1.机器学习的分类
- 监督学习(Supervised Learning)是指从已标注的训练数据中学习判断数据特征,并将其用于对未标注数据的判断的一种方法。
- 无监督学习(Unsupervised Learning)不同于监督学习,它的学习算法是从没有标注的训练数据中学习数据的特征。
2.深度学习和机器学习的区别
二者提取特征的方式不同:深度学习具备自动提取抽象特征的能力,机器学习大多是手动选取特征和构造特征。
3.深度学习的典型特点
- 多层结构:深度学习模型通常由多层神经网络组成。
- 自动特征学习:深度学习模型能够自动从原始数据中学习有用的特征表示。
- 高模型容量和表达能力:深度学习模型能够拥有足够多的参数和层级,以适应更复杂、更抽象的任务。
- 分布式并行计算,利用CPU、TPU等计算资源。
- 强大的泛化能力。
4.深度学习的发展历程
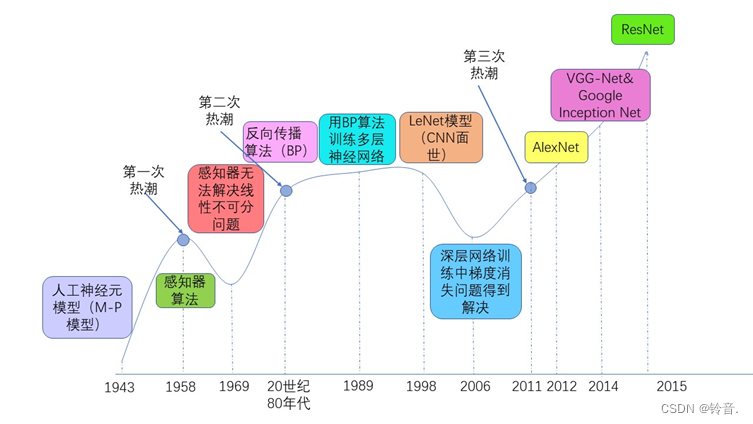
- 第一阶段:萌芽期(20世纪40年代~80年代) 1943年,美国神经生理学家沃伦·麦卡洛克(Warren McCulloch)和数学家沃尔特·皮兹(Walter
Pitts)通过对生物神经元建模,首次提出了人工神经元模型,该模型被称为M-P模型。 - 第二阶段:发展期(20世纪90年~2011年) 20世纪80年代,罗森•布拉特提出的适用多层感知机的反向传播算法(Back Propagation,BP)解决了线性不可分问题,引起了神经网络的第二次热潮。BP算法的提出使得神经网络的训练变得简单可行。到了1989年,被称为卷积神经网络之父的杨立昆 (Yann LeCun)利用BP算法训练多层神经网络并将其用于识别手写邮政编码,这个工作可以认为是卷积神经网络(Convolutional Neural Network,CNN)的开山之作。
