Linux系统出现了性能问题,一般我们可以通过top、iostat、free、vmstat等命令来查看初步定位问题。其中iostat可以给我们提供丰富的IO状态数据。
1.小文件读写的磁盘性能瓶颈是寻址(随机读写性能更差)评估标准:TPS
2.大文件读写的磁盘性能瓶颈是贷款,评估标准是持续的读写速度
3.Linux有一个特性是可以用空闲的内存作为Cache,因此大的内存可以很有效的提高存储系统性能.
nmon
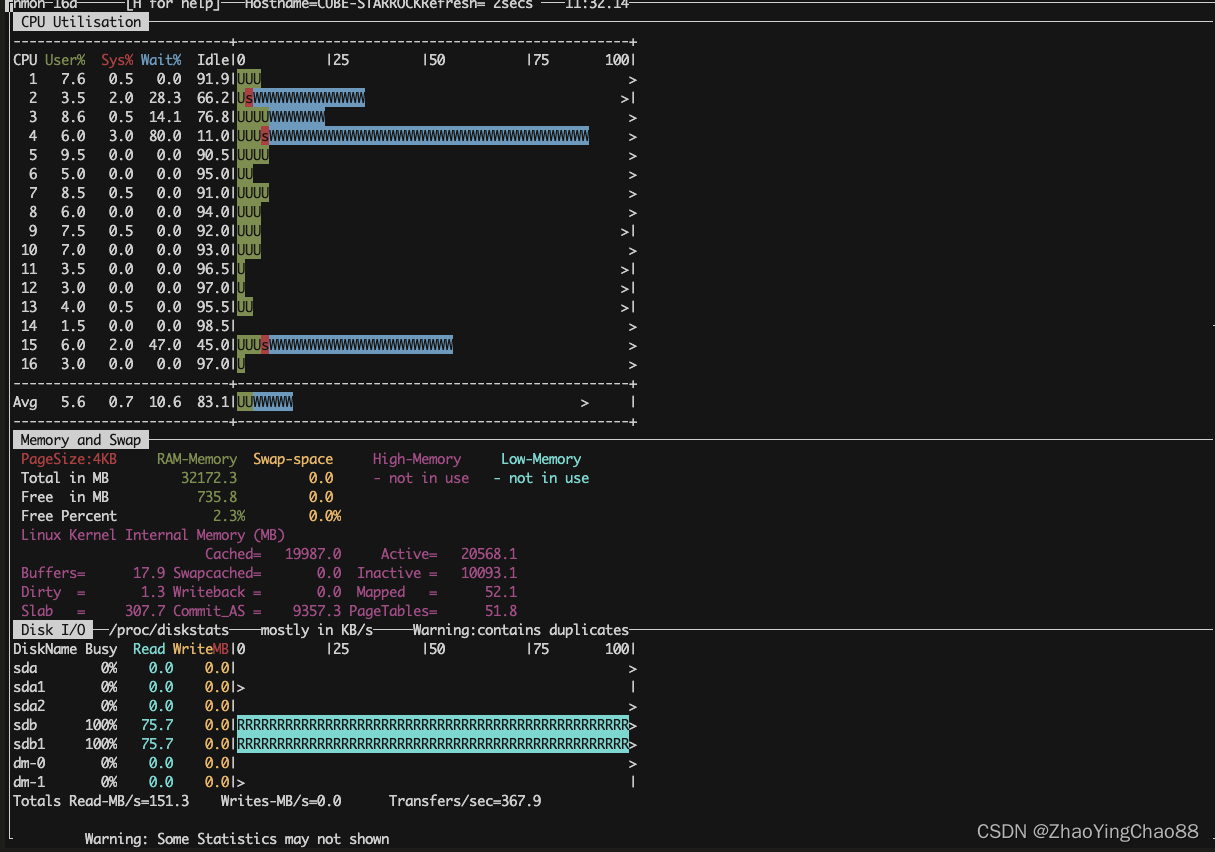
1. 首先分析是不是io引起的系统缓慢(top命令)
top
top - 14:31:20 up 35 min, 4 users, load average: 2.25, 1.74, 1.68
Tasks: 71 total, 1 running, 70 sleeping, 0 stopped, 0 zombie
Cpu(s): 2.3%us, 1.7%sy, 0.0%ni, 0.0%id, 96.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 245440k total, 241004k used, 4436k free, 496k buffers
Swap: 409596k total, 5436k used, 404160k free, 182812k cached
从CPU(s) 这行你可以看出当前CPU I/O Wait的情况;越高的wa表示越多的cpu资源在等待I/O。
2.查找哪个磁盘正在被写入(iostat命令)
iostat -x 2 5
$ iostat -x 2 3
Linux 2.6.32-642.el6.x86_64 (nginx-console-prd-10-20-133-35.bj01.vivo.lan) 10/15/2018 x86_64 (32 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.08 0.00 0.20 0.01 0.00 99.71
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.13 510.12 1.67 18.81 232.08 4231.47 218.01 0.07 3.50 1.68 3.66 0.25 90.52
sdb 0.00 0.02 0.76 0.65 168.25 220.98 276.10 0.00 1.60 0.17 3.28 0.17 0.02
上述示例,sda盘的%utilized达到了90.52%。这表示引起I/O慢的进程在写入sda盘。
————————————————
3.查找引起高I/O的进程(iotop命令)
查看哪个进程使用硬盘最多的最简单的方法就是使用iotop命令。
iotop
Total DISK READ: 8.00 M/s | Total DISK WRITE: 20.36 M/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
15758 be/4 root 7.99 M/s 8.01 M/s 0.00 % 61.97 % bonnie++ -n 0 -u 0 -r 239 -s 478 -f -b -d /tmp
补充扩展:查看io占比大于0.2%的进程
iotop -botqqq --iter=3 | awk '{if ($4 > 0.2) print}'注: -b, --batch 非交互式模式,可以用于写日志。
4.查看高I/O进程的磁盘读写情况
方法一:通过cat /proc/pid/io 便可以获取进程的io信息
cat /proc/16528/io
rchar: 48752567
wchar: 549961789
syscr: 5967
syscw: 67138
read_bytes: 49020928
write_bytes: 549961728
cancelled_write_bytes: 0
rchar: 读出的总字节数,read或者pread()中的长度参数总和(pagecache中统计而来,不代表实际磁盘的读入)
wchar: 写入的总字节数,write或者pwrite中的长度参数总和
syscr: read()或者pread()总的调用次数
