前言
官方为我们提供了一个 对服装图像进行分类 的案例,方便我们快速学习
学习
预处理数据
案例中有下面这段代码
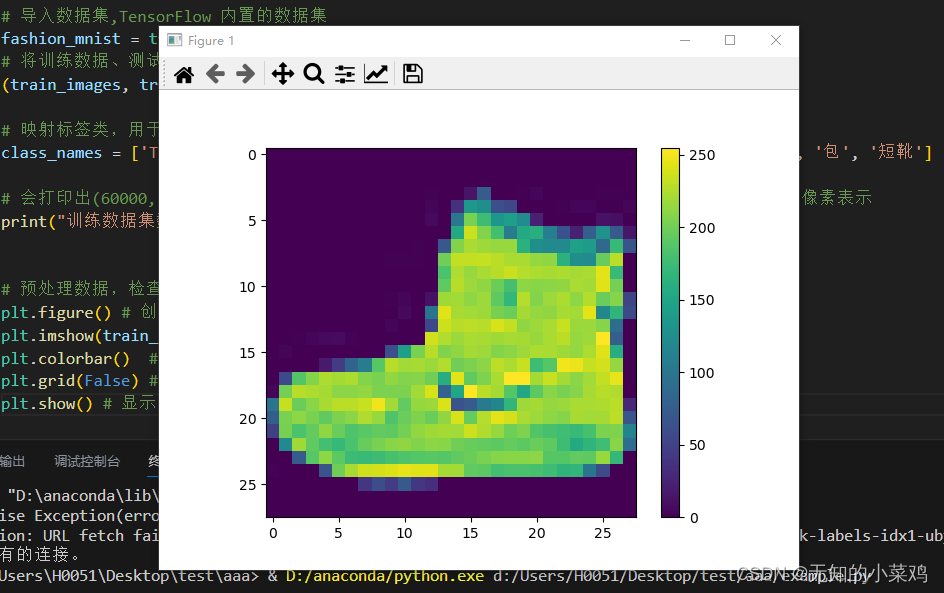
# 预处理数据,检查训练集中的第一个图像可以看到像素值处于0~255之间
plt.figure() # 创建图像窗口
plt.imshow(train_images[0]) # 显示图片
plt.colorbar() # 在图像旁边添加颜色条
plt.grid(False) # 取消网格线
plt.show() # 显示图形窗口
# 将值缩小至0~1之间,然后将其反馈到神经网络模型。训练集和测试集都需要处理
train_images = train_images / 255.0
test_images = test_images / 255.0
百度查了一下,将值缩小至0~1之间是为了
将训练集和测试集数据的值缩小到0~1之间是为了进行数据归一化(Normalization)。这是一个常见的预处理步骤,对于图像分类任务特别重要。
将图像的像素值缩放到0~1之间有几个好处:
- 数值范围一致性:将所有像素值限制在0~1范围内可以确保不同样本的特征具有一致的数值区间。这有助于避免某些特征对模型训练产生过大的影响。
- 梯度下降稳定性:在深度学习中,常用的优化算法如梯度下降依赖于权重的更新和损失函数的梯度计算。将像素值缩小到较小的范围可以使这些计算更加稳定,有助于加速模型的收敛。
- 避免数值溢出:在一些激活函数和优化算法中,如果输入值太大,可能会导致数值溢出或不稳定的情况。将像素值限制在0~1之间可以减少这种情况的发生。
以后再遇见处理255时就明白这样做的目的了
构建模型
构建神经网络需要先配置模型的层,然后再编译模型。
设置层
神经网络的基本组成部分是层。层会从向其馈送的数据中提取表示形式。希望这些表示形式有助于解决手头上的问题。
大多数深度学习都包括将简单的层链接在一起。大多数层(如 tf.keras.layers.Dense)都具有在训练期间才会学习的参数
# 1、设置层
# tf.keras是TensorFlow中的高级API,用于构建和训练神经网络模型。它是一个基于Keras库的接口,提供了更简单、更高级的方式来定义、配置和训练神经网络模型。
# tf.keras.Sequential 用于按顺序堆叠各个神经网络层来构建模型,是一种简单的模型类型
model = tf.keras.Sequential([
# 将图像格式从二维数组(28*28像素),转化为一维数组(28*28 = 784像素)。将该层视为图像中未堆叠的像素行并将其排列起来。该层没有要学习的参数,它只会重新格式化数据。
tf.keras.layers.Flatten(input_shape=(28,28)),
# 第二层,是一个具有128个神经元的全连接神经层
tf.keras.layers.Dense(128,activation='relu'),
# 第三层会返回一个长度为10的数组,每个都包含一个得分来表示当前图像属于10个类中的哪一个
tf.keras.layers.Dense(10)
])
这段代码我相信很多人跟我一样都有些疑问,还好现在有gpt,不然都不知道上哪里去找答案。下面是我的一些疑问及gpt的回答:
- 为什么只有三层。答:在神经网络中,层数的选择是一个灵活的设计选择,取决于特定问题的复杂性和数据集的特征。选择三层可能是为了简化模型或者问题本身不需要更多层
- 第二层为什么是
tf.keras.layers.Dense(128)。答:选择128个神经元是基于对问题复杂性的估计和经验。如果问题比较复杂或数据集较大,增加神经元数量可以增加模型的容量,提高模型的表示能力。 - 第三层为什么是
tf.keras.layers.Dense(10)。答:因为这是一个分类问题,这个案例中有10个分类。每个神经元对应一个类别,并输出相应类别的预测概率。 tf.keras.layers.Dense(128)是计算的来的吗。答:通常需要根据实际问题和数据集来进行调整。增加神经元的数量可以增加模型的容量和学习能力,但也可能导致过拟合。过拟合是指模型在训练数据上表现良好,但在新数据上表现较差。建议先从较小的数量开始,然后逐渐增加,直到模型的性能不再提高或开始出现过拟合为止。- 模型的最后一层是输出层吗。答:模型的最后一层通常是输出层。输出层的神经元数量通常与你要解决的问题相关。对于分类任务,输出层的神经元数量应该等于类别的数量。对于二分类任务,可以使用一个神经元来表示两个类别的概率。对于多分类任务,可以使用多个神经元,每个神经元表示一个类别的概率。在使用
tf.keras``构建模型时,你可以使用tf.keras.layers.Dense`来定义输出层,并使用适当的激活函数来产生输出。
编译模型
在准备对模型进行训练之前,还需要再对其进行一些设置。以下内容是在模型的编译步骤中添加的:
- 损失函数 - 测量模型在训练期间的准确程度。你希望最小化此函数,以便将模型“引导”到正确的方向上。
- 优化器 - 决定模型如何根据其看到的数据和自身的损失函数进行更新。
- 指标 - 用于监控训练和测试步骤。以下示例使用了准确率,即被正确分类的图像的比率。
# 2、编译模型
model.compile(
optimizer='adam', # 指定优化器,adam是常用的优化器,可以自适应的调整学习率
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), # 指定损失函数,这里使用了稀疏分类交叉熵损失函数
metrics=['accuracy'] # 指定评估模型性能的指标,这里使用准确率
)
训练模型
训练神经网络模型需要执行以下步骤:
- 将训练数据馈送给模型。在本例中,训练数据位于 train_images 和 train_labels 数组中。
- 模型学习将图像和标签关联起来。
- 要求模型对测试集(在本例中为 test_images 数组)进行预测。
- 验证预测是否与 test_labels 数组中的标签相匹配。
# 1、将训练数据反馈给模型
# model.fit用于将模型与训练数据进行拟合,这里是将所有样本迭代10次
model.fit(train_images,train_labels,epochs=10)
如下图:

# 2、在测试数据集上评估准确率,verbose=2参数表示以详细模式输出评估过程
test_loss,test_acc = model.evaluate(test_images,test_labels,verbose=2)
