本文转自王喆的《深度学习计算广告》,仅用于学习。
文章目录
- 一、计算广告系统简介
- 二、经典的广告系统架构
- 三、dl时代广告系统各模块技术演进
- 1. Ad Ranking - 从大刀阔斧的革命到精雕细琢的改进
- (1)模型发展图
- (2)张俊林:从召回到排序再到重排
- (3)粗排:阿里的cold
- 2.联邦学习 - 隐私合规时代的新宠
- 3. Pacing - 广告系统的隐藏核心
- (1)Pacing模块
- (2)Pacing模块的2个核心问题
- 4. 竞价 - 博弈的艺术
- 5. Calibration
- 6. 转化样本延迟问题
- 四、王喆对广告算法工程师的看法
本文转自王喆的《深度学习计算广告》,仅用于学习。
一、计算广告系统简介
广义的计算广告系统囊括的范围非常广,分类也非常复杂。比如效果广告和品牌广告,合约广告和不保量交付广告,CPC、CPA、oCPM、oCPC广告等等。搞清楚这些复杂的分类固然重要,但却不是重点,因为这些知识肯定会随着你从业年数的增加一一理解清楚。这里我们只描述这些广告系统的一个超集,从技术上,只要搞清楚了这个“超集”的技术体系,其他类型的广告系统通过补充一些枝节就可以比较快的熟悉。
那么这个超集是什么呢?我建议你就了解清楚oCPM广告系统是怎么工作的就完全足够了。oCPM的全称是 Optimized Cost Per 1000 Impressions,就是优化后的千次曝光价格。广告主需要选定一个优化目标,大多数时候是一个转化目标比如APP安装,电商购买行为等,但广告主还是按照CPM来付费。oCPM最早是由facebook提出的,这种付费方式既满足了广告主追求优化目标的利益,又保证了广告平台相比CPA付费比较可控的收入预期,双方利益都能有效保证,因此很快成为了效果广告行业的主流。
那为什么说oCPM广告系统是最适合了解计算广告技术体系的“超集”呢?我们看一看它的计费公式就知道了。一般来说,oCPM广告要求广告主提供一个转化目标的出价,即CPA,那么一次广告展示的出价公式就是: CPA × pCTR × pCVR × pacingFactor \text { CPA } \times \text { pCTR } \times \text { pCVR } \times \text { pacingFactor } CPA × pCTR × pCVR × pacingFactor
上面的公式中pCTR指的是系统预估的这次广告请求的点击率,pCVR是预估转化率,pacingFactor是进行广告预算平滑使用的pacing因子。从这几个变量就可以看到,要做好oCPM广告,就一定要把CTR模型,CVR模型,广告预算相关的pacing模块都做好才行,而这几个模块,就是计算广告系统最核心的模块。如果是其他类型的广告,比如品牌广告,缺少了CTR,CVR模块;如果是CPC广告,缺少了CVR模块,都不能算是广告系统的“超集”。
二、经典的广告系统架构
广告系统的复杂度远远大于推荐系统。事实也确实如此,广告系统涉及到的模块数量,与系统外的其他系统,甚至不同公司交互的复杂度远远高于推荐系统。具体来说,广告系统的复杂度主要是下面三个问题带来的:
① 广告系统往往需要跟Ad Exchange,广告主的数据系统,第三方计费度量系统,数据采买和合作公司系统进行对接,这些工作推荐系统一般不会涉及,工程复杂度就高很多。
② 广告系统中的模型相比推荐模型的要求更高,推荐模型一般只要求把推荐物品的序排正确,广告模型则要求预估的CTR,CVR要非常准确,具备物理意义,因为这些都影响到出价和扣费这些直接和公司收入相关的模块。
③ 广告系统需要处理广告计划,需要合理匹配广告预算和流量,因此催生了一大批推荐系统不具备的业务模块和相应算法,包括pacing,流量预估,预算分配等等。

那广告系统这把“火枪”上有哪些主要的零件呢?如上面的架构图,主要有四大部分:
① 数据工程部分。这部分其实跟推荐系统没有明显区别,主要是在流式或batch的数据平台上处理广告模型/算法所用的样本、标签和特征。唯一有显著区别的是由于CVR模型需要第三方回传的转化数据作为label,因此需要增加一个度量模块,并在模型训练中处理label回传延迟的问题。
② 算法流程部分。这个部分是指广告系统的主要逻辑流程。推荐系统的“召回、粗排、精排、重排”经典流程在这里被框定为Ad Ranking模块,这仍然是广告流程中的核心部分。此外广告系统还前置了定向、预算规划,后置了Pacing、对外竞价这些广告系统独有的模块。
③ 基础模型部分。基础模型部分解决的是一个个比较独立的计算广告问题,比如CTR、CVR模型就是要准确的预估出点击率和转化率,Pacing算法就是要精确的控制广告计划的投放速度等,这些基础模型被算法的主流程调用,组装成为完整的广告投放逻辑。但一般来说,基础模型的各模块都可以当作独立的问题单独迭代。
④ 模型工程部分。这部分跟推荐系统也是一致的,一般负责模型的在线/离线训练,模型的分发和评估等功能。
三、dl时代广告系统各模块技术演进
1. Ad Ranking - 从大刀阔斧的革命到精雕细琢的改进
深度学习时代对于广告系统最大的革命性影响还是在于Ad Ranking,也就是架构图最中央的红色部分。而Ad Ranking的技术发展其实跟推荐系统的主流进展是高度一致的,在2022年的KDD-DLP workshop上,我与董振华,唐睿明两位博士合作的文章:
《A Brief History of Recommender Systems》
https://arxiv.org/pdf/2209.01860.pdf
(1)模型发展图
重新更新了《深度学习推荐系统》的模型发展图,这里也给大家分享一下:
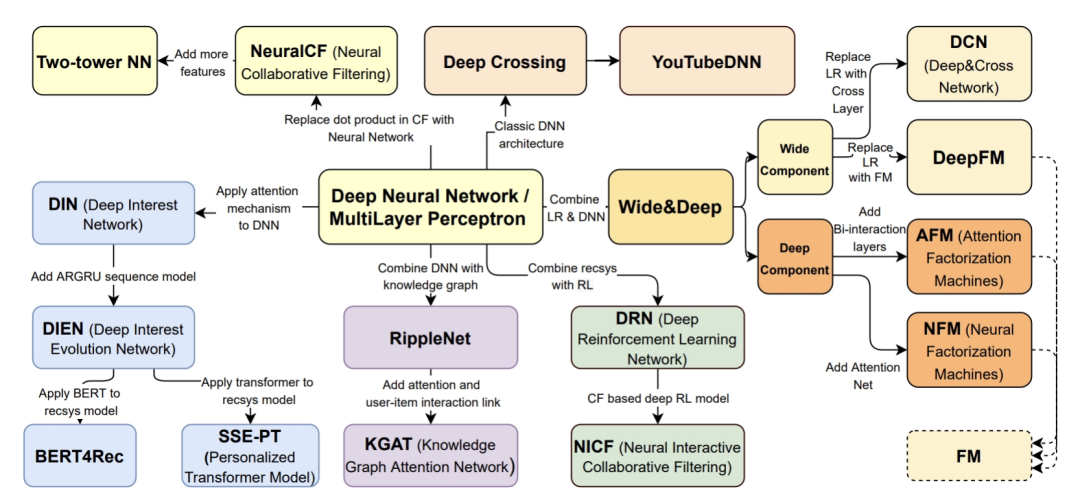
相比于几年前阿里提出的DIN、DIEN等模型,精排模型的发展其实有两个主要的趋势,一是Transformer、Bert等NLP结构的进一步引入,让模型具备更强的表达能力,这里面典型的模型是BERT4Rec;二是GCN等知识图谱领域的技术与精排模型的结合,让模型对于复杂结构的知识有了更好的融合能力,典型的模型有RippleNet,KGAT。
但关于深度学习模型的发展,这里不希望展开太多,这里有两个原因:
① 相关的信息已经过剩。大量paper、学术分析文章对这部分的关注已经过多,大家肯定也不缺乏相应的信息源。
② 过于复杂的深度学习模型已经被不少公司证明对业务指标的提升效果是微乎其微的。复杂结构对于稳定性的影响,模型体积过大对于资源的过度浪费,已经很难和模型带来的效果提升持平。因此不希望过分强调模型继续朝复杂化的方向发展。特别是对于数据质量比较低的公司,盲目追求模型的复杂度,只意味着盲目的投入和计算资源的浪费。
可以这么说,2016到2021年这段业界大刀阔斧的把原有传统模型替代为深度学习模型的时代已经过去了,大家不约而同的开始对自己的模型方案进行精雕细琢,这里面有两大机会:
① 保效果的前提下,压缩模型体积降成本。这里面典型的工作是知识蒸馏在模型压缩上的应用。
② 针对自己公司数据特点的模型微改造,微创新。这里面最典型的工作是多任务学习,也就是针对不同广告系统的优化目标不同,自定义不同的任务,融合在一个模型里学习。
(2)张俊林:从召回到排序再到重排
很多同行可能会说,上面主要说的是CTR,CVR这类比较重的精排模型吧,召回和粗排的迭代难道也遇到同样的问题吗?这里我推荐大家读另外一篇文章,张俊林老师的两万字大作《推荐系统技术演进趋势:从召回到排序再到重排》
https://zhuanlan.zhihu.com/p/100019681
文中不仅详细介绍了当前召回的经典框架,而且覆盖了“用户行为序列召回”,“用户多兴趣Embedding召回”,“知识图谱召回”等多种新颖的召回手段,这里也不再重复了。
(3)粗排:阿里的cold
粗排领域近来给我比较深刻影响的工作是阿里的COLD:
Computing power cost-aware Online and Lightweight Deep pre-ranking system
