文章目录
- 1. 前言
- 2. 回表操作 Index Lookup
- 2.1 什么是回表
- 2.2 回表的成本
- 2.3 如何避免回表
- 3. 索引覆盖 Covering Index
- 3.1 什么是索引覆盖
- 3.2 索引覆盖的优点
- 3.3 如何使用索引覆盖
- 4. 最左匹配原则(Leftmost Prefix Match)
- 4.1 什么是最左匹配原则
- 4.2 最左匹配原则的应用
- 4.3 最左匹配原则的注意事项
- 4.3 最左匹配底层原理
- 5. MySQL索引使用的最佳实践
- 5.1 如何选择索引列
- 5.2 如何评估索引效果
- 6. MySQL索引面试常见问题
- 6.1 索引是否越多越好?
- 6.2 什么情况下需要使用索引?
- 6.3 如何判断一个查询是否使用了索引?
- 6.4 什么是索引的并发问题?如何解决?
- 6.5 其他高频面试题
- 7. 参考文档

1. 前言
背景:有一个小老弟面试的时候再数据库索引话题中被问到一些名词索引下推,回表,最左匹配原则涉及到一些原理层面的问题。所以今天抽时间聊聊。
MySQL面试过程中,经常在索引面试话题中,最常问的几个名词,我们今天来聊一聊。其实这些名词也是作为一个开发应该要掌握理解的。这是基本常识。今天先来聊聊回表、索引覆盖,最左匹配 对于索引下推 SQL优化操作我们下次专门一篇文章聊聊等。
2. 回表操作 Index Lookup
2.1 什么是回表
回表(Index Lookup)是指在使用非聚簇索引进行查询时,需要通过索引找到对应的行数据,然后再回到原始表中查找其他列的值。当一个查询无法完全通过索引满足所有需要返回的列时,就需要进行回表操作。
在MySQL中,聚簇索引包含了完整的行数据,所以在使用聚簇索引进行查询时,无需回表操作即可获取所需的数据。但对于非聚簇索引,只包含索引列和主键列,当需要查询其他非索引列的值时,就需要进行回表操作。
回表操作会增加额外的I/O开销,因为需要进行两次查询操作。首先,通过非聚簇索引找到满足查询条件的索引行,然后根据索引行中的主键值再次回到原始表中查找其他列的值。这意味着需要读取更多的数据块,并且可能会导致更多的磁盘I/O操作。
在某些情况下,回表操作可能会降低查询性能,特别是在需要返回大量列的查询中。因此,为了提高查询性能,可以考虑通过调整索引的设计或使用覆盖索引等方法,尽可能减少或避免回表操作的发生。
关于文中出现的聚簇索引和非聚簇索引不理解的同学可以查看我之前的文章《聊聊MySQL的聚簇索引和非聚簇索引》
回表是指在使用非聚簇索引进行查询时,需要通过索引找到对应的行数据,然后再回到原始表中查找其他列的值。回表操作会增加额外的I/O开销,可能降低查询性能。为了避免或减少回表操作,可以优化索引设计或使用覆盖索引等方法。
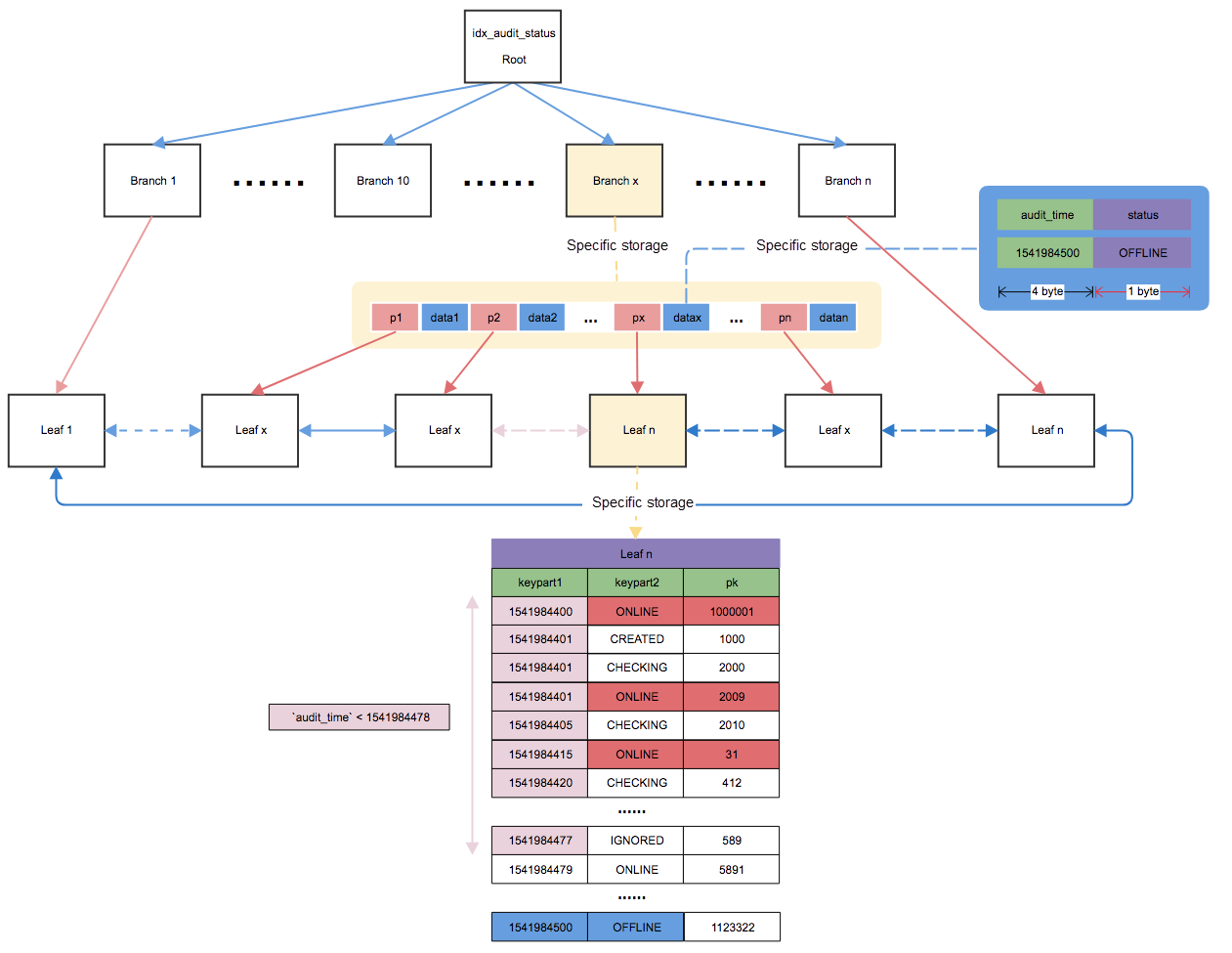
例如图中的数据从复合索引中找到小于给定audit_time值的最大audit_time值的行。
查找其他小于该audit_time值的audit_time值的行。由于< audit_time是一个范围查询,并且第二列的索引值是分散的,我们需要逐个进一步搜索匹配的行,找到所有满足条件(status=‘ONLINE’)的索引行,直到获得第五个匹配的行。在回到表中进行检索和查询表中的具体数据记录。
2.2 回表的成本
在MySQL中,"回表"是指在非聚簇索引查询过程中,需要通过索引指针回到主键索引进行查询的操作。这是因为非聚簇索引并不包含全部的行数据,因此当需要获取非索引列数据时,就需要通过索引列中保存的主键指针,回到主键索引(也就是聚簇索引)去查找需要的数据。
