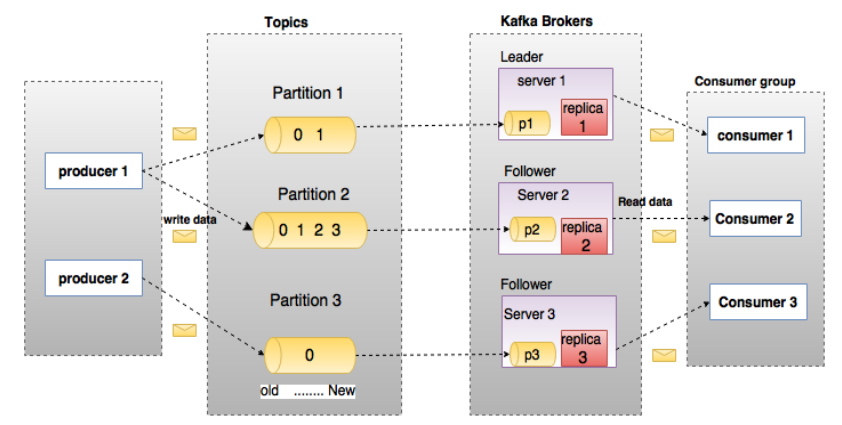
本节内容以刷题为主,大致目录:
1.一维数组
2.字符数组
3.二维数组
学完后,你将对数组有了更全面的认识
在刷关于数组的题目前,我们先认识一下数组名:
数组名的意义:表示数组首元素的地址
但是有两个例外:
(1)sizeof(数组名),这里的数组名表示整个数组,计算的是整个数组的大小。单位:字节。
(2)&数组名,这里的数组名表示整个数组,取出的是整个数组的大小。
一、一维数组
1.判断下列sizeof计算的大小
(1)一维数组
#include<stdio.h>
int main()
{
int a[] = { 1,2,3,4 };//一维数组
printf("%zd\n", sizeof(a));
printf("%zd\n", sizeof(a + 0));
printf("%zd\n", sizeof(*a));
printf("%zd\n", sizeof(a + 1));
printf("%zd\n", sizeof(a[1]));
printf("%zd\n", sizeof(&a));
printf("%zd\n", sizeof(*&a));
printf("%zd\n", sizeof(&a + 1));
printf("%zd\n", sizeof(&a[0]));
printf("%zd\n", sizeof(&a[0] + 1));
return 0;
}结果展示:

代码分析:
#include<stdio.h>
int main()
{
int a[] = { 1,2,3,4 };//一维数组
//整形数组,每个元素4个字节,整个数组为16字节
printf("%zd\n", sizeof(a));
//数组名直接放在sizeof内部,表示整个数组的大小
printf("%zd\n", sizeof(a + 0));
//数组名没有单独放在sizeof内部,表示数组首元素的地址。大小就是4/8字节
printf("%zd\n", sizeof(*a));
//a就是首元素地址。*a==*(a+0)==a[0];所以*a就算首元素,大小为4字节
printf("%zd\n", sizeof(a + 1));
//a为首元素地址,+1跳过一个元素的地址,就算第二个元素的地址。a+1==&a[1]
//只要是地址,就算4/8字节
printf("%zd\n", sizeof(a[1]));
//a[1]表示第二个元素,大小就是4字节
printf("%zd\n", sizeof(&a));
//&a,取出的是地址,只要是地址,就是4/8字节
printf("%zd\n", sizeof(*&a));
//*与&操作相互抵消。sizeof(*&a)==sizeof(a),为整个数组元素的大小==16字节
printf("%zd\n", sizeof(&a + 1));
//&a的结果是地址,+1操作后还是地址,那就是4/8字节
printf("%zd\n", sizeof(&a[0]));