https://arxiv.org/pdf/2007.16122.pdf
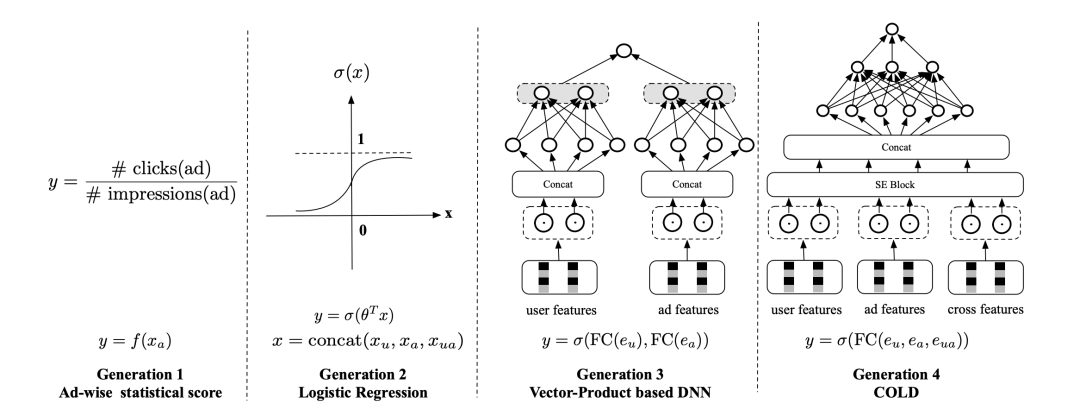
它的主要思路是通过一系列的infra优化提升了深度学习模型中特定operation的计算效率,从而能够在粗排阶段应用原来不具备应用条件的复杂模型。两年前我们的认知还认为粗排召回只能用双塔模型,因为可以通过ANN的计算快速找到合适的备选。但COLD的提出让粗排层也能够进行复杂的特征交叉,给人一种“合久必分,分久必合”的感觉。
事实也确实如此,七八年前,大家清一色用的是FTRL,因为是线性模型,计算速度非常快,系统也没有必要分成召回粗排精排这么多层。四五年前,随着深度学习模型的崛起,排序模型做的效果越来越好,但体积也越来越大,延迟越来越长,我们不得不把Ranking的过程拆分开来,召回负责快速过滤候选集,粗排负责高效的排序和截断,精排最终进行精排序。近年来,随着我们在model serving,deep learning infra上面投入的精力越来越多,深度学习模型也可以用在粗排上,甚至可以和精排模型合并。这也代表了Ad Ranking相关技术的下一步发展趋势,几乎所有一线公司关注的方向都是类似COLD的Algorithm-System Codesign的方式。在有限的资源下寻求“成本-效果”的综合优化,远比让模型成为吞金巨兽来的实在一些。
2.联邦学习 - 隐私合规时代的新宠
近几年在广告模型领域异军突起的一个方向是联邦学习。它的基本概念不难理解,就是把原来集中式的模型学习过程分布到不同的数据拥有方的计算节点上,不同的计算节点像“联邦”一样互相配合完成一个模型的学习。
联邦学习的流行主要是由于大家越来越重视数据的作用和对用户隐私的保护,特别是不同的数据巨头合作的时候,互相不愿意分享原数据,又希望发挥数据的作用来提升广告效果,这就给了联邦学习生长的土壤。
联邦学习的基本原理可以用一个“加密”版的分布式parameter server来解释。传统的parameter server是在同一个数据中心的很多计算节点上并行进行模型训练,每个节点训练一部分数据,然后把模型参数或者梯度上传至parameter server。如果把计算节点替换成不同的数据主体,再把参数传递的过程进行加密,就成为了联邦学习的一般方案。
如下图所示,计算节点变成了手机,平板,PC,数据中心等等,这些都可以成为能够独立保证数据隐私的数据主体。在完成本地数据的训练之后,模型的参数或者梯度等可以通过差分隐私或者各种加密算法进行传输,保证接收方无法解密出受保护的数据信息,同时能够完成模型的更新。

这几年来联邦学习方案在广告和金融领域应用越来越广,主要是这两个领域特别依赖用户的隐私数据,但又对隐私数据有很强的保护需求。比较典型的案例有微众银行在风控上的联邦学习应用:
https://aisp-1251170195.cos.ap-hongkong.myqcloud.com/wp-content/uploads/pdf/%E8%81%94%E9%82%A6%E5%AD%A6%E4%B9%A0%E7%99%BD%E7%9A%AE%E4%B9%A6_v2.0.pdf
京东腾讯广告平台对联邦学习上的合作等等。近年来,各大巨头也陆续推出了自己的联邦学习框架,比如:
阿里的FederatedScope:https://federatedscope.io/
微众银行的FATE:https://fate.fedai.org/
但联邦学习也有它的弊端,主要是对参与方的技术门槛要求比较高。如果是小的合作方、广告主,没有技术能力,其实很难玩的转联邦学习。所以目前来说,联邦学习的方案还主要是大厂之间的游戏。如何提高它的易用性,让小的合作方能够无门槛进入是当前的痛点。
3. Pacing - 广告系统的隐藏核心
(1)Pacing模块
