文章目录
- python常用库之数据库orm框架之SQLAlchemy
- 一、什么是SQLAlchemy
- SQLAlchemy 使用场景
- 二、SQLAlchemy使用
- SQLAlchemy根据模型查询
- SQLAlchemy SQL 格式化的方式
- db_session.query和 db_session.execute区别
- 实测demo 总结:让我们留意一下SQLAlchemy 的 lazy loading 特性
- scoped session
- 关于scoped_session自动提交事务
- 参数autoflush=False 的工作机制
- 三、关于SQLAlchemy自动提交事务
- PostgreSQL 和 MySQL 自动提交区别
- 查看PostgreSQL当前连接是否开启自动提交
- 四、工作遇到的问题
- 1. pg报错:unexpected EOF on client connection
- 2. 报错:sqlalchemy.exc.ArgumentError: autocommit=True is no longer supported
python常用库之数据库orm框架之SQLAlchemy
一、什么是SQLAlchemy
官网:https://www.sqlalchemy.org/
SQLAlchemy是一个基于Python实现的SQL工具包和ORM框架,提供了高层抽象来管理数据库交互。
SQLAlchemy功能强大,可以省去很多手动管理数据库连接、资源、事务等重复工作,让开发者更加高效地使用数据库。许多大型Python项目都选择使用SQLAlchemy作为ORM框架。
SQLAlchemy 使用场景
SQLAlchemy是一个强大的Python ORM框架,主要应用于以下场景:
- 数据库访问和操作:SQLAlchemy提供了高层抽象来操作数据库,可以避免写原生SQL语句。支持多种数据库后端。
- ORM映射:建立Python类与数据库表的映射关系,简化数据模型的操作,支持声明式操作。
- 复杂查询: SQLAlchemy提供丰富的查询方式,如过滤、分组、联结等,可以构建复杂查询。
- 异步查询:基于Greenlet等实现异步查询,提高查询效率。
- 事务控制: 通过Session管理数据库会话和事务。
- 工具集成:如数据迁移工具Alembic,可以实现Schema版本控制和迁移。
- 大数据集查询:基于Pagination实现数据分页,避免大量数据查询内存溢出。
- 多数据库支持:支持Postgres、MySQL、Oracle等主流数据库。
- Web框架集成:框架如Flask可以集成SQLAlchemy,便于Web应用开发。
二、SQLAlchemy使用
SQLAlchemy根据模型查询
- 引入和初始化
导入sqlalchemy模块,然后使用create_engine创建引擎,sessionmaker创建会话类并生成会话对象。
from sqlalchemy import create_engine
from sqlalchemy.orm import scoped_session, sessionmaker
engine = create_engine(SQLALCHEMY_DATABASE_URI)
db_session = scoped_session(sessionmaker(autoflush=False,bind=engine))
- 使用sql 或者 数据模型
这里先举例模型方式:
在SQLAlchemy中,declarative_base()用来创建一个基类,这个基类会为所有继承它的子类提供declarative的ORM功能。
TblObject = declarative_base() 的作用是:
3. 创建了一个名为TblObject的基类
4. 这个TblObject具有declarative的功能
5. 后续定义的模型类可以继承这个TblObject基类来使用declarative
from sqlalchemy.orm import declarative_base
from sqlalchemy import Column, Text, Integer,String, VARCHAR, TIMESTAMP, BOOLEAN, Float, text
TblObject = declarative_base()
class User(TblObject):
__tablename__ = 'table_user'
__table_args__ = ({"schema": "public"})
id = Column(Integer, primary_key=True)
name = Column(String)
query = db_session.query(User)
user = query.first()
print(user.name)
SQLAlchemy SQL 格式化的方式
- 将sql语句本身不包含参数格式化,直接作为文本构建完整的sql:
要想实现变量替换,需要使用f-string的格式
myschema = 'xxxx'
sql = text(f'SELECT id FROM {myschema }.table...')
