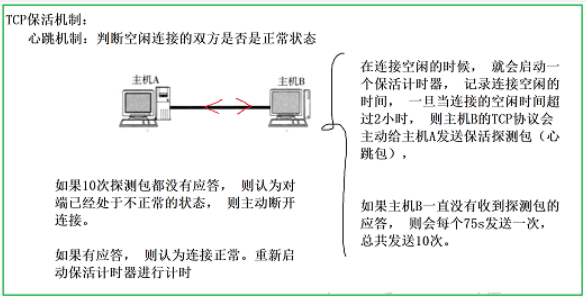
笔记整理:郑国鹏,天津大学硕士
链接: https://www.sciencedirect.com/science/article/pii/S0306437921000223
动机
特征集(CS)根据与其主题节点相关的属性集来组织RDF三元组。它可以捕捉到RDF数据的隐含模式。虽然大多数基于CS的方法在空间和查询性能上有明显的改善,但在回答复杂查询工作负载时, CS的数量会变得非常大,最终影响系统性能。本文根据CS的层次结构进行合并,解决上述的CS数量过多的问题。
亮点
本文的方法采用网格来捕捉CS之间的层次关系,识别密集的CS并将密集的CS与它们的祖先合并。本文在关系主干之上实现了合并的算法,每个合并的CS都存储在一个关系表中。
本文的亮点主要包括:
•将CS合并问题,归纳为一个网格缩小问题。并利用CS的层次结构,提出了一种新型的CS合并算法。极大程度的减少的CS的数量。减少连接操作•实现了raxonDB系统,在存储和查询处理都运用了本文提出的CS合并算法。
概念及模型
•概念:CS节点
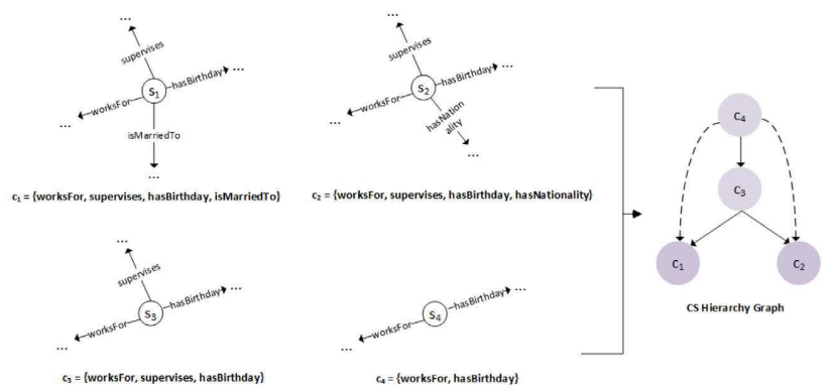
