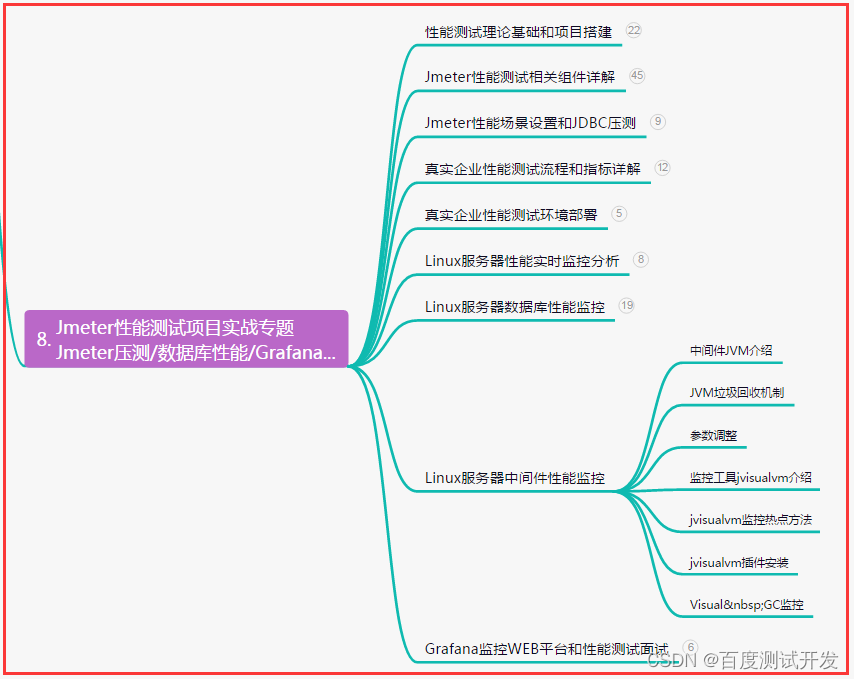
模型评估指标【准度、精度、召回率、F1-score及ROC曲线】总结
参考于李沐的机器学习课程。
通常要使用多个模型综合评价一个模型的好坏。
Accuracy
- 预测正确的个数 / 样本总个数
sum(y_pred == y_label)/y_label.size()
Precision
- 正确地预测为类别 i 的个数 / 预测为 i 的总样本数
- 预测为 i 且就是 i 在所有预测为 i 的样本中占的比率
- 在预测为类别 i 的样本内部进行观察
sum((y_pred == 1)&(y_label==1))/sum(y_pred == 1)
Recall
- 正确的预测为 i 的个数 / 类别为 i 的总样本个数
- 在类别为 i 的样本内部进行观察
sum((y_pred)==1 & (y_label == 1))/sum(y_label == 1)
F1-score
- 平衡Precision和Recall(使用调和平均)
2*P*R/(P+R)
AUC&ROC
- AUC是ROC曲线下方的面积,用于测量模型能把类别分开的能力

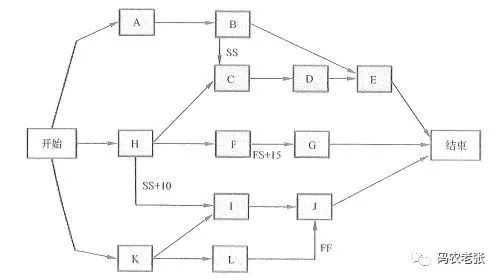
如图,Y轴表示正确的预测为正的个数 / 正样本的总个数,X轴表示错误的预测为正的个数 / 负样本的总个数。
我们取一个变量θ,如果预测值大于θ,就将其预测为正。
每个θ值,都会对应一个(x,y)坐标点,
当θ的值从0变化到1时,就是ROC曲线。
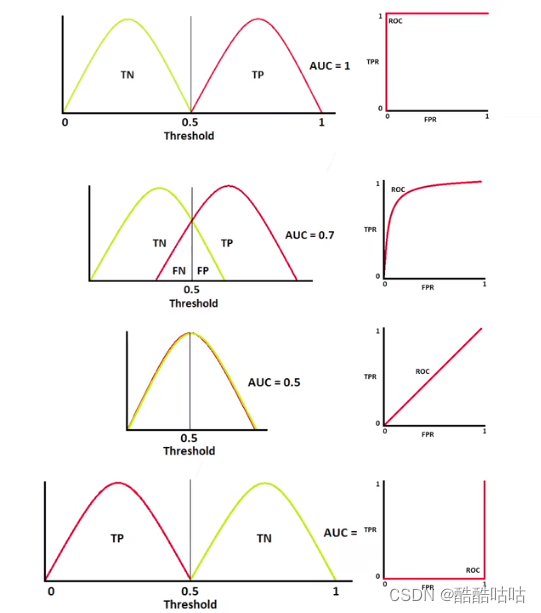
如图T(True)、F(False)、P(Positive)、N(Negative),true和positive都表示正样本,单词不同只是为了区分真实值和预测值。
TP(真实值为正 预测值为正)
TN(真实值为正 预测值为负)
FP(真实值为负 预测值为正)
FN(真实值为负 预测值为负)
第一行,表示存在一根线,能够完美的将两个类别区分开来。
第二行,表示有一块数据是无法很好的进行区分的。
第三行,表示所得的模型没有任何能力能区分正例和负例。
第四行,表示正例和负例完全搞反了。