注意看字符串前面有个f。
- 使用参数绑定的方式,而不是%格式化:
sql = text('SELECT id FROM :schema.table...')
params = {'schema': 'my_schema'}
result = session.execute(sql, params)
总结:
- sql文本内不要再使用% formatting
- 使用f-string或参数绑定格式化
- 创建text对象时直接构建完整sql文本
参数绑定也可以提高安全性,避免SQL注入\
db_session.query和 db_session.execute区别
在SQLAlchemy中,db_session.query()和db_session.execute()主要有以下几点区别:
- 返回值不同:
- db_session.query() 返回一个Query对象,可以用于构建查询并最终获取结果。
- db_session.execute() 直接执行语句并返回结果。
- 查询方式不同:
- db_session.query() 通过ORM构建查询。
- db_session.execute() 通过原生SQL语句查询。
- 查询灵活性不同:
- db_session.query() 可以构建非常灵活的查询,包含各种过滤、JOIN等。
- db_session.execute() 只能执行简单的SQL语句查询。
- 返回结果不同:
- db_session.query() 返回的是ORM对象或者自定义类的实例。
- db_session.execute() 直接返回行数据组成的列表。
- 性能不同:
- 对简单查询,db_session.execute()往往更快。
- 对复杂查询,db_session.query()可以通过ORM特性进行优化。
所以,简单来说:
- db_session.query() 是面向对象的查询方式,更灵活,但复杂查询可能有性能问题。
- db_session.execute() 是执行原生SQL的直接查询,性能好但不够灵活。
需要特别注意的点:使用 db_session.query() 后获取的 ORM 对象实例,在访问其属性之前,需要确保与该查询关联的 db_session 没有关闭或失效。
否则报错:
raise orm_exc.DetachedInstanceError(
sqlalchemy.orm.exc.DetachedInstanceError: Instance <User at 0x7f2973d6fbe0> is not bound to a Session; attribute refresh operation cannot proceed (Background on this error at: https://sqlalche.me/e/20/bhk3)
通常的使用模式是:
db_session = Session()
# 创建查询
query = db_session.query(User)
# 获取用户对象
user = query.first()
# 访问属性
print(user.name)
# 关闭会话
db_session.close()
在关闭 db_session 之前,需要先完成对其查询结果的处理和访问。
如果在获取到 user 对象后立即关闭会话,然后访问 user.name,会发生 detached实例错误。
因为在会话关闭后,user 对象脱离了会话,属性无法加载。
使用 db_session.execute() 执行原生SQL查询general不会存在会话过早关闭导致属性访问错误的问题。
db_session.execute() 返回的是数据库行记录组成的结果集,不涉及 ORM 对象映射。
实测demo 总结:让我们留意一下SQLAlchemy 的 lazy loading 特性
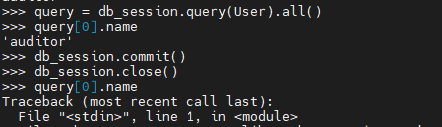
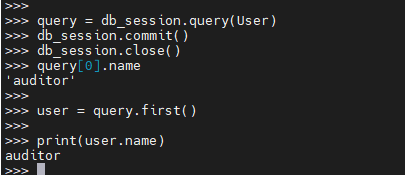
测试结果:经过测试,query = db_session.query(User).all() 这样db_session.close() 后,使用query[0].name会报错,但是query = db_session.query(User),close之后 query的数据还能用。
db_session.query(User) 只是构造了一个查询,并没有立即获取结果。
而 db_session.query(User).all() 执行了查询并获取了结果。
在会话关闭后,这两种情况的行为不同:
- 对于仅构造查询的 db_session.query(User),由于没有结果产生,所以不会有 detached 实例的问题。我们可以在会话关闭后,使用这个查询加上过滤条件等再次执行,产生新结果。
- 但对于立即执行了的 db_session.query(User).all(),其结果中的实例与关闭后的会话失去关联,成为 detached 实例,会导致访问属性失败。
这与 SQLAlchemy 的 lazy loading 特性有关 - 查询只有在需要时才执行和加载实例。
- 构造查询只生成了一个执行计划,不涉及具体实例数据,所以会话关闭后计划还可以再执行。
- 但执行查询并获取实例,实际上已经加载了具体的数据,所以会依赖会话提供的数据状态。
scoped session
使用 db_session.query() 时,为了避免访问 detached 实例,我们希望延迟关闭会话 db_session。但这样就无法及时提交事务,可能会导致锁表问题。
解决方法:
- 在查询之后、访问实例属性之前,先显式提交事务:
db_session.query(...)