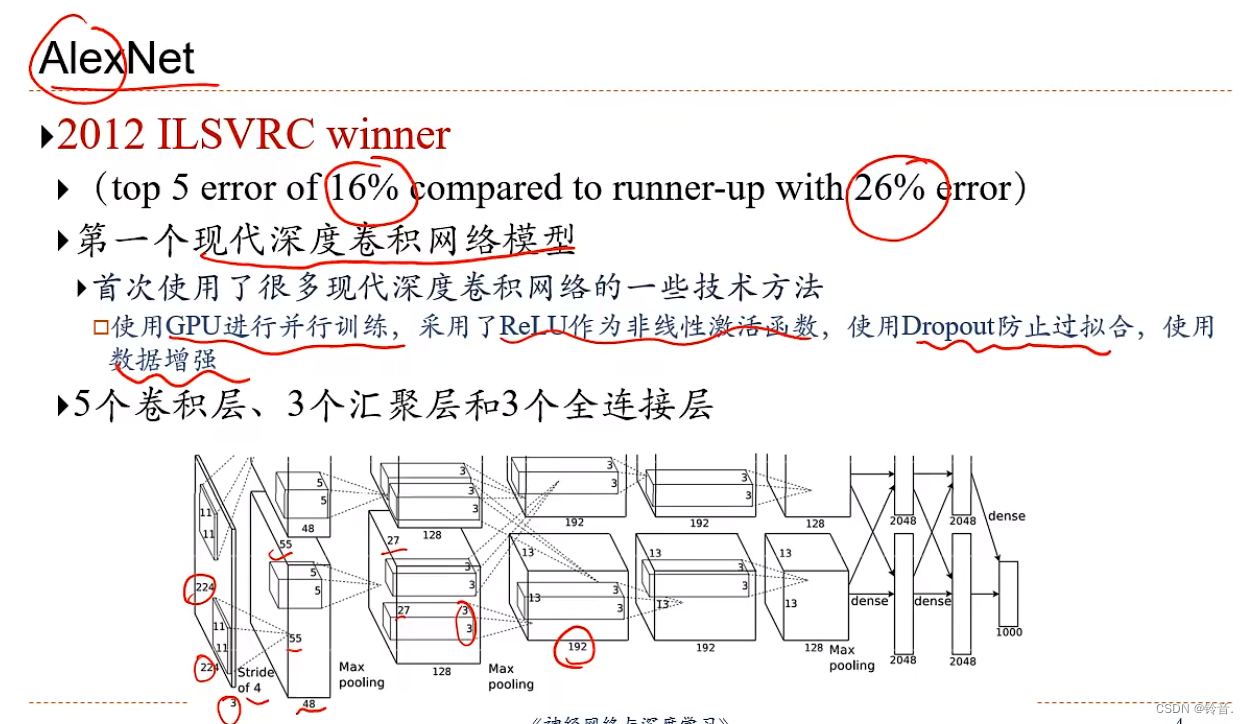
- 第三阶段:爆发期(2011年至今) 硬件资源发展,开始使用GPU 2012年Hinton课题组构建了AlexNet。2014年,由牛津大学VGG(Visual Geometry
Group)提出的VGG-Net获得ImageNet竞赛定位任务的第一名和分类任务的第二名,同年分类任务的第一名则是被Google的Inception网络夺得。2015年,ResNet横空出世,在ILSVRC和COCO大赛上获得冠军。2017年,Google提出的移动端模型MobileNet以及CVPR2017的DenseNet模型在模型复杂度以及预测精度上又做了很多贡献。
5.深度学习基础框架
- TensorFlow:由Google开发的开源深度学习框架,提供了丰富的工具和库,支持跨多个平台和设备进行高性能计算。TensorFlow使用静态计算图来定义和执行计算任务。
- PyTorch:由Facebook开发的开源深度学习框架,具有简单易用的API和动态计算图的特点。PyTorch的设计理念更贴近Python编程风格,使得模型的构建和调试更加方便。
- Keras:一个高级神经网络API,可以作为TensorFlow、PyTorch等后端运行。它提供了简洁的API接口,使得深度学习模型的构建、训练和评估更加快捷和便利。
- MXNet:一个可扩展、高效的深度学习框架,支持多种编程语言,包括Python、R、Julia等。MXNet提供了符号式和命令式两种编程方式,具有良好的灵活性。
- Caffe:一个用于快速搭建神经网络的深度学习框架,以速度和效率为重点。Caffe采用了C++编写,支持CPU和GPU加速,适合在计算资源有限的情况下进行快速原型开发。
6.M-P神经元模型、感知机模型和多层感知机模型的区别?