print("损失率:",test_loss,"准确率:",test_acc)
如下图:

进行预测
# 进行预测
# 模型经过训练后,您可以使用它对一些图像进行预测。附加一个 Softmax 层,将模型的线性输出 logits 转换成更容易理解的概率
probability_model = tf.keras.Sequential([model,tf.keras.layers.Softmax()])
# 预测图片
predictions = probability_model.predict(test_images)
print("第一个预测结果:",predictions[0])
预测结果是一个包含 10 个数字的数组。它们代表模型对 10 种不同服装中每种服装的“置信度”。您可以看到哪个标签的置信度值最大:
np.argmax(predictions[0])
使用训练好的模型
现在模型已经训练好了,我们可以基于模型对单个图像进行预测
# 使用训练好的模型
# 加载图片
img = Image.open('pics/shirt.png')
# 调整大小
img = img.resize((28,28))
# 将彩色图片转为灰度图片
img_gray = img.convert('L')
# 将图像转换为 NumPy 数组,并反转颜色
img_arr = np.array(img_gray)
img_arr = 255 - img_arr
# 将图像像素值归一化到0~1
img_arr = img_arr / 255.0
# 将图像形状调整为(1,28,288)
img_arr = img_arr.reshape(1,28,28)
# 可以保存处理后的文件,也可以进行预测
# np.save('abc.npy',img_arr)
# tf.keras 模型经过了优化,可同时对一个批或一组样本进行预测。因此,即便您只使用一个图像,您也需要将其添加到列表中
#img_arr = tf.keras.preprocessing.image.img_to_array(img)
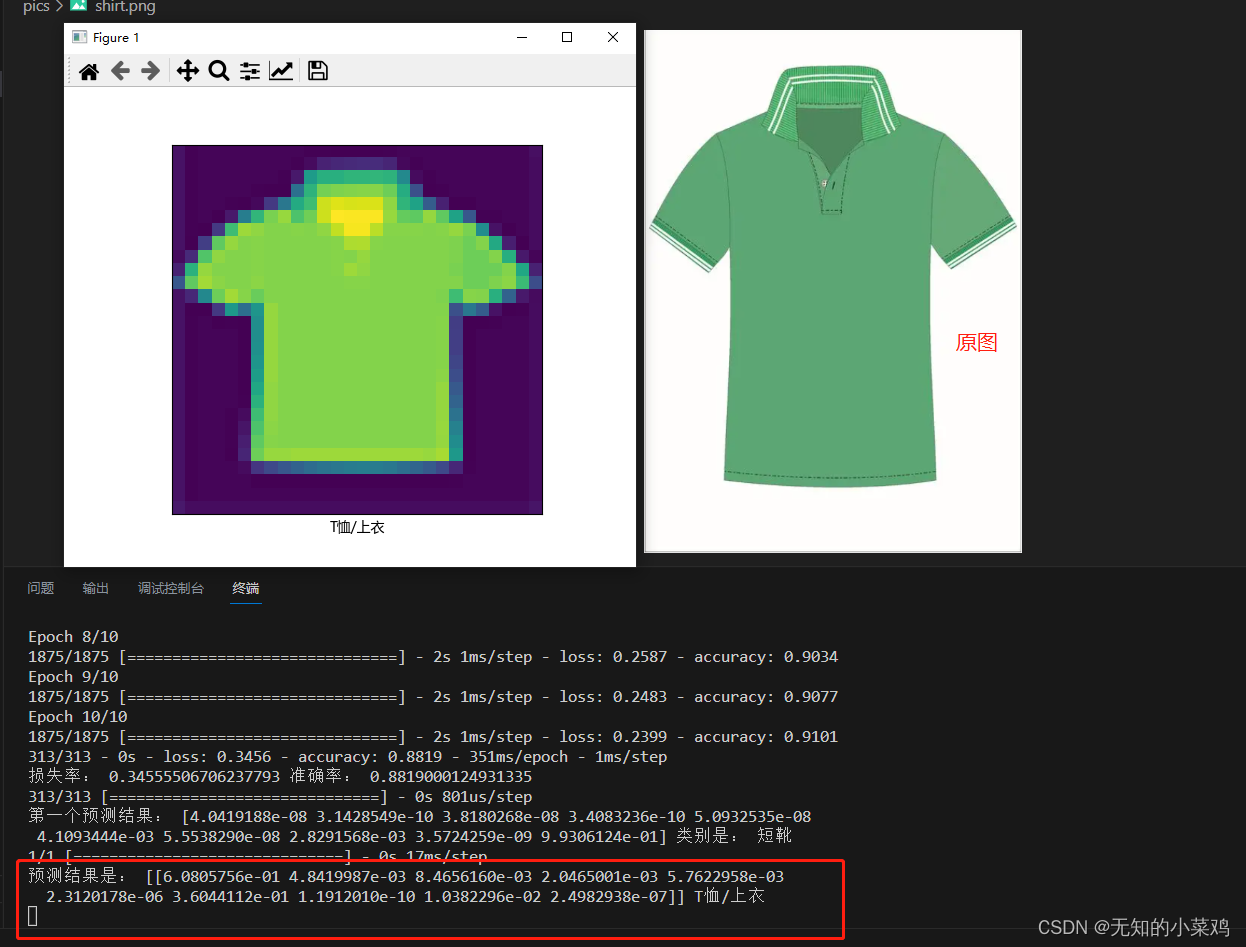
res = probability_model.predict(img_arr)
print("预测结果是:",res,class_names[np.argmax(res[0])])
# 可视化显示
font = FontProperties()
font.set_family('Microsoft YaHei')
plt.figure() # 创建图像窗口
plt.xticks([])
plt.yticks([])
plt.grid(False) # 取消网格线
plt.imshow(img_arr[0]) # 显示图片
plt.xlabel(class_names[np.argmax(res[0])],fontproperties=font)
plt.show() # 显示图形窗口
这块是最复杂的,搞了好久才成功。你加载的图片是彩色的,你必须将图片变成灰度的,并且是28*28像素的图片,也就是你的图片要处理成符合这个模型的图片才行。
