学习目标
1.C接口与系统调用接口的差别
2.文件描述符, 重定向, 一切皆文件, 缓冲区
3.fd与FILE, 系统调用和库函数的关系
4.系统中的inode
5.软硬链接
6.动静态库
预备知识
1.文件 = 内容 + 属性
2.文件的所有操作: a. 对内容的操作 b.对属性的操作
3.文件在磁盘(硬件)上, 我们访问文件的过程: 代码 -> 编译->exe->运行
访问文件本质上是谁访问的? 进程
如何访问? 通过调用系统接口
原因: 要向硬件写入内容, 只有OS有权力

访问文件需要调用系统接口
4.之前为什么没听说过
--1.语言上对这些接口做了封装, 让这些接口更好的使用
--2.跨平台性: 如果语言不提供对文件系统接口的封装, 一旦使用系统接口, 编译所谓的文件代码 , 就无法在其它平台上运行
原因: 语言不同, 所写出的代码也不同
解决: 把所有平台的代码都实现一遍, 使用条件编译, 动态裁剪
1.文件描述符
1.1 C语言接口与系统调用接口
C语言接口
1.头文件: #include<stdio.h>
2.相关接口:
FILE * fopen ( const char * filename, const char * mode );
size_t fwrite ( const void * ptr, size_t size, size_t count, FILE * stream );
size_t fread ( void * ptr, size_t size, size_t count, FILE * stream );
int fputs (const char* str, FILE *stream);
int fclose ( FILE * stream );
系统调用接口
1.头文件:#include<sys/types.h> #include<sys/stat.h> #include<fcntl.h>
2.相关接口:
int open(const char *pathname, int flags);
int open(const char *pathname, int flags, mode_t mode);
ssize_t write(int fd, const void *buf, size_t count);
ssize_t read(int fd, const void *buf, size_t count);
int close(int fd);
flags: O_APPEND O_CREATE O_TRUNC等 flags:选项标记位
ssize_t : 表示实际读/写的个数