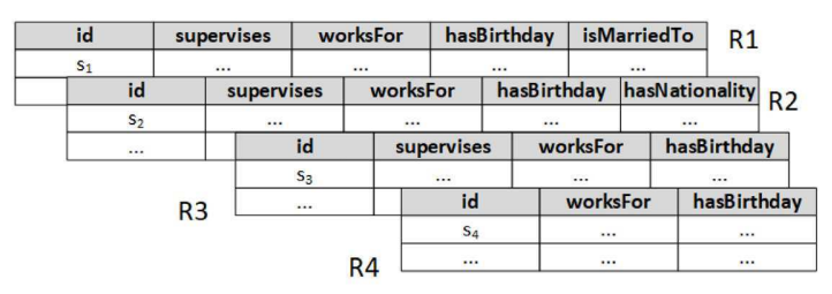
节点S表示主语,一个CS由主语及其谓词构成。
节点C表示一个CS划分。
本文的核心目的在于,利用CS之间的层级关系,对CS节点进行合并。主要有两个步骤:寻找稠密节点(合并的终点),寻找合适的合并路径。
•寻找稠密节点
稠密节点,即终点节点。其他CS节点需要通过层级关系最终合并到稠密节点上。因此,稠密节点的选择至关重要。本文希望合并后表的空值越少越好,因此以空值为标准设计了代价模型。公式如下图所示:
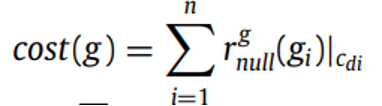
在选定完稠密节点之后,CS节点图以稠密节点为终点,划分成各子图。如下图所示:深紫色为稠密节点。
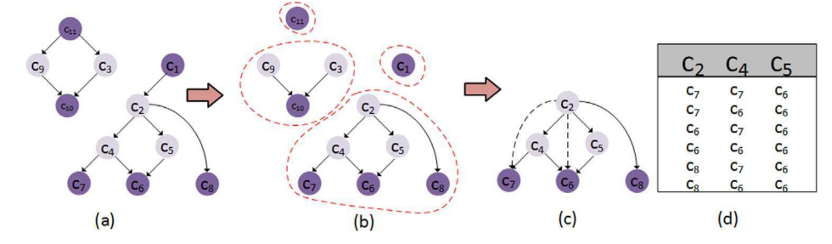
子图划分算法如下图所示:

•节点合并
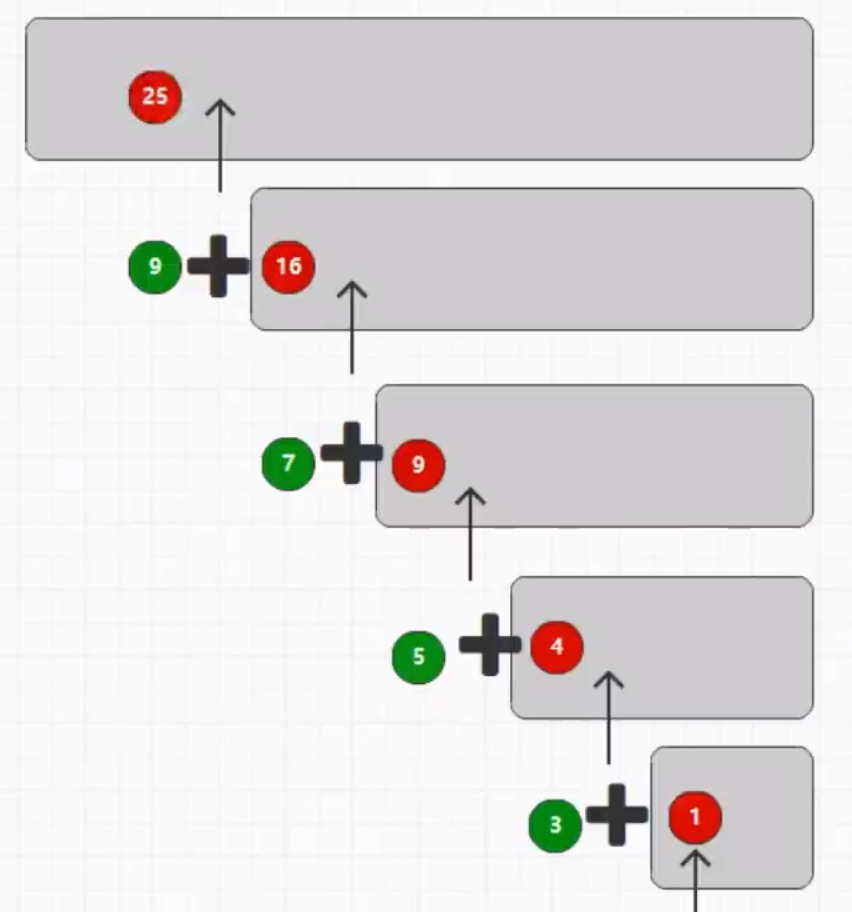
在划分出子图之后,则该考虑如何将CS节点合并到稠密节点。本文先采用穷举的方式进行合并,但是时间复杂度过高。继而采用贪心的思想,降低时间复杂度,对节点进行合并。合并示意图与算法如下所示:


