目录
一、分布式事务理论
1.1、分布式事务问题
1.2、什么是分布式事务
1.3、解决分布式事务思路
1.3.1、CAP 定理
a)Consistency(一致性)
b)Availability(可用性)
c)Partition tolerance (分区容错性)
问题1:为什么三者最多只能满足其二?
分析总结
问题2:ElasticSearch 的集群是属于哪种模式呢?
1.3.2、BASE 理论
a)基于 base 理论,通过 ap 模式解决
b)基于 basse 理论,通过 cp 模式解决
分析:上述方法的共同特点
一、分布式事务理论
1.1、分布式事务问题
在我们以往学习的单体架构中,往往只有一个服务,直接访问一个数据库,业务比较简单,已经能够实现 ACID 了(原子性、一致性、隔离性、持久性),但是微服务的业务往往比较复杂,可能一个业务就要跨多个服务,每个服务又有自己的数据库,这个时候在靠数据库本身的特性,可以就不一定能保证整个业务的 ACID 了.
例如,我这里有三个微服务,分别是订单服务、账户服务、库存服务. 现在有一个用户下单的业务,就是说用户下单的时候,希望订单服务去创建订单,然后再调用账户服务去扣 减用户余额,最后再调用库存服务去扣 减商品库存数量.
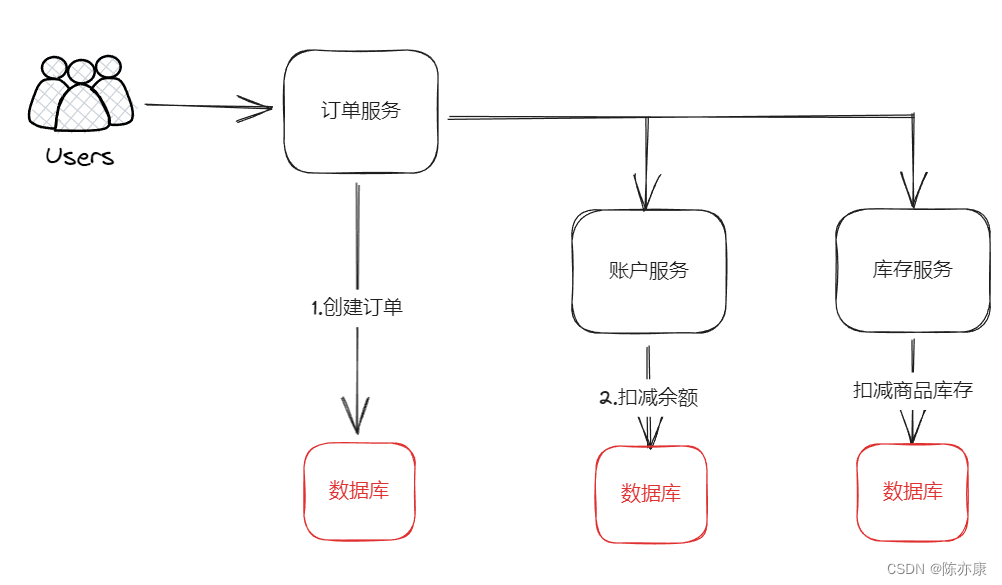
可以看到整个业务中,每个微服务都有自己独立的数据库,独立的事务,那么我肯定希望的是,下单业务一旦执行,要么都成功,要么都失败.
实际上,如果 订单服务 和 账户服务 执行成功,但是库存服务执行失败,那么是不会回滚. 为什么呢?
- 首先因为每一个服务都是独立的,并且是依次同步执行的,即使最后一个库存服务抛了一个异常,但是订单服务和账户服务都感知不到啊.
- 每个服务的是独立的,那么他们的事务也都是独立的,也就意味着,执行完 订单服务 和 账户服务,他们的事务也就执行完成了,所以也没办法进行回滚,最终就没有达成事务一致的状态.
1.2、什么是分布式事务
在分布式系统下的一个业务,跨越了多个服务和数据库,每个防毒物都可以任务是一个分支事务,分布式事务就是要保证,所有分支事务最终状态一致,要么大家都成功,要么大家都失败.
而分布在事务出现了问题,就是因为各个分之事务之间是相互隔离,感知不到的,因此就导致无法回滚,进一步导致没法保证一致性.