回表操作的成本主要体现在以下几个方面:
-
磁盘I/O的成本:由于聚簇索引和非聚簇索引在磁盘上的存储位置是不连续的,因此回表操作需要进行额外的磁盘I/O操作。这样就会增加数据查询的延迟,降低查询速度。
-
CPU的成本:回表操作需要通过主键指针在聚簇索引中进行查找,这个过程需要消耗CPU资源。如果回表操作过于频繁,可能会导致CPU资源紧张,影响服务器的整体性能。
-
内存的成本:在回表操作过程中,需要在内存中缓存一部分数据,如果内存资源有限,频繁的回表操作可能会导致内存压力增大。
-
并发的成本:由于在回表操作过程中,需要先锁定非聚簇索引,再锁定聚簇索引,这就可能导致锁等待的情况,降低并发性能。
回表操作会增加数据库查询的成本,降低查询速度,因此在设计表和索引结构时,应尽量避免需要进行回表操作的查询。这也是为什么有时候我们会选择将更多的列加入到非聚簇索引中,形成覆盖索引,从而避免回表操作的原因。
2.3 如何避免回表
避免MySQL回表的主要方法是使用覆盖索引。覆盖索引是指一个查询语句的执行只用到了一个索引,并且不需要再去访问表中的其他数据,我们称这个索引覆盖了查询。换句话说,覆盖索引能够在索引结构内完成一条查询的全部工作。
如何避免回表
- 创建覆盖索引:在创建索引时,将查询中需要用到的字段都包含在索引列中。这样,数据库在查询时就可以只通过索引就获取到需要的数据,无需再回到主表中去查找。例如,如果有一个频繁执行的查询是
SELECT name, age FROM users WHERE age > 18,那么可以创建一个包含name和age的索引。
假设我们有一个users表,包含id(主键)、name、age字段,我们经常需要执行如下查询:
SELECT name, age FROM users WHERE age > 18;
为了减少回表操作,我们可以创建一个覆盖索引包含name和age:
CREATE INDEX idx_age_name ON users(age, name);
这样,上述查询可以直接在idx_age_name索引中获取所有需要的数据,无需回表。
- 避免查询非索引列:在编写查询语句时,只查询索引列。这样,查询操作就可以完全在索引上完成,无需再访问主表。
在上述users表中,如果我们只需要查询年龄大于18岁的用户的name,那么我们就可以只查询索引列:
SELECT name FROM users WHERE age > 18;
这样,查询操作就可以完全在idx_age_name索引上完成,无需再访问主表。
3. 使用索引提示:在查询语句中使用FORCE INDEX 或 USE INDEX 索引提示,显式指定MySQL使用覆盖索引。
如果我们希望上述查询强制使用idx_age_name索引,可以使用FORCE INDEX或USE INDEX索引提示:
SELECT name FROM users FORCE INDEX (idx_age_name) WHERE age > 18;
或者
SELECT name FROM users USE INDEX (idx_age_name) WHERE age > 18;
这样,MySQL就会按我们的指示,使用idx_age_name索引执行查询,从而避免回表。
4. 合理设计表结构:尽量减少宽表,将一些不常用,但是数据量大的字段拆分到其他表,减少主表的IO负担。
3. 索引覆盖 Covering Index
3.1 什么是索引覆盖