这一小节我们来介绍Pacing这个模块,Pace的意思是步伐,调节步伐或者速度的意思。顾名思义Pacing就是指广告中调节广告投放速度的模块。其实广告系统的业界和学术界的同行们大多数的关注点都在CTR,CVR预估这类“大模型”上,Pacing这种非常偏实践,偏工程模块的曝光度就比较低。但事实上,Pacing在广告系统中的重要程度丝毫不亚于CTR,CVR预估,甚至可以称为广告系统的“隐藏核心”。因为Pacing做不好,你的系统一分钟内把人家一天的预算都投完了,怎么会有广告主敢在你的平台上投放呢,更谈不上去观察投放效果了。
这也是广告系统独有的魅力,就是有很多工程问题是要切实的,深入问题核心去解决的,任何实验环境,或者模拟环境都无法真正积累起最宝贵的广告系统工程经验。而对于一位广告系统工程师来说,这样的经验才是你最深的技术护城河。
那么如何做好Pacing模块,其实是有经典答案的,这里推荐三篇Pacing的经典论文:
- 雅虎:https://arxiv.org/pdf/1506.05851.pdf
- Turn:https://arxiv.org/pdf/1305.3011.pdf
- Linkedin:http://wnzhang.net/share/rtb-papers/linkedin-pacing.pdf
(2)Pacing模块的2个核心问题
要设计一个好的Pacing模块一定要解决两个核心问题:
① 一个广告计划应该以什么样的预算分配曲线投出去?
② 预算曲线设定好了之后,广告引擎应该如何投放广告让消耗符合预算曲线的趋势?
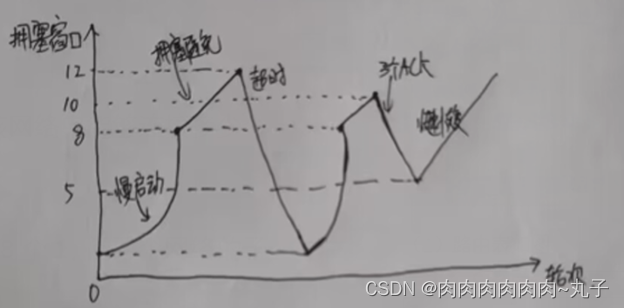
对于问题①,广告预算的分配一般有下面几种情况。比如图a,还没到全天结束就把预算花完了,后面几个小时的流量没有利用上,这显然浪费了流量。图b的预算像过山车,让广告主投放的心惊胆战,显然也不是好的分配方式。图c平均分配了预算,虽然平滑但不高效。图d和图e分别按照流量波动和广告计划的效果波动来分配预算,是两种经典的预算分配方式。

按照效果分配预算的方式其实比较好理解,就是看广告计划的历史投放效果,晚上的转化效果好就晚上多分配一些,周末效果好就周末多分配一些。按照流量分配预算的方式是现在流量分配的主流方式。要做好按照流量分配,也分为两步,一步是做好符合该广告计划的流量预估,第二步是做流量和广告预算的配对分配。
流量预估是一个特别偏实践的话题。大家也不用看什么太深奥的paper,业界主流的做法就是用一些时序预估预估的方法:
https://souhaib-bentaieb.com/papers/2014_phd.pdf
比如ARIMA去预估总流量的趋势。用一些机器学习模型去预估细粒度上的流量分布偏移量。比如影响流量的典型特征有,是否节假日,ios/android,是否周末,男性/女性等。用xgboost,NN等比较通用,拟合能力也比较强的模型进行学习即可。
有了一个靠谱的流量预估模型,那么剩下的就是做广告预算的分配,能在全局上更好的把预算分配给对应的流量。简单的做法当然就是预估一条计划可投的流量趋势之后,预算也按照这样的趋势分配就可以了。但这样的方式没有考虑全局条件下不同计划竞争的问题,在流量比较稀缺的场景下,如果要考虑全局分配的话,这个问题就会变成一个经典的二部图匹配的问题。

如何解这个问题,其实是一个比较复杂的数学问题,这里就不展开了,推荐两篇老东家hulu的同事们写的经典blog,分别用Dual,High Water Mark,SHALE三种方法解决这个问题。
https://mp.weixin.qq.com/s/JbPgHJaGKttEbtGeXgRiFg
https://mp.weixin.qq.com/s/I-xvNFl4A30LGfyD9zb9ww
当然,对于大多数广告系统,能够做到比较准确的流量预估,并按照流量去分配预算,就已经是非常优秀的实现方案了。
讨论进行到这,其实刚完成了预算分配这第一步;下一步我们要讲解Pacing模块如何设计才能让cost按照预算曲线投放。
