向前进!
一、摘要
Instant analysis of cybersecurity reports is a fundamental challenge for security experts as an immeasurable amount of cyber information is generated on a daily basis, which necessitates automated information extraction tools to facilitate querying and retrieval of data. Hence, we present Open-CyKG: an Open Cyber Threat Intelligence (CTI) Knowledge Graph (KG) framework that is constructed using an attention-based neural Open Information Extraction (OIE) model to extract valuable cyber threat information from unstructured Advanced Persistent Threat (APT) reports. More specifically, we first identify relevant entities by developing a neural cybersecurity Named Entity Recognizer (NER) that aids in labeling relation triples generated by the OIE model. Afterwards, the extracted structured data is canonicalized to build the KG by employing fusion techniques using word embeddings. As a result, security professionals can execute queries to retrieve valuable information from the Open-CyKG framework. Experimental results demonstrate that our proposed components that build up Open-CyKG outperform state-of-the-art models.1
二、研究背景和挑战
为了理解不同网络攻击的手段及后果,网络安全专家们借鉴网络安全报告,但这些报告通常是非结构化的,造成信息难以被检索和获取。
面临如下问题:
1、在信息抽取中,实体和关系通常被预先定义。
2、缺少有效存储信息的数据结构。
3、构建知识图谱时面临冗余&模糊的问题。
三、研究内容
1、一个不预先设定实体类别的系统—【此步主要由OIE完成,可是后期用NER时,不也需要设定吗】
2、设计基于注意力机制的s2s OIE模型
3、设计NER模型(感觉没什么创新)
4、使用NER的label和word embedding完成KG的实体融合
5、演示KG功效—一个查询系统
四、方法
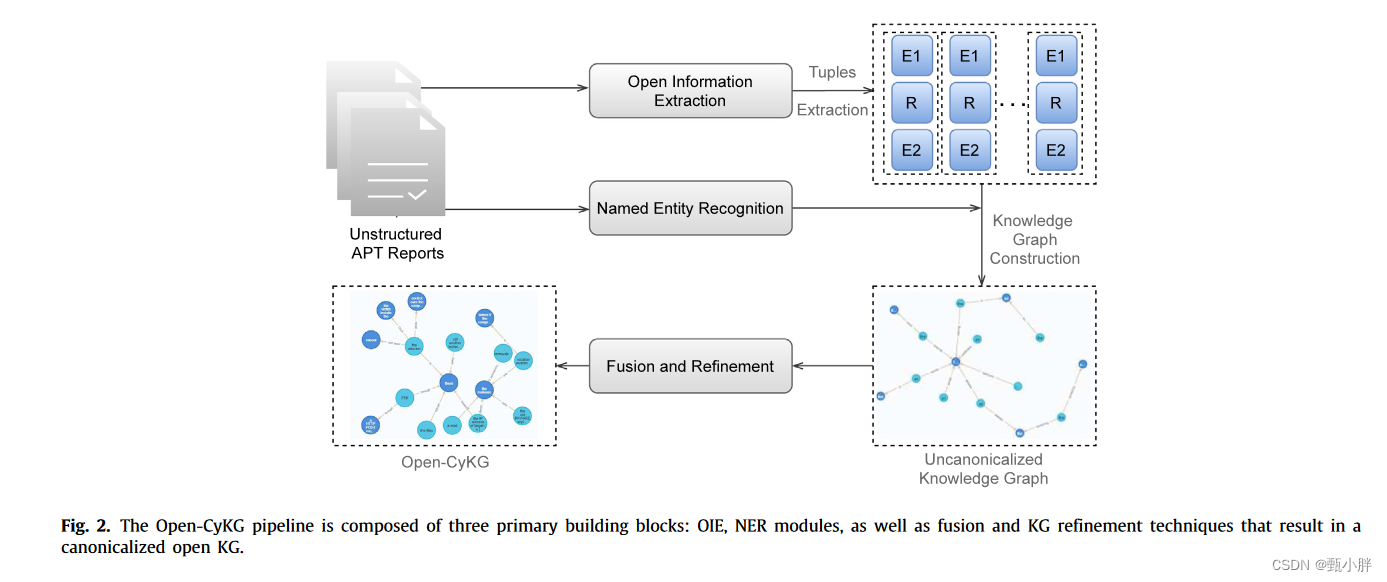
1、整体结构—三个模块
(1)OIE提取三元组
(2)NER给词汇打标签
(3)KG构建—进行实体消融
2、KG消融具体方法
(1)平均实体中的所有词嵌入向量
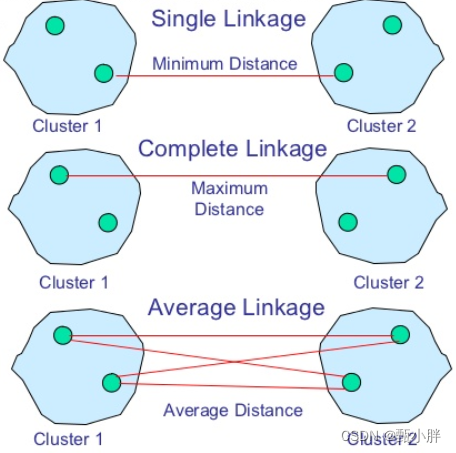
(2)使用HAC方法进行聚类----不需要预定义簇的个数+complete linkage clustering(如下图)