代码演示

1.2 fd,重定向,一切皆文件,缓冲区
fd
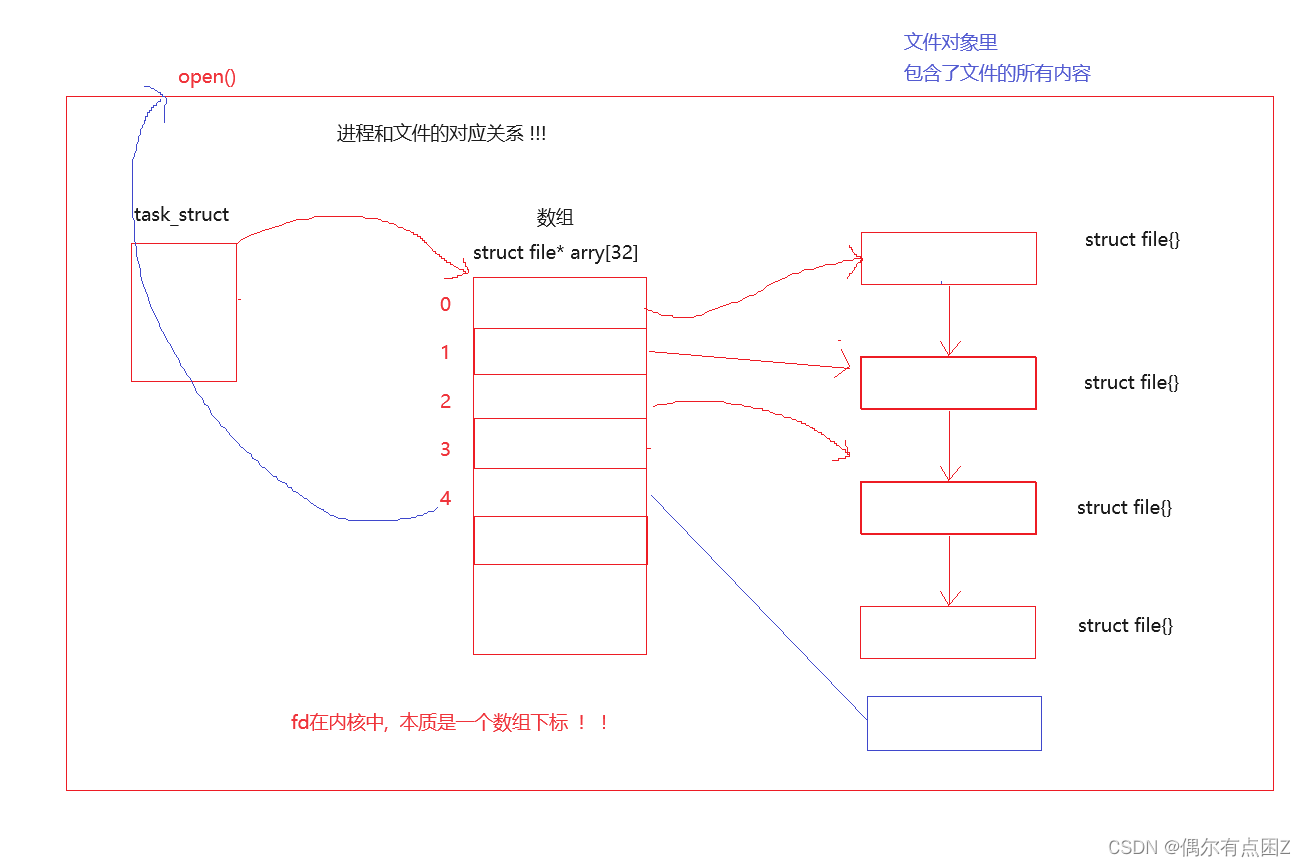
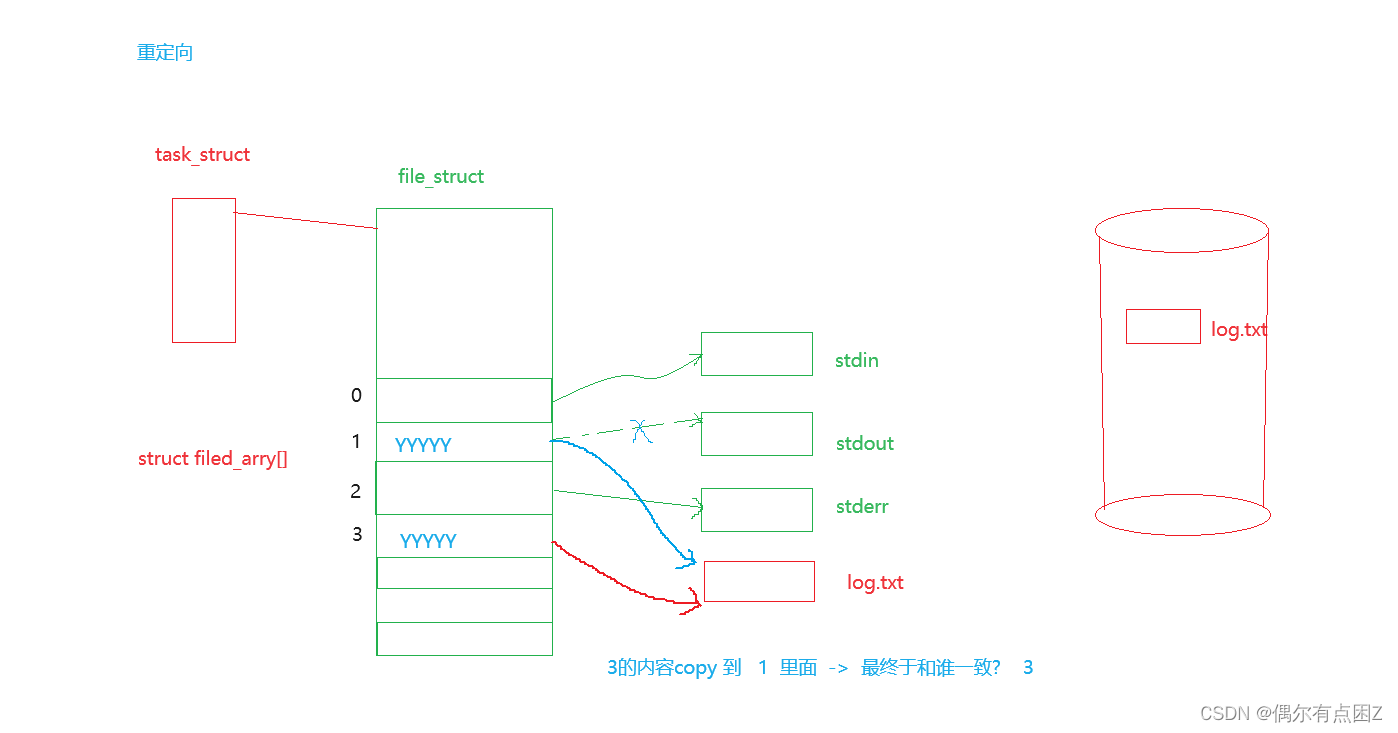
fd: 文件描述符(file descriptor)
本质: 一个数组下标
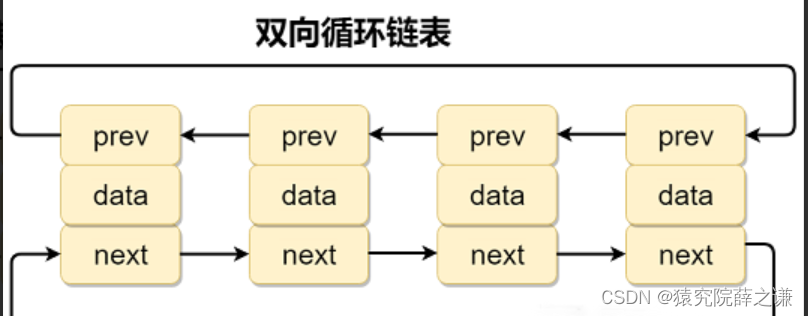
原因: 系统中会存在大量被打开的文件, 系统要管理这些文件, 就将这些文件的内容和属性抽象出来, 构建struct file{} ,创建一个struct file{}对象来充当被打开的文件, 若文件很多,则用双链表链接起来, 方便找到这些文件, 创建一个数组,用来存放这些对象的地址 , 这个数组的下标就叫做文件描述符, 这个数组就叫文件描述符表, 通过文件描述符(下标),我们能在文件描述符表(数组)中找到这个文件对象
fd的分配原则: 最小的, 没有被占用的文件描述符
重定向
1.现象描述: 重定向可以理解为, 本该显示在显示其上的东西, 却显示在了另一个文件当中
2.原理: 文件描述符表中, 文件描述符对应存的地址不再是原来文件的地址, 变为另一个文件的地址了
比如这张图中, 1原来存的是stdout的地址, 变为log.txt的地址, 就会造成,此时执行ls命令, 本该显示再显示其中的东西, 显示再log.txt中了
我们打开一个文件, 向一个文件内里读/写, 是通过文件描述符来找到这个文件的
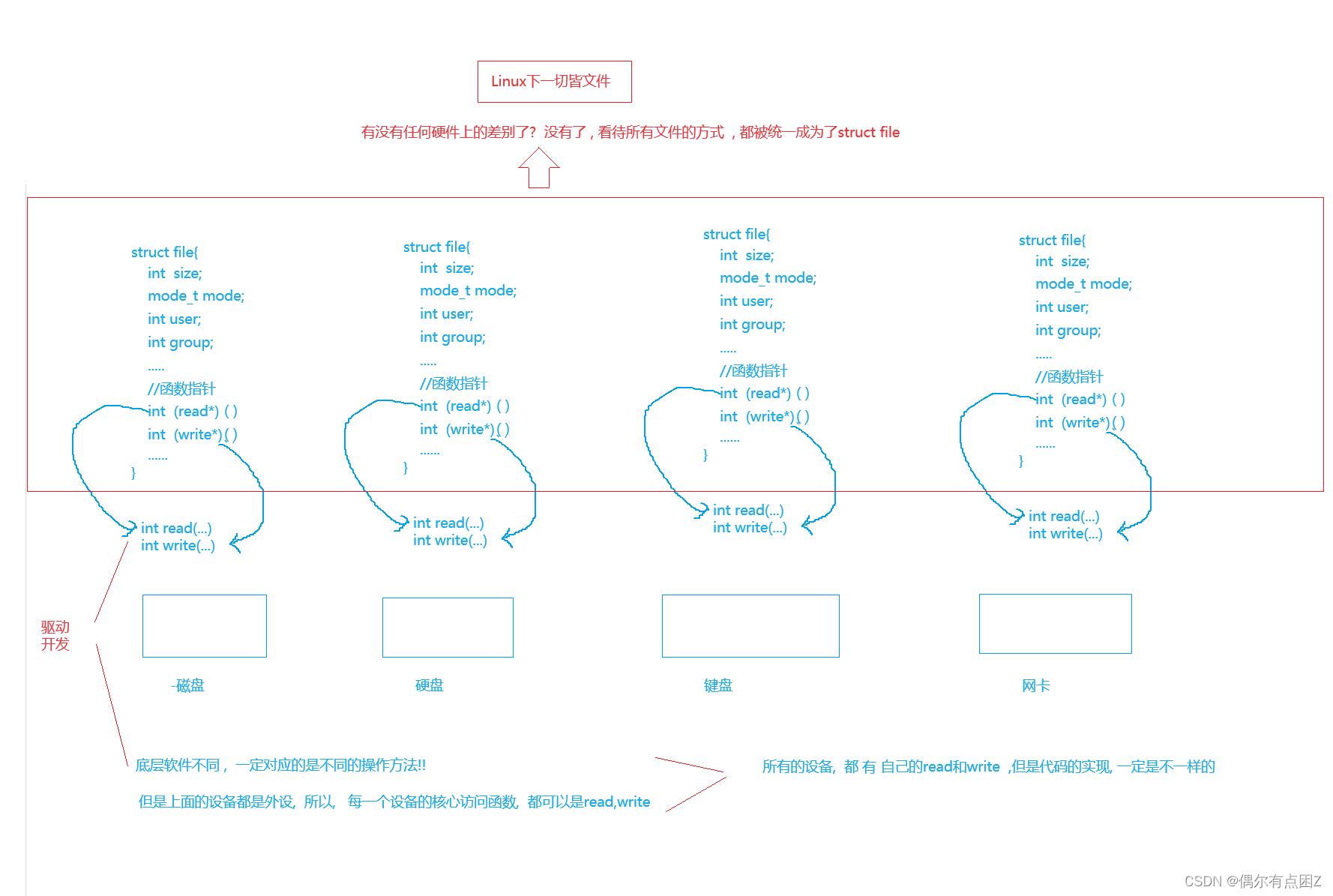
一切皆文件
Linux 设计哲学 --> 体现操作系统的软件设计层面的!
--多态:访问同一种类型的对象, 最后可以表现出不同的行为
Linux C语言写的! 如何使用C语言实现面向对象, 甚至运行时多态?
--构造一个结构体对象, 里面存放文件的共有属性, 对于不同的硬件, 需要采用不同的读写方法, 那么就在结构体中定义函数指针, 指向不同硬件的读写方法.
缓冲区
1.缓冲区是什么? --就是一段内存空间
a.这个空间谁提供? 库
b.缓冲区刷新策略:
--1.立即刷新
