1 背景说明
Clang提供了C/C++语言对矩阵的扩展支持,以方便用户使用可变大小的二维数据类型来实现计算,目前该特性还是实验版,设计和实现都在变化中。LLVM目前设计为支持小型列矩阵(column major),其对矩阵的设计基于向量。为用户提供向量代码生成功能,能够减少不必要的内存访问,并且提供用户友好的接口。本文基于LLVM13以Intel X86架构为平台,来实验和分析LLVM编译器对矩阵运算的基础支持。
LLVM目前支持的矩阵间运算包括矩阵转置、矩阵加减法和矩阵乘法,矩阵除法只支持矩阵除以标量,不支持矩阵与矩阵相除。
2 功能实现
2.1 数据实现
矩阵支持的元素类型有整型、单精、双精、半精,用户可以通过matrix_type属性来定义各种不同元素类型不同行列数的矩阵。
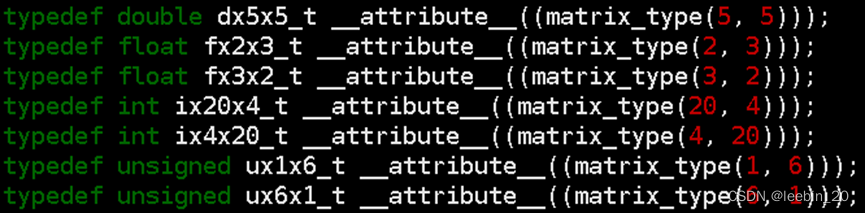
2.2 内建支持
2.2.1 Clang
Clang前端提供了3个内建接口供用户使用,如下表所示,目前矩阵的load和store都是按列操作,未来对行矩阵(row major)的支持也在计划中。
| 接口名称 | 功能 | 参数 | 返回值 |
|---|---|---|---|
| __builtin_matrix_column_major_load | 按列加载矩阵 | T *ptr:加载起始地址 size_t row:矩阵行数 size_t col:矩阵列数 size_t columnStride:跨步,指加载完一列数据后ptr自增的元素个数 | row行col列T元素类型矩阵 |