我们其实可以把Pacing模块当作一个水龙头,我们通过调大和调小这个水流大小来达到控制投放的目的。如下图所示,这个水龙头控制的经典变量有两个,一个是概率控制,一个是出价控制。前者是指通过控制随机drop广告流量的概率来控制广告投放的速度,后者是指控制广告出价的高低来控制竞胜率,来控制广告投放的速度。

虽然两者的控制对象不一样,但控制方法是相似的。大白话就是,当实际消耗大于预算的时候,拧紧一些这个水龙头,反之,放松一些这个水龙头。形式化的来说,主要是下面这个公式:
p
i
,
t
=
{
p
i
,
t
−
1
∗
(
1
+
r
t
)
,
if
s
i
,
t
≤
a
i
,
t
p
i
,
t
−
1
∗
(
1
−
r
t
)
,
if
s
i
,
t
>
a
i
,
t
p_{i, t}=\left\{\begin{array}{lll} p_{i, t-1} *\left(1+r_t\right), & \text { if } & s_{i, t} \leq a_{i, t} \\ p_{i, t-1} *\left(1-r_t\right), & \text { if } & s_{i, t}>a_{i, t} \end{array}\right.
pi,t={pi,t−1∗(1+rt),pi,t−1∗(1−rt), if if si,t≤ai,tsi,t>ai,t
其中 p i , t − 1 p_{i, t-1} pi,t−1 是 t − 1 t-1 t−1 时间片上的 “水龙头概率”, r t r_t rt 是一个调节参数, s i , t s_{i, t} si,t 是 t t t 时刻的实际消耗, a 1 , t a_{1, t} a1,t 是 t t t 时刻的 预算。所以公式中 r t r_t rt 的决定就至关重要了, 对于一个控制问题, 我们当然要搬出控制论中最经典的PID 控制, 事实上用它解决pacing的问题也完全够用了。当然有不熟悉PID控制的同行们不难通过网上的 资料熟悉它。
至此,我们介绍完了Pacing模块的经典方法,几乎也是业界的统一解法。这也是一个可以不断打磨的模块,比如启动期和结束期的平稳控制,与出价、预估模块的复杂配合,都考验着相关工程师的全面性和对细节的把控能力。
4. 竞价 - 博弈的艺术
下面要介绍的是计算广告系统中的另一个很有意思的模块,就是竞价模块。竞价模块要解决的问题是用什么价格去购买外部的流量才是合适的。比如我是一家DSP,流量全部来自于购买Ad Exchange的流量。那么如何用便宜的价格买到优质的流量就是非常重要的事情。否则,你的整个生意就是赔钱的买卖。在竞价策略方向上,我比较推荐大家参考上海交大的张伟楠副教授和任侃博士的研究。
https://arxiv.org/pdf/1803.02194.pdf
https://arxiv.org/pdf/1701.02490.pdf
https://www.saying.ren/thesis/phd_thesis_Kan_Ren.pdf

竞价策略的好玩之处在于它是一个与对手博弈的艺术。某种意义上来说,广告交易所跟股票交易所是很接近的,只不过它们一个交易的是广告流量,一个交易的是股票,实时竞价广告中竞价策略的开发与股票交易所中的高频交易策略也是很相似的。
如果我们不以“博弈”的思路来优化竞价策略,而是以流量采买的思路来定义竞价策略,会发生什么事情呢?我们就以系统算出的这条流量的ecpm来去竞价,竞得到,我们会以≤ecpm的价格拿到这部分流量,竞不到,我们也不亏,总体上来说,我们是有利可图的。
但是“有利可图”并不代表着“利益最大化”。比如我们系统判断这条流量值1块钱,但其实其他竞价方最高只出到1毛钱,在越来越多的ad exchange改成1价计费的前提下,我们其实亏了9毛钱。我们只考虑自己,不考虑竞争对手,这种竞价方式往往会让我们只能取得微薄的利润。但其实四五年前,大部分的竞价方确实是这样做的。
