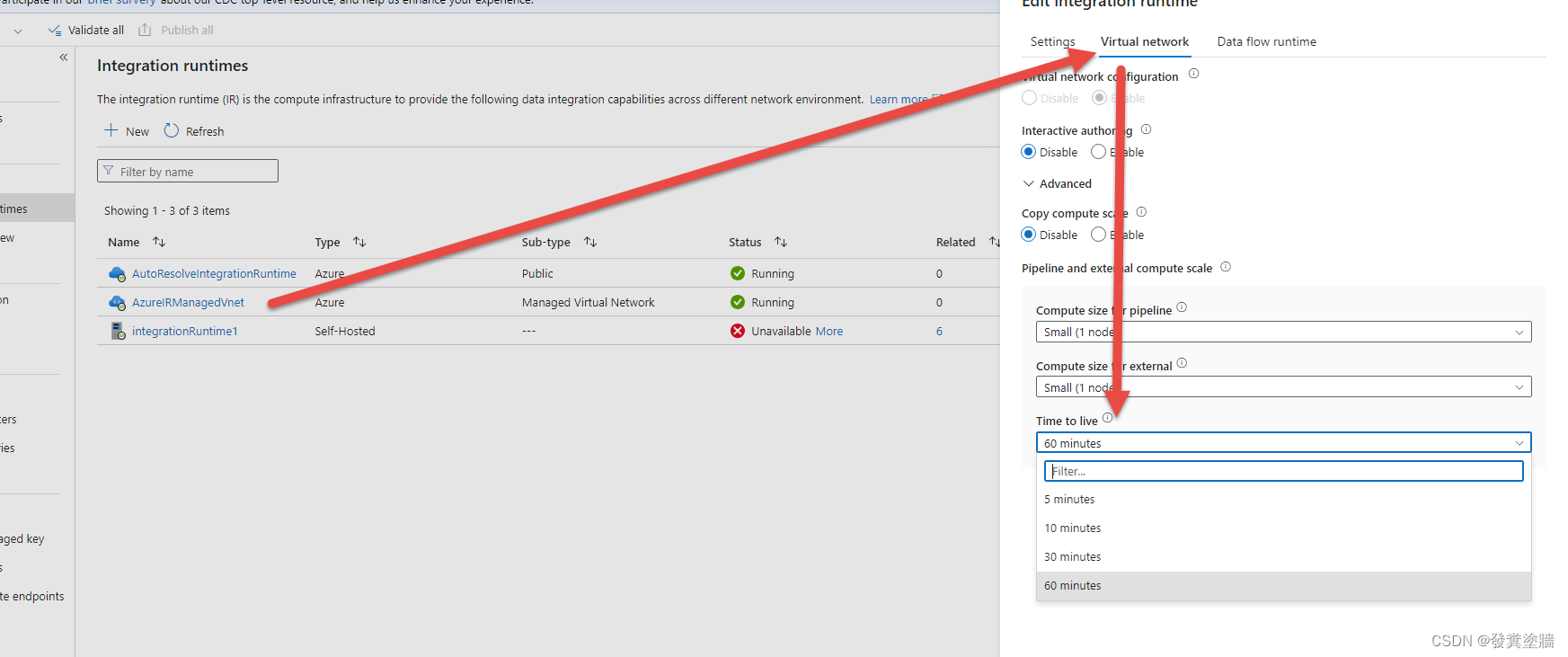
安全性
由于Data Flow使用AIR, 而AIR 默认通过公网访问Azure内的资源,所以从企业级应用而言,并不安全,这就要对这个链接进行改造,可以参考我的另外一篇文章:【Azure 架构师学习笔记】-Azure Data Factory (5)-Managed VNet