//a[0]是第一个元素,&a[0]表示取出第一个元素的地址,地址就算4/8字节
printf("%zd\n", sizeof(&a[0] + 1));
//&a[0]是首元素的地址,&a[0]+1就是第二个元素的地址,大小4/8个字节
return 0;
} 内存分局图:
总结:只要可以确定是地址,那么大小一定就是4/8字节
(2)字符数组
#include<stdio.h>
int main()
{
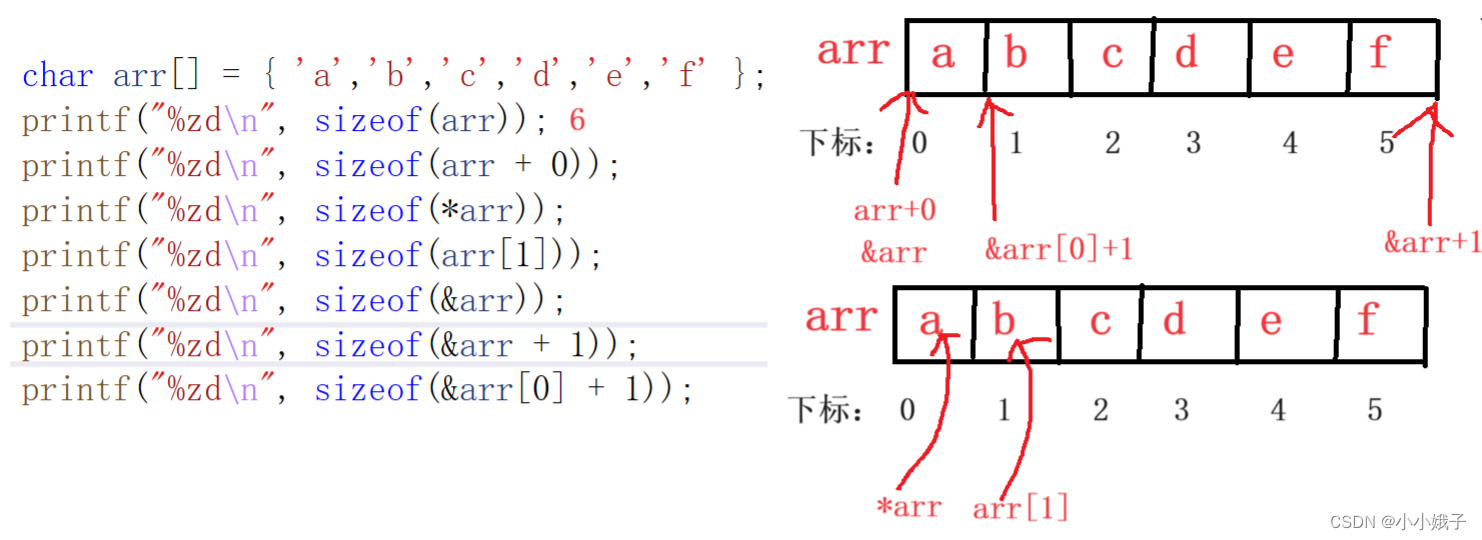
char arr[] = { 'a','b','c','d','e','f' };
printf("%zd\n", sizeof(arr));
printf("%zd\n", sizeof(arr + 0));
printf("%zd\n", sizeof(*arr));
printf("%zd\n", sizeof(arr[1]));
printf("%zd\n", sizeof(&arr));
printf("%zd\n", sizeof(&arr + 1));
printf("%zd\n", sizeof(&arr[0] + 1));
return 0;
}结果展示:

代码分析:
#include<stdio.h>
int main()
{
char arr[] = { 'a','b','c','d','e','f' };
//字符数组,每个元素大小1字节,整个数组大小6字节
printf("%zd\n", sizeof(arr));
//计算的是整个数组的大小,为6字节
printf("%zd\n", sizeof(arr + 0));
//计算的是地址,大小为4/8字节
printf("%zd\n", sizeof(*arr));
//*arr为第一个元素,大小为1字节
printf("%zd\n", sizeof(arr[1]));
//arr[1]表示第二个元素,大小为1字节
printf("%zd\n", sizeof(&arr));
//地址,4/8字节
printf("%zd\n", sizeof(&arr + 1));
//地址,4/8字节
printf("%zd\n", sizeof(&arr[0] + 1));
//地址,4/8字节
return 0;
}内存布局图:
(3)字符串数组
#include<stdio.h>
int main()
{
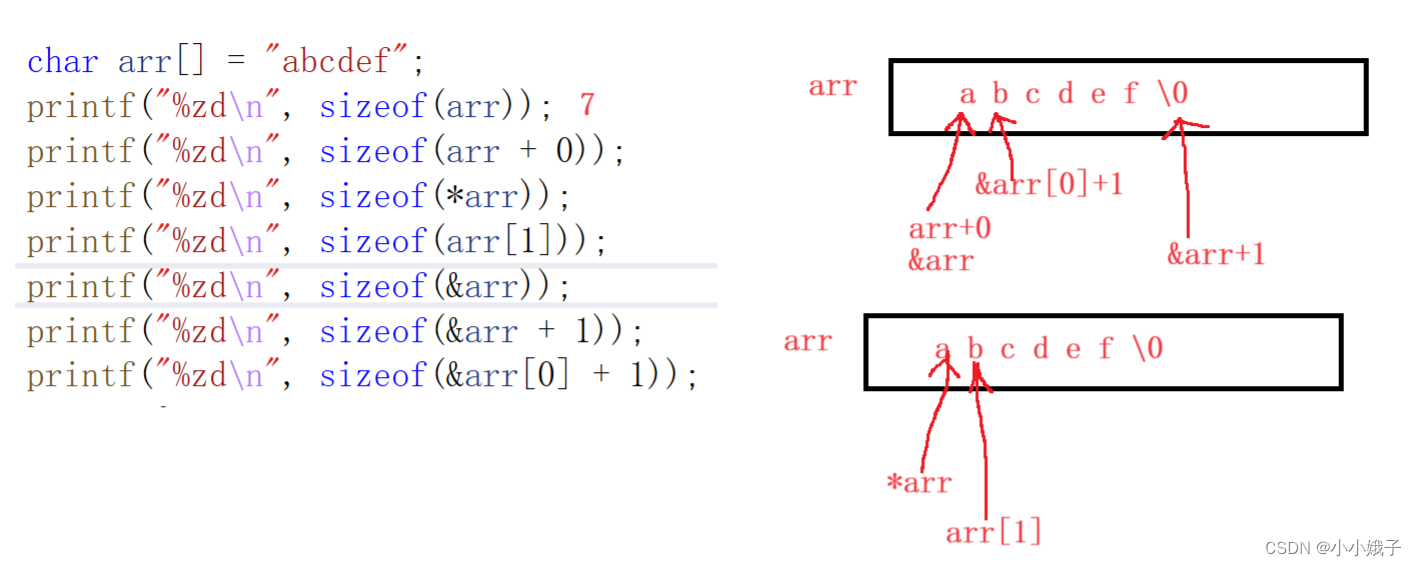
char arr[] = "abcdef";
printf("%zd\n", sizeof(arr));
printf("%zd\n", sizeof(arr + 0));
printf("%zd\n", sizeof(*arr));
printf("%zd\n", sizeof(arr[1]));
printf("%zd\n", sizeof(&arr));
printf("%zd\n", sizeof(&arr + 1));
printf("%zd\n", sizeof(&arr[0] + 1));