索引覆盖(Index Covering)是一种查询优化技术,在某些情况下可以避免回表操作,通过仅使用索引就可以满足查询的需求,从而提高查询性能。
通常情况下,当使用非聚簇索引进行查询时,如果查询需要返回的列不包含在索引中,就需要进行回表操作,通过索引找到对应的行数据,然后再回到原始表中查找其他列的值。这会增加额外的磁盘I/O和网络传输开销。
而索引覆盖则是指在查询过程中,索引包含了查询所需的所有列,无需回表操作即可获取所需的数据。也就是说,索引本身就能够覆盖查询的需求,能够直接返回查询结果,而不需要再回到原始表中查找其他列的值。
比如说,有一个 SQL 语句如下:
SELECT name, age FROM users WHERE age > 20
如果我们在 users 表上有一个索引 idx_age_name(age, name),那么这个索引就是一个覆盖索引,因为这个索引完全覆盖了上面 SQL 语句中需要查询的所有字段。
使用覆盖索引的优势在于,当 MySQL 使用这个索引时,可以在索引中获取所有需要的信息,而无需再回到数据表中去查找。这样就减少了磁盘I/O操作,提高了查询效率。
注意:覆盖索引并不是越多越好,因为过多的索引会增加存储空间的需求,并可能影响写操作的性能。选择哪些字段创建覆盖索引,需要根据实际的查询需求来决定。
3.2 索引覆盖的优点
并非所有的查询都能够使用索引覆盖。索引覆盖的前提是索引包含了查询所需的所有列。在实际应用中,可以通过合理的索引设计和查询调优来尽可能地实现索引覆盖,以提高查询性能。
使用索引覆盖可以带来以下好处
- 减少磁盘I/O:由于无需进行回表操作,减少了额外的磁盘I/O开销,提高了查询性能。
- 减少网络传输:回表操作会增加数据传输量,而索引覆盖可以直接返回查询结果,减少了网络传输的开销。
- 减少CPU计算:回表操作需要进行额外的计算和比较,而索引覆盖可以避免这些额外的计算,减轻了CPU的负载。
- 减少内存消耗:回表操作可能需要加载更多的数据到内存中,而索引覆盖可以减少内存的消耗,对系统的整体性能有利。
3.3 如何使用索引覆盖
使用索引覆盖需要两步:
- 创建覆盖索引:在创建索引时,将查询中需要用到的字段都包含在索引列中。例如,如果有一个频繁执行的查询是
SELECT name, age FROM users WHERE age > 18,那么可以创建一个包含name和age的索引,如:
CREATE INDEX idx_age_name ON users(age, name);
- 查询时使用索引列:在编写查询语句时,只查询索引列。这样,查询操作就可以完全在索引上完成,无需再访问主表,如:
SELECT name, age FROM users WHERE age > 18;
在以上例子中,由于name和age都被包含在idx_age_name索引中,因此MySQL可以直接通过这个索引找到所有满足条件的name和age,无需再回到主表中去查找。
另外,如果我们能确定MySQL的查询优化器没有正确地选择到覆盖索引,我们也可以在查询中使用FORCE INDEX或USE INDEX索引提示来显式指定MySQL使用覆盖索引,例如:
SELECT name, age FROM users FORCE INDEX (idx_age_name) WHERE age > 18;
4. 最左匹配原则(Leftmost Prefix Match)
4.1 什么是最左匹配原则
最左匹配原则,也称为最左前缀原则,是指MySQL在使用复合索引(多列索引)进行查询时,只有在查询条件中使用了索引列的最左部分,才能够使用该索引。