如果希望用更“贪心”的博弈策略来竞价,就必须首先做到“知己知彼”,而要“知彼”,就要构建好你的竞争对手对某类流量的出价分布,这就是所谓的bid landscape。下图就是针对某个广告位的整体出价分布,和基于这个出价分布的竞胜率曲线。利用统计方法的bid landscape预估其实是实用的,但却没有办法把更多流量特征放进来,进行更为个性化的精准预估。如何融合更多的特征做准确的bid landscape预估呢?下面就介绍一种把深度学习应用于竞价模型思路——DLF(Deep Landscape Forecasting)。

DLF本质上是一个序列模型, RNN, LSTM, GRU等都可以作为其模型结构。这里以RNN为例解释其 原理。如下图所示, 搞清楚原理的关键是明白每个神经元的输入输出都是什么。以红框里的神经元Z 为例,它预估的是流量特征
x
x
x 下, 在价格区间
z
z
z 内竞得这条流量的概率
h
z
h_z
hz, 并向右传递给下一个神经元一个状态隐向量
r
r
r 。

有了这样一个神经网络。我们就可以知道,流量特征x条件下,如果出价是b,那么它竞价失败的意思就是在小于b的价格区间上全部无法竞胜,也就是所有区间失败概率的乘积:
∏ l : I ≤ l b ( 1 − h l i ) \prod_{l: I \leq l_b}\left(1-h_l^i\right) l:I≤lb∏(1−hli)
反过来说,出价b的竞胜率就是:
1
−
∏
l
:
l
≤
l
b
(
1
−
h
l
i
)
1-\prod_{l: l \leq l_b}\left(1-h_l^i\right)
1−l:l≤lb∏(1−hli)
在这套框架下,我们就可以用深度模型解决bid landscape预估的问题,从而大大提高原来统计方法对特征利用不足的问题。
那么得到了bid landscape的预估曲线,如何去制定竞价策略去参竞其实是一个更全局的问题。这里面就必须要考虑广告主侧的利益。如下图所示,竞价模块最核心的部分是图中红绿蓝的三块。其中user response prediction其实就是我们常说的CTR,CVR预估,通过它得到系统对这条流量广告主获得价值的预估,而bid strategy部分负责综合广告主的价值预估和这条流量的成本预估,做出一个决定,到底参与不参与这条流量的竞价,到底以多高的价格去竞价。

我们其实可以用一个非常朴素的,但直击问题本质的模型来解决这个问题。基本的原则是:我们应该竞得那些成本低,但广告主价值高的流量,这中间的差值越大,我们越应该竞得它。所以竞价策略要解决的其实是在预算限制下去最优化广告主价值的利润:
max Σ ( ( advertiser value − win price ) ⋆ win rate ) \max \Sigma\left(\left(\text { advertiser } \text { value }-\text { win }_{\text {price }}\right) \star \text { win }_{\text {rate }}\right) maxΣ(( advertiser value − win price )⋆ win rate )
但由于 w i n r a t e win_{rate} winrate和 b i d p r i c e bid_{price} bidprice之间有关系, w i n p r i c e win_{price} winprice又受 b i d p r i c e bid_{price} bidprice影响,所以让这个问题变成了一个比较复 杂的全局优化问题, 传统的方法是用贪心的策略去解决, 虽然做不到全局最优, 但起码能做到出价合 理。要彻底解决这个最优化问题依赖非常复杂的数学理论, 我甚至认为在复杂多变的实际竞价环境 下, 即使数学上设计的够严谨, 也无法做到最优的解决这个问题。所以实际竞价环境中我们更希望用 比较实用的含心策略或者控制策略来解决利润最大化的问题。
5. Calibration
我之前写过一篇介绍推荐模型和广告模型区别的文章:
https://zhuanlan.zhihu.com/p/430431149