return 0;
}结果展示:
代码分析:
#include<stdio.h>
int main()
{
char arr[] = "abcdef";
//arr中的内容:a,b,c,d,e,f,\0
printf("%zd\n", sizeof(arr));
//整个数组大小:7字节
printf("%zd\n", sizeof(arr + 0));
//地址,4/8字节
printf("%zd\n", sizeof(*arr));
//首元素,1字节大小
printf("%zd\n", sizeof(arr[1]));
//第二个元素,1字节大小
printf("%zd\n", sizeof(&arr));
//地址,4/8字节
printf("%zd\n", sizeof(&arr + 1));
//地址,4/8字节
printf("%zd\n", sizeof(&arr[0] + 1));
//地址。4/8字节
return 0;
}内存分布图:
(4)单单字符串
char *p = "abcdef";
printf("%zd\n", sizeof(p));
printf("%zd\n", sizeof(p+1));
printf("%zd\n", sizeof(*p));
printf("%zd\n", sizeof(p[0]));
printf("%zd\n", sizeof(&p));
printf("%zd\n", sizeof(&p+1));
printf("%zd\n", sizeof(&p[0]+1));结果展示:

代码分析:
#include<stdio.h>
int main()
{
char* p = "abcdef";
//p指向a的地址
printf("%zd\n", sizeof(p));
//p是指针,存放首字符a的地址,4/8字节
printf("%zd\n", sizeof(p + 1));
//p+1为字符b的地址,4/8字节
printf("%zd\n", sizeof(*p));
//*p==p[0],拿到的是第一个字符:a,为1字节
printf("%zd\n", sizeof(p[0]));
//求的是字符的大小,1字节
printf("%zd\n", sizeof(&p));
//地址,4/8字节
printf("%zd\n", sizeof(&p + 1));
//地址,4/8字节
printf("%zd\n", sizeof(&p[0] + 1));
//地址,4/8字节
return 0;
}内存分布图:

2.判断下列strlen计算的大小
知识点:strlen是计算字符串的长度(个数)的函数。统计的是在字符串中\0之前出现的字符的个数
(1)不带\0的字符数组
#include<stdio.h>
#include<string.h>
int main()
{
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr + 0));