例如,如果一个复合索引是(a,b,c),那么以下情况中索引会被使用:
- WHERE a=xx
- WHERE a=xx AND b=xx
- WHERE a=xx AND b=xx AND c=xx
而在以下情况索引则不会被使用:
- WHERE b=xx
- WHERE b=xx AND c=xx
- WHERE a=xx AND c=xx
4.2 最左匹配原则的应用
当我们在设计数据库索引和编写SQL查询语句时,都需要考虑到最左匹配原则。在创建复合索引时,需要将查询条件中最频繁使用的列放在最左边。在编写查询语句时,即使不需要所有的索引列,也需要包含索引的最左边的列。
假设我们有一个员工表employee,表中有id、first_name、last_name和age四个字段。我们经常需要查询姓氏为某值且年龄在某个范围的员工。所以我们创建了一个复合索引idx_last_name_age:
CREATE INDEX idx_last_name_age ON employee(last_name, age);
根据最左匹配原则,以下查询都可以使用该复合索引:
SELECT * FROM employee WHERE last_name = '张三';
SELECT * FROM employee WHERE last_name = '张三' AND age >= 30;
SELECT * FROM employee WHERE last_name = '张三' AND age BETWEEN 30 AND 40;
而以下查询则不能使用idx_last_name_age索引:
SELECT * FROM employee WHERE first_name = '李四';
SELECT * FROM employee WHERE age >= 30;
SELECT * FROM employee WHERE first_name = '四' AND age >= 30;
在第一和第三个不能使用索引的查询中,因为查询条件中并未使用到索引最左边的last_name列。在第二个查询中,虽然使用了索引中的age列,但由于它不是最左边的列,所以索引也无法被利用。
注意:如果查询条件中的列包含范围查询,那么它右侧的所有列都无法使用索引优化查询。例如:
SELECT * FROM employee WHERE last_name LIKE 'S%' AND age = 30;
在这个查询中,尽管使用了索引的所有列,但由于last_name列进行了范围查询,所以age列无法使用索引。
4.3 最左匹配原则的注意事项
-
最左匹配原则并不意味着一定要使用所有索引列。只要满足最左前缀,就可以利用索引进行查询。
-
如果查询条件中的列包含范围查询(如:>,<,BETWEEN,LIKE),那么它右侧的所有列都无法使用索引优化查询。例如,对于复合索引(a,b,c),在WHERE a=10 AND b>20 AND c=30的查询中,只有a、b两列会使用索引。
-
即使在不符合最左匹配原则的情况下,MySQL也可能会选择使用索引的部分列进行查询,或者进行索引扫描。这取决于MySQL的查询优化器如何评估和选择索引。
-
最左匹配(Leftmost Prefix Match)是指在复合索引中,索引的最左边的列被用于查询条件时,可以有效利用该索引进行查询和过滤。
-
查询条件必须从索引的最左边开始:如果查询条件涉及到了索引的最左边的列,那么数据库可以使用该索引进行快速定位和过滤。但如果查询条件从索引的非最左边的列开始,那么索引无法有效使用,可能需要进行全表扫描或回表操作。
