文章目录
- 前言
- 一、背景建模
- 1、帧差法
- 2、混合高斯模型
- 二、光流估计
前言
本文为12月21日 OpenCV 实战基础学习笔记,分为两个章节:
- 背景建模;
- 光流估计。
一、背景建模
1、帧差法
由于场景中的目标在运动,目标的影像在不同图像帧中的位置不同。该类算法对时间上连续的两帧图像进行差分运算,不同帧对应的像素点相减,判断灰度差的绝对值,当绝对值超过一定阈值时,即可判断为运动目标,从而实现目标的检测功能。

帧差法非常简单,但是会引入噪音和空洞问题。
2、混合高斯模型
先对背景进行训练,对图像中每个背景用一个混合高斯模型进行模拟,每个背景的混合高斯的个数可以自适应。
在测试阶段,对新来的像素进行 GMM 匹配,如果该像素值能够匹配其中一个高斯,则认为是背景,否则认为是前景。由于整个过程 GMM 模型在不断更新学习中,所以对动态背景有一定的鲁棒性。
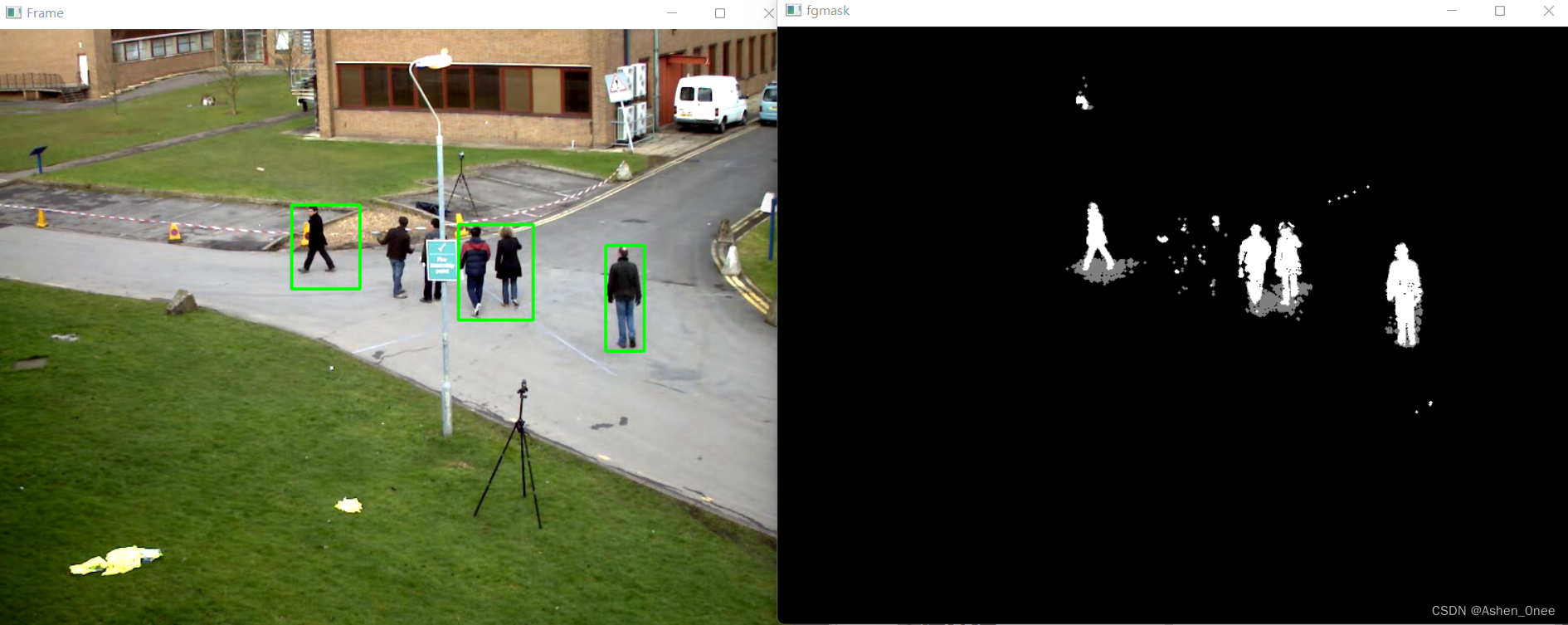
最后通过对一个有树枝摇摆的动态背景进行前景检测,取得较好效果。
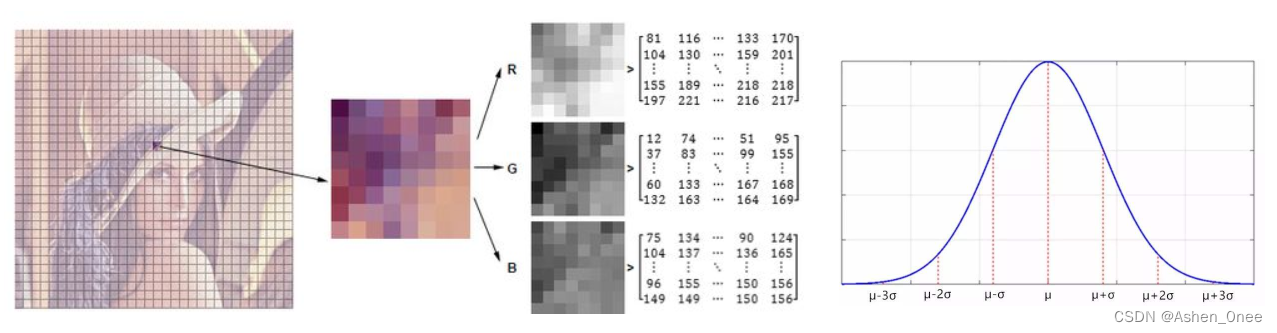
背景的实际分布应当是多个高斯分布混合在一起,每个高斯模型也可以带有权重。
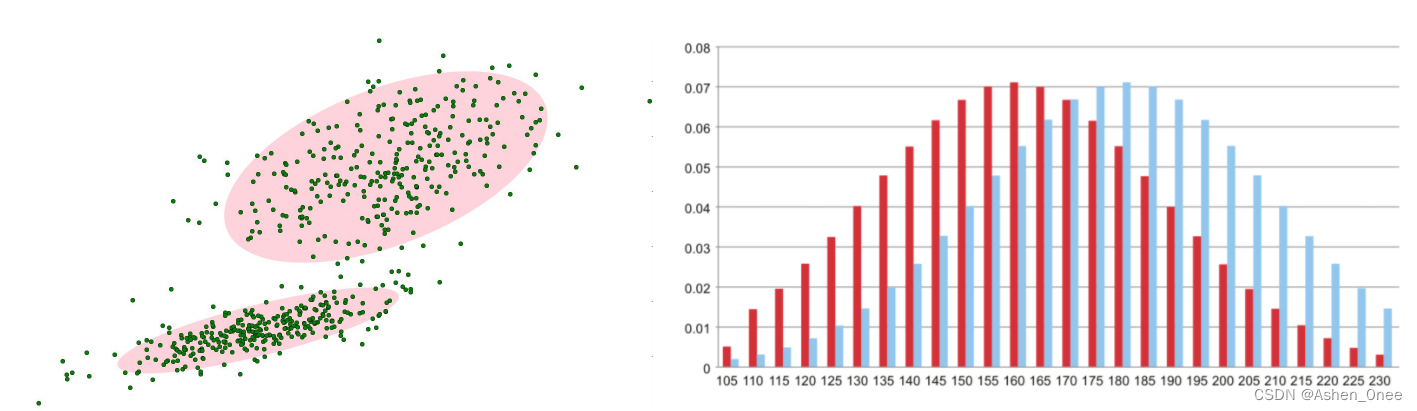
-
混合高斯模型学习方法:
- 首先初始化每个高斯模型矩阵参数。
- 取视频中 T 帧数据图像用来训练高斯混合模型。来了第一个像素之后用它来当做第一个高斯分布。
- 当后面来的像素值时,与前面已有的高斯的均值比较,如果该像素点的值与其模型均值差在3倍的方差内,则属于该分布,并对其进行参数更新。
- 如果下一次来的像素不满足当前高斯分布,用它来创建一个新的高斯分布。
-
混合高斯模型测试方法:
对新来像素点的值与混合高斯模型中的每一个均值进行比较。
如果其差值在2倍的方差之间的话,则认为是背景,否则认为是前景。将前景赋值为255,背景赋值为0。
import numpy as np
import cv2 as cv
# 测试视频
cap = cv.VideoCapture('./背景建模与光流估计/test.avi')
# 形态学操作: 去除噪音
kernel = cv.getStructuringElement(cv.MORPH_ELLIPSE, (3, 3))
# 创建混合高斯模型用于背景建模
fgbg = cv.createBackgroundSubtractorMOG2()
while(True):
ret, frame = cap.read()
fgmask = fgbg.apply(frame)
# 形态学开运算去噪点
fgmask = cv.morphologyEx(fgmask, cv.MORPH_OPEN, kernel)
# 寻找视频中的轮廓
contours, hierachy = cv.findContours(fgmask, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)
#计算各轮廓的周长
for c in contours:
perimetre = cv.arcLength(c, True)
if perimetre > 188:
# 找到一个直矩形(不会旋转)
x, y, w, h = cv.boundingRect(c)
# 画出这个矩形
cv.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
cv.imshow('Frame', frame)
cv.imshow('fgmask', fgmask)
k = cv.waitKey(150) & 0xff
if k == 27:
break
cap.release()
cv.destroyAllWindows()
二、光流估计
空间运动物体在观测成像平面上的像素运动的“瞬时速度”,根据各个像素点的速度矢量特征,可以对图像进行动态分析,例如目标跟踪。
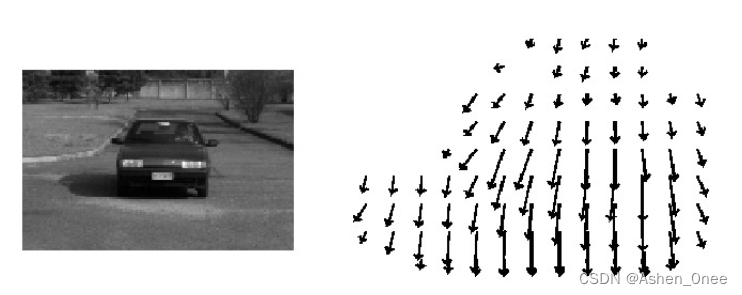
-
Lucas-Kanade 算法:
I ( x , y , t ) = I ( x + d x , y + d y , t + d t ) = I ( x , y , t ) + ∂ I ∂ x d x + ∂ I ∂ y d y + ∂ I ∂ t d t I x d x + I y d y + I t d t = 0 I x u + I y v = − I t → [ I x I y ] ⋅ [ u v ] I(x, y, t) = I(x+dx, y+dy, t+dt) = I(x, y, t) + \frac{\partial I}{\partial x}dx + \frac{\partial I}{\partial y}dy + \frac{\partial I}{\partial t}dt\\ I_xdx + I_ydy + I_tdt = 0\\ I_xu + I_y v = - I_t → \begin{bmatrix} I_x\ I_y \end{bmatrix}\cdot \begin{bmatrix} u \\ v \end{bmatrix} I(x,y,t)=I(x+dx,y+dy,t+dt)=I(x,y,t)+∂x∂Idx+∂y∂Idy+∂t∂IdtIxdx+Iydy+Itdt=0Ixu+Iyv=−It→[Ix Iy]⋅[uv]
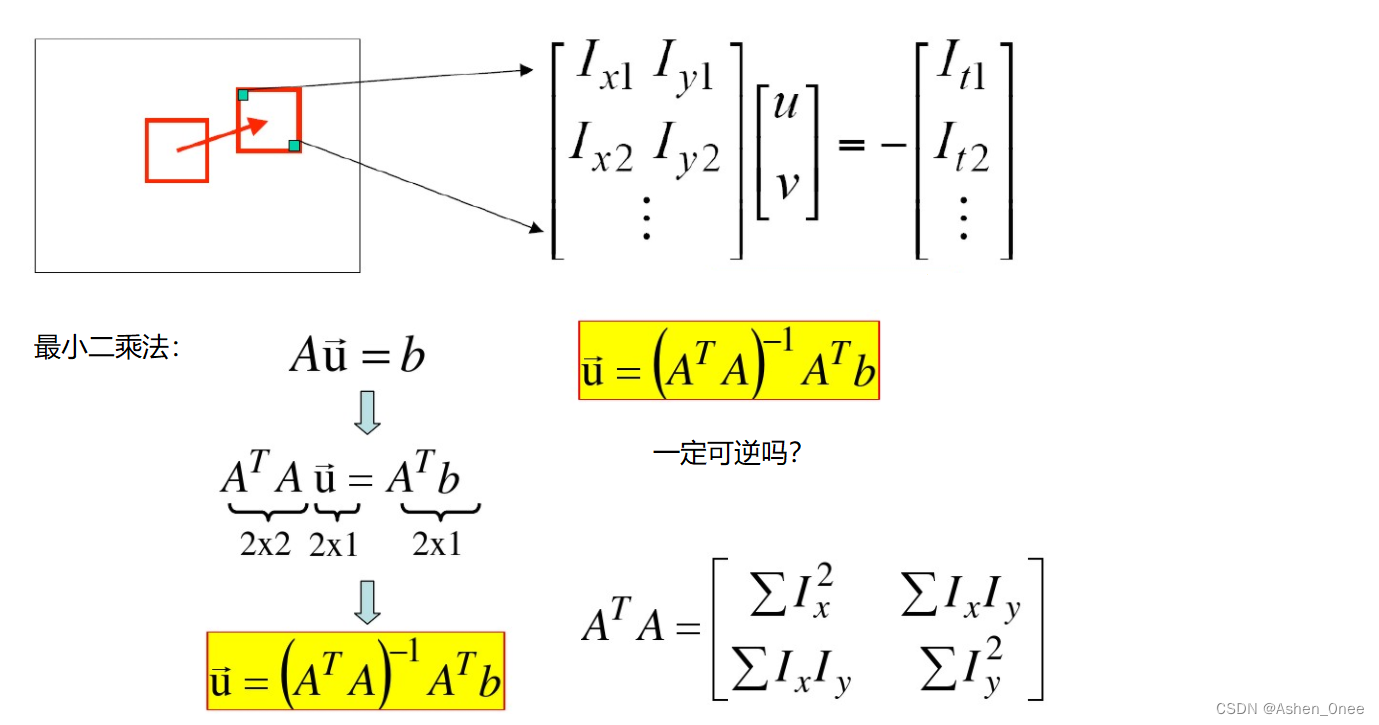
-
cv2.calcOpticalFlowPyrLK()
- prevImage 前一帧图像;
- nextImage 当前帧图像;
- prevPts 待跟踪的特征点向量;
- winSize 搜索窗口的大小;
- maxLevel 最大的金字塔层数.
返回:
- nextPts 输出跟踪特征点向量;
- status 特征点是否找到,找到的状态为1,未找到的状态为0。
import numpy as np
import cv2 as cv
cap = cv.VideoCapture('./背景建模与光流估计/test.avi')
# 角点检测所需参数
feature_paras = dict( maxCorners=100,
qualityLevel=0.3,
minDistance=7)
# lucas kanade参数
lk_paras = dict( winSize=(15, 15),
maxLevel=2)
# 随机颜色条
color = np.random.randint(0, 255, (100, 3))
# 拿到第一帧图像
ret, old_frame = cap.read()
old_gray = cv.cvtColor(old_frame, cv.COLOR_BGR2GRAY)
# 返回所有检测特征点,需要输入图像
# 角点最大数量(效率),品质因子(特征值越大的越好,来筛选)
# 距离相当于这区间有比这个角点强的,就不要这个弱的了
p0 = cv.goodFeaturesToTrack(old_gray, mask=None, **feature_paras)
# 创建一个mask
mask = np.zeros_like(old_frame)
while(True):
ret, frame = cap.read()
frame_gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
# 需要传入前一帧和当前图像以及前一帧检测到的角点
p1, st, err = cv.calcOpticalFlowFarneback(old_gray, frame_gray, p0, None, **lk_params)
# st=1表示
good_new = p1[st == 1]
good_old = p0[st == 1]
# 绘制轨迹
for i, (new, old) in enumerate(zip(good_new, good_old)):
a, b = new.ravel()
c, d = old.ravel()
mask = cv.line(mask, (a, b), (c, d), color[i].tolist(), 2)
frame = cv.circle(frame, (a, b), 5, color[i].tolist(), -1)
img = cv.add(frame, mask)
cv.imshow('Frame', img)
k = cv.waitKey(150) & 0xff
if k