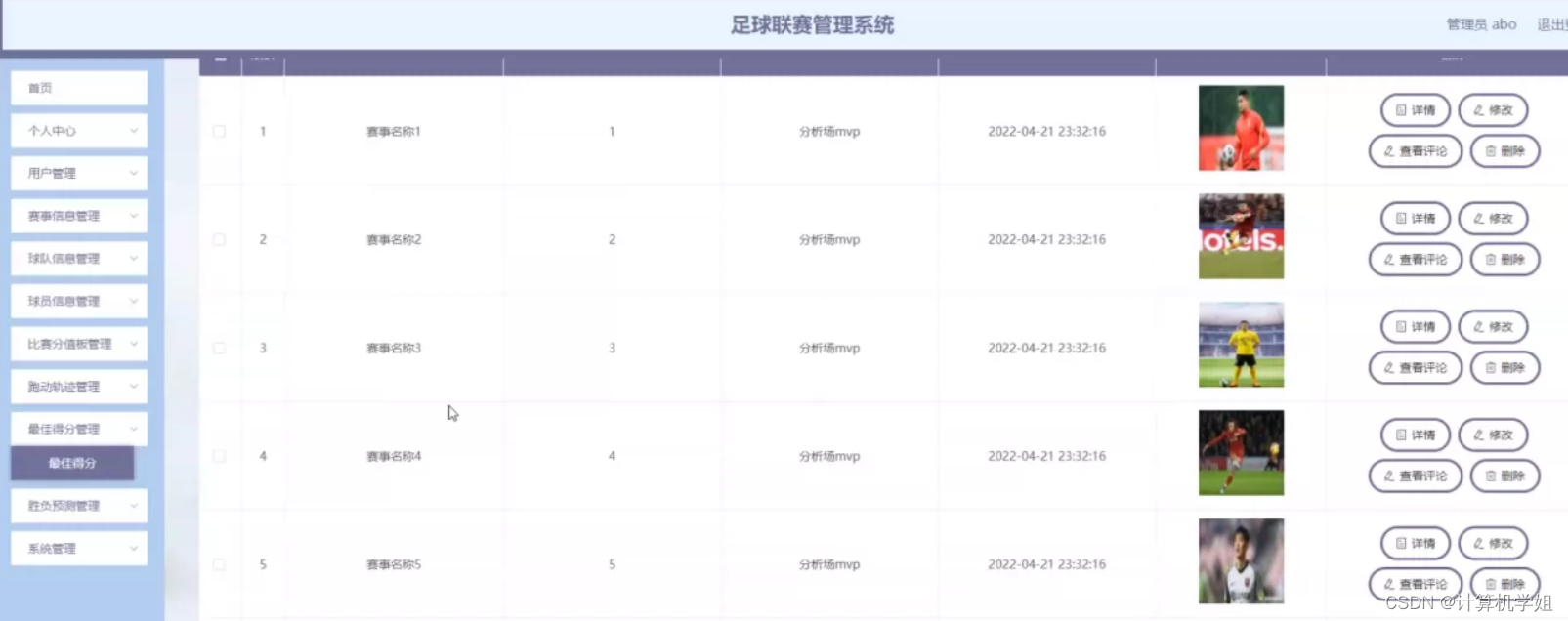
利用python的爬虫功能进行信息爬取,关键在于源码分析,代码相对简单。
1 源代码分析
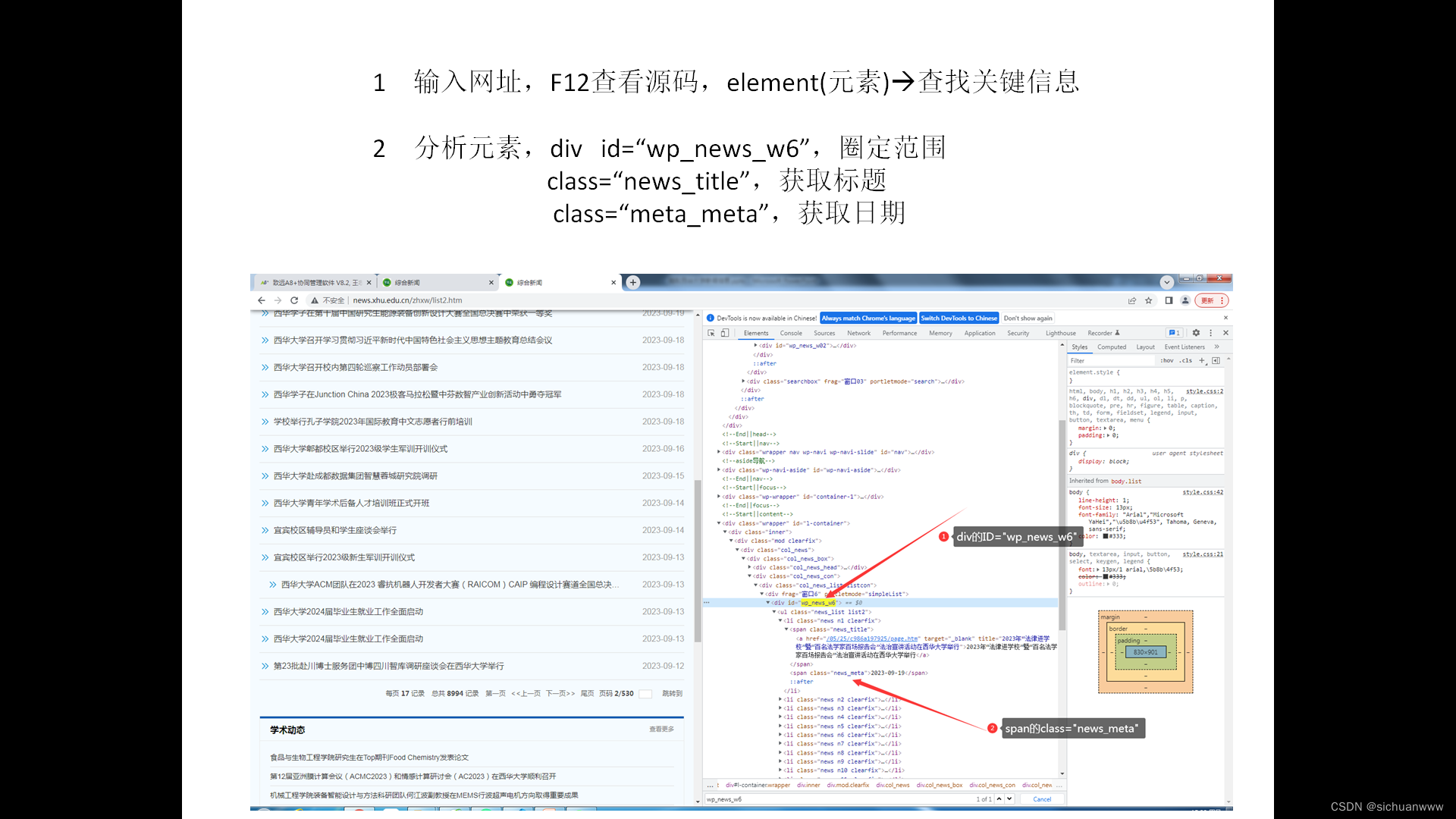
访问网站,按下F12,进行元素查找分析。
2 代码实现
from requests import get
from bs4 import BeautifulSoup
def getXhuNews(pageNum=1):
"""获取西华大学新闻信息"""
url="http://news.xhu.edu.cn/zhxw/list%d.htm"%(pageNum)
print(url)
response=get(url)
if (response.status_code==200):
print("顺利获取数据")
else:
print("目的网站无法连接")
exit();
response.encoding = 'utf8'
html=response.text
soup=BeautifulSoup(html,"html.parser")
#myTitle=soup.select(".news_title") #根据class查找结点(会找出太多的div)
myTitle=soup.find_all("div",{"id":"wp_news_w6"}) #根据div的id查找结点
soup = BeautifulSoup(str(myTitle),"html.parser") #重新构造soup
myTitle=soup.select(".news_title") #根据class查找结点(会找出太多的div)
myDate=soup.select(".news_meta") #根据class查找结点
print("第%d页"%pageNum," ",len(myTitle),"条新闻")
listDate=[] #存储日期
listTitle=[] #存储标题
listHref=[] #存储连接
for i in myTitle:
soup = BeautifulSoup(str(i),"html.parser") #重新构造soup
s=soup.select("a") #根据标签获取结点
for x in s:
listHref.append(x["href"]) #获取结点属性值
listTitle.append(x.getText()) #获取属性文本
for i in myDate:
soup = BeautifulSoup(str(i),"html.parser") #重新构造soup
s=soup.select("span") #根据标签获取结点
for x in s:
listDate.append(x.getText()) #获取属性文本
#写入文件
fileName="text%05d.txt"%(pageNum)
f=open(fileName,"w",encoding="utf8")
for i in range(len(listDate)):
str2="%04d"%(i+1)+" "+listDate[i]+" "+listHref[i]+" "+listTitle[i]+"\n"
f.write(str2)
f.close()
#----------使用样例---------------------------------
for i in range(40,50):
getXhuNews(i)


![2023年中国智慧医院市场现状及行业发展趋势分析[图]](https://img-blog.csdnimg.cn/img_convert/d5dec0e1b777be6ad6d4376d5d9a09c7.png)
![2023年中国连锁麻辣烫市场发展趋势分析:连锁麻辣烫行业规模将持续增长[图]](https://img-blog.csdnimg.cn/img_convert/47bafa59a252afec69d42a5201174bb1.png)
![2023年中国香樟木家具行业分析:定制化和个性化的需求不断增加[图]](https://img-blog.csdnimg.cn/img_convert/ce9af28a880f7e8a0c0070e75c5d2a3b.png)