The complete linkage clustering is fitting in KG canonicalization as demonstrated in [38] as small-sized clusters are expected as opposed to single and average linkage clustering. Fig. 6 illustrates the canonicalized version of Fig. 5, where nodes are merged after the clustering process
(3)决定聚类代表
与平均距离最近的节点
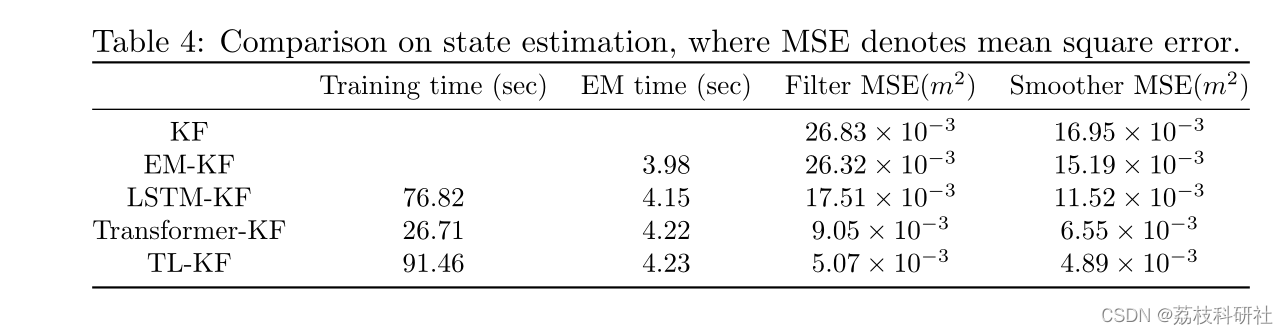
五、实验与结果




六、总结
几个有意思的未来方向
1、补全+链路预测
2、动态推理
3、多语言
Despite their value and practicality, KGs usually suffer from incompleteness, redundancy, and ambiguity that might translate to uninformative query results. First and foremost, we are in the process of acquiring more cybersecurity data from AAR reports to carry out a large-scale experiment. In future work we will shift our attention to KG completion and link prediction to further enhance the strength of the generated KG. Additionally, we would like to explore the possibility of extending the KG model to include a dynamic reasoning component instead of completely relying on static information to build the KG. A final interesting addition would be to construct a multi-lingual or cross-lingual KG to support machine translation-based applications. All in all, we foresee that in the near future KGs will become sufficiently mature to provide added value to daily practices in cybersecurity and beyond.
七、个人评价
(一)positive
1、OIE这个名词对我来说还是很新鲜的,不预定实体和关系种类地去做抽取。
2、neo4j的用法确实可以好好研究一下,最后的示例挺有意思。
3、文中所举的关于KG消歧作用(加强数据关联性,避免节点孤岛)的例子很直观。
4、文章写作不错,有理有据。
(二)question/negative
后续的NER再给实体分类。但是我觉得这篇论文NER解释的不是很清楚,既然NER是预定种类的,就有必要把图谱构建时候的种类写清楚。
然而,作者却说没有该数据集的标注信息(如下),那么KG是如何生成的呢?
As the MalwareDB dataset has no named entities annotation we could not train or evaluate our model based on MalwareDB extractions. In this section, we will discuss the datasets used to train and validate our NER neural network described in Section 3.2.
