信息检索主要是查找与用户查询相关的文档。
给定:大型静态文档集合 和信息需求(基于关键字的查询)
任务:查找所有且仅与查询相关的文档
典型的 IR 系统:
• 搜索一组摘要
• 搜索报纸文章
• 图书馆搜索
• 搜索网络
通常比语言有更多的统计数据,但要检索和处理的对象是语言
信息索引的几个方法
索引是找到很好地描述文档的术语的任务
• 手动:人工索引(使用固定词汇),劳动和培训密集
• 自动:术语操纵(某些单词算作相同的术语),术语加权(某些术语比其他术语更重要),自动从文本提取索引
对于大词汇表的信息索引(数千项)
Dewey Decimal System 杜威十进制系统
Library of Congress Subject Headings 国会图书馆主题词
ACM – subfields of CS
MeSH – Medical Subject Headings
MeSH — Medical Subject Headings 医学主题词,是一个非常大的受控词汇表,用于描述/索引医学文档,例如期刊论文和书籍。提供一些相关的主题词,用于分配给文档以描述其内容,层次结构有许多top-level 类别,例如 Anatomy [A],Organisms [B],Diseases [C],Chemicals and Drugs [D],Analytical, Diagnostic and Therapeutic Techniques and Equipment [E], Psychiatry and Psychology [F], Biological Sciences [G]
MEDLINE — Medical Literature Analysis and Retrieval System Online 在线医学文献分析和检索系统
每篇 MEDLINE 文章都使用 MeSH 中的 10-15 个描述符进行索引
对于手动索引
• 优点:
高精度搜索
适用于封闭式馆藏(图书馆中的书籍)
• 缺点:
搜索者需要了解术语以实现高精度
标签制作者需要接受培训以实现一致性,期望网络上的所有内容创建者都这样做是不可行的
收藏是动态的,因此方案不断变化
自动索引没有预定义的索引术语集,相反会使用自然语言作为索引语言,并且文档中的单词提供有关其内容的信息
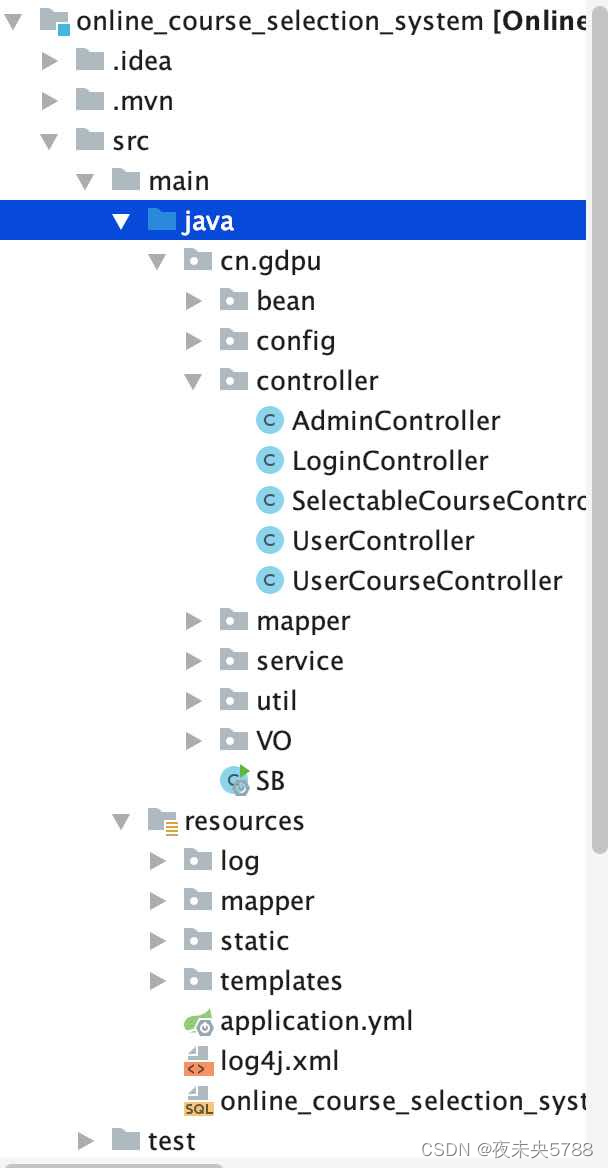
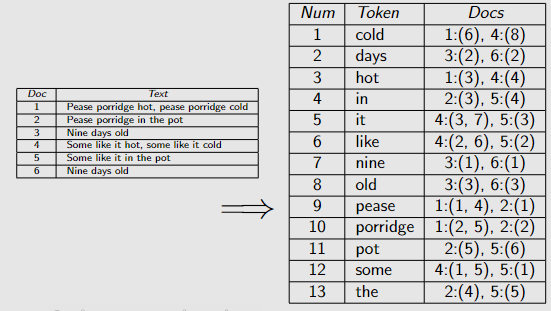
自动索引的实现:倒排文件,Google 的 IR 系统就是这么做的
每个术语的记录,它出现的文档的 ID ,只在它出现或不出现时才重要,而不是出现了多少次。
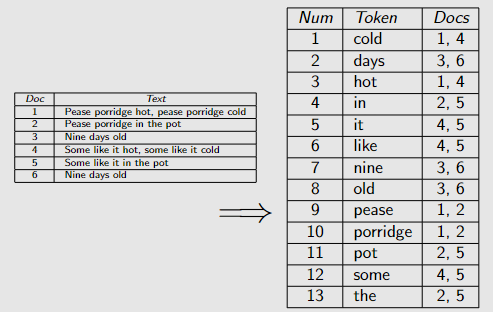
一些更复杂的版本是
还记录了每个文档中出现的次数,这能帮助查找与查询更相关的文档。
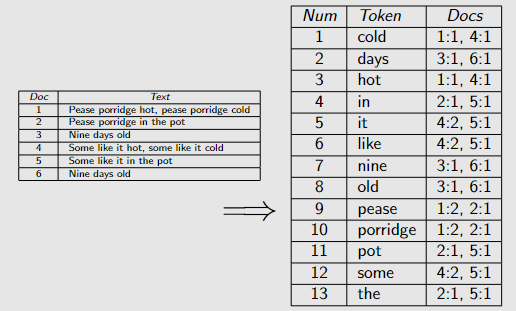
还记录文档中每个术语出现的位置,可能有助于在文档中搜索短语。
自动信息检索模型
布尔搜索:
用了二元决策比如文档相关与否
术语的存在对于匹配是必要且充分的
布尔运算符是集合运算(AND,OR)
方法:通过使用布尔运算符组合,基本搜索关键字来构建复杂的搜索命令