-
列的顺序非常重要:复合索引中列的顺序非常重要。根据查询的特点和频率,将最常用的列放在索引的最左边,以确保最左匹配的效果。
-
可以使用索引覆盖:如果查询只需要索引中的列,而不需要回表操作获取其他列的值,那么可以实现索引覆盖,进一步提高查询性能。
-
适用于等值查询和范围查询:最左匹配对于等值查询(例如 WHERE column = value)和范围查询(例如 WHERE column > value)都适用。对于范围查询,数据库可以利用索引的有序性进行范围的快速定位。
当创建复合索引时,索引会按照列的顺序进行排序。在查询时,如果查询条件能够使用索引的最左边的列,数据库可以直接利用该索引进行快速定位和过滤,而无需扫描整个索引。这样可以大大提高查询性能。
同时,最左匹配的原则也意味着只有索引的最左边的连续列能够被有效使用。如果查询条件中的列不是索引的最左边的列,那么数据库无法利用该索引进行快速过滤,可能需要进行全表扫描或回表操作,导致性能下降。
4.3 最左匹配底层原理
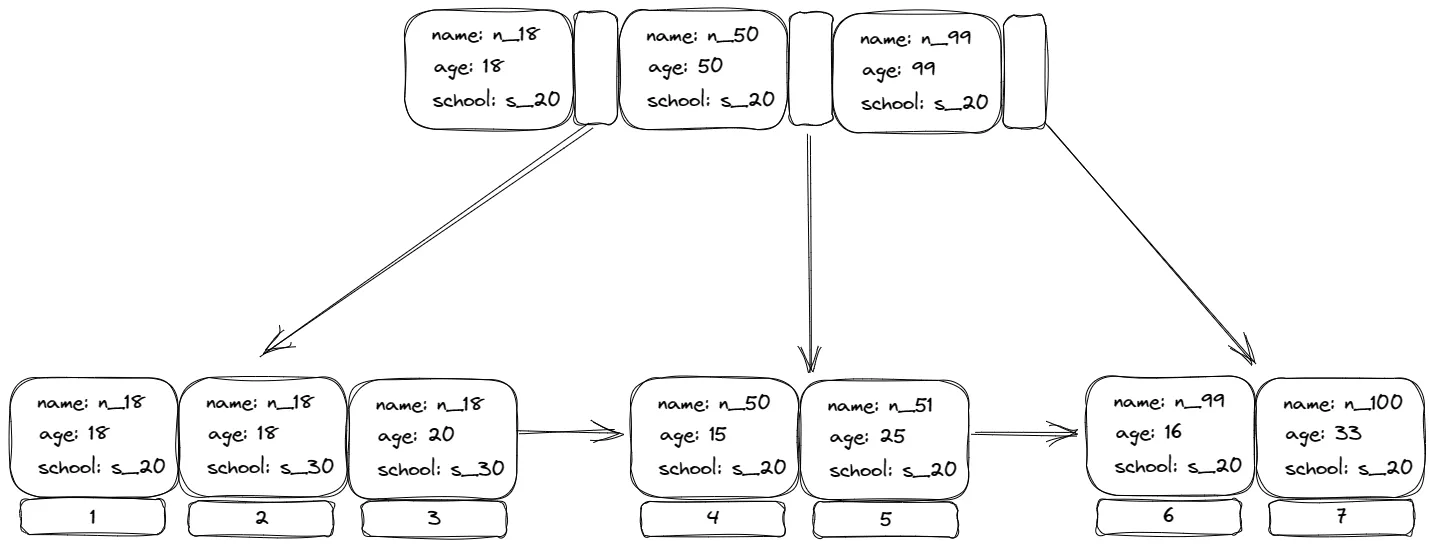
图片来源 https://levelup.gitconnected.com/how-to-optimize-a-mysql-index-e357d3434ea9
最左匹配原则的底层原理与B树(B-Tree)数据结构的特性有关。MySQL索引使用的是一种特殊类型的B树:B+树。
B+树是一种自平衡的、可以进行快速查找的树形数据结构。在B+树中,所有的值都存在于叶子节点,并且叶子节点是通过指针连接在一起的,这使得范围查找变得非常高效。
对于复合索引(a, b, c),在B+树中,数据是按照a、b、c的顺序排序的。首先按照a排序,a相同的情况下再按照b排序,然后是c。这样的排序方式也称为字典序。
所以,当我们进行查询时,如果查询条件中只有b,数据库就无法直接定位到具体的数据位置,因为数据首先是按照a进行排序的,a的值不同,b的位置也会不同。这就是最左匹配原则的底层原理。
但是,如果通过a和b的组合进行查询,数据库就可以快速定位到数据的位置,因为a和b的组合在B+树中是有序的,数据库可以通过B+树的特性快速找到满足条件的数据。
这就是为什么我们在进行复合索引查询时需要遵循最左匹配原则,这样才能充分利用B+树索引的优势,提高查询性能。
5. MySQL索引使用的最佳实践
5.1 如何选择索引列
选择哪些列进行索引取决于的数据以及的查询需要。考虑以下因素:
- 频繁在WHERE子句中使用的列:这些列是索引的最佳候选者。
- 有唯一值的列:唯一值的列适合做索引,因为索引的目的就是快速找到数据,唯一值可以更快地找到数据。
- 参与排序的列:如果某列经常需要排序,那么在这列上创建索引可以加快排序速度。
- 参与联接的列:如果一个表与其他表经常需要进行联接查询,那么这些参与联接的列应该被索引。
5.2 如何评估索引效果
详细了解,可参考我之前发布的一篇关于MySQL EXPLAIN的文章《【实践篇】MySQL EXPLAIN执行计划详解》
创建索引后,可以使用EXPLAIN命令来查看查询是否使用了索引,以及如何使用的。EXPLAIN可以显示MySQL如何使用索引来处理SQL语句,以及连接表的顺序。
另外, 还可以通过比较创建索引前后查询的速度来评估索引的效果。但是记住,索引并不总是提高性能,它也有消耗,因此需要权衡。