--2.行刷新 (\n) ---显示器
--3.满刷新(全缓冲) ---磁盘文件 (效率考量) 可以尽量减少
特殊情况: 1.用户强制刷新(fflush) 2.进程退出
所有的设备永远都倾向于全缓冲的! ---缓冲区满了 , 才刷新 -->需要更少的IO操作 --> 更少次的外设访问
2.为什么要有缓冲区?
--缓冲区可以用来提高性能。
在许多情况下,读写数据时直接访问主存或磁盘可能会很慢,因为这些操作涉及到物理硬件的访问。
通过将数据暂时存储在缓冲区中,可以减少对慢速设备的访问次数,从而提高程序的运行速度。
看下面这段代码:
#include <stdio.h> #include <unistd.h> #include <sys/types.h> #include <sys/stat.h> #include <fcntl.h> //myfile helloworld //int main(int argc, char *argv[]) int main() { // 往显示器上打印 // C语言提供的 printf("hello printf\n"); fprintf(stdout, "hello fprintf\n"); const char *s = "hello fputs\n"; fputs(s, stdout); // OS提供的 const char *ss = "hello write\n"; write(1, ss, strlen(ss)); fork(); //创建子进程 return 0; }运行结果
我们发现同一段程序, 向显示器打印,输出4行文本, 向普通文件(磁盘)打印的时候,变成了7行
--1.C IO接口,是打印了2次 --2.系统接口, 只打印一次和显示器打印一样
原因: 往显示器打印时行刷新, 往普通文件打印, 缓冲区刷新规则转换为全刷新
--往显示器打印, fork之前,缓冲区内的数据已经刷新完, 不发生写时拷贝
--往普通文件打印,fork之前,缓冲区的内数据不刷新, 在进程退出的时候,发生写实拷贝, 代码会拷贝从而打印2次
--系统接口只打印1次, 调用系统接口直接将数据刷新到内核中