但是最终结果其实也不是很准确,根本原因是你的图片处理后,能够获取的特征就很少了,这样会导致判断错误。
结果
遇到的问题
问题1
在执行(train_images, train_labels), (test_images,test_labels) = fashion_mnist.load_data()时提示
Exception: URL fetch failure on https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz: None – [WinError 10054] 远程主机强迫关闭了 一个现有的连接。
这是加载数据集时失败了,国内访问下载谷歌的数据总会出现这样的问题。
解决:
1、打开数据集官方网站 https://github.com/zalandoresearch/fashion-mnist,将下面这4个数据下载到本地放到项目里

2、加载本地数据
import gzip
import numpy as np
def load_data():
# 加载训练集图像数据
with gzip.open('train-images-idx3-ubyte.gz', 'rb') as f:
train_images = np.frombuffer(f.read(), np.uint8, offset=16).reshape(-1, 28, 28)
# 加载训练集标签数据
with gzip.open('train-labels-idx1-ubyte.gz', 'rb') as f:
train_labels = np.frombuffer(f.read(), np.uint8, offset=8)
# 加载测试集图像数据
with gzip.open('t10k-images-idx3-ubyte.gz', 'rb') as f:
test_images = np.frombuffer(f.read(), np.uint8, offset=16).reshape(-1, 28, 28)
# 加载测试集标签数据
with gzip.open('t10k-labels-idx1-ubyte.gz', 'rb') as f:
test_labels = np.frombuffer(f.read(), np.uint8, offset=8)
return (train_images, train_labels), (test_images, test_labels)
# 调用加载数据函数
(train_images, train_labels), (test_images, test_labels) = load_data()
问题2
验证前25个图像,设置中文乱码。教程中的使用的是英文,我这里尝试了一下中文,中文乱码
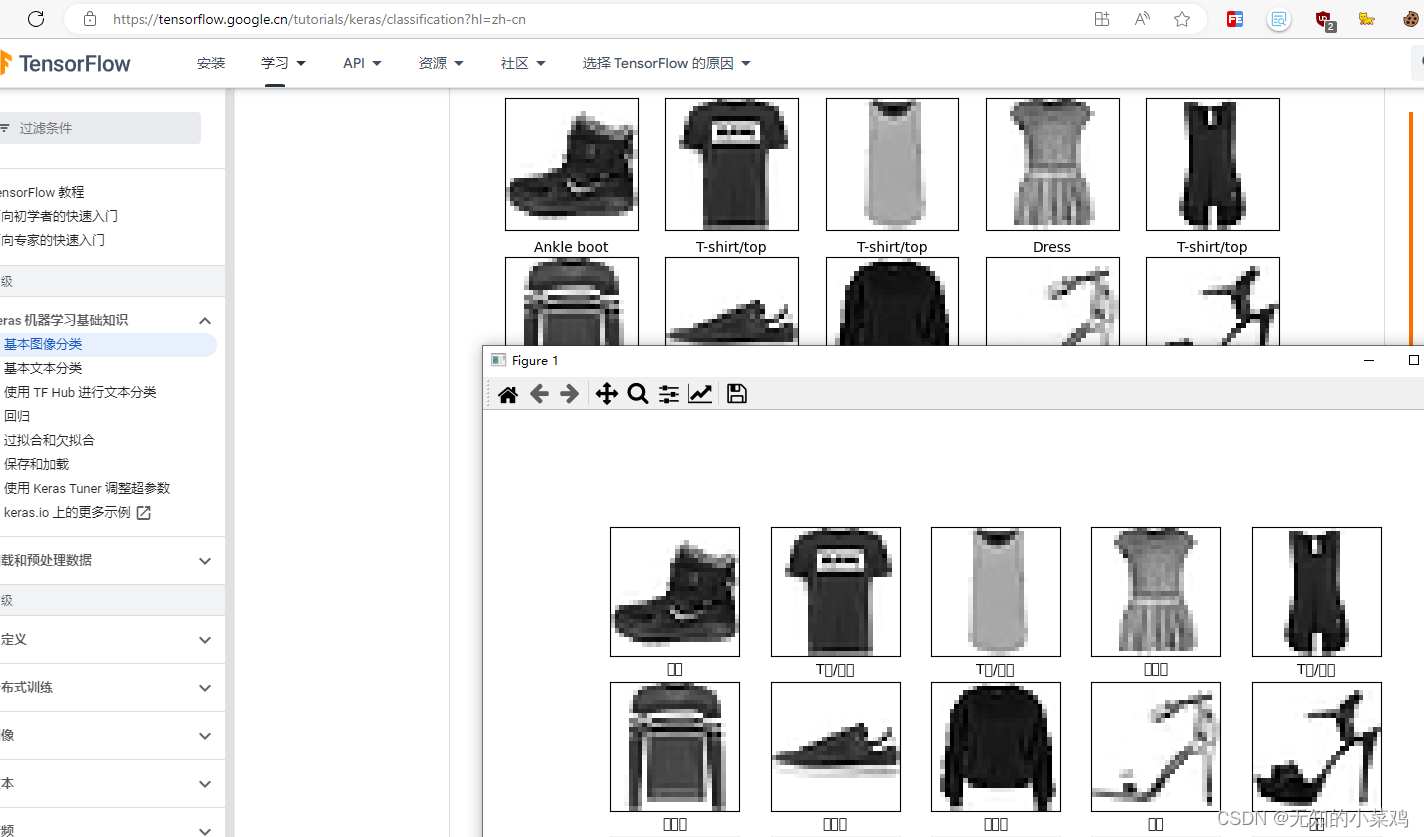
解决:设置中文字体
# 字体属性
from matplotlib.font_manager import FontProperties
# 验证训练集中的前25个图像,并显示其名称
font = FontProperties()
font.set_family('Microsoft YaHei')