布尔运算符AND, OR, NOT, BUT, XOR 等
布尔查询为决定是否应返回任何文档提供了一个简单的逻辑基础,参考了两点:查询的基本术语是否出现在文档中和其中逻辑运算符的含义
布尔运算符具有有效检索的集合论解释,整体文档集合构成最大文档集
该模型经常被书目搜索引擎,例如图书馆使用
但是对大多数用户不利因为:
大多数用户不熟悉编写布尔查询 → 不自然
大多数用户不想费力地浏览 1000 个未排序的结果列表 → 除非在小集合中进行非常具体的搜索
对于网络搜索影响尤其大 → 大集合文档
排序检索方法
会用到文档术语的频率,并非所有搜索词都必须出现在文档中
比如:
向量空间模型(SMART,Salton 等人,1971 年)
概率模型(OKAPI,Robertson/Sp ̈arck Jones,1976 年)
网络搜索引擎
向量空间模型的文档是高维向量空间中的点,索引中的每个术语都是一个维度。值是文档中术语的频率,或频率的变体。
查询方法,将查询向量与每个文档的向量进行比较
选择文档-查询相似度最高的文档。根据与查询的相似性对文档进行排名。使用排名,返回文档的数量不太相关,用户从顶部开始,在满意时停。
对于不同长度的向量,欧几里得距离值很大,即使只有一个项(例如 Doc2 和 Q),这表示项的频率的影响太大。
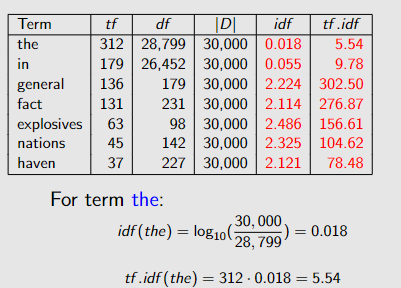
除此之外经常会用cosine相似度
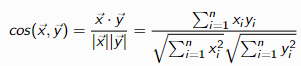
信息检索的预处理
通常只使用单词,但要对它们进行预处理以进行泛化,Tokenisation,Capitalisation,Lemmatisation,Stemming,Normalisation
Tokenisation: 从标点符号中拆分单词(去掉标点符号)
大写:将所有单词标准化为小写(或大写)
词形还原:将一个词的不同变形形式合并为它们的基本形式(单数、现在时、第一人称)
词干提取:通过切断词缀来合并词法变体
规范化:合并因为拼写、连字符、空格出现的一些变体
使用停止列表删除来排除非内容词
为了帮助识别短语,可能允许使用多词术语,或者允许多词索引。备选方案:在检索过程中识别多词短语位置索引,在文档中存储术语的位置。
词权重
二进制权重 - 0/1:文档中是否存在术语,但是多次出现查询关键字的文档可能更相关
document collection D collection (set) of documents 文档集
size of collection |D| total number of documents in collection 集合中的文档总数
term freq tfw ,d number of times w occurs in document d w 在文档 d 中出现的次数
collection freq cfw number of times w occurs in collection w 在集合中出现的次数
document freq dfw number of documents containing w 包含 w 的文档数
信息量与(文档)频率成反比,不太常见的术语对查找相关文档更有用的想法