stdout与stderr
1和2对应的都是显示器, 但是它们两个是不同的, (同一个显示器被打开了2次)
一般而言:
如果程序有问题, 建议使用stderr或者cerr打印
如果是常规的文本内容, 我们建议进行cout,stdout打印
三种重定向写法:
1 ./myfile > ok.txt 2>err.txt
将正确信息打印到ok.txt中,将错误信息打印到err.txt
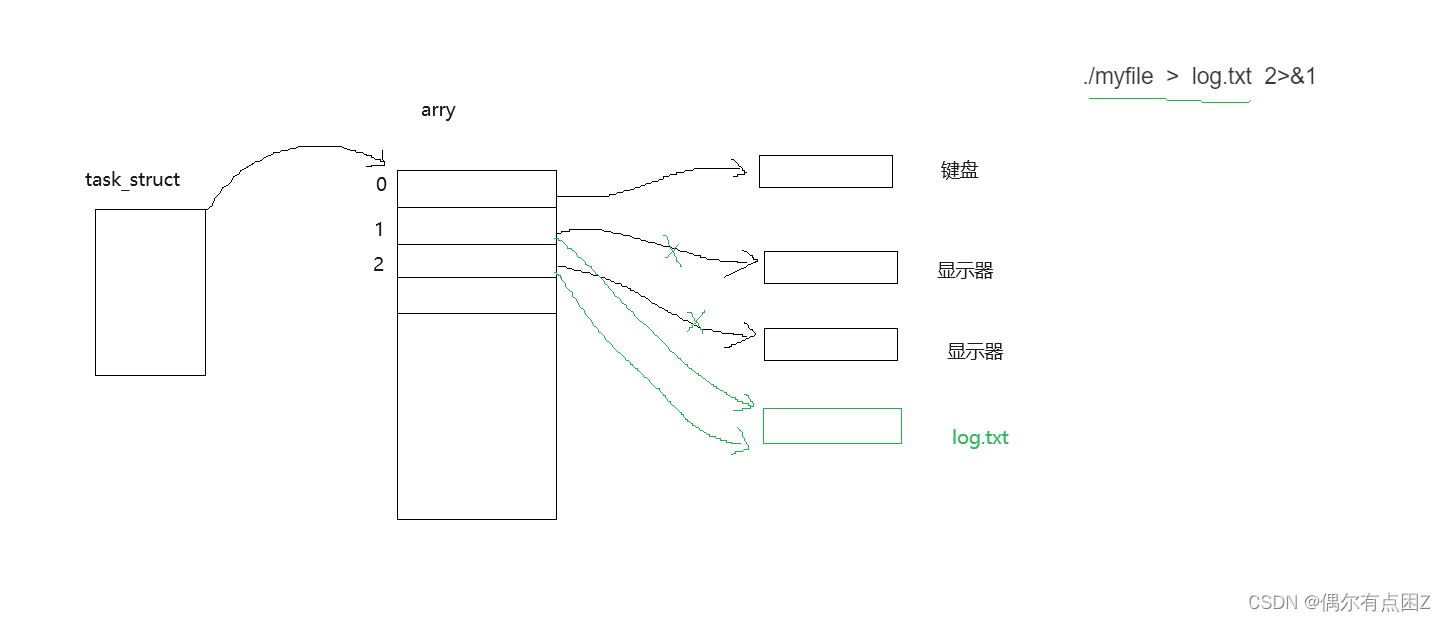
2 ./myfile > log.txt 2>&1
把1,2的信息都打印到log.txt中
3. cat < log.txt > back.txt
把log.txt的数据给cat, 然后把结果重定向到back.txt
1.3 fd与FILE,系统调用与库函数的关系
在进程中 , OS会默认打开stdin, stdout, stderr 对应0 1 2
这里可以看出: 库函数接口是封装后的系统接口