1.3、解决分布式事务思路
1.3.1、CAP 定理
CAP 定理提出:分布式系统中有三个指标
- Consistency(一致性)
- Availability(可用性)
- Partition tolerance (分区容错性)
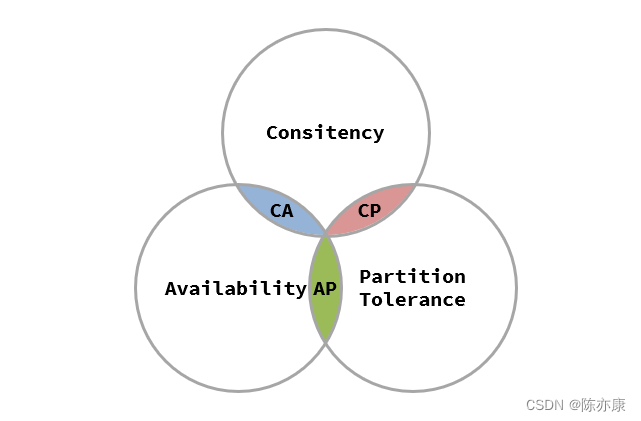
并且指出这个三个指标是不能同时满足的,最多只能满足其中两个.
为什么呢?我们就要弄清楚这三个指标的含义是什么.
a)Consistency(一致性)
一致性就是说,用户在访问分布式系统中的任意节点时,得到的数据必须时一致的.
比方说,我现在有两个节点,第一个节点上有一个数据 k1 的值为 0,第二个节点上也是一样,形成了一个主从关系. 现在我对第一个节点的数据进行修改,那么为了满足一致性,就需要将第一个节点的数据同步给第二个节点. 因此在分布式系统中,对数据进行修改时,一定要及时去完成数据同步.
b)Availability(可用性)
可用性就是说,用户在访问集群中的任意一个健康节点的时候,必须得到响应,不能是拒绝或者超时.
比如我这里有一个集群,包含三个节点,正常情况下用户访问任何一个节点都是没有问题的,但是突然有一天,请求发往其中一个节点被阻塞或者拒绝了,那么就说明这个节点不可用了,也就不能被正常访问了.
c)Partition tolerance (分区容错性)
先来看一下 “分区”,就是指因为网络的故障或者其他原因,导致分布式系统中的部分节点失去了连接,形成独立分区.
比如说,我有 node1、node2、node3 三个节点,node1 和 node2 可以互相访问,node2 和 node3 可以相互访问,但是其中 node3 因为网络原因和 node2 断开了连接,就导致 node3 无法和 前两个节点进行数据同步,也就是说形成了两个分区,node1 和 node2 是一个分区, node3 是一个分区. 此时,如果有用户给 node1 上写数据,那么数据就会同步给 node2,但是 node3 确感知不到,就导致两个分区数据不一致了.
“分区容错” 就是指不管集群有没有出现分区,整个系统也都要持续对外提供服务,尽管你这里分区了,用户也是要继续访问的.
问题1:为什么三者最多只能满足其二?
AP (可用性、分区容错性):刚刚讲到分区容错,即使出现分区,用户也要继续访问,那么就会导致数据出现不一致的情况.
CP(一致性、分许容错性):那如果我就要满足一致性,怎么办?那我是不是可以等待 node3 (因为网络故障被分区的节点)这个节点和 node2 的网络恢复之前,阻塞所有请求,告诉他们 “你们等等,我这里数据还没有同步好呢!”,那是不是就可以满足数据的一致性了,但是明明三个健康的节点却不让用户访问,不就不满足可用性了嘛.
CA(一致性、可用性):那如果我要满足可用性,又要保证一致性,那就需要保证数据的一致,那么就不允许出现分区的情况.
分析总结
但是分区这种情况又是不可以避免的,因为在分布式系统中,节点之间虽然不一定是通过网络连接,但是你只要是通过网络连接,就没办法保证网络百分之百是健康的. 那么既然分区一定会出现,此时,就需要你在 a(可用性)和 c(一致性)之间做出选择了.
问题2:ElasticSearch 的集群是属于哪种模式呢?
当出现网络故障时,有节点与其他节点断开连接的时候,es 集群会处于一个警告状态,出现故障的节点过了一段时间就会从集群中剔除,而这个节点上的数据分片就会分散到其他健康的节点上去. 那么出现故障的节点就无法访问他了,也就是牺牲了可用性,因此 es 显然是一个 CP 啊.
1.3.2、BASE 理论
我们知道,在分布式系统下,分区时不可避免的,因此你不得不在 一致性 和 可用性 之间做出一个选择,但是这两个特性都非常重啊,一个都不想放弃怎么办?BASE 理论刚好可以解决这个问题.