提到推荐模型的首要任务是要把排序做的更好,而广告模型则要把CTR,CVR估的更准。因为计算广告的ECPM出价公式中,是一定要把CTR,CVR预估的准确,才能出好价,才能不浪费钱。因此,在广告系统中,有一个独特的模块叫做Calibration,就是要在训练出的CTR,CVR模型预估的不太准确的时候,用一个附加模块,把预估值强制地纠偏到后验结果上去。
就比如说,我们把N个样本按照预估CTR值从左到右排列,分100个桶,每个桶N/100个,再根据样本上的label算出后验的CTR,下图中,我们假设灰色的线就是后验CTR,彩色的线是桶内的模型预估值CTR均值,那么显然,左边的黄色预估CVR曲线是不准确的,因为在模型后段明显高估了。而绿色的线显然更为准确,把黄色的线纠正成绿色线的过程就叫做Calibration。
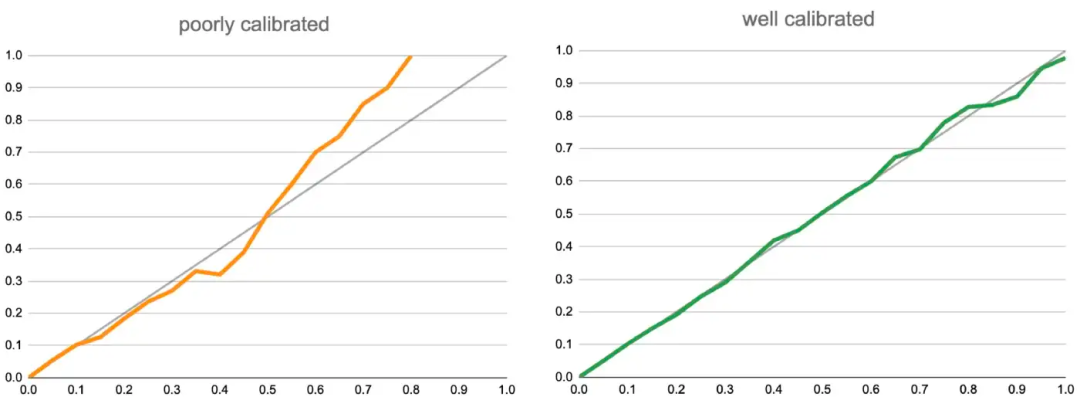
比较经典的Calibration方法是保序回归。就是说我们不改变按预估值排序的样本的顺序,就通过改变预估值来让模型的输出更接近后验分布。事实上,上图中把黄线纠正成绿线的过程就是保序回归的过程。我们并没有让黄线的趋势逆转,只是把它“捋直了”,让他更接近后验了。具体的保序归回方法是非常经典的统计方法,大家可以很容易查到具体的资料。
由于现在主流的CTR,CVR预估模型都是深度学习模型,所以针对深度学习模型本身的Calibration方法也是层出不穷,比如做model ensemble,模型中加一些bias,模型里建一个专门用来calibration的tower等等。这里介绍一个Instacart工程师,提出来的方法,比较简单易用,也可以一试。
https://tech.instacart.com/calibrating-ctr-prediction-with-transfer-learning-in-instacart-ads-3ec88fa97525
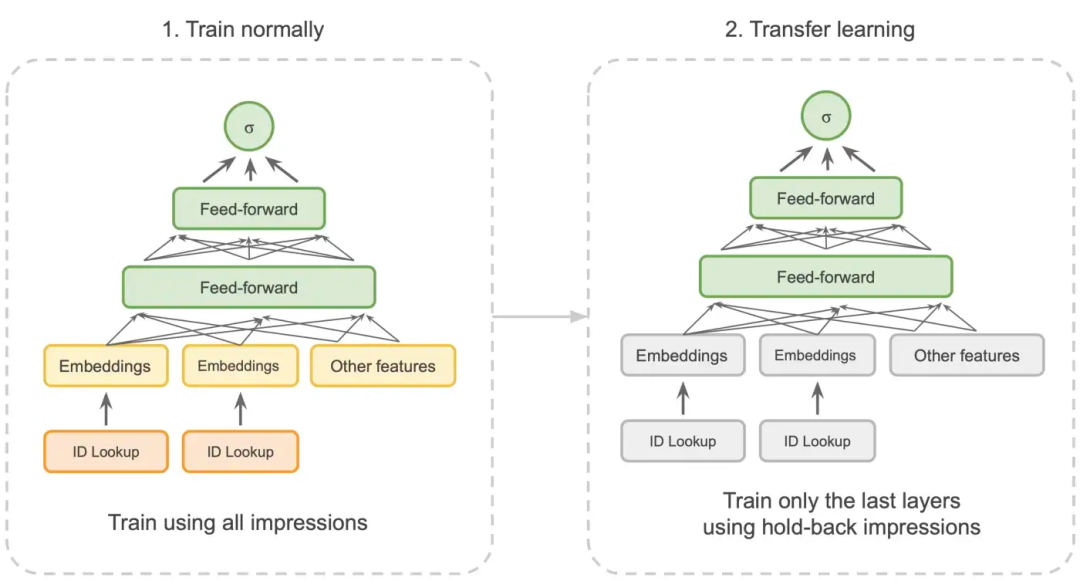
他采用的方法是在广告请求中随机选出一部分流量作为无偏的随机流量,当然它们产生的训练样本就是无偏的训练样本。当你用全量数据集训练好模型之后,锁定模型较低层的参数,再用这个无偏的小数据集训练最上面的1-2层,把模型输出纠正为无偏输出。这个方法说好听点叫transfer learning,说的直白点其实就是一个巧妙的纠偏技巧。这个方法的实用之处在于我们的数据本身大多数情况下都是有偏的,因为我们经历了流量筛选,模型排序等步骤,投出去的样本大概率是被自己系统带偏的,这时候保留无偏数据集做calibration就是非常重要的把模型带出“坑”的一步。否则整个广告系统有可能像一个不稳定正反馈系统一样,越走越偏。
6. 转化样本延迟问题
最后我想谈一谈的是困扰了效果广告系统好多年的一个问题,就是转化样本回传的延迟问题。我6年前做DSP的时候就被这个问题折磨的不行,没想到这两年回到广告方向,这个问题还是那么痛。我们看看这几年广告行业的工程师们有哪些奇思妙想来解决这个问题的:
部分内容引用自:
https://zhuanlan.zhihu.com/p/506476146
转化延迟问题这么痛的原因是它让模型很难处理那些转化延迟很长的样本,把它们当作正样本也不是,负样本也不是,如果一开始当作负样本训练,未来转化回传回来,样本翻正了之后也很难处理。2014年Criteo有一篇影响力很大的文章提出了一个经典的解法,就是在CVR模型训练过程中加入一个预估转化延迟的模型DFM(Delayed Feedback Model)。这个DFM模型主要用来预测转化延迟在训练窗口外到来的概率p(d>w0|y=1)。于是CVR模型的loss function就可以改写成如下的形式。