syscw: write()或者pwrite()总的调用次数
read_bytes: 实际从磁盘中读取的字节总数 (这里if=/dev/zero 所以没有实际的读入字节数)
write_bytes: 实际写入到磁盘中的字节总数
cancelled_write_bytes: 由于截断pagecache导致应该发生而没有发生的写入字节数(可能为负数)
方法二:通过pidstat工具
pidstat -d -p 98536 2 10(输出io的使用情况)
pidstat -d -p 98536 2 10
Linux 2.6.32-642.el6.x86_64 (bj01.prd.saltdb01.vivo.lan) 12/13/2018 x86_64 (16 CPU)
05:43:11 PM PID kB_rd/s kB_wr/s kB_ccwr/s Command
05:43:12 PM 98536 10000.00 0.00 0.00 mysqld
05:43:13 PM 98536 10000.00 0.00 0.00 mysqld
Average: 98536 10000.00 0.00 0.00 mysqld
5.查看不可中断的进程及僵尸进程的情况
ps -eo state,pid,cmd | grep “^D”
ps -eo state,pid,cmd | grep “^D” (产生D状态的原因出现uninterruptible sleep状态的进程一般是因为在等待IO,例如磁盘IO、网络IO等)
ps -eo state,pid,cmd | grep “^Z”————————————————
iostat工具使用详解
1. 基本使用
$iostat -d -k 1 10
参数 -d 表示,显示设备(磁盘)使用状态;-k某些使用block为单位的列强制使用Kilobytes为单位;1 10表示,数据显示每隔1秒刷新一次,共显示10次。
$iostat -d -k 1 10 Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn sda 39.29 21.14 1.44 441339807 29990031 sda1 0.00 0.00 0.00 1623 523 sda2 1.32 1.43 4.54 29834273 94827104 sda3 6.30 0.85 24.95 17816289 520725244 sda5 0.85 0.46 3.40 9543503 70970116 sda6 0.00 0.00 0.00 550 236 sda7 0.00 0.00 0.00 406 0 sda8 0.00 0.00 0.00 406 0 sda9 0.00 0.00 0.00 406 0 sda10 60.68 18.35 71.43 383002263 1490928140 Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn sda 327.55 5159.18 102.04 5056 100 sda1 0.00 0.00 0.00 0 0
![]()
tps:该设备每秒的传输次数(Indicate the number of transfers per second that were issued to the device.)。“一次传输”意思是“一次I/O请求”。多个逻辑请求可能会被合并为“一次I/O请求”。“一次传输”请求的大小是未知的。
kB_read/s:每秒从设备(drive expressed)读取的数据量;kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;kB_read:读取的总数据量;kB_wrtn:写入的总数量数据量;这些单位都为Kilobytes。
上面的例子中,我们可以看到磁盘sda以及它的各个分区的统计数据,当时统计的磁盘总TPS是39.29,下面是各个分区的TPS。(因为是瞬间值,所以总TPS并不严格等于各个分区TPS的总和)
2. -x 参数
使用-x参数我们可以获得更多统计信息。