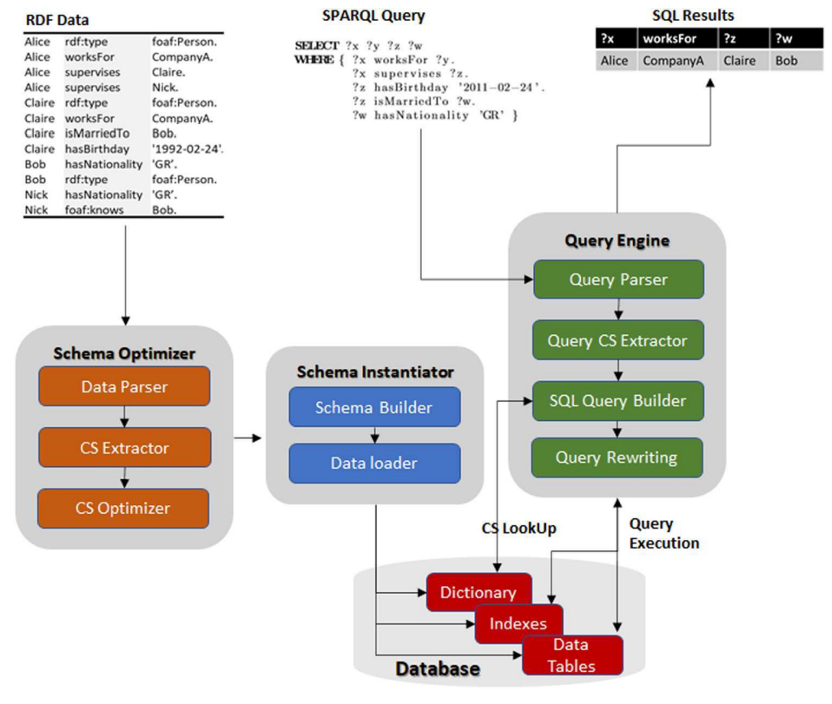
另外,本文将CS合并算法应用的存储和查询优化中,实现的raxonDB系统,系统架构如下图所示:
理论分析
实验
作者在LUBM2000、Geonames、Reactome三个数据集上,与virtuoso、rdf3x、triplebit、emergent、axonDB等单机SPARQL查询系统进行对比。性能均明显优于现有的系统。
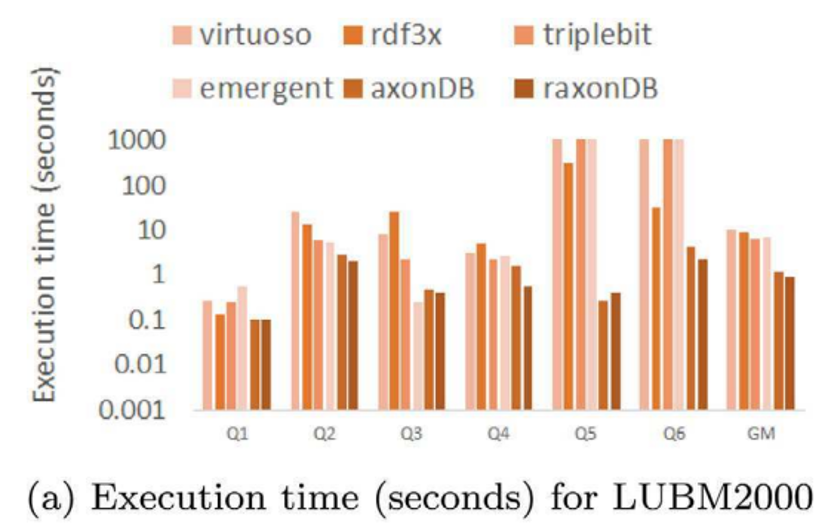
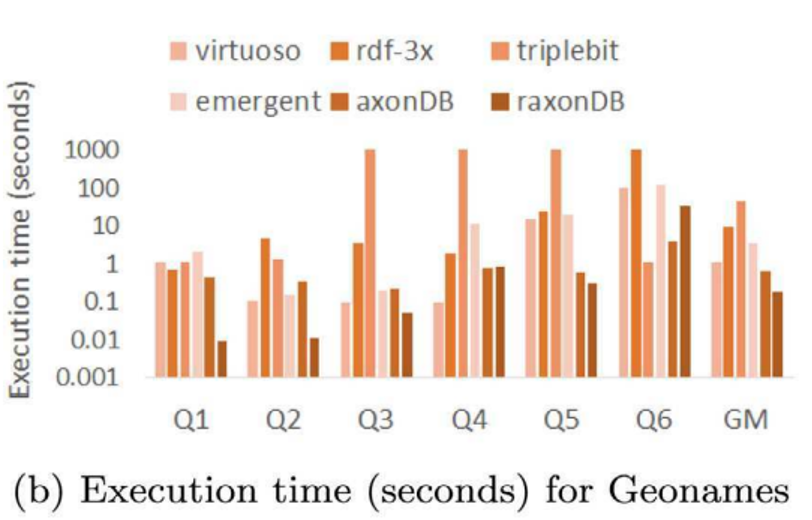
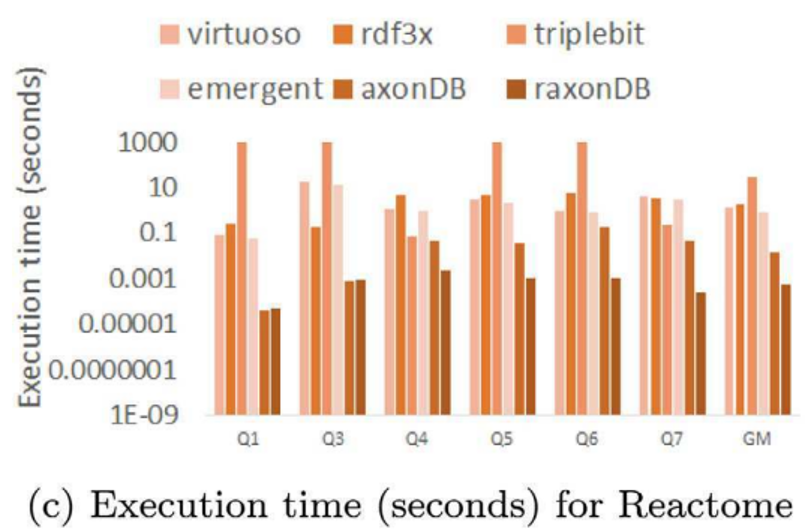
总结
在本文通过考虑RDF三元组中的隐含模式,解决了将异质RDF数据集自动映射到关系模式的问题。提出了一种提取特征集的方法,即描述数据中不同类别的RDF实例的属性集,并利用不同CS之间的层次关系,以便将它们合并并映射到关系表中。本文提供了两种算法,一种是穷举算法,在指数时间内选择CS的祖先子图进行合并;另一种是贪婪算法,通过使用启发式算法将性能提高到多项式时间。