L delay = − 1 N ∑ i = 1 N y i log [ f θ ( x i ) p ( d i ≤ w o ∣ y = 1 ) ] + ( 1 − y i ) log [ 1 − f θ ( x i ) + f θ ( x i ) p ( d i > w o ∣ y = 1 ) ] \mathcal{L}_{\text {delay }}=-\frac{1}{N} \sum_{i=1}^N y_i \log \left[f_\theta\left(x_i\right) p\left(d_i \leq w_o \mid y=1\right)\right]+\left(1-y_i\right) \log \left[1-f_\theta\left(x_i\right)+f_\theta\left(x_i\right) p\left(d_i>w_o \mid y=1\right)\right] Ldelay =−N1i=1∑Nyilog[fθ(xi)p(di≤wo∣y=1)]+(1−yi)log[1−fθ(xi)+fθ(xi)p(di>wo∣y=1)]
那么这个DFM模型如何训练呢?是和CVR模型进行利用EM方法联合训练的,先固定CVR模型,训练DFM模型,再固定DFM模型,训练CVR模型直到二者收敛。
DFM的方法虽然听上去很合理,但真要去实现的话可能算法工程师们都会望而却步,因为这种联合训练的方法不是标准的建模方法,而且需要进行多轮的EM迭代,费时又费力。
比较实用的方法是通过延迟下发正样本+Calibration的方案来解决。就是模型在收到点击样本的时候就当作负样本去训练,在收到延迟转化样本的时候直接当作一个正样本去训练。那这样的话模型肯定是有偏啊,那就在模型之后依赖Calibration模型去纠偏,因为Calibration模块会考虑较长时间稳定的后验CVR,因此可以把模型纠正到正确的后验上来。
除此之外,今年阿里在WWW上发表的一篇论文也挺有意思:
https://arxiv.org/pdf/2202.06472.pdf
简单来说,阿里提出了一种叫做Bi-DEFUSE的模型结构,在shared base上分出两个头,分别预估转化窗口内的CVR,和转化窗口外的CVR。然后在预估最终CVR的时候,再把二者加起来。

这样的模型有什么好处呢?站在一个工程师的角度就是模型的稳定性和准确性都能够得到保证。因为左边塔代表的窗口内CVR头完全不受转化延迟的影响,可以认为预估值是准确的,这个头保证了模型的稳定性。
而右边的头则可以用一系列的纠偏方法专注于预估转化窗口外的延迟转化。比如原文中采用了一种叫DEFUSE的纠偏方法,实际操作中,我们也可以采用不同方法来实现这部分的设计,甚至可以为这部分独立建模,然后再跟窗口内CVR模型做bagging。独立建模之后,我们可以彻底忽略转化延迟对左侧模型的扰动,让转化回传的影响完全可控。
四、王喆对广告算法工程师的看法
洋洋洒洒写了这么多,说是“深度”学习计算广告,其实也只是过了一遍当前广告系统面临的主要问题和相应的解决方法。之前写过一篇文章,叫算法工程师的天地之间:
https://zhuanlan.zhihu.com/p/495479206
说到系统架构是天,数据和技术细节是地,我们算法工程师们只有了解“天”才能不出方向性的错误,而只有踏踏实实的踩在“地”上,去分析数据的细节,了解技术的具体实现,才能真正做出实际的效果,这一点在广告系统这种工程实践属性非常强的领域尤甚。
这篇文章,顶多让你了解一下广告系统的天,而实际的工作都是基于对琐碎数据的观察,工程和算法的联合优化带来的。实际工作中最欠缺的人才,应该是广告系统体系烂熟于胸,但却能躬亲入局,查看算法和数据细节的人。工作中也无时无刻不在出现新的问题,不可能是paper中包括的,因此灵活地,针对性地解决这些问题,才是真正优秀的算法工程师。
计算广告发展到今天,已经度过了粗放型生长的阶段。业界大的红利也早已经被拿走。但相比推荐系统日益追求精深的推荐模型来说,广告系统的各大模块极度依赖工作经验。没做过就是没做过,做过了就是有不一样的思考和深度。当深度学习模型技能已经变成算法基本功的当下,去踏踏实实地在一个领域做精做深,学会主动思考,主动去解决问题,反而有可能成为业界不可多得的人才。