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1) # 按照 5*5进行显示
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]],fontproperties=font)
plt.show()
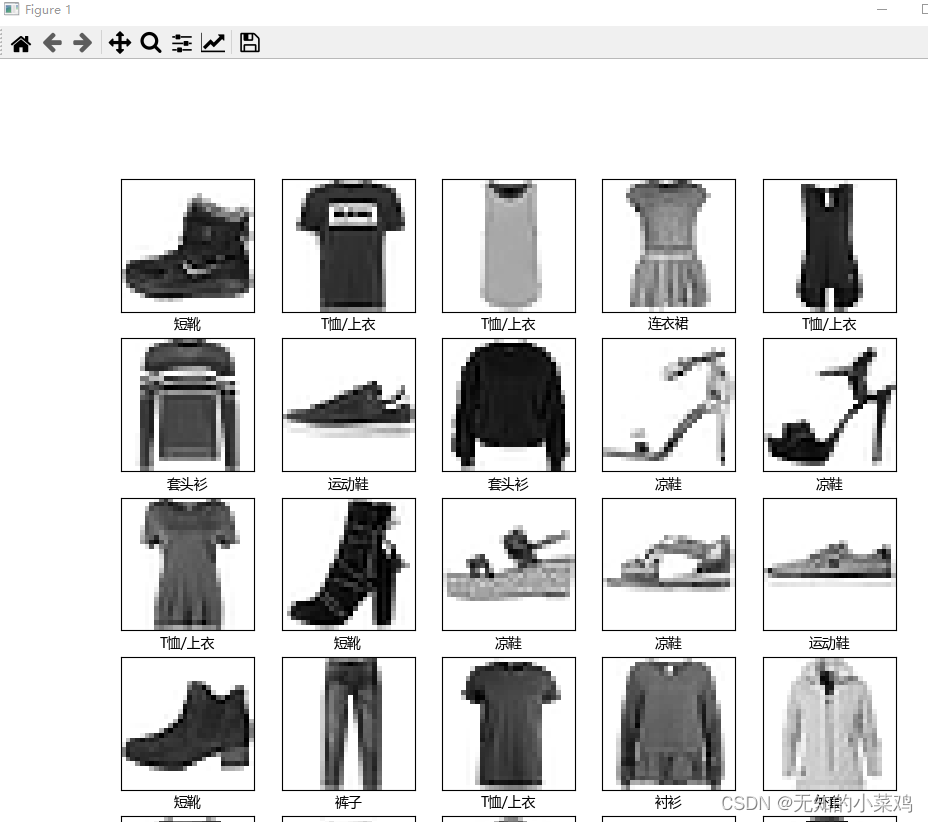
完整代码
# 导入 TensorFlow 重命名
import tensorflow as tf
# numpy是科学计算库,matplotlib是用于绘制图表和可视化数据的库
import numpy as np
import matplotlib.pylab as plt
# 字体属性
from matplotlib.font_manager import FontProperties
# 用于加载文件
import gzip
# 用于处理图片
from PIL import Image
# 用于加载数据集的函数
def load_data():
# 加载训练集图像数据
with gzip.open('train-images-idx3-ubyte.gz', 'rb') as f:
train_images = np.frombuffer(f.read(), np.uint8, offset=16).reshape(-1, 28, 28)
# 加载训练集标签数据
with gzip.open('train-labels-idx1-ubyte.gz', 'rb') as f:
train_labels = np.frombuffer(f.read(), np.uint8, offset=8)
# 加载测试集图像数据
with gzip.open('t10k-images-idx3-ubyte.gz', 'rb') as f:
test_images = np.frombuffer(f.read(), np.uint8, offset=16).reshape(-1, 28, 28)
# 加载测试集标签数据
with gzip.open('t10k-labels-idx1-ubyte.gz', 'rb') as f:
test_labels = np.frombuffer(f.read(), np.uint8, offset=8)
return (train_images, train_labels), (test_images, test_labels)
print("tf版本:",tf.__version__)
# 导入数据集,TensorFlow 内置的数据集
fashion_mnist = tf.keras.datasets.fashion_mnist
# 将训练数据、测试数据取出,保存的元组里
(train_images, train_labels), (test_images,test_labels) = load_data()
# 映射标签类,用于后面绘制图像使用
class_names = ['T恤/上衣', '裤子', '套头衫', '连衣裙', '外套', '凉鞋', '衬衫', '运动鞋', '包', '短靴']