M-P神经元模型
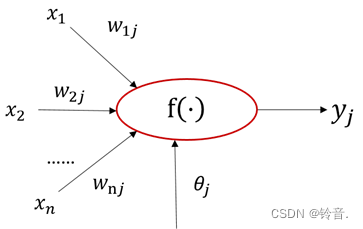
该模型旨在模拟从多输入到单输出的信息处理单元。
M-P模型的工作步骤:
- 神经元接受n个输入信号。
- 将输入与权值参数进行加权求和并经过激活函数激活。
- 将激活结果作为结果输出。
人为设定参数值。
output = step_function(sum(inputs * weights) - threshold)
其中,inputs表示输入信号向量,weights表示权重向量,threshold表示阈值,sum表示求和操作,step_function表示阶跃函数,输出为0或1。
感知机模型
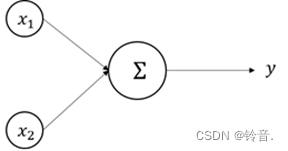
旨在建立一个线性超平面用来解决线性可分问题。
对样本数据的训练自动获得对参数的更新结果。
感知机学习机制:
- 准备训练样本和对权值参数进行初始化
- 加入一个训练样本,并计算实际输出值
- 比较实际输出值和期望输出值的大小,如果相同,则参数不变;如果不同,则需要通过误差修正调整参数大小
- 对每个训练样本重复上述步骤,直到计算的误差为0或者小于某个指定的值
感知机运行原理:
假设 𝑥1,𝑥2是输入信号;𝑤1,𝑤2是权重,控制输入信号的重要性;𝑦 是输出信号,在感知机中,只有两种输出,其中,0 代表“不传递信号”,1 代表“传递信号”。当输入信号被送往神经元时,分别乘以各自的权重,然后加总,如果总和超过阈值 𝜃 ,则𝑦的输出为 1 ,否则为 0 。抽象为公式如下:
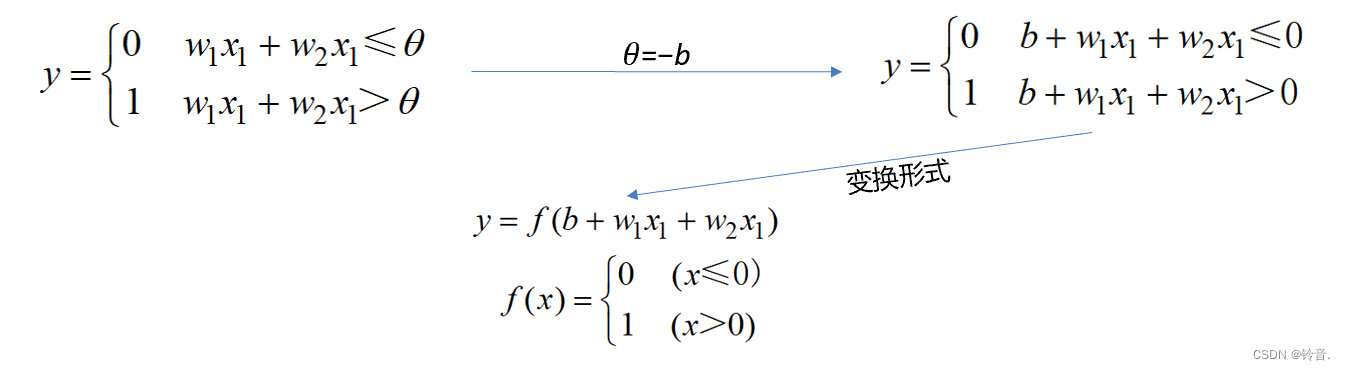 感知机模型局限性:
感知机模型局限性:
仅对线性问题具有分类能力——它只能表示由一条直线分割的空间,而对由曲线分割而成的非线性空间却无能为力
多层感知机模型
就是在输入层和输出层之间加入了若干隐藏层,以形成能够将样本正确分类的凸域,使得神经网络对非线性情况的拟合程度大大增强。
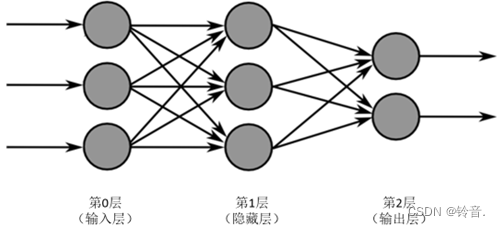