BASE 理论中包含三个思想:
- Basically Available (基本可用):分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
- Soft State(软状态):在一定时间内,允许出现中间状态,比如临时的不一致状态。
- Eventually Consistent(最终一致性):虽然无法保证强一致性,但是在软状态结束后,最终达到数据一致。
实际上,BASE 理论就是对 可用性和一致性去做的调和和选择. 出现故障,我可以牺牲一部分的可用性,或者临时不可用,那么也就会导致这个期间会有部分数据不一致的情况,而一旦网络恢复了,在把他加入到集群中,重新给他分片,是不是又可用了,并且得到了最终的一致性.
那么基于 base 理论如何解决分布式事务呢?
a)基于 base 理论,通过 ap 模式解决
也就是满足可用性,牺牲一定的一致性.
比如说有很多子事务,将来分别去执行和提交,有些成功有些失败,产生不一致,也就是处于一个软状态了,当执行完了以后,在相互通个气问问 “欸?你成功了吗?哦,我成功了. 哎呀,我这边失败了......”.
一对比发现有人失败了,并且他还给提交了,没关系啊,我们也可以反向操作. 比如说你之前新增了一个,那接下来把他删了不就可以了,不也实现最终一致了.
因此,这是一种基于 ap 思想的分布式事务解决方案.
b)基于 basse 理论,通过 cp 模式解决
就是满足一致性,牺牲一定的可用性.
比如现在有很多子事务,一个个执行完之后别提交,互相等待,彼此都看看执行完了没. 如果全部执行完没问题,就同时提交. 如果中间有人失败了,就同时回滚.
那么在这个过程中,各个子事务要相互等待,因此服务其实时处于一个弱可用状态,因为你会锁定资源啊,导致无法访问.
分析:上述方法的共同特点
各个子事务都需要做相互通信,辨别对方的执行状态,因此就需要有一个事务的协调者来帮助分布式事务中的各个子事务进行一个通信,感知彼此的状态.
比如拿之前的下单为例子,用户下单,调用订单服务,然后去调用账户和库存服务,此时就需要有一个事务协调者了.
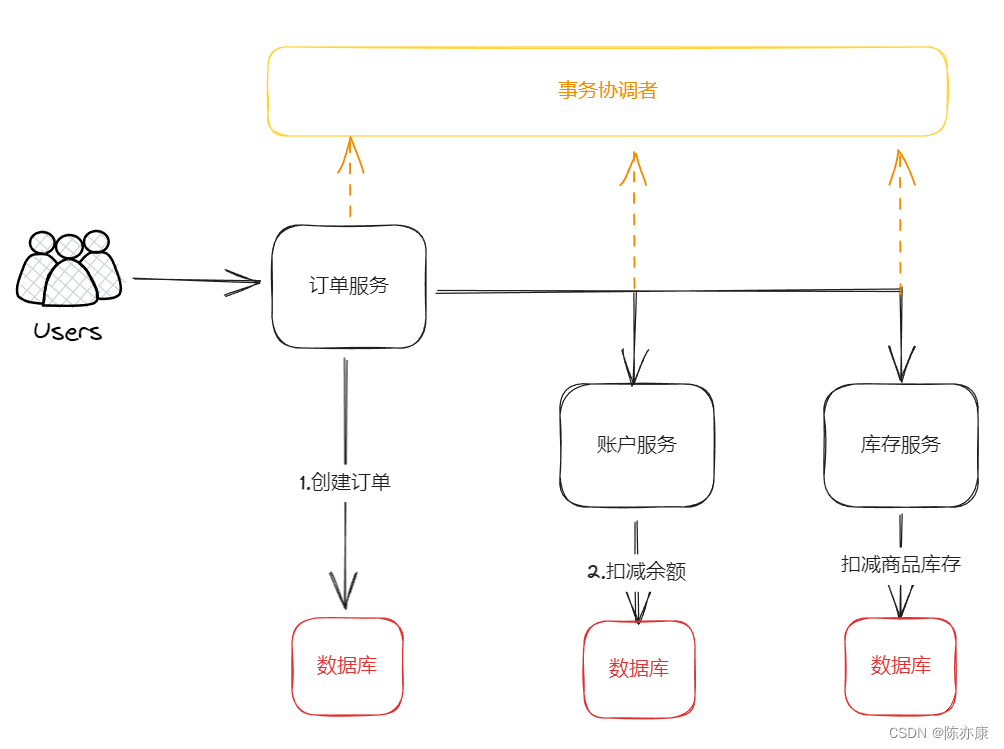
如果你现在要做强一致,那么在订单服务执行的时候不要提交,先把自己执行的状态告诉事务协调者(成功或者失败),接着执行账户服务 和 库存服务,然后把自己的状态都告诉事务协调者,如果发现有人失败了,再通知他们去做回滚,这样大家保持一致了.
这整个过程中,每一个子事务也叫做分支事务,而有关联的整个分支事务一起也称之为全局事务.