# 会打印出(60000, 28, 28),官方文档解释为训练集中有 60,000 个图像,每个图像由 28 x 28 的像素表示
print("训练数据集数据:",train_images.shape)
# 预处理数据,检查训练集中的第一个图像可以看到像素值处于0~255之间
# plt.figure() # 创建图像窗口
# plt.imshow(train_images[0]) # 显示图片
# plt.colorbar() # 在图像旁边添加颜色条
# plt.grid(False) # 取消网格线
# plt.show() # 显示图形窗口
# 将值缩小至0~1之间,然后将其反馈到神经网络模型。训练集和测试集都需要处理
train_images = train_images / 255.0
test_images = test_images / 255.0
# 验证训练集中的前25个图像,并显示其名称
# font = FontProperties()
# font.set_family('Microsoft YaHei')
# plt.figure(figsize=(10,10))
# for i in range(25):
# plt.subplot(5,5,i+1) # 按照 5*5进行显示
# plt.xticks([])
# plt.yticks([])
# plt.grid(False)
# plt.imshow(train_images[i], cmap=plt.cm.binary)
# plt.xlabel(class_names[train_labels[i]],fontproperties=font)
# plt.show()
# 构建模型
# 1、设置层
# tf.keras是TensorFlow中的高级API,用于构建和训练神经网络模型。它是一个基于Keras库的接口,提供了更简单、更高级的方式来定义、配置和训练神经网络模型。
# tf.keras.Sequential 用于按顺序堆叠各个神经网络层来构建模型,是一种简单的模型类型
model = tf.keras.Sequential([
# 将图像格式从二维数组(28*28像素),转化为一维数组(28*28 = 784像素)。将该层视为图像中未堆叠的像素行并将其排列起来。该层没有要学习的参数,它只会重新格式化数据。
tf.keras.layers.Flatten(input_shape=(28,28)),
# 第二层,是一个具有128个神经元的全连接神经层
tf.keras.layers.Dense(128,activation='relu'),
# 第三层会返回一个长度为10的数组,每个都包含一个得分来表示当前图像属于10个类中的哪一个
tf.keras.layers.Dense(10)
])
# 2、编译模型
model.compile(
optimizer='adam', # 指定优化器,adam是常用的优化器,可以自适应的调整学习率
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), # 指定损失函数,这里使用了稀疏分类交叉熵损失函数
metrics=['accuracy'] # 指定评估模型性能的指标,这里使用准确率