2.文件系统与inode
预备知识
磁盘文件 - 了解磁盘
内存 -- 掉电易失存储介质
磁盘 -- 永久性存储介质 -- SSD, U盘 flash卡 , 光盘 , 磁带
磁盘是一个外设, 还是我们计算机中唯一的一个机械设备 ----慢!!!
磁盘的结构
1.磁盘的物理结构
磁盘盘片. 磁头, 伺服系统, 音圈马达...
2.磁盘的存储结构
在物理上, 如何把数据写入到知道的扇区里?
如何找到一个扇区? CHS寻址
a.在哪一个盘面上?(对应的就是哪一个磁头)Head
b.在哪一个磁道上?(柱面)Cylindar
c.在那一个扇区(512字节)上?Sector
3.磁盘的抽象结构(虚拟,逻辑)
LBA -> CHS
磁盘管理 --> 线性结构管理
分区:


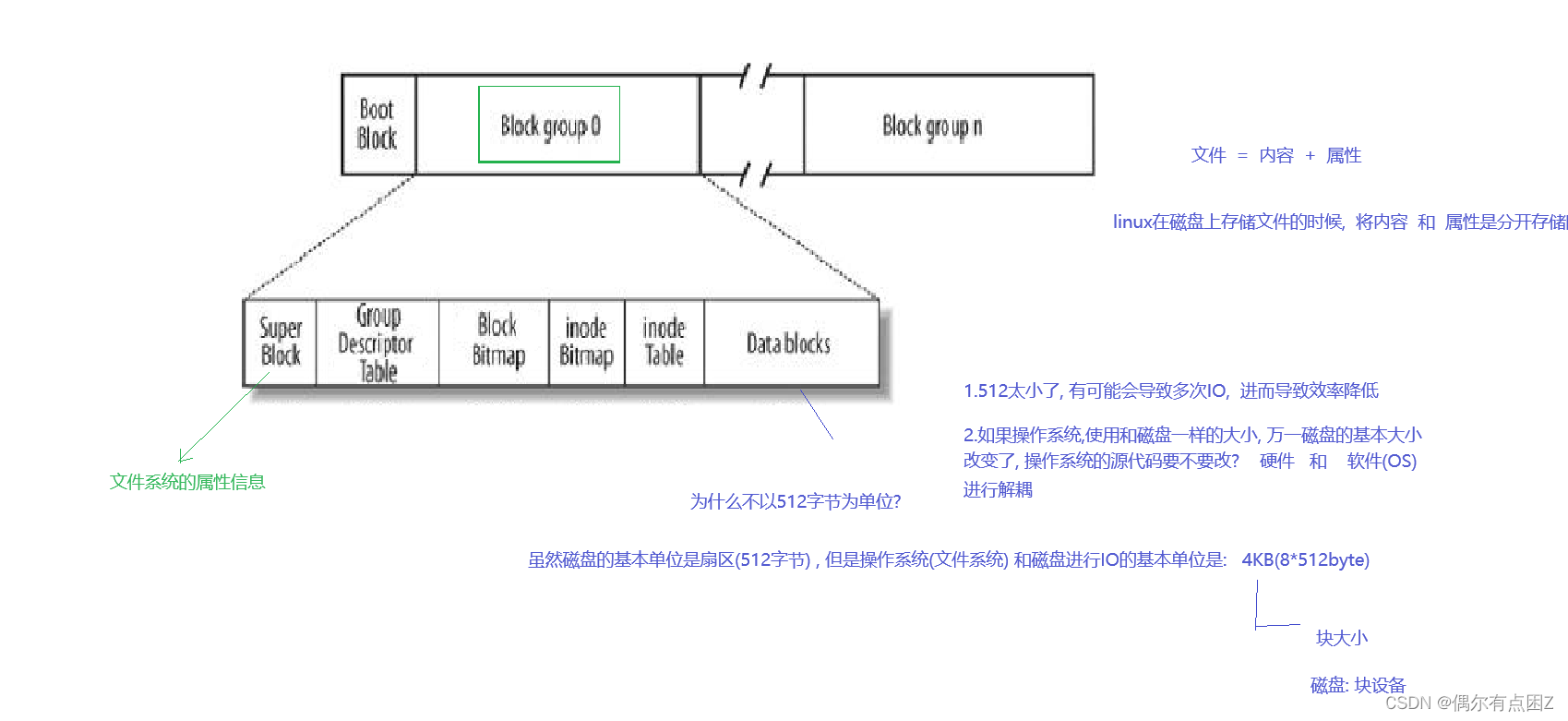
文件系统
块组的基本信息:
这5个信息 , 能够让一个文件的信息可追溯 , 可管理.
我们将块组分割成为上面的内容 , 并且写入相关的管理数据 -> 每一个快组都这么干 -> 整个分区就被写入了文件系统信息 (格式化)