printf("%d\n", strlen(*arr));
printf("%d\n", strlen(arr[1]));
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr + 1));
printf("%d\n", strlen(&arr[0] + 1));
return 0;
}因为\0是strlen结束的标志,没有\0则不能正常计算
所以准确的来说,上述代码都是错误的。
错误原因解析:
#include<stdio.h>
#include<string.h>
int main()
{
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", strlen(arr));
//随机值。地址
printf("%d\n", strlen(arr + 0));
//随机值。地址
printf("%d\n", strlen(*arr));
//非法访问地址,代码错误
printf("%d\n", strlen(arr[1]));
//非法访问地址,错误代码
printf("%d\n", strlen(&arr));
//随机值。地址
printf("%d\n", strlen(&arr + 1));
//随机值。地址
printf("%d\n", strlen(&arr[0] + 1));
//随机值。地址
return 0;
}内存分布图:
(2)自带\0的字符串数组
#include<stdio.h>
#include<string.h>
int main()
{
char arr[] = "abcdef";
printf("%d\n", strlen(arr));
printf("%d\n", strlen(arr + 0));
printf("%d\n", strlen(*arr));
printf("%d\n", strlen(arr[1]));
printf("%d\n", strlen(&arr));
printf("%d\n", strlen(&arr + 1));
printf("%d\n", strlen(&arr[0] + 1));
return 0;
}
代码分析:
#include<stdio.h>
#include<string.h>
int main()
{
char arr[] = "abcdef";
//arr中的数据:a,b,c,d,e,f,\0
printf("%d\n", strlen(arr));
//从起始位置开始计算长度,为6
printf("%d\n", strlen(arr + 0));
//从起始位置开始计算长度,为6
printf("%d\n", strlen(*arr));
//*arr==a,传入的值就为97,代码报错
printf("%d\n", strlen(arr[1]));
//arr[1]==b,传入的值为98,代码错误
printf("%d\n", strlen(&arr));
//从起始位置开始计算,长度为6