)
# 训练模型
# 1、将训练数据反馈给模型
# model.fit用于将模型与训练数据进行拟合,这里是将所有样本迭代10次
model.fit(train_images,train_labels,epochs=10)
# 2、在测试数据集上评估准确率,verbose=2参数表示以详细模式输出评估过程
test_loss,test_acc = model.evaluate(test_images,test_labels,verbose=2)
print("损失率:",test_loss,"准确率:",test_acc)
# 进行预测
# 模型经过训练后,您可以使用它对一些图像进行预测。附加一个 Softmax 层,将模型的线性输出 logits 转换成更容易理解的概率
probability_model = tf.keras.Sequential([model,tf.keras.layers.Softmax()])
# 预测图片
predictions = probability_model.predict(test_images)
print("第一个预测结果:",predictions[0],'类别是:',class_names[np.argmax(predictions[0])])
# 使用训练好的模型
# 加载图片
img = Image.open('pics/shirt.png')
# 调整大小
img = img.resize((28,28))
# 将彩色图片转为灰度图片
img_gray = img.convert('L')
# 将图像转换为 NumPy 数组,并反转颜色
img_arr = np.array(img_gray)
img_arr = 255 - img_arr
# 将图像像素值归一化到0~1
img_arr = img_arr / 255.0
# 将图像形状调整为(1,28,288)
img_arr = img_arr.reshape(1,28,28)
# 可以保存处理后的文件,也可以进行预测
# np.save('abc.npy',img_arr)
res = probability_model.predict(img_arr)
print("预测结果是:",res,class_names[np.argmax(res[0])])
# 可视化显示
font = FontProperties()
font.set_family('Microsoft YaHei')
plt.figure() # 创建图像窗口
plt.xticks([])
plt.yticks([])
plt.grid(False) # 取消网格线
plt.imshow(img_arr[0]) # 显示图片
plt.xlabel(class_names[np.argmax(res[0])],fontproperties=font)
plt.show() # 显示图形窗口






![windows2003远程访问tscc.msc[终端服务配置\连接]选项卡为灰色,怎么样才能使其可配置](https://img-blog.csdnimg.cn/280ba7521052454ca4512e2fdf8378be.png)