db_session.commit() # 提交事务
obj.some_attr # 访问属性
这可以先释放锁,同时实例也绑定到会话中。
- 使用scoped session,可以避免手动 close db_session。
from sqlalchemy.orm import sessionmaker, scoped_session
session_factory = sessionmaker(bind=engine)
Session = scoped_session(session_factory)
def get_user():
session = Session()
return session.query(User).first()
这里的Session是一个scoped session类。其特点是:
- 每个线程或请求都会自动创建一个新的session实例,避免同一个session跨线程/请求使用。
- 使用完session后不需要关闭它,scoped session会在当前上下文退出后自动关闭、invalidate该session。
- 所以我们只需要使用Session类创建session,不需要close。
- 不同的框架可以集成scoped session到自己的上下文。比如Flask集成后,每个请求都会自动开启一个session,请求结束后自动关闭。
- 这样就可以不需要我们手动管理session的生命周期。
所以综上,scoped session通过封装context管理,让session的生命周期与当前上下文(线程、请求等)绑定,自动开启和关闭,省去了手动管理的问题。
总结:
方法1: 我们只调commmit,这里不调colse(),需要其他地方,只有在确定不用的情况下才调close。
方法2:我们使用scoped_session,scoped session 的生命周期由应用管理,不需要我们手动关闭。
使用scoped_session,这个 session 实例绑定到线程/请求,在其线程结束时自动关闭.
关于scoped_session自动提交事务
scoped_session 的工作原理是:
- 为每个线程或请求创建一个新的 session 实例
- 这个 session 实例绑定到线程/请求,在其结束时自动关闭
- 开发者只需要使用 Session 类即可,不需要手动关闭
也就是说,每个线程/请求都会有一个独立的 session 实例,这个实例不会自动提交。
如果我们需要自动提交,需要在使用 session 的时候设置:
在会话层面设置自动提交:
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
session = Session()
session.autocommit = True
通过设置session.autocommit启用自动提交。这会针对当前线程的 session 实例开启自动提交。
另外,scoped_session 也不建议使用自动提交模式,因为会有并发问题。推荐的方式还是手动提交控制事务。
总结,对于 scoped_session:
- 在创建时设置autocommit 不会生效
- 应在使用时针对 session 实例设置autocommit
- 推荐的方式仍是手动提交控制事务
参数autoflush=False 的工作机制
db_session = scoped_session(sessionmaker(autoflush=False, bind=engine))
db_session = scoped_session(sessionmaker(bind=engine))
如上,有什么区别?