printf("%d\n", strlen(&arr + 1));
//&arr为起始地址,&arr+1跳过了整个数组,为随机值
printf("%d\n", strlen(&arr[0] + 1));
//从第二个元素开始,为5
return 0;
}
内存分布图:

(3)带\0的纯字符串
#include<stdio.h>
#include<string.h>
int main()
{
char* p = "abcdef";
printf("%d\n", strlen(p));
printf("%d\n", strlen(p + 1));
printf("%d\n", strlen(*p));
printf("%d\n", strlen(p[0]));
printf("%d\n", strlen(&p));
printf("%d\n", strlen(&p + 1));
printf("%d\n", strlen(&p[0] + 1));
return 0;
}
代码分析:
#include<stdio.h>
#include<string.h>
int main()
{
char* p = "abcdef";
printf("%d\n", strlen(p));
//从起始位置开始计算长度,为6
printf("%d\n", strlen(p + 1));
//从b位置开始计算长度,为5
printf("%d\n", strlen(*p));
//*p==a,传入97,代码报错
printf("%d\n", strlen(p[0]));
//代码报错
printf("%d\n", strlen(&p));
//&p为指针变量的地址,为随机值
printf("%d\n", strlen(&p + 1));
//&p+1跳过了该字符串,为随机值
printf("%d\n", strlen(&p[0] + 1));
//从b位置开始计算,长度为5
return 0;
}内存分布图:

二、二维数组
前言:二维数组的数组名同样是首元素地址,不过二维数组的首元素是第一行元素;而且依旧有两个例外。
题目:判断下列sizeof计算的大小
#include<stdio.h>
int main()
{
int a[3][4] = { 0 };
printf("%zd\n", sizeof(a));
printf("%zd\n", sizeof(a[0][0]));
printf("%zd\n", sizeof(a[0]));
printf("%zd\n", sizeof(a[0] + 1));
printf("%zd\n", sizeof(*(a[0] + 1)));
printf("%zd\n", sizeof(a + 1));
printf("%zd\n", sizeof(*(a + 1)));
printf("%zd\n", sizeof(&a[0] + 1));
printf("%zd\n", sizeof(*(&a[0] + 1)));
printf("%zd\n", sizeof(*a));
printf("%zd\n", sizeof(a[3]));