假设我们有一个employees表,它有id, first_name, last_name和age四个字段,并且我们在last_name和age上创建了一个复合索引:
CREATE INDEX idx_last_name_age ON employees(last_name, age);
我们可以使用EXPLAIN命令来查看查询是否使用了索引:
EXPLAIN SELECT * FROM employees WHERE last_name = 'Smith' AND age = 30;
查询结果可能会类似这样:
+----+-------------+-----------+------------+------+-----------------+------+---------+-------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+-----------------+------+---------+-------+------+----------+-------------+
| 1 | SIMPLE | employees | NULL | ref | idx_last_name_age | idx_last_name_age | 8 | const | 1 | 100.00 | NULL |
+----+-------------+-----------+------------+------+-----------------+------+---------+-------+------+----------+-------------+
在key列,我们可以看到MySQL使用了我们的idx_last_name_age索引。在type列,我们可以看到查询类型是ref,这意味着MySQL是使用索引进行查询的。
如果我们对没有索引的查询使用EXPLAIN,结果可能会像这样:
EXPLAIN SELECT * FROM employees WHERE first_name = 'John';
查询结果可能会类似这样:
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
| 1 | SIMPLE | employees | NULL | ALL | NULL | NULL | NULL | NULL | 1000 | 10.00 | Using where |
+----+-------------+-----------+------------+------+---------------+------+---------+------+------+----------+-------------+
在这个查询中,type列的值是ALL,这意味着MySQL对整个表进行了全表扫描,possible_keys和key列都是NULL,这表明MySQL没有使用任何索引进行查询。
6. MySQL索引面试常见问题
6.1 索引是否越多越好?
并不是。虽然索引能提高查询的速度,但它也需要空间来存储,增加了存储成本。同时,每次执行插入、删除和更新操作时,索引也需要被维护,这会增加写操作的开销。因此,索引不是越多越好,而是要根据实际的查询需求和数据情况来合理创建。
6.2 什么情况下需要使用索引?
以下情况可能需要考虑使用索引:
- 表数据量大,而且经常需要执行复杂的查询。
- 常常需要排序的字段。
- 常常需要查询的字段。
- 数据量大但值的种类较少的列,比如性别、状态等。
- 经常需要联接的列。
6.3 如何判断一个查询是否使用了索引?