层数计算:不计输入层,把除去输入层之后的神经网络从左至右依次计数得到的总层数,就是神经网络的最终层数。如上图层数为2。
上图网络又称为全连接神经网络。全连接是指神经网络模型中,相邻两层单元之间的连接方式,使用全连接方式时,网络当前层的单元与网络上一层的每个单元都存在连接。
激活函数的引入使得多层感知机具备了非线性建模的能力。
- 非线性转换:
激活函数将输入信号进行非线性转换,从而在每个节点上引入非线性操作。在单层感知机中,由于仅使用线性激活函数(如恒等函数),无法对输入数据进行非线性分类。这是因为线性函数的输出仍然是输入的线性组合,无法表达非线性关系。通过引入非线性激活函数,如ReLU、Sigmoid、Tanh等,可以在每个节点上引入非线性操作,使得多层感知机能够学习和表示更加复杂的非线性关系。 - 多层叠加:
多层感知机通过将多个全连接层叠加在一起,将前一层的输出作为后一层的输入。每个层都通过激活函数进行非线性转换,并传递给下一层。这种层叠的结构使得网络可以通过组合多个非线性操作来逐渐构建更加复杂的非线性模型。每一层都可以学习到不同层次的抽象特征,通过层层叠加,模型可以逐渐提取出更高级别、更复杂的特征表示。这样,多层感知机在处理复杂问题时能够更好地拟合数据,实现非线性建模。
7.激活函数的作用
激活函数是神经网络中的一个重要组成部分,它的作用主要有以下几点:
- 1.引入非线性:激活函数的主要作用是将输入信号进行非线性变换。神经网络的每一层都使用激活函数对输入信号进行处理,从而使神经网络具有处理非线性关系的能力。如果没有激活函数,多层神经网络就会退化成线性模型,无法学习和表示复杂的非线性关系。
- 2.增强表达能力:激活函数的非线性变换可以增加神经网络的表达能力,使得网络能够学习和表示更加复杂的函数关系。通过激活函数的作用,神经网络可以捕捉到不同特征之间的非线性关系,从而提高了网络对输入数据的建模能力。
- 3.实现信号的稀疏性:有些激活函数具有稀疏性的特点,即对于某些输入值,激活函数的输出为0,称为稀疏激活。稀疏激活可以使得神经网络在处理大规模数据时,仅激活部分神经元,从而减少计算量和存储空间。