| __builtin_matrix_column_major_store | 按列存储矩阵 | dx4x4_t matrix:待存储的矩阵 T *ptr:存储起始地址 size_t columnStride:跨步,指ptr存储完一列数据后自增的元素个数 | 无 |
| __builtin_matrix_transpose | 矩阵转置 | dx4x4_t matrix:待转置的矩阵 | 转置后的矩阵 |
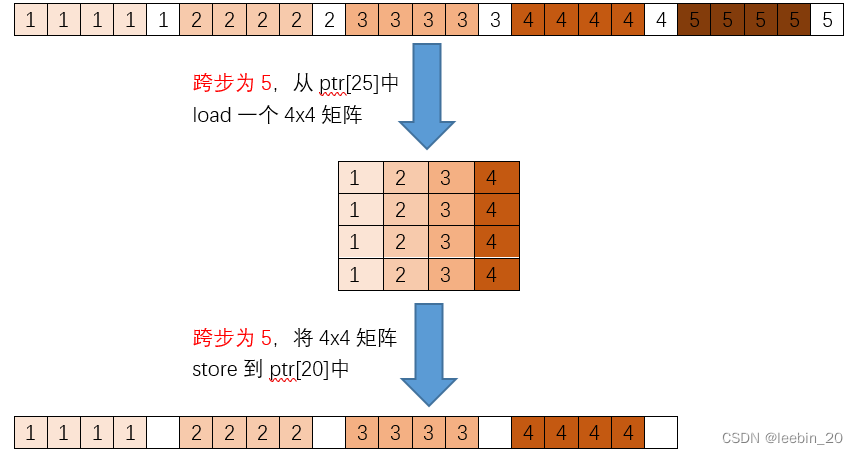
当从一个基地址*ptr加载矩阵时,列矩阵(column major)是一列一列依次赋值的。下图展示了跨步为5时, 列矩阵(column major)的load和store操作。
2.2.1 LLVM
LLVM后端提供了int_matrix_multiply内建函数,该接口并未在Clang前端暴露,用户在编码矩阵乘计算时,只需要使用乘法符号(*),LLVM在创建中间表示(IR)的时候会自动创建对该内建函数的调用。
2.3 算法流程
通过clang -cc1 -fenable-matrix -emit-llvm matrix_load.c编译代码,生成的IR中包含对内建接口的调用。

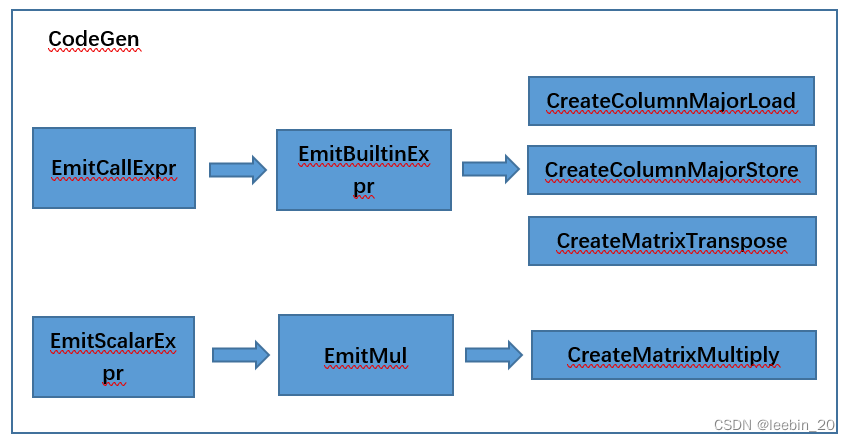
Clang中的3个内建接口是用户编码过程中可以直接调用的,所以它们的IR的生成过程是走的内建解析,矩阵乘在用户编码时并不是函数调用,所以走的是标量乘法解析,在其中增加了矩阵类型的分支。
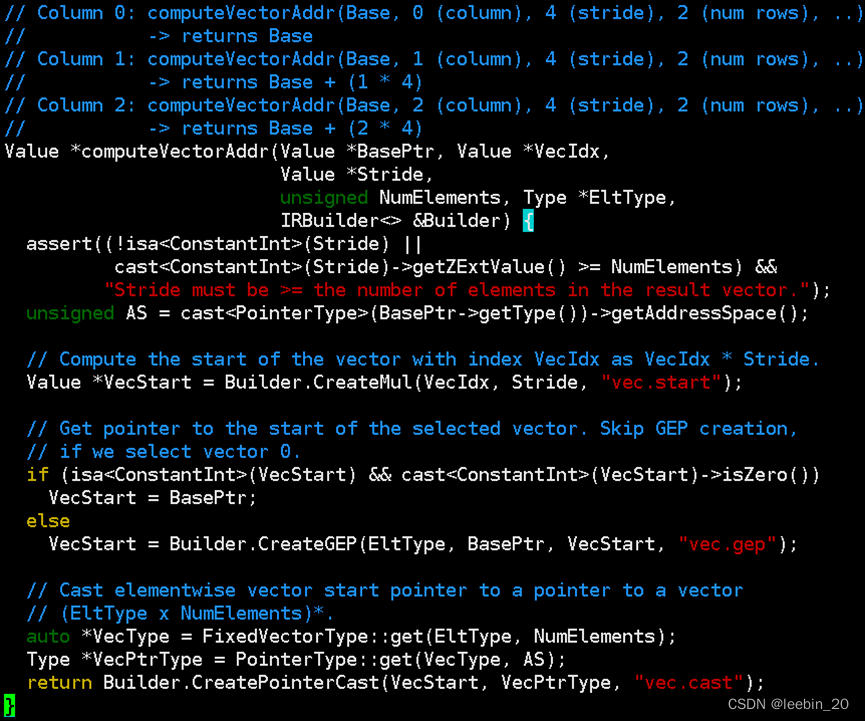
以下是CreateColumnMajorLoad函数的详细代码。

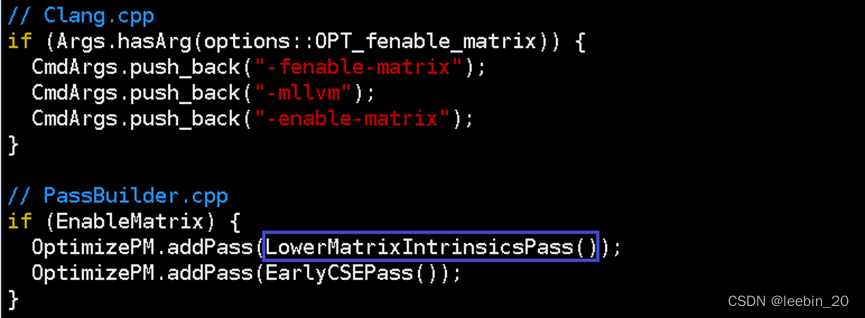