return 0;
}运行结果:
代码分析:
#include<stdio.h>
int main()
{
int a[3][4] = { 0 };
//三行四列,一行的大小是12,整个数组是48
printf("%zd\n", sizeof(a));
//数组名单独放在里面,计算的是整个数组的大小
printf("%zd\n", sizeof(a[0][0]));
//a[0][0]表示第一行第一列的元素,计算的是元素的大小,4字节
printf("%zd\n", sizeof(a[0]));
//a[0]表示第一行的地址,也可以称为第一行这个数组的数组名
//sizeof(arr[0])计算的就是第一行整个一维数组的全部大小,16字节
printf("%zd\n", sizeof(a[0] + 1));
//a[0]没有单独存放,a[0]==&a[0][0],也表示第一行第一个元素的地址
//所以a[0]+1==&a[0][1],地址就是:4/8字节
printf("%zd\n", sizeof(*(a[0] + 1)));
//a[0]+1为第二行元素的数组名,也是第二行元素的首元素,4字节
printf("%zd\n", sizeof(a + 1));
//a没有单独放在sizeof内部,所以表示第一行的地址
//所以a+1是第二行的地址,4/8字节
printf("%zd\n", sizeof(*(a + 1)));
//a+1为第二行的地址,*(a+1)就是第二行
//*(a+1)==a[1],第二行元素的总大小=4*4=16
printf("%zd\n", sizeof(&a[0] + 1));
//&a[0]是第一行的地址,&a[0]+1是第二行的地址
//地址就是4/8字节
printf("%zd\n", sizeof(*(&a[0] + 1)));
//*(&a[0]+1)==a[1],计算的是第二行元素的大小,为16字节
printf("%zd\n", sizeof(*a));
//a没有单独放在sizeof内部,所以是第一行的地址
//*a==a[0],计算的是第一行的元素,为16字节
printf("%zd\n", sizeof(a[3]));
//a[3]表示第四行元素,但是没有第四行元素
//sizeof计算的只是类型大小,a[3]和a[0]或a[1]一样,都表示某一行元素
//虽然没有第四行,但是跟a[0]的类型一样,都是四个int元素的数组
return 0;
}内存布局图:
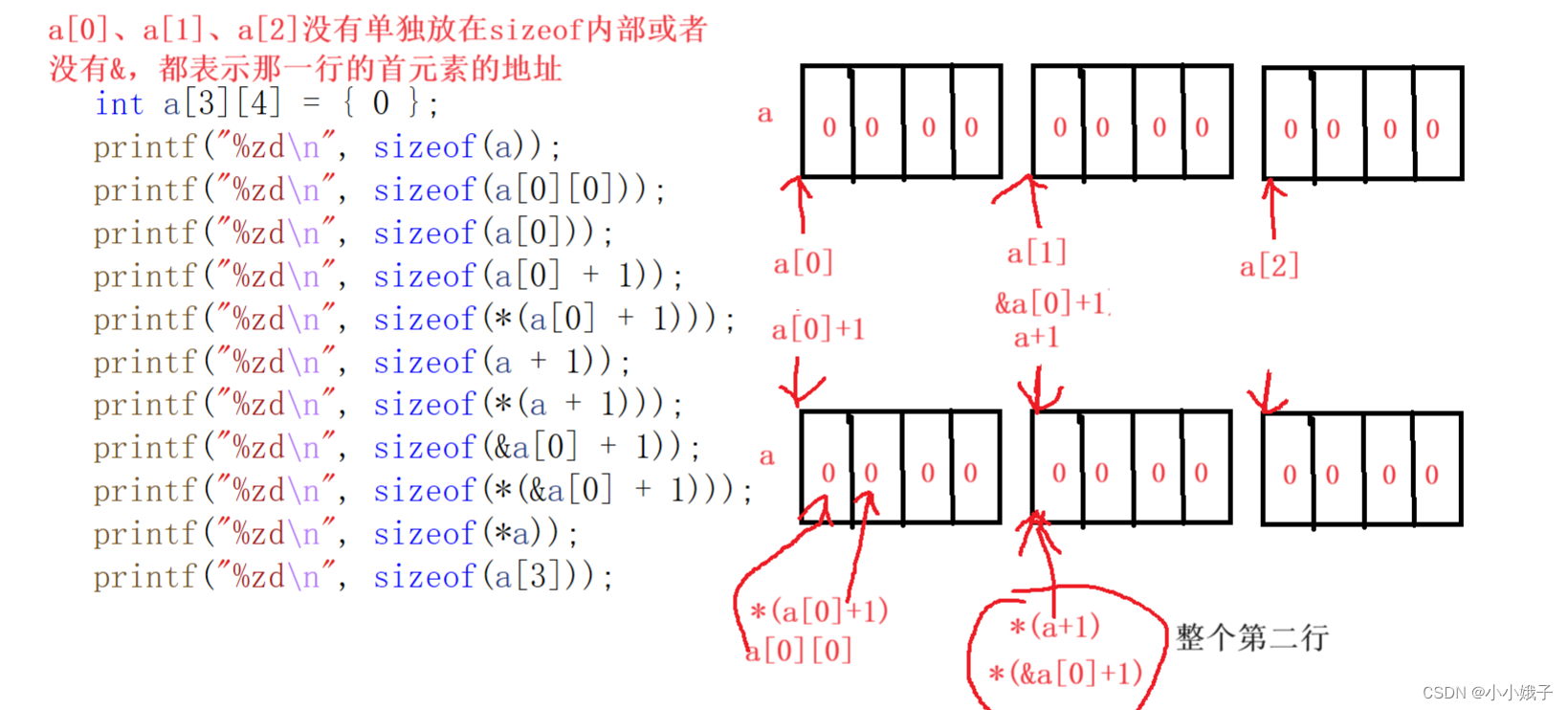
总结:有二维数组a[3][4]
(1)a、a[0]、a[1]、a[2]都表示数组名
(2)a是二维数组的数组名,a[0]、a[1]、a[2]分别是第一、二、三行的数组名。
(3)第一、第二和第三行数组又可以称为一个一维数组
(4)a、a[0]、a[1]、a[2]单独放在sizeof内部或者&数组名,就表示整个数组
(5)没有像(4)那种,a、a[0]、a[1]、a[2]就表示首元素的地址