关闭自动 flush(autoflush=False)的主要目的是可以更精细地控制 flush 的时机,原因如下:
- 自动 flush 可能导致不必要的数据库写入操作,比如在一个事务中有多次 CRUD 操作时,希望只在事务提交时一次性写入,而不是每次操作都触发 flush。
- 在一些场景下需要确保 flush 只在事务提交时发生,如两个关联对象的变更,希望它们的变更作为一个事务执行。
- 需要根据业务逻辑精确控制 flush 时机,而不是通过隐式的自动 flush。
SQLAlchemy中的session.commit()内部会自动调用session.flush()来保证所有pending的变更都被持久化。
即使设置autoflush=False,commit操作也会强制执行flush。只是在commit之外的其他情况下,需要手动调用flush。
在autoflush=False的情况下:
- 正常的增删改操作不会自动flush
- 调用commit会触发强制flush以持久化变更
这是SQLAlchemy的一种保护机制,来确保在事务提交时不会丢失还未flush的变更。
autoflush=False 需要手动flush,但不影响commit的自动flush行为。
三、关于SQLAlchemy自动提交事务
背景:
工作发现使用,出现很多 sqlalchemy出现很多未提交事务 情况。
demo:
from sqlalchemy import create_engine
from sqlalchemy.orm import scoped_session, sessionmaker
from sqlalchemy import text
username="aaa"
password="xxx"
host="127.0.0.1"
port="5432"
db="xx"
sqlalchemy_uri = f"postgresql://{username}:{password}@{host}:{port}/{db}"
engine = create_engine(sqlalchemy_uri)
#engine = create_engine(sqlalchemy_uri, echo=False, client_encoding='utf8', pool_size=100, pool_recycle=3600)
db_session = scoped_session(sessionmaker(bind=engine))
sql = text('SELECT * FROM auth_user WHERE id = :userid;')
userid=1
# execute() 方法仅仅是执行查询,不会自动提交事务。
objs = db_session.execute(sql, {"userid": userid}).fetchall()
print(objs)
**每个session默认都是在一个事务中,不会自动提交。**因此当你调用db_session.execute(sql)时,会默认复用当前session的事务来执行,而这个session已经在一个未提交的事务中了。
这与直接调用begin()开始一个新事务其实效果是一样的。
PostgreSQL 和 MySQL 自动提交区别
PostgreSQL 的默认设置是自动提交关闭的,每次事务需要显式地通过 COMMIT 提交。
PostgreSQL的事务autocommit是transaction级的。每个transaction需要显式提交或回滚。
在PostgreSQL中,autocommit是作用于每个事务(transaction)的,主要体现在以下两个方面:
- 新建立的连接默认都是非自动提交状态(autocommit=off)。这个连接下的所有事务操作默认都是非自动提交的。
- 开始一个新的事务时,这个事务会继承连接当前的autocommit状态。如果连接是非自动提交的,那么这个事务也是非自动提交的。
举个例子:
– 新建立连接,默认autocommit=off
postgres=# begin; -- 开始一个新事务,继承连接的autocommit=off
postgres=# insert into table_a values (1); -- 非自动提交
postgres=# commit; -- 需要显式提交事务
新连接默认的是非自动提交状态。当开始一个新的事务时,这个事务继承了连接的非自动提交属性。所以我们必须通过提交事务来持久化改变。
- MySQL 的默认设置是自动提交开启的,每条语句会自动提交事务。
MySQL的事务autocommit标志是session级的。也就是说,一个会话内全部操作默认都是自动提交的。
您的问题提到了MySQL中的自动提交模式,这和PostgreSQL中的事务处理模式有些不同。
MySQL中的自动提交(autocommit)是作用于整个数据库连接会话的,主要体现在:
- 新建立的连接默认是自动提交模式(autocommit=on)。
- 连接的自动提交模式作用于该连接下执行的所有事务。不管执行多少个事务,都使用该连接的自动提交模式。
- 设置自动提交模式会改变连接的默认提交行为。
举个例子:
– 新连接默认autocommit=ON
mysql> start transaction; -- 开始事务,但继承连接的自动提交模式
mysql> insert into table_a values (1); -- 自动提交