实际上LLVM X86中矩阵操作最终都是转成向量来做的,所以这一步生成的IR还需要进一步降级,使用向量指令替换内建接口的调用指令,并且对已经替换的接口指令做了缓存,下次再次调用同类矩阵接口指令,可以直接从缓存中取向量指令,而不需要再去执行矩阵转向量的操作,从而提高性能。通过clang -fenable-matrix -emit-llvm –S matrix_load.c可以生成最终的IR,该命令行在Clang.cpp中给后端传递了-enable-matrix选项,该选项会在PassBuilder.cpp中添加LowerMatrixIntrinsicsPass优化,该优化将上述IR中的矩阵操作转换成向量操作。
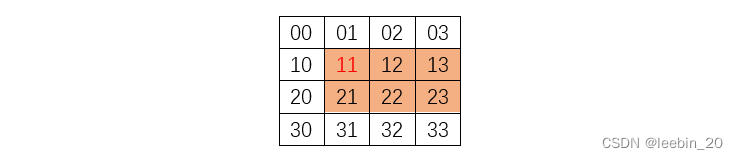
假设一个4x4的矩阵如下所示,现在需要以11为基址,从中计算一个2x3的子矩阵,LLVM提供了computeVectorAddr函数来计算子矩阵的地址。BasePtr指矩阵(向量)起始元素地址,VecIdx指当前向量在子矩阵中的index,Stride指加载时的跨步,NumElements指每个向量中的元素个数,EltType指元素类型。函数中VecStart变量通过VecIdx跟Stride相乘得到,该变量表示当前计算的向量的起始位置,比如示例矩阵中13对应的VecStart = 2 * 4 = 8;如果VecStart = 0,则代表是第0列向量,此时将BasePtr赋给VecStart作为新向量的起始地址,如果VecStart != 0,则通过Builder.CreateGEP()创建一个IR操作getelementptr,取对应列首地址,以此类推;最后通过Builder.CreatePointerCast()把上述列的首地址转成VecPtrType对应的向量地址,这样新向量就生成了。
