文章目录
- 1. Actions as Moving Points
- 摘要和结论
- 引言:针对痛点和贡献
- 模型框架
- 实验
1. Actions as Moving Points
Actions as Moving Points (ECCV 2020)
摘要和结论
MovingCenter Detector (MOCdetector) 通过将动作实例视为移动点的轨迹。通过三个分支生成 tubelet detection results(bbos sequences)。
- (1)中心分支(Center Branch)用于中心检测和动作识别;
- (2)运动分支(Movement Branch)用于相邻帧的运动估计,形成运动点的轨迹;
- (3)盒子分支(Box Branch)用于空间范围检测,通过直接回归每个估计中心的边界框大小。
Tubelet检测结果,可以进一步链接到生成具有匹配策略的视频级管。
引言:针对痛点和贡献
痛点:
- Frame-level Detector:一些早期的方法独立地在每一帧上应用一个动作检测器,然后通过将这些帧级检测结果或跨时间跟踪一个检测结果来生成动作管。这些方法在进行帧级检测时不能很好地捕获时间信息,因此在现实中检测动作管效果较差。
- Clip-level Detector(action tubelet detectors): 现有的小管检测方法与目前主流的目标检测器(如Faster R-CNN[24]或SSD[20])密切相关,这些方法都是在大量的预定义锚盒上运行。ACT [15] 采用了从锚长方体回归的短帧和输出小管序列。STEP [36] 提出了一种渐进式方法,通过几个步骤细化提案以解决大位移问题并利用更长的时间信息。一些方法[12,17]首先链接帧或小管提议来生成管提议,然后进行分类。这些方法都是基于锚点的目标检测器,由于锚点盒数量多,其设计对锚点设计和计算成本比较敏感。
- 首先,随着剪辑时间的增加,可能的小管锚点数量会急剧增加,这对训练和推理都提出了很大的挑战。
- 通常需要设计更复杂的锚盒放置和调整,以考虑沿时间维度的变化。
- 这些基于锚点的方法直接沿着时间维度扩展2D锚点,将每个动作实例预定义为跨越空间和时间的长方体。这种假设缺乏灵活性,无法很好地捕捉相邻帧级边界框的时间相干性和相关性。
贡献:
提出了一个新的检测框架(动作实例视为移动点moving points),并且时Anchor-free的。
模型框架
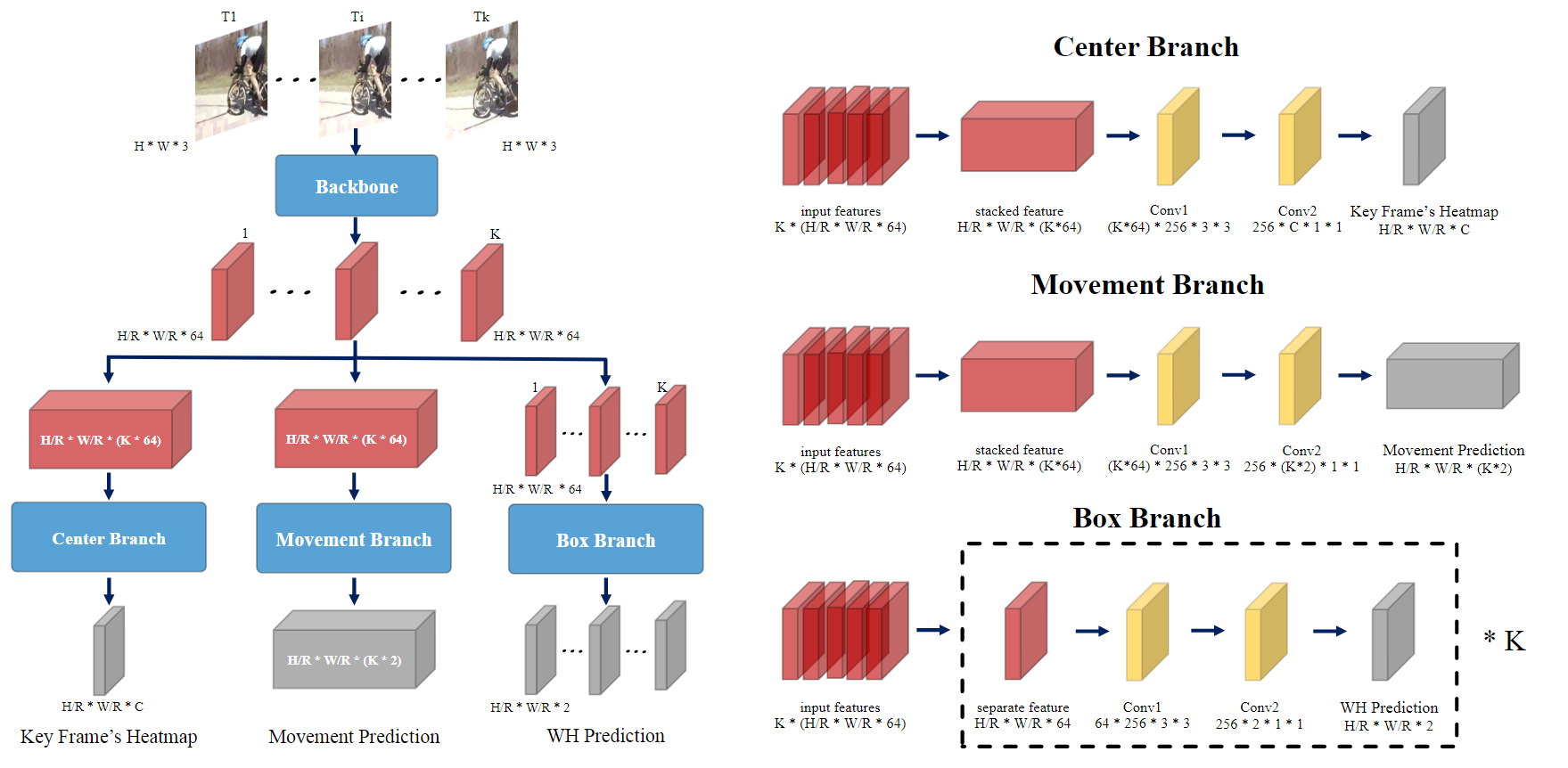
将一组连续的帧作为输入,并将它们分别输入到一个有效的2D主干中,以提取帧级特征。我们设计了三个头部分支,以无锚的方式执行小管检测。这三个分支协同工作以从短剪辑中产生小管检测,这将通过遵循常见的链接策略进一步链接到在长未修剪的视频中形成动作管检测。
-
Backbone:输入 K 帧,每帧的分辨率为 W × H。R=4 是空间下采样率,B=64 表示通道数。为了保留完整的时间信息以供后续检测,我们不对时间维度执行任何下采样。具体来说,我们选择 DLA-34 [38] 架构作为我们遵循 CenterNet [41] 的 MOC 检测器特征主干。该架构采用编码器-解码器架构来提取每个帧的特征。提取的特征由三个头分支共享。
输出特征大小为:K * W/R * W/R * B -
Center Branch: Detect Center at Key Frame : 目的是检测关键帧(即中心帧)中的动作实例中心,并根据提取的视频特征识别其类别。
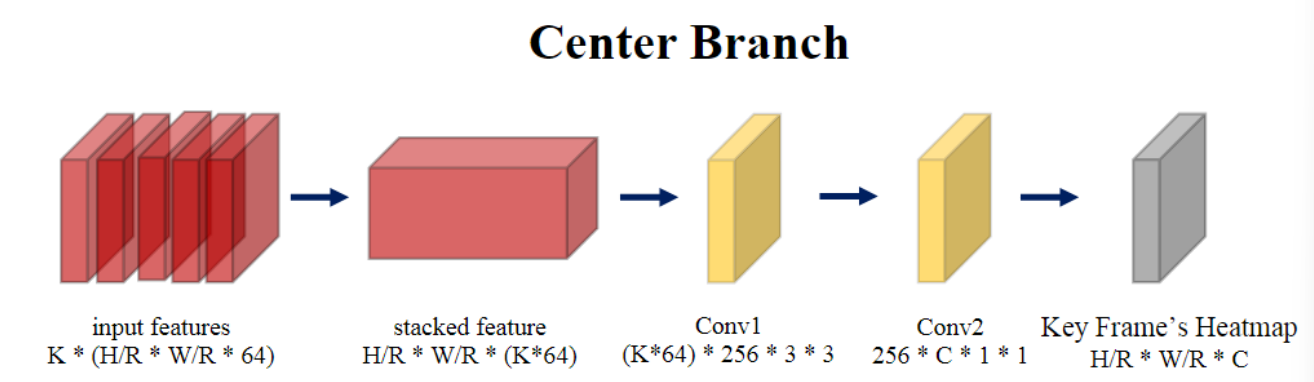
时间信息对于动作识别很重要,因此我们设计了一个时间模块来估计动作中心并通过沿通道维度连接多帧特征图来识别其类别。
估计关键帧的中心热图 ˆL ∈ [0, 1] W/R × H/R ×C。C 是动作类别的数量。 ^L(x,y,c) 的值表示在位置 (x, y) 处检测到类 c 的动作实例的可能性,值越高表示可能性越强。 -
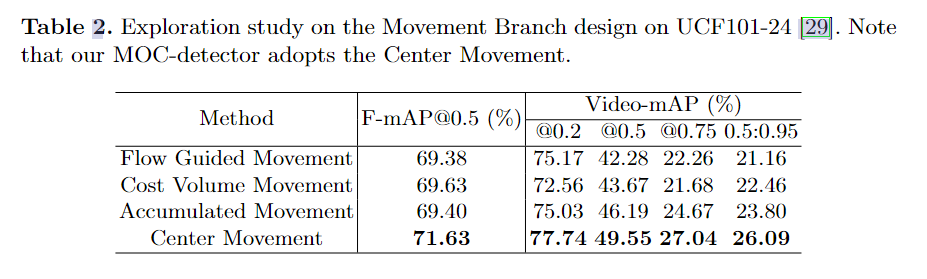
Movement Branch: Move Center Temporally:运动分支尝试关联相邻帧以预测动作实例中心沿时间维度的运动。
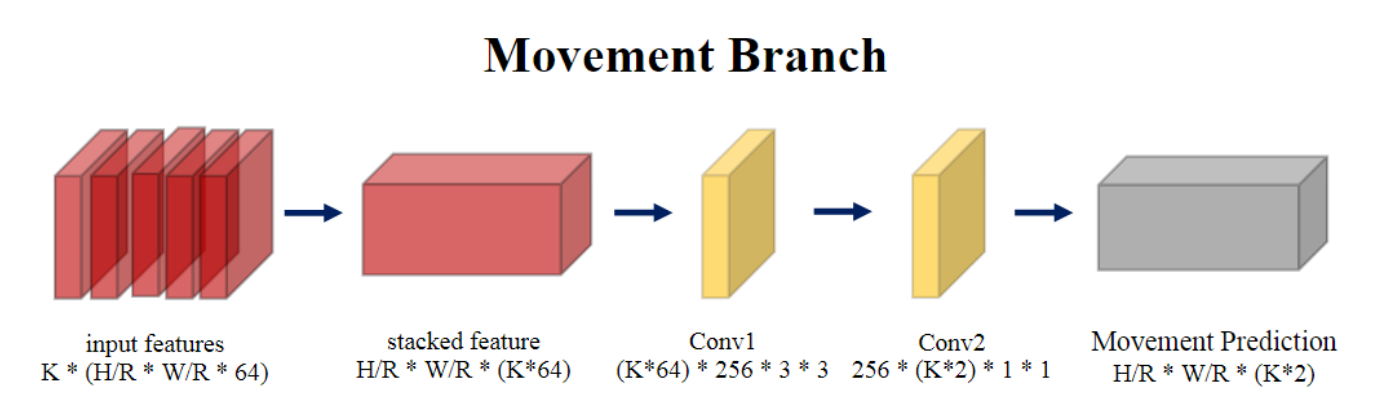
与中心分支类似,运动分支也利用时间信息来回归当前帧相对于关键帧的中心偏移。具体来说,运动分支以堆叠特征表示作为输入,并输出运动预测图 ˆM ∈ W/R × H/R ×(K×2)。 2K 通道表示 X 和 Y 方向上从关键帧到当前帧的中心移动。 -
Box Branch: Determine Spatial Extent:Box Branch 是 tubelet 检测的最后一步,重点是确定动作实例的空间范围。
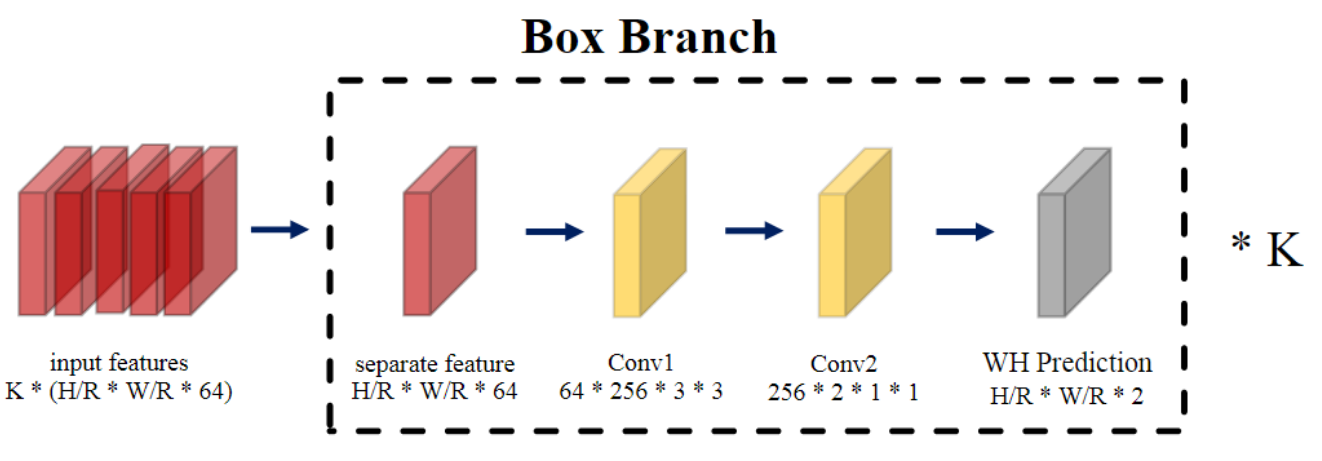
与中心分支和运动分支不同,我们假设框检测仅取决于当前帧,并且时间信息不会有利于与类无关的边界框生成。 我们将在附录 B 中提供消融研究。从这个意义上说,这个分支可以以逐帧的方式进行。具体来说,Box Branch 输入单帧的特征 f j ∈ W/R × H/R ×B 并生成第 j 帧的尺寸预测图 ˆSj ∈W/R × H/R ×2 来直接估计边界框尺寸(即宽度和高度)。请注意,Box Branch 在 K 个帧之间共享。 -
Tubelet Linking:获得剪辑级检测结果后,我们将这些小管跨时间连接成最终的管。MOC模型会对输入的视频进行处理,提取出多个短序列的图像帧,并以每个序列为单位提取出最优的10个候选物体作为候选的区域,这些候选区域会在每个序列中按照一定步长进行滑动,并通过连接每个序列中的候选物体,形成最终的动作管道。
首先,在第一帧中,所有候选动作都会开始一个新的链接。在后续帧中,没有分配到任何现有链接的候选动作会开始新的链接。
在每一帧中,我们按照链接得分的降序扩展现有的链接,使用一个可用的tubelet候选动作作为链接的一部分。链接的得分是该链接中所有tubelet的平均得分。当满足以下三个条件时,一个候选动作只能分配给一个现有链接:(1)候选动作没有被其他链接选择,(2)链接和候选动作之间的重叠大于阈值τ,(3)候选动作拥有最高的得分。
如果一个存在的链接在连续的K帧中没有被扩展,它就会停止。我们为每个链接构建一个动作tube,其得分是链接中所有tubelet的平均得分。对于链接中的每一帧,我们平均包含该帧的tubelet的bbox坐标。初始化和终止确定tube的时间范围。具有低置信度和短持续时间的tube会被丢弃。由于这个链接算法是在线的,因此MOC可以应用于在线视频流。
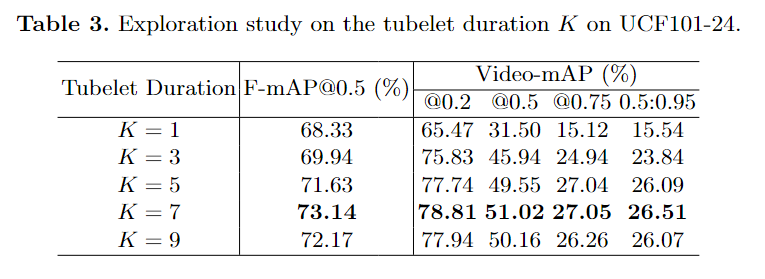
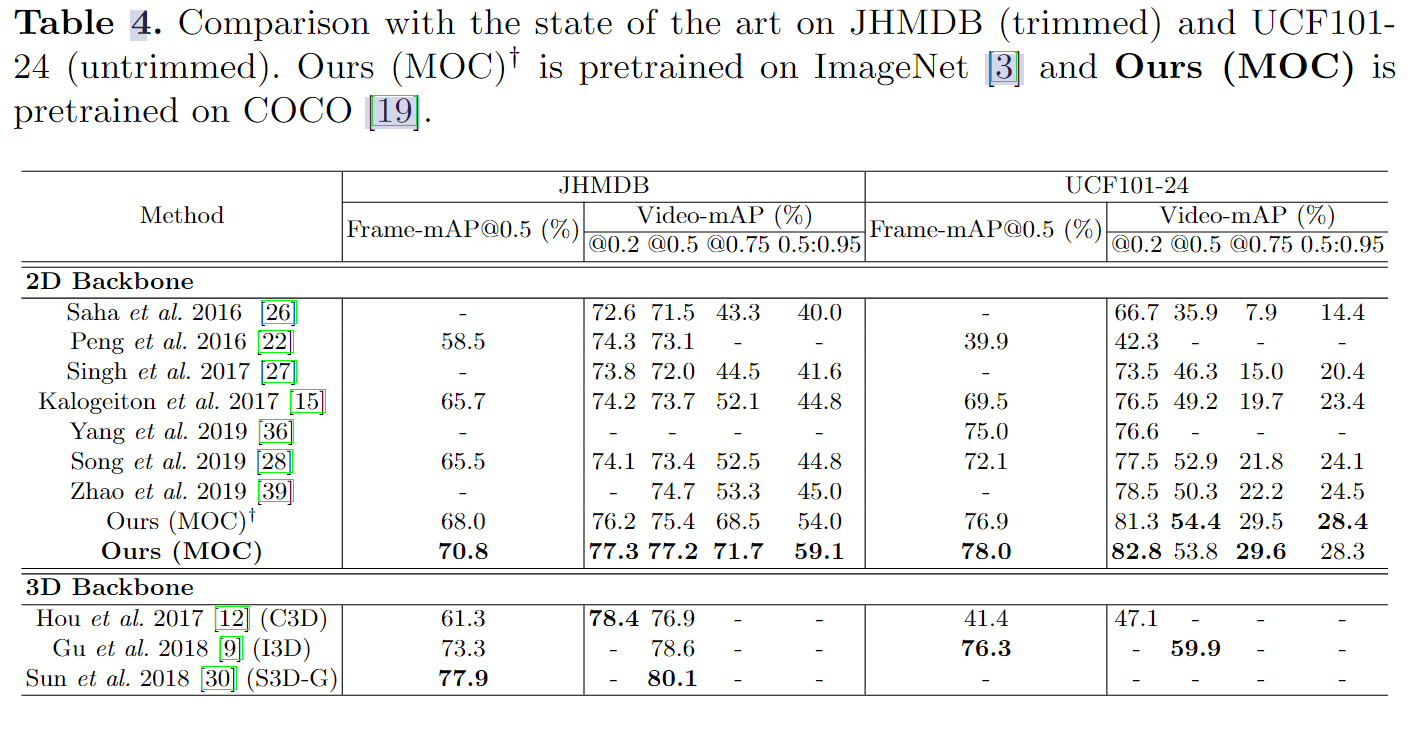
实验