- 4.归一化输入和输出:激活函数可以对输入和输出进行归一化处理,使得输入和输出值的范围在一个合适的区间内,利于神经网络的训练和优化过程。常用的激活函数如sigmoid、tanh 和 ReLU 等都具有将输入值映射到一定范围内的特性。
总之,激活函数在神经网络中起到了非常重要的作用,通过引入非线性变换和增强表达能力,它使得神经网络可以学习和表示复杂的非线性关系,从而提高了网络的建模能力。
8.分别在什么场合下应用
不同的激活函数适用于不同的场合。以下是常见的场合和适用的激活函数:
sigmoid 激活函数:
- 二分类问题:sigmoid 函数的输出范围在 (0, 1) 之间,可以将输出解释为概率值,适用于二分类问题的输出层。(输出层)
- 强调信号的非线性:sigmoid 函数具有平滑的 S 形曲线,适用于在神经网络中引入非线性,使得网络能够学习和表示非线性关系。(隐藏层)
tanh 激活函数:
- 多分类问题:tanh 函数的输出范围在 (-1, 1) 之间,可以用作多分类问题的输出层,代表不同类别的概率分布。
- 强调信号的对称性:tanh 函数是关于原点对称的,可以保持输入数据的正负号,适用于需要保持输入数据的符号信息的场景。
ReLU 激活函数(Rectified Linear Unit):
- 隐藏层激活函数:ReLU 函数将负数输入映射为0,而对于正数输入则保持不变,可以有效地缓解梯度消失问题,适用于神经网络的隐藏层激活函数。
- 提升稀疏性:ReLU 函数的输出在正数范围内全为非零值,对于稀疏性的要求较高的任务,如自动编码器等,ReLU 函数可以更好地实现。
9.神经网络的训练流程
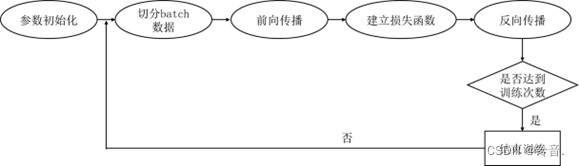
Epoch(时期)是指将全部训练数据在神经网络上正向传播和反向传播的次数。
- 一个 Epoch 表示模型使用整个训练数据集(包含多个样本)进行一次前向传播和一次反向传播的过程。在每个 Epoch
中,模型对所有的训练样本进行处理并更新模型的参数。一个 Epoch