若文件特别大怎么办?
--一个文件对应一个inode节点,inode编号, 但不一定只有一个block
--data block中 , 不是所有的 data block, 只能存文件数据 , 也 可能存其它块的块号

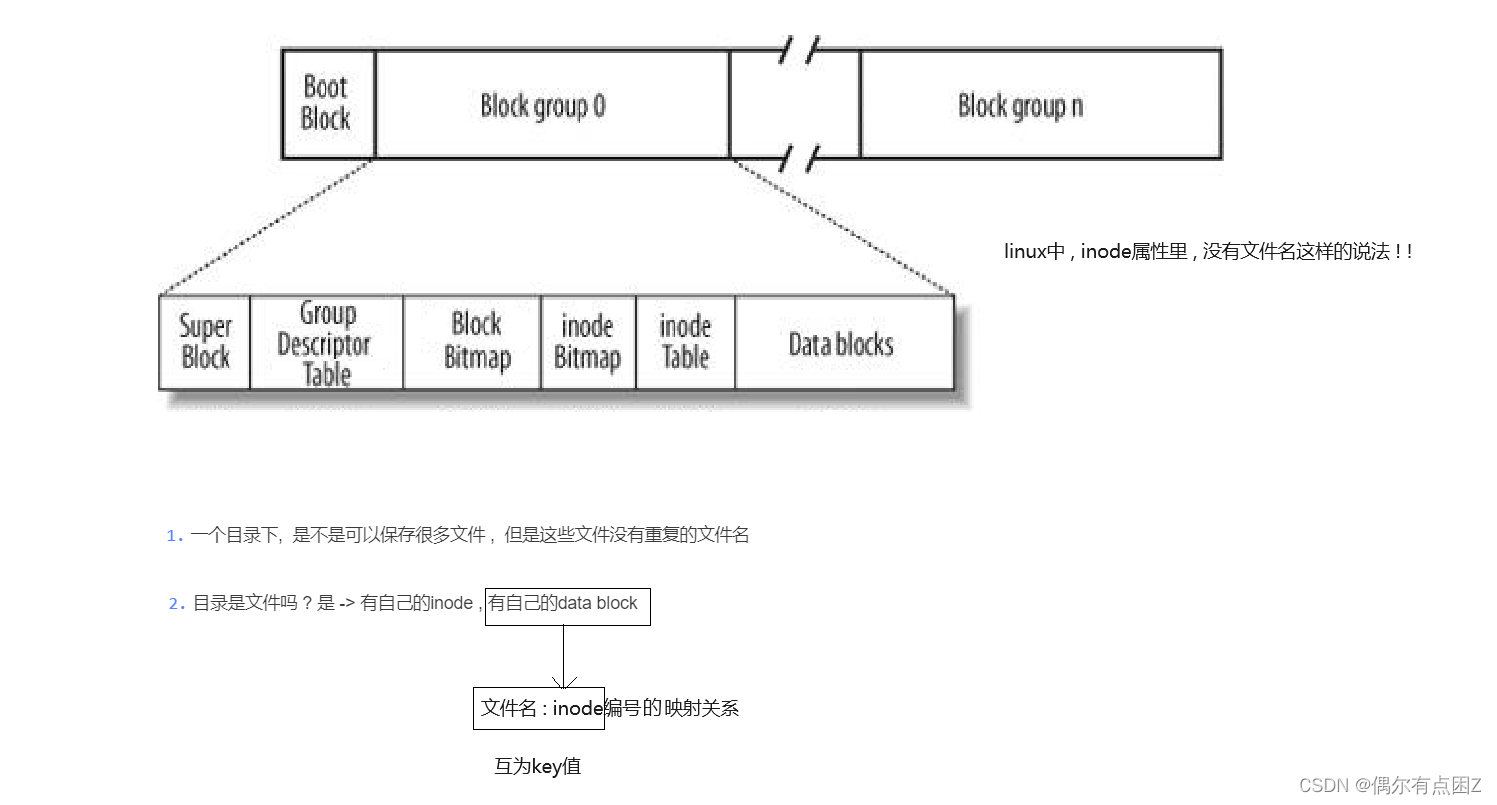
目录
目录也是文件, 有自己的inode,data block
它的data block放的是文件名和inode的映射关系
文件名不会在inode的属性里存在, 放在了目录的内容里
所以我们拿到文件名就可以将其作为key值找到inode, 反之同理 所以创建一个文件需要W权限, 显示文件属性要R权限
inode 与文件名
inode与文件名互为key值
找到文件 : inode编号 -> 分区他的的bg -> inode -> 属性 -> 内容
如何知道inode编号? 依托于目录结构
1.创建文件, 系统做了什么?
2.删除文件, 系统做了什么?
3.查看文件, 系统做了什么?
1.创建文件, 系统做了什么?
--根据文件系统, 在分区当中, 找到目录所在的分区, 块组,
a.在inodebitmap中, 找到第一个为0的比特位, 将其0置为1, 同时我们也拿到了一个inode号 ,
b.在inode表里面, 把新建文件的属性写进去 , (拥有者,所属组...)
c.data blocks : 在后面写的时候,再在block bitmap里面找块, 把数据写道块中, 在建立inode和块的映射关系
用户提供文件名, 文件系统,将文件在内部创建好后, 提供inode
把用户输入的文件名 和 inode 建立映射关系 , 写到目录的内容当中
2.删除文件, 系统做了什么?
-a.找到该目录对于的data block
-b. 以文件名作为索引 ,找到文件对应的inode, 在特定的快组内,根据编号
-c.把对应的inode bitmap由1置为0
-d. 把对应的data block bitmap由1置为0
-e. 把文件名和inode的映射关系去掉
3.查看文件, 系统做了什么?
找到目录 , 找到inode , 找到data block ,将文件名对应的内容显示
软硬链接
1.命令: 软连接 ln -s 链接的文件 起的文件名 (硬链接不 + s)
2.软硬连接有什么本质区别 : 有没有独立的inode
--软连接有独立的inode -> 软连接是一个独立的文件
--硬连接没有独立的inode -> 硬连接不是一个独立的文件
硬链接本质就是对inode内部的一种引用计数, 当这个计数减为0的时候这个文件才会被删除