计算方法为 size of collection / term freq
Inverse document frequency (idf) 是log(size of collection / term freq)

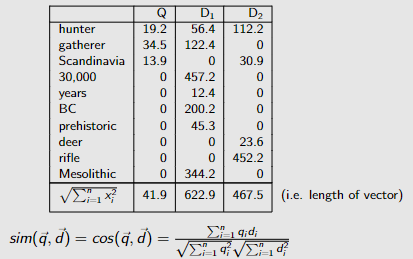
cos(Q, D1) = (19.2 ∗ 56.4) + (34.5 ∗ 122.4) + · · · + (0 ∗ 0) + (0 ∗ 344.2)/(41.9 ∗ 622.9)
= 5305.68/26071.72 = 0.20
cos(Q, D2) = (19.2 ∗ 112.2) + (34.5 ∗ 0) + · · · + (0.0 ∗ 452.2) + (0.0 ∗ 0.0)/(41.9 ∗ 467.5)
= 2583.8/19570.0 = 0.13
所以文档 D1 比 D2 更类似于 Q
Page rank 算法
利用链接结构:PageRank 算法
• 利用网页链接结构的关键方法:
PageRank 算法以其发明者的名字命名:Larry Page(Google 的联合创始人)为网络上的每个页面分配一个分数:
它的 PageRank 分数 • 可以看出代表页面的权威(或质量)
• 关键思想:
从页面 A 到页面 B 的链接赋予 B 权威 赋予 B 多少权威取决于A 的权威(PageRank 得分)及其出局数外链,即 A 的权限在其外链之间共享 ,此度量是递归定义的,即任何页面的分数取决于所有其他页面的分数
PageRank 分数有另一种解释:随机冲浪者访问该页面的概率
从一个随机页面开始,向前点击随机选择的链接,然后(感到无聊)跳转到一个新的随机页面,等等以此类推
在检索过程中,文档d 的排名得分是以下各项的加权组合:
它的 PageRank 得分:衡量其权威性的指标
它的 IR-Score:d 与查询 q 的匹配程度,基于向量空间模型、TF.IDF、重要术语的加权等
性能评估
使用预先创建的基准测试语料库(又名黄金标准数据集)比较性能,提供:
• 一组标准的文档和查询
• 人类受试者会判断与每个查询相关的文档列表
• 相关分数,通常被视为二进制
recall : proportion of relevant documents returned
Precision: proportion of retrieved documents that are relevant
Precision 和 Recall 解决了检索 retrieved和 relevant文件集的的关系
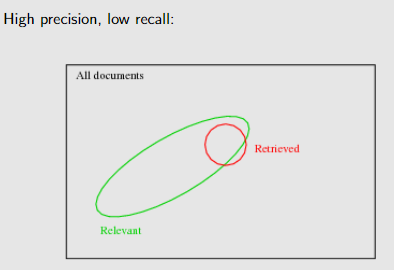
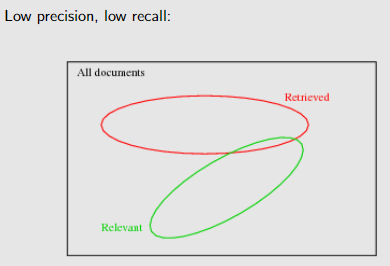
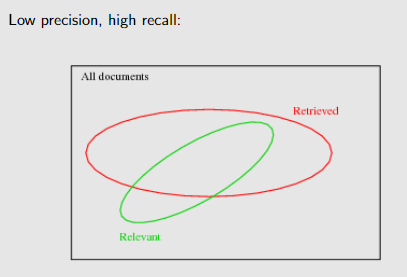
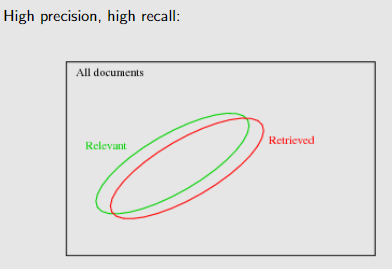
F-measure 是调和平均值:比算术平均值更能惩罚一个值的低性能









![[网络工程师]-VLAN](https://img-blog.csdnimg.cn/b36d9eb45f7a432ca5601094e516942f.png)