的完成意味着模型已经完整地遍历了一次整个数据集,并通过反向传播来更新了所有的权重和偏置等参数。 - 为什么要使用 Epoch
这个概念呢?因为训练神经网络的过程中,通常需要进行多次的迭代训练才能使模型达到较好的性能。每次迭代训练都会更新模型参数,但并不保证模型已经完全学习到数据的特征。通过多次迭代训练,模型可以逐渐优化,提高自己的性能。而一个Epoch 则表示了一次完整的数据集遍历,可以看作是迭代训练的一个单元。 - 在训练过程中,经常会设置一个合适的 Epoch 数量来控制模型的训练轮数。选择恰当的 Epoch数量取决于问题的复杂度、数据集规模和模型的收敛速度等因素。较小的 Epoch 数量可能导致模型欠拟合,而较大的 Epoch数量则可能导致过拟合,因此需要进行适当的调节和实验。
一般来说,在深度学习的训练过程中,我们需要使用大规模的数据集来训练模型。如果一次性将所有的数据都用于训练,会导致内存占用过大,而且训练时间也会非常长。因此,我们通常将训练数据切分成小的批次(batch),每个批次中包含固定数量的数据样本,然后在这些批次上进行训练。
具体地,切分 batch 数据一般可以按照以下步骤进行:
- 首先,我们需要加载并打乱整个训练数据集,以保证每个批次中的数据都是随机的。打乱的目的是为了避免样本之间的相关性,并使模型更好地泛化。
- 接下来,我们需要将打乱后的训练数据集分割成多个大小相等的 batch。每个 batch
的大小通常设置为2的次幂,比如32、64、128等,这样有利于 GPU 进行优化计算。 - 在每个 epoch 中,将每个 batch 的数据送入模型进行训练。具体地,选择一个 batch,将该 batch
中的数据输入给模型,得到该批次数据的预测值,并计算预测值与真实标签之间的损失。然后根据损失计算每个参数的梯度,并使用优化算法(如随机梯度下降)更新模型的权重。这样,经过多个
epoch 的训练,模型的性能逐渐提高。 - 在训练过程中,通常会对每个 batch 进行多次迭代训练,以进一步提高模型的学习效果。对于每个
batch,可以设置一个固定的迭代次数,也可以在训练过程中动态调整。