3.动静态库
- 我如果想写一个库 ? (编写库的人的角度)
- 如果我把库给别人, 别人是怎么用的呢? (使用库的人的角度)
- 为什么要有库? 1.简单 2. 代码安全
自己所写的库是第三方库,
静态库: .a后缀
动态库: .so后缀
生成动静态库
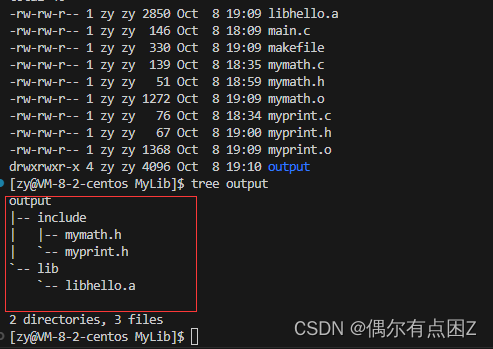
1.生成静态库
Archive files 归档文件 r : replace c : create
命令:
ar -rc lib库名.a mymath.o myprint.o //例如: ar -rc libhello.a mymath.o myprint.oMakefile:
libhello.a:mymath.o myprint.o ar -rc libhello.a mymath.o myprint.o mymath.o:mymath.c gcc -c mymath.c -o mymath.o myprint.o:myprint.c gcc -c myprint.c -o myprint.o .PHONY:output output: mkdir -p output/include mkdir -p output/lib cp -rf *.h output/include cp -rf *.a output/lib .PHONY:clean clean: rm -rf *.a output *.o效果:
2.生成动态库
生成.o文件
gcc -fPIC -c mymath.c -0 mymath.o生成动态库
gcc -shared myprint.o mymath.o libhello.soMakefile
libhello.so:mymath_d.o myprint_d.o gcc -shared mymath_d.o myprint_d.o -o libhello.so mymath_d.o:mymath.c gcc -c -fPIC mymath.c -o mymath_d.o myprint_d.o:myprint.c gcc -c -fPIC myprint.c -o myprint_d.o .PHONY:output output: mkdir -p output/include mkdir -p output/lib cp -rf *.h output/include cp -rf *.so output/lib .PHONY:clean clean: rm -rf output *.o *.out *.so效果:

3.同时生成动静态库
构造一个伪目标all
.PHONY:all all:libhello.so libhello.a libhello.so:mymath_d.o myprint_d.o gcc -shared mymath_d.o myprint_d.o -o libhello.so mymath_d.o:mymath.c gcc -c -fPIC mymath.c -o mymath_d.o myprint_d.o:myprint.c gcc -c -fPIC myprint.c -o myprint_d.o libhello.a:mymath.o myprint.o ar -rc libhello.a mymath.o myprint.o mymath.o:mymath.c gcc -c mymath.c -o mymath.o myprint.o:myprint.c gcc -c myprint.c -o myprint.o .PHONY:output output: mkdir -p output/include mkdir -p output/lib cp -rf *.h output/include cp -rf *.so output/lib cp -rf *.a output/lib .PHONY:clean clean: rm -rf *.a output *.o *.out效果:

使用动静态库
- 头文件gcc的默认搜索路径是 : /usr/include
- 库文件的默认搜索路径是: /lib64 or /usr/lib64
使用动静态库规则: 当动静态库同时存在时, 默认优先使用动态库
1.使用静态库
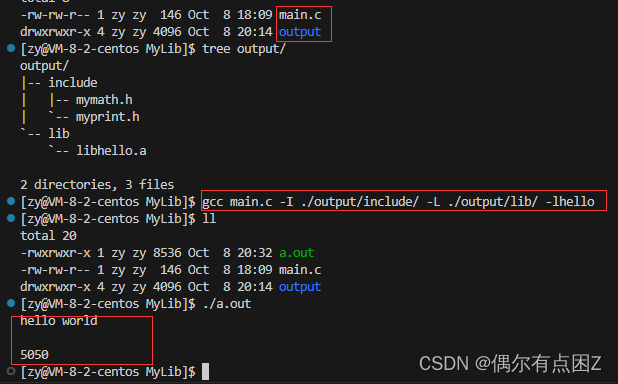
方法一: 告诉gcc头文件和库的路径在那
命令:
gcc main.c -I ./output/include/ -L ./output/lib/ -lhello-I: include (头文件) -L: lib(库) -lhello -l(link),去掉前缀lib,后缀.a
效果:

方法二:拷贝库到系统下
命令:
sudo cp output/include/* /usr/include //拷贝头文件 sudo cp output/lib/libhello.a /lib64 //拷贝静态库效果:
但不建议这么做: 避免自己写的文件, 污染系统库
上面将库拷贝到系统库就叫做库的安装
2.使用动态库
问题引入
这里执行的命令和运行静态库的命令一样, 但是运行的时候报错了 说没有这个文件
说明当动静态库同时存在的时候, 默认优先使用动态库
原因: 我们是在编译的时候, 告诉gcc库的路径在哪, 运行加载的时候并没有告诉系统在哪
解决方法: 1.使用静态库 2. 配置环境变量


方法一: 加static
static的意义: 摒弃优先使用动态库的原则, 使用静态库
命令:
gcc main.c -I ./output/include/ -L ./output/lib/ -lhello -static效果:

方法二: 配置环境变量 LD_LIBRARY_PATH
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:绝对路径(不用带库名)效果;
缺点:重新登陆后失效
原因: 这是内存级的环境变量 重新登陆后LD_LIBRARY_PATH, 会在系统配置文件里再去拿
,会把之前的环境变量清掉



方法三:修改配置文件
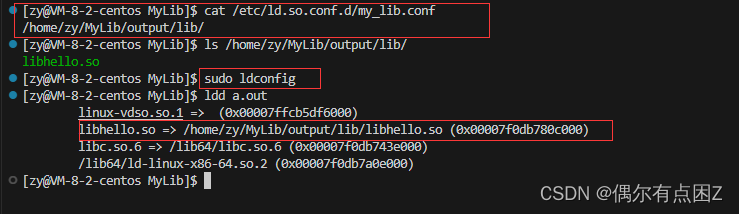
ldconfig 配置/etc/ld.so.conf.d/,ldconfig更新
sudo touch /etc/ld.so.conf.d/文件名.conf //创建文件 sudo vim /etc/ld.so.conf.d/文件名.conf //然后把库的路径放进去就行1.创建文件,并将路径写到文件中
2.sudo ldconfig更新一下
效果:
删除:
sudo rm /etc/ld.so.conf.d/文件名.conf sudo ldconfig

方法四:软链接添加到系统默认路径(不推荐)
sudo ln -s 动态库路径(绝对,带上库) /lib64/libhello.so(库名)删除:
sudo unlink /lib64/库名