Elasticsearch 是一个基于 Apache Lucene™ 的开源搜索引擎。不仅仅是一个全文搜索引擎,它还是一个分布式的搜索和分析引擎,可扩展并能够实时处理大数据。以下是关于 Elasticsearch 的一些主要特点和说明:
1.实时分析:Elasticsearch 能在大量数据上执行复杂的查询,并迅速返回结果。
2.分布式设计:它自动将数据分片,并在集群的不同节点上复制这些分片,以提供冗余和高可用性。
3.高可扩展性:可以简单地添加新节点,而 Elasticsearch 会自动重新平衡和路由数据。
4.多种数据类型:除了文本外,Elasticsearch 还可以处理结构化数据、数值、地理位置等数据。
5.基于 JSON:数据结构为 JSON 文档,并使用 HTTP RESTful API 进行通信。
6.灵活的查询语言:Elasticsearch 提供了一种非常灵活的查询语言,可以执行简单的文本查询到复杂的聚合查询。
7.集成与客户端库:Elasticsearch 提供了多种语言的官方客户端,如 Java、Python、PHP、JavaScript 等。
Elasticsearch 在许多应用中被广泛使用,包括日志和事件数据分析、内容搜索、数据可视化、地理搜索等。无论是在大型企业还是在初创公司,它都是实时搜索和分析大数据的流行选择。在本应用中,我们有大量的非结构化文档要存储(PDF、TXT和HTML),而ElasticSearch恰好可以帮助我们实现相应的检索功能。
我们通过Docker可以很方便的下载并启动一个ElasticSearch服务,执行下列命令即可。
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.10.2
docker run --name es01 -d -p 9200:9200 -it -m 1GB docker.elastic.co/elasticsearch/elasticsearch:8.10.2
需要注意的是,如果在Windows上通过Docker(WSL 2支持)启动ElasticSearch,遇到报错“node validation exception\n[1] bootstrap checks failed. You must address the points described in the following [1] lines before starting Elasticsearch.\nbootstrap check failure [1] of [1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]”,则需要配置一个参数。
wsl -d docker-desktop -u root
vi /etc/sysctl.conf
然后在文件中添加下面这一行。
vm.max_map_count = 262144
ElasticSearch第一次启动时,会创建一个默认用户elastic以及一个密码,如图6.x所示。这个用户认证信息只有在第一次启动时才会打印,因此我们需要将这个账号和密码记下来。
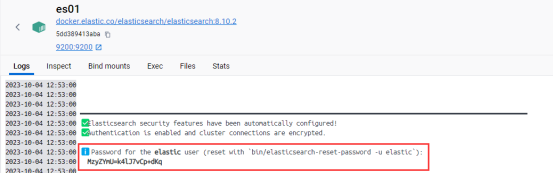
如果要在本地通过https链接到ElasticSearch,则还需要拷贝SSL证书到本地。
docker cp es01:/usr/share/elasticsearch/config/certs/http_ca.crt .
接下来我们可以通过Python的Elasticsearch库进行基本的Elasticsearch操作。
1.安装elasticsearch
pip install elasticsearch
2.设置和初始化连接
from elasticsearch import Elasticsearch
client = Elasticsearch(
"https://localhost:9200",
ca_certs="./http_ca.crt",
basic_auth=("elastic", "R+JWq7gBc4_rAPSN3gj7")
)
该部分首先从elasticsearch模块导入Elasticsearch类。然后,创建一个Elasticsearch客户端实例,并连接到本地运行在9200端口上的Elasticsearch服务器。使用ca_certs参数指定证书路径,并使用basic_auth参数为连接提供身份验证凭证。
3.创建索引
client.indices.create(index="my_index", ignore=400)
这个命令尝试在Elasticsearch中创建一个名为my_index的新索引。ignore=400意味着如果索引已存在,将忽略400错误。
4.向索引中添加文档
client.index(
index="my_index",
id="my_document_id",
document={
"foo": "foo",
"bar": "bar",
}
)
通过index方法将一个新文档添加到my_index索引中,并为其分配一个ID为my_document_id。
5.检索文档
client.get(index="my_index", id="my_document_id")
该命令从my_index索引中检索ID为my_document_id的文档。
6.搜索文档
client.search(index="my_index", query={
"match": {
"foo": "foo"
}
})
在my_index索引中执行一个搜索查询,查找字段foo值为foo的文档。
7.更新文档
client.update(index="my_index", id="my_document_id", doc={
"foo": "bar",
"new_field": "new value",
})
更新ID为my_document_id的文档,更改字段foo的值并添加一个新字段new_field。
8.删除文档
client.delete(index="my_index", id="my_document_id")
从my_index索引中删除ID为my_document_id的文档。
9.删除索引
client.indices.delete(index="my_index")
删除整个my_index索引。














![P1017 [NOIP2000 提高组] 进制转换](https://img-blog.csdnimg.cn/5492d6e2a39d48e0b73e8fdfa246f0ad.png)