有了以上computeVectorAddr函数,只要给定相应的参数,就可以计算出一个向量(子矩阵)的地址了,调用过程如下所示。LLVM中在load矩阵时,便是根据矩阵的列数(行矩阵根据行数)来依次生成原始矩阵对应的向量,比如一个int 5x4的矩阵会被load为4个<5 x i32>向量,而一个int 4x5的矩阵会被load为5个<4 x i32>向量。
矩阵的加减法是对应位置元素加减,所以在拆成向量后,即可以复用向量的加减操作,乘法与加减法的运算规则不同,所以需要对拆出来的向量进一步处理。假设矩阵A乘矩阵B等于矩阵C,元素类型都是int,如下所示。
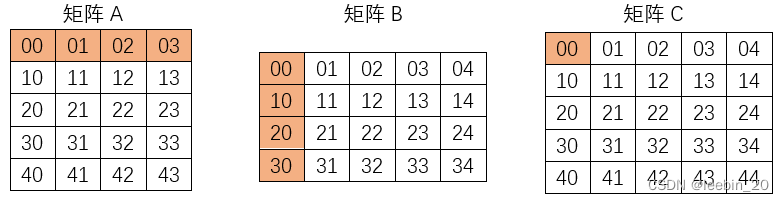
load的时候矩阵A被拆成了4个<5 x i32>向量,矩阵B被拆成了5个<4 x i32>向量,LLVM会根据拆分后的向量的地址把向量进一步整合成适合目标架构宽度乘法运算的新向量,具体是通过目标架构寄存器宽度和当前向量元素类型宽度的比值得出要整合的向量的大小。当前x86架构这里的VF返回的是4,也就是说以4个元素为一组向量整合矩阵A和矩阵B,整合完成后进行向量运算,如下所示。
<A00,A10,A20,A30>x<B00,B00,B00,B00>+
<A01,A11,A21,A31>x<B10,B10,B10,B10>+
<A02,A12,A22,A32>x<B20,B20,B20,B20>+
<A03,A13,A23,A33>x<B30,B30,B30,B30>=
<C00,C10,C20,C30>
