这几天在和第三方交互的时候,对方返回的数据是base64格式的数据,所以这两天又彻底捋了下Base64的来龙去脉。之前看过一篇文章说的非常好(再找到给加上链接),我在这不详细说明了,只说转换过程。
还是使用中文“爸”来举例说明,在之前的文章“一文彻底搞懂计算机中文编码”和“一文读懂UTF-8的编码规则”已了解到“爸”使用GBK编码后数据为“B0D6(10110000 11010110)”,使用utf-8编码数据为“E 7 8 8 B 8(1110 0111 1000 1000 1011 1000)”。
前边我们已经有了测试数据,那么Base64编码规则如下:
就是包括小写字母a-z、大写字母A-Z、数字0-9、符号"+“、”/"一共64个字符的字符集,(任何符号都可以转换成这个字符集中的字符,这个转换过程就叫做base64编码。

Base64 编码的字符索引表如下所示:
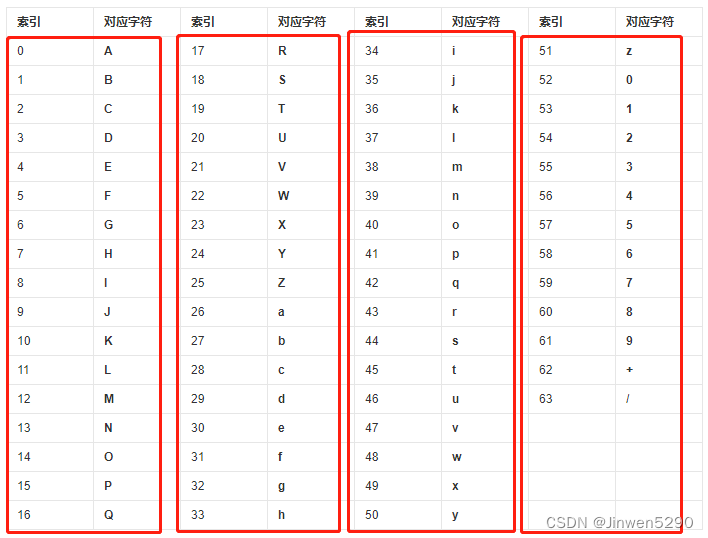
B0D6(10110000 11010110)转换过程如下:
| 步骤 | 数据 | 数据 | 数据 | 数据 |
|---|---|---|---|---|
| 先按每6位分组: | 101100 | 001101 | 011000 | |
| 高位补00: | 00101100 | 00001101 | 00011000 | |
| 转换成十进制: | 44 | 13 | 24 | |
| 索引映射字符: | s | N | Y | |
| 编码后数据: | s | N | Y | = |
像上边不够24位,只有16位,name最后一个四位低位同样补"00",剩下的一个字节用“=”补齐。
E 7 8 8 B 8(1110 0111 1000 1000 1011 1000)转换过程如下:
| 步骤 | 数据 | 数据 | 数据 | 数据 |
|---|---|---|---|---|
| 先按每6位分组: | 111001 | 111000 | 100010 | 111000 |
| 高位补00: | 00111001 | 00111000 | 00100010 | 00111000 |
| 转换成十进制: | 57 | 56 | 34 | 56 |
| 索引映射字符: | 5 | 4 | i | 4 |
| 编码后数据: | 5 | 4 | i | 4 |
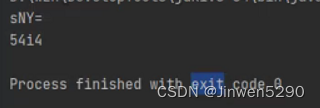
验证程序:
String str = "爸";
System.out.println(Base64.encode(str.getBytes("gb2312")));
System.out.println(Base64.encode(str.getBytes("utf-8")));
运行结果如下:



![[python 刷题] 76 Minimum Window Substring](https://img-blog.csdnimg.cn/4c15e497209d4b12af5e6f1a83e82931.jpeg#pic_center)


![2023年中国金属涂胶板行业供需分析:销量同比增长2.8%[图]](https://img-blog.csdnimg.cn/img_convert/6e90f968cd964613e71aebb8035ae5d4.png)