10.损失函数
损失函数通常表示为真实值与预测值之间的距离。
- 均方误差:回归
- 交叉熵:分类
11.梯度下降、批量梯度下降、随机梯度下降的区别和联系
联系:都是基于梯度下降算法的策略
区别:执行一次所需的样本量不同
单个样本指的是训练数据集中的一个独立的数据样本,它由输入特征和对应的标签(或目标)组成。在机器学习和深度学习中,通常使用一组样本来训练模型。
一个小的随机子集是指从整个训练数据集中随机选择出的一部分样本。这个子集通常包含相对较少的样本,但足够大以代表整个数据集的特征。通过使用随机子集,可以在每次迭代中使用不同的样本来计算梯度,从而减少计算开销,并引入一定程度的随机性。
梯度下降使用整个训练集,批量梯度下降也使用整个训练集,而随机梯度下降只使用单个样本(或一个小的随机子集)。这导致了它们的计算代价和收敛速度不同。同时,随机梯度下降相对于另外两种算法来说更容易陷入局部最优解,但在大规模数据集上具有更高的效率。
12.改进批量梯度下降算法
动量梯度下降算法(Momentum Gradient Descent):
在标准的梯度下降算法中,参数更新的方向只取决于当前的负梯度。然而,这样的方法容易受到参数空间中的局部最优解和谷底的干扰,导致收敛速度较慢。动量梯度下降算法引入了动量项来解决这个问题。具体来说,动量项考虑了之前的梯度方向,并在参数更新时累积了一个速度。这样就产生了一个惯性效应,使得参数更新的方向不仅仅取决于当前的梯度,而是综合了之前的梯度信息。通过这种方式,动量梯度下降算法可以跳出局部最优解,并加快收敛速度。
均方根加速算法(Root Mean Square Propagation,RMSProp):
学习率是优化算法中一个非常重要的超参数,它控制着参数更新的步长。然而,固定的学习率在不同的参数空间和不同的方向上可能不适用。为了解决这个问题,RMSProp算法引入了自适应学习率的概念。具体来说,RMSProp算法通过对梯度进行指数加权移动平均,计算出每个参数的梯度方差的估计。然后,使用这个方差的估计值来调整学习率,以适应参数空间中不同方向的变化。这样就使得在梯度较大的方向上,学习率较小,而在梯度较小的方向上,学习率较大。这种自适应性可以提高训练的效果。