可以看到,C40还没有被计算出来,此时就剩1个元素需要计算了,于是把矩阵A每一列最后1个元素和矩阵B第一列每个元素转成<1 x i32>向量,然后对应元素相乘后再相加,从而完成计算。
<A40>x<B00>+<A41>x<B10>+<A42>x<B20>+<A43>x<B30>=<C40>
那么是如何得到最后的向量是<1 x i32>类型呢?如前所述,VF决定了整合的向量的元素个数,LLVM通过以下代码来实现,C = 4,R = 5,当I + BlockSize > R时,会不断对BlockSize取半,确保了除1以外的其它向量元素个数都是偶数,BlockSize初值为4,第0列第0行时,I + BlockSize = 4 < R,所以取4个元素作为一组向量,第0列第5行时,I + BlockSize = 8 > R,BlockSize在while循环中最终算得1后满足条件。

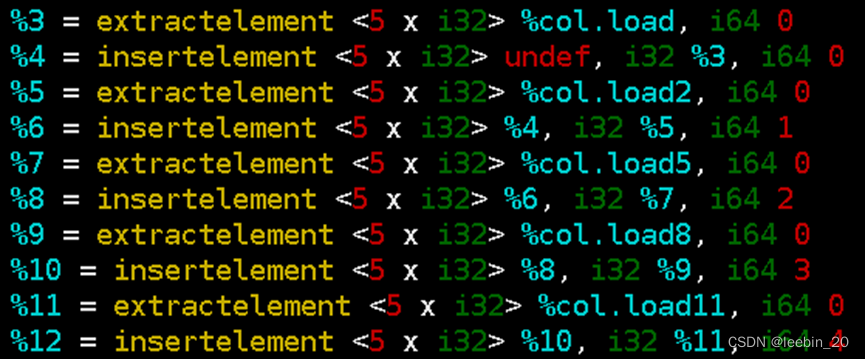
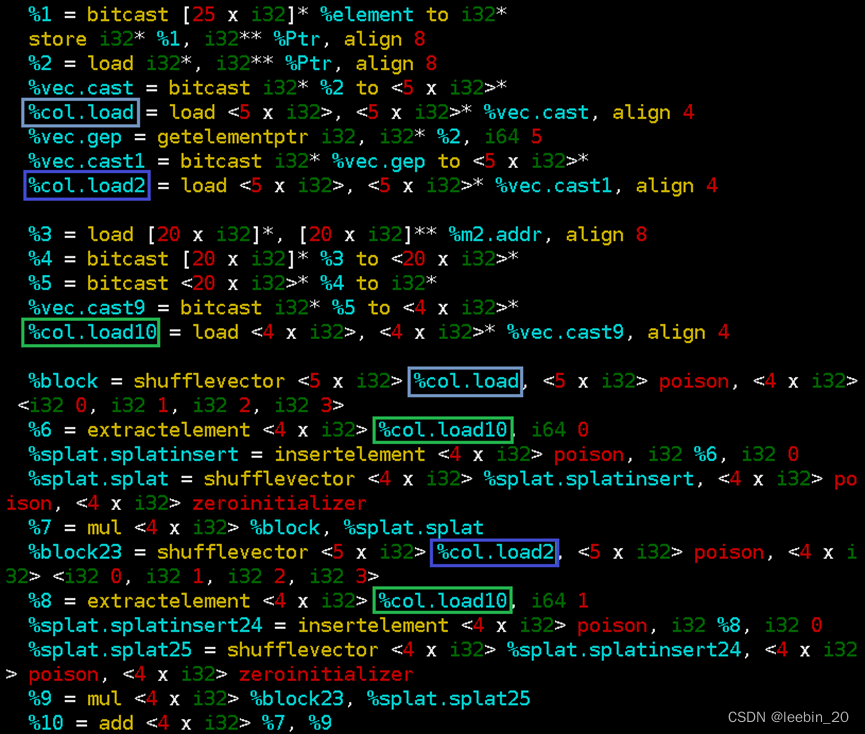
实际在IR中使用了shufflevector、extractelement和insertelement来生成新的向量。如下代码所示,%col.load为矩阵A第0列元素,%col.load2为矩阵A第1列元素,%col.load10为矩阵B第0列元素,从%col.load中取4个元素依次与%col.load10中的第0个元素相乘,从%col.load2中取4个元素依次与%col.load10中的第1个元素相乘,再把乘积依次相加。
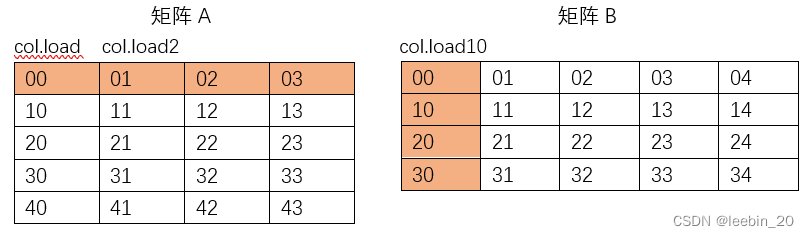
| key | value |
|---|---|