iostat -d -x -k 1 10 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util sda 1.56 28.31 7.80 31.49 42.51 2.92 21.26 1.46 1.16 0.03 0.79 2.62 10.28 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util sda 2.00 20.00 381.00 7.00 12320.00 216.00 6160.00 108.00 32.31 1.75 4.50 2.17 84.20
rrqm/s:每秒这个设备相关的读取请求有多少被Merge了(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读 取请求读取的是相同Block的数据,FS会将这个请求合并Merge);wrqm/s:每秒这个设备相关的写入请求有多少被Merge了。
rsec/s:每秒读取的扇区数;wsec/:每秒写入的扇区数。r/s:The number of read requests that were issued to the device per second;w/s:The number of write requests that were issued to the device per second;
await:每一个IO请求的处理的平均时间(单位是微秒毫秒)。这里可以理解为IO的响应时间,一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了。
%util:在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备 的%util = 0.8/1 = 80%,所以该参数暗示了设备的繁忙程度。一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因 为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。
3. -c 参数
iostat还可以用来获取cpu部分状态值:
iostat -c 1 10
avg-cpu: %user %nice %sys %iowait %idle
1.98 0.00 0.35 11.45 86.22
avg-cpu: %user %nice %sys %iowait %idle
1.62 0.00 0.25 34.46 63.67
4. 常见用法
$iostat -d -k 1 10 #查看TPS和吞吐量信息 iostat -d -x -k 1 10 #查看设备使用率(%util)、响应时间(await) iostat -c 1 10 #查看cpu状态
5. 实例分析
$$iostat -d -k 1 |grep sda10 Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn sda10 60.72 18.95 71.53 395637647 1493241908 sda10 299.02 4266.67 129.41 4352 132 sda10 483.84 4589.90 4117.17 4544 4076 sda10 218.00 3360.00 100.00 3360 100 sda10 546.00 8784.00 124.00 8784 124 sda10 827.00 13232.00 136.00 13232 136
上面看到,磁盘每秒传输次数平均约400;每秒磁盘读取约5MB,写入约1MB。
iostat -d -x -k 1 Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util sda 1.56 28.31 7.84 31.50 43.65 3.16 21.82 1.58 1.19 0.03 0.80 2.61 10.29 sda 1.98 24.75 419.80 6.93 13465.35 253.47 6732.67 126.73 32.15 2.00 4.70 2.00 85.25 sda 3.06 41.84 444.90 54.08 14204.08 2048.98 7102.04 1024.49 32.57 2.10 4.21 1.85 92.24
可以看到磁盘的平均响应时间<5ms,磁盘使用率>80。磁盘响应正常,但是已经很繁忙。