自适应矩估算法(Adaptive Moment Estimation,Adam):
Adam算法是一种结合了动量梯度下降和RMSProp的优化算法。它利用了梯度的一阶矩估计和二阶矩估计来自适应地调整学习率。具体来说,Adam算法使用了梯度的一阶矩(均值)的估计和二阶矩(方差)的估计来更新参数。通过计算一阶矩和二阶矩的移动平均,Adam算法能够自适应地调整每个参数的学习率。这种自适应性可以在训练过程中平衡不同参数的更新速度,并且在参数空间中变化较大的方向上减小学习率。Adam算法具有较快的收敛速度和较好的性能,在深度学习中被广泛使用。
这些改进算法在梯度下降过程中引入了动量信息、自适应学习率以及参数更新时的指数加权移动平均等机制,能够提高收敛速度、稳定性和全局最优解的搜索能力。根据具体情况,可以选择合适的算法进行优化。
13.解决过拟合的方法
增加数据量,损失函数中加入正则化,使用Dropout方法。
Dropout 是一种广泛使用的正则化技术,通过在训练过程中随机丢弃一部分神经元的输出来减少连接的依赖关系,防止过拟合。通过随机地将一些神经元的输出置为零,Dropout 可以强制模型学习到多个相似的表示,从而提高模型的鲁棒性。
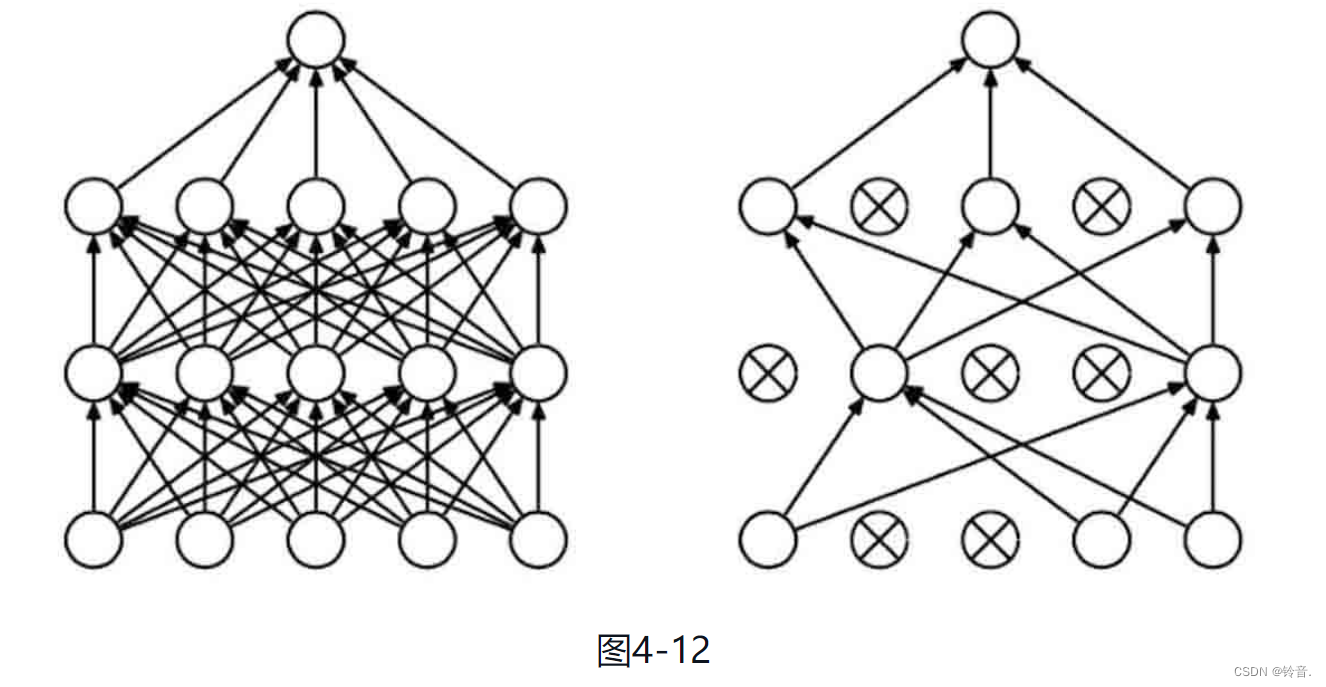
它强迫一个神经单元和随机挑选出来的其他神经元共同工作,减弱了神经元节点间的联合适应性,增强了泛化能力。
14.输出矩阵的维度

18.如何区分Inception,ResNet,DenseNet,MoblieNet的⽹络结构
Inception
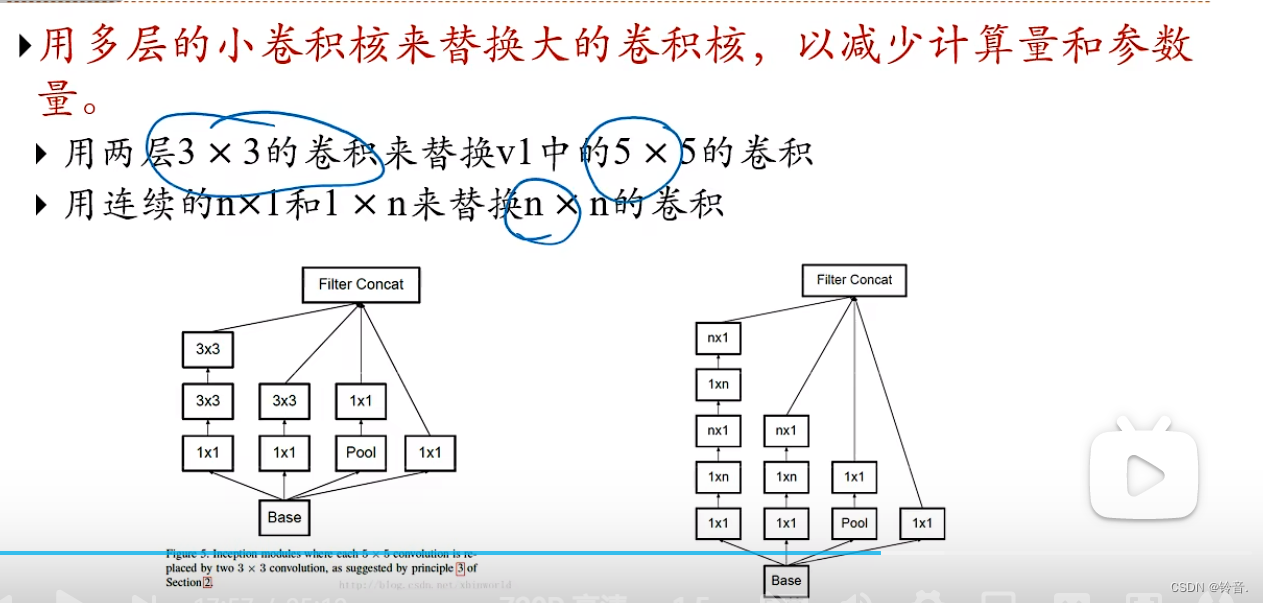
ResNet
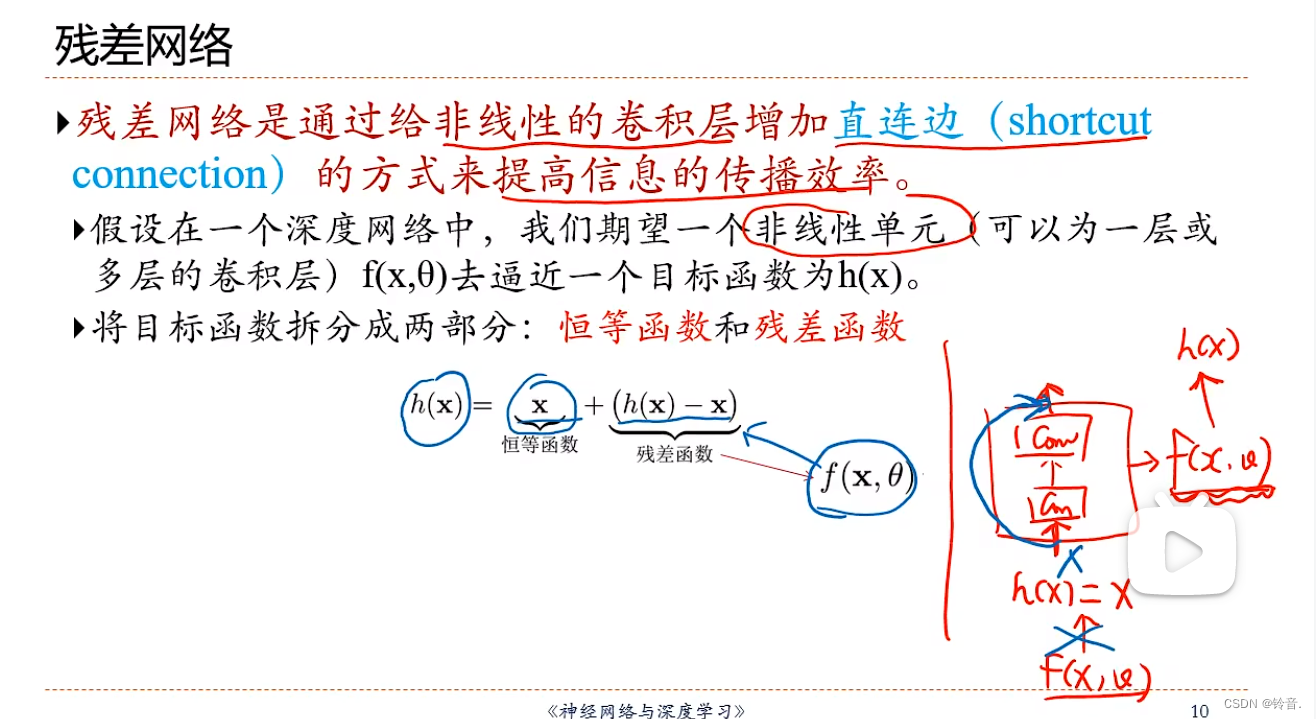
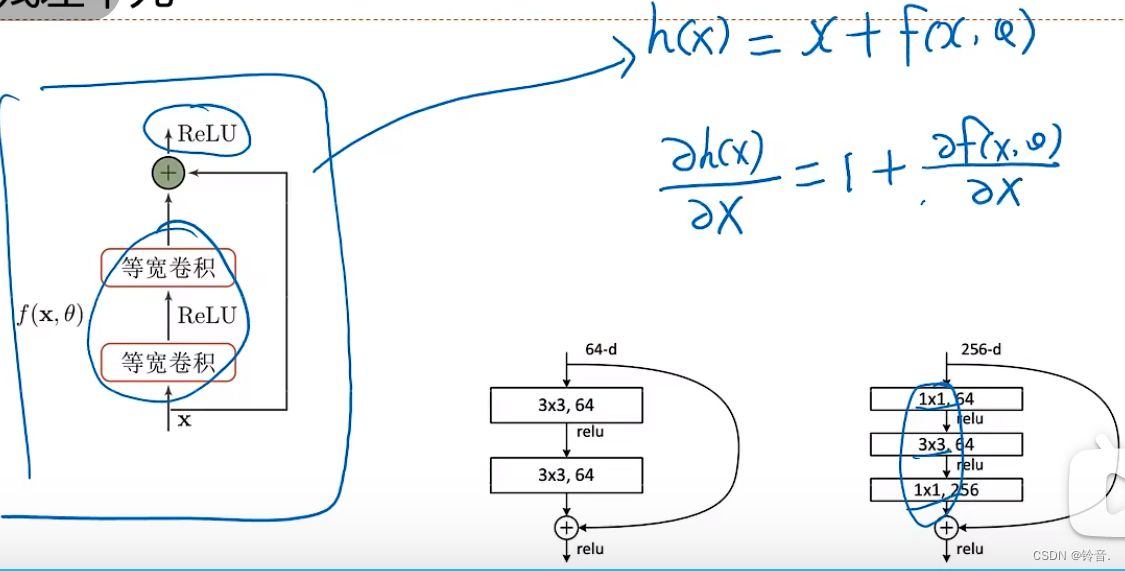
因为求偏导数之后有个1存在,所有梯度不会太小。