| %block | < A00,A10,A20,A30> |
| %splat.splat | < B00,B00,B00,B00> |
| %block23 | < A01,A11,A21,A31> |
| % splat.splat25 | < B10,B10,B10,B10> |
3 举例说明
3.1 Matrix load
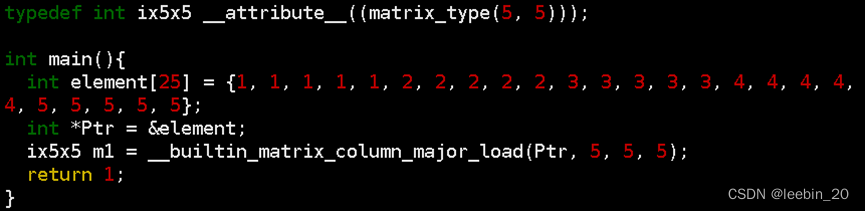
编写一段测例matrix_load.c如下所示,通过matrix_type属性指定行列数定义5x5的int类型矩阵,跨步设为5,这样正好把数组中的25元素都加载到矩阵中。
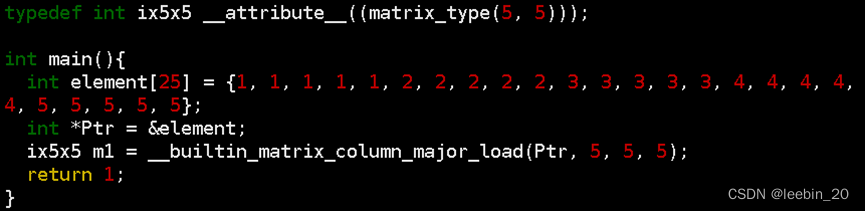
生成的IR正如前文所述,首先每次从数组element中取出5个元素组成一个向量。

再依次存到m1对应的矩阵的地址里。
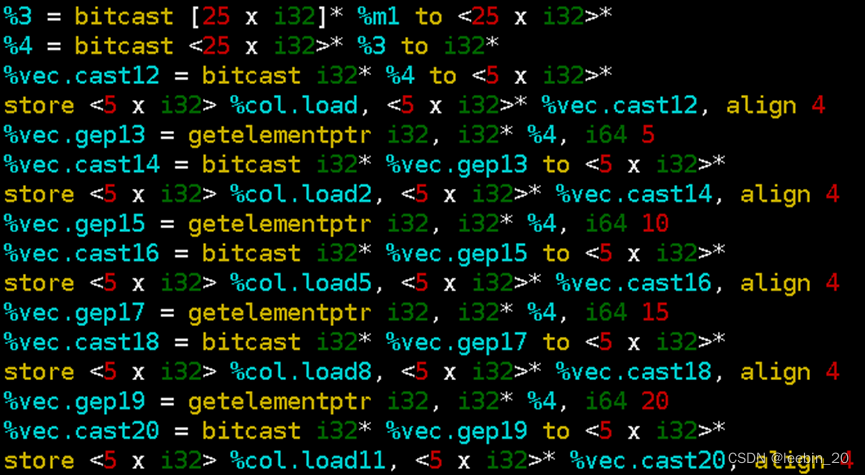
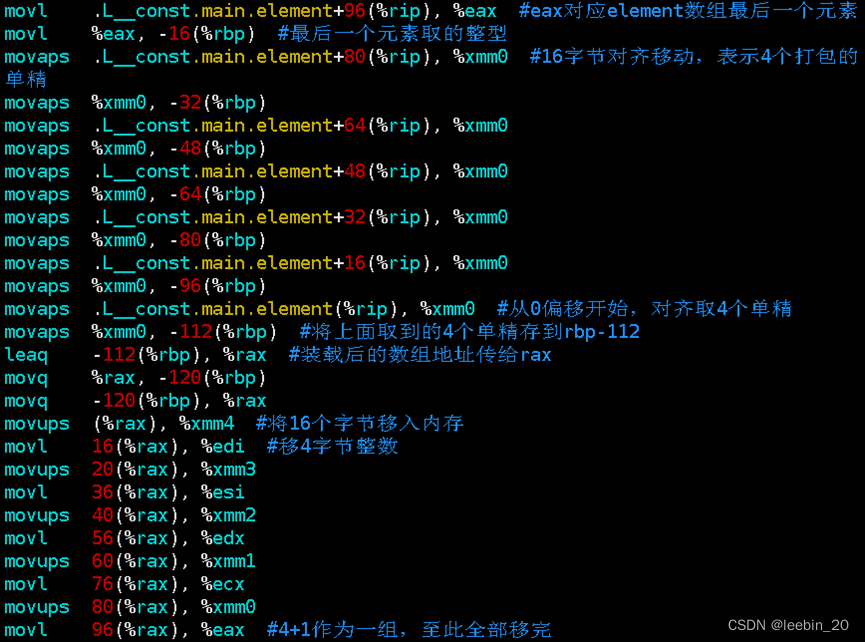
生成的汇编部分截图如下所示,可以看到,长度25的数组元素被拆成4+4+4+4+4+4+1取出来放到对应地址,存的时候按照4+1作为一组存了5次,正好构成5x5的矩阵。
3.3 Matrix transpose
矩阵转置同样也是将矩阵操作转换为向量操作,编写测例如下所示。

以下是生成的部分IR,从矩阵中load出每一列向量,第0列第0个元素插入到%4代表的<5 x double>新向量第0位置,第1列第0个元素插入到%4第1位置,第2列第0个元素插入到%4第2个位置,依次提取,按序插入,这样就完成了矩阵的转置操作。