可以使用EXPLAIN命令来查看查询的执行计划,如果key列有值并且type列的值不是ALL,那么就是使用了索引。
6.4 什么是索引的并发问题?如何解决?
索引的并发问题指的是当多个用户同时对一个表进行读写操作时,可能会导致数据的读写冲突。这主要是由于在写操作(如插入、删除和更新)时,会对索引加锁,而这个锁可能会阻止其他用户的读写操作。
解决索引的并发问题的方法主要有:
- 尽量减少锁的持有时间,尽快释放锁以提高并发性。
- 使用最新的InnoDB引擎,它支持行级锁,相对于表级锁,能大大提高并发性。
- 尽可能地设计合理的事务,并尽量减少事务的大小,避免长事务。
- 在必要的时候,可以考虑使用乐观锁和悲观锁。
6.5 其他高频面试题
- MySQL的索引是如何工作的?
MySQL支持多种索引类型,其中最常用的是B+树索引。当你对某列创建索引时,MySQL会创建一个B+树,然后将该列的所有值存储在B+树中。当你查询时,MySQL会从B+树的根节点开始,一直向下查找,直到找到你需要的数据,这大大提高了查询效率。
- B+树索引的工作原理是什么?
B+树是一种自平衡的多路搜索树,它的每个节点都包含了键和指向子节点的指针。在B+树中,所有的数据都保存在叶子节点,非叶子节点仅存储键信息。这种设计使得B+树的每一层深度相同,查询效率稳定。这对于处理大量数据尤其重要。
- 为什么MySQL使用B+树作为索引结构,而不是其他数据结构,如哈希表或B树?
相比哈希表,B+树索引不仅支持等值查询,还支持范围查询和排序。这是因为B+树的所有叶子节点通过指针串联起来,数据之间的顺序关系得以保留。而哈希表的插入和删除操作会引起哈希值的重新分配,不利于维持数据的物理顺序。
相比于B树,B+树的所有键值都出现在叶子节点,非叶子节点仅作为索引,这使得B+树在磁盘I/O性能上有优势。因为磁盘读写数据时是以页为单位,一页可以加载更多的索引,减少了I/O操作。同时,B+树查询效率更稳定,因为查询每一条记录的路径长度相同。
- 索引的创建和维护是如何进行的?
当对一个字段创建索引时,MySQL会将该字段的数据取出,然后按照索引类型(如B+树)的规则生成相应的数据结构。当对表进行插入、删除或者更新操作时,MySQL会自动更新相应的索引。
- 什么是最左前缀匹配原则?为什么它很重要?
最左前缀匹配原则是指在进行查询时,MySQL会从复合索引的最左边开始匹配。这意味着,如果查询条件中没有包含复合索引的最左列,那么MySQL不会使用这个复合索引。
它之所以重要,是因为它决定了复合索引的使用情况。理解了这一原则,你就能更好地设计索引,从而提高查询效率。
- 为什么说索引可以提高查询速度?
索引是一种数据结构,主要用于快速查找数据。MySQL的索引基于B+树数据结构,它能大大加快数据检索速度,避免了全表扫描。
- 什么情况下索引可能失效?
有一些情况下,索引可能失效,包括:like语句以%开头的模糊查询,对索引列做运算或函数操作,复合索引并未遵循最左匹配原则,索引列使用了不等于,索引列与NULL进行比较。
- 什么是全文索引?何时使用全文索引?
全文索引是一种能够基于自然语言理解的索引,能够查找包含给定词语的数据记录,而不仅仅是匹配整个词语。当需要对大文本字段进行搜索,如文章,描述等,可以考虑使用全文索引。
- 什么是哈希索引?它的优点和缺点是什么?
哈希索引基于哈希表,适用于等值查询。优点是查找速度快,对于大量数据等值查找有明显优势。缺点是不支持范围查找,不能利用索引完成排序,不支持模糊查找。
- 如何选择索引的列和顺序?
选择索引的列和顺序需要考虑查询的频率,列的选择性,查询的性质等因素。频繁作为过滤条件的列,应该被考虑作为索引列。有大量不同值的列,选择性好,适合作为索引列。使用最左前缀原则,最常用作限制条件的列应该放在复合索引的最左边。
7. 参考文档
《8.2.1.6 Index Condition Pushdown Optimization》https://dev.mysql.com/doc/refman/8.0/en/index-condition-pushdown-optimization.html