还是说NER这个模块是多余的?有没有都无所谓?如何理解NER这个模块在其中的作用呢?如果如下所述,模型都没训练,如何label呢?
First, an attentionbased OIE architecture for extracting domain-independent relational triples from unstructured data. Second, a NER model for automatic labeling of cybersecurity terms. More precisely, we start by extracting structural relation tuples from APT reports using OIE, which are later populated in the KG with the help of the NER task.
八、其他知识
1、span OIE model
开放信息抽取(OIE)是信息抽取的一种全新的范式,主要思想是减少人工参与,无监督地进行信息抽取,抽取那些实体、关系未定义地情形。
我把span翻译成“文段”。Cambridge dictionary的定义是:the length of something from one end to the other,所以在一段文本里,就是连续的若干token (usually represented as word in English or character in Chinese)。
作者:sulley
链接:https://www.zhihu.com/question/450683401/answer/1794295308
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2、bootstrapping pattern-based approach for tuple extraction.
(1)一个少量标注数据集+一个分类模型
(2)一个评价标注效果的方法
Bootstrapping过程形式化描述为:
对于给定的自然语言处理任务,选取特定的有指导的训练分类模型的方法。然后需要两个数据集,一般是少量的标注数据集L和为标注的数据集U。然后逐步通过未标注的数据集U来扩大标注的数据集。从而训练处最终的分类器实现具体的自然语言处理任务。
通过未标注数据集扩大标注数据集的过程如下:
1.使用已经标注的数据集L(可能是非常少量的数据集),应用选择的分类方法训练分类器h,h的作用主要是用于标注未标注数据集中的标注分类,通常可能是一些启发式规则等。
2.使用h对U进行标注分类目的是从U中获取到标注的数据。
3.在(2)中获取的标注数据中选择置信度较高的数据作为标注数据加入到标注数据集;
4.重复上述过程直到满足迭代结束条件。
Bootstrapping是一个能利用较少的标注语料获取到置信度较高的多量的标注语料的反复迭代的过程。Bootstrapping方法是通过两个主要的过程实现的,首先是提供一个少量语料就能够有效的进行分类的启发式规则或者时其他分类方法,其次是对分类器产生的新的标注语料进行评价的方法。通过评价来获得置信度较高的标注语料,这样通过迭代就可以获取到更大的标注数据集。迭代终止条件是给定一个迭代次数的阈值,或者时产生新的标注数据的数目过少等。
————————————————
版权声明:本文为CSDN博主「长弓Smile」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u012485480/article/details/80227240
3、KG
将知识图谱理解为一种数据结构–由节点和边组成,方便查询。
Knowledge Graph can be defined as a form of a data structure, which is composed of nodes and edges that are leveraged as a way to manage and illustrate information in such manner that users can efficiently query and obtain data on a specific topic.
第一个KG由google于2012年推出,旨在加强用户搜索查询体验
The first KG was introduced by Google [28] in 2012, with the main objective of enhancing query results and further enriching the overall search experience of end-users.
4、After Action Reports (AAR)
和CTI相似——提供检测和减缓影响的方法。
As AARs provide crucial data about detection and mitigation techniques of attacks, they can also aid in dealing with new unidentified cybersecurity incidents by matching pattern similarities with a predefined incident.
5、Time Distributed Dense (TDD)
应该和dense layer相似,只不过多了一个time维度。
搜索的时候发现了这个教程网站,挺好的。
https://campus.datacamp.com/courses/machine-translation-in-python/implementing-an-encoder-decoder-model-with-keras?ex=9
6、A good example for explaining canonicalization
如果不canonicalize的话,就会导致信息孤立。
To further clarify the importance of canonicalization in addressing ambiguity and redundancy, consider the following two triple extractions: <Barack Obama, born in, Hawaii> and <Obama, served as, 44th U.S President>. In an uncanonicalized version of the KG, the two extractions would be included separately without any connecting edges, as Barack Obama and Obama are perceived as two distinct entities. This may lead to a remarkable impact when querying data from the KG as it will not return all information linked with Barack Obama. Such KGs will also suffer from redundant facts, which is undesired. Canonicalizing KGs using HAC clustering as described above guarantees relation transitivity, that both entities —Barack Obama and Obama— are fused to represent a single entity. Several other canonicalization approaches and entity linking techniques are proposed in [55,56].