mysql> commit; -- 提交无实际效果,因为已自动提交
在这个例子中,由于连接的默认autocommit=on,所以不管执行多少个事务,每条SQL语句都会隐式提交。
SQLAlchemy 的设计是为了最大程度兼容不同数据库的行为,所以从 1.4 版本开始采用关闭自动提交作为默认值,这更符合 PostgreSQL 和一些其他数据库的行为。
总结:PostgreSQL的autocommit属性是针对每个事务的,而不是整个会话。这就要求我们必须显式地提交或回滚事务来结束一个事务。
查看PostgreSQL当前连接是否开启自动提交
查询 pg_settings 系统表:
SELECT setting FROM pg_settings WHERE name = 'default_transaction_isolation';
返回 ‘read committed’ 表示未开启。
是否可以直接查询PostgreSQL的autocommit状态,而不通过 default_transaction_isolation 这种间接的方式。
直接查询autocommit的参数在PostgreSQL中是不支持的。因为autocommit实际上不是一个配置参数,而是个概念,是由default_transaction_isolation参数决定的。
没有办法直接用SHOW或者SELECT方式获取autocommit的状态。
之所以我们常用 default_transaction_isolation 来判断,是因为这两个设置在PostgreSQL内部是耦合的:
- read committed 表示关闭了autocommit
- read uncommitted 表示开启了autocommit
所以default_transaction_isolation等于read committed的时候,就可以确定autocommit是关闭的。
四、工作遇到的问题
1. pg报错:unexpected EOF on client connection
在 PostgreSQL 中,“unexpected EOF on client connection” 这个错误通常表示客户端应用程序异常中断了与数据库的连接,导致有一个未完成的打开事务状态。
这种错误的常见原因包括:
- 应用程序进程崩溃或异常退出,没有正常关闭数据库连接。
- 网络连接异常中断。比如网络闪断,客户端机器宕机等。
- 客户端没有正确处理查询超时或者服务器重启的情况。
- 由于编程错误或者资源问题,客户端忘记提交/回滚一个长时间运行的事务。
- 数据库连接泄露,占用了所有可用连接。
当出现这个错误时,该未提交的事务会一直持有锁占用连接,阻塞其他事务,因此需要进行以下处理:
- 检查网络链接情况,确保客户端和数据库服务器网络畅通。
- 检查客户端应用程序代码,确保正确处理超时、事务提交等情况。
- 在数据库端执行以下命令,手动终止该占用连接的事务:
SELECT pg_terminate_backend(pid) FROM pg_stat_activity WHERE state = 'idle in transaction';
你执行这个语句后,处在 idle in transaction 状态的后端进程将被强制终止,相关的事务也会被回滚。
注:pg_terminate_backend() 函数的返回值 ‘t’ 表示终止后端成功。
终止后端进程后,还需要几个后续步骤:
- 再次执行同样的查询,检查是否还有处在 idle in transaction 状态的进程:
SELECT * FROM pg_stat_activity WHERE state = 'idle in transaction';
- 分析日志,找到未提交事务的根本原因,比如编程错误、资源问题等,从代码级别解决问题。
- 合理配置数据库连接池,避免连接泄露。
- 调整数据库配置,适当增大max_connections数值。
2. 报错:sqlalchemy.exc.ArgumentError: autocommit=True is no longer supported
早期版本的 SQLAlchemy 支持在 Engine 创建时设置 autocommit=True,将该引擎设置为自动提交事务模式。但是从版本 1.4 开始,这个参数就不再支持了。
导致这个错误的典型代码如:
engine = create_engine(URL, autocommit=True)
要修复这个错误,需要移除 autocommit 参数,改为手动管理事务:
- 去掉 autocommit=True
engine = create_engine(URL)
- 在代码中手动提交事务:
with engine.begin() as conn:
conn.execute(...)
conn.commit()
- 或者开启自动提交模式:
connection = engine.connect()
connection.autocommit = True
总之,Engine 对象不再支持 autocommit 参数。需要通过上述方式自行控制事务提交。









![解决Error in rawToChar(block[seq_len(ns)]) :](https://img-blog.csdnimg.cn/e3d61a20f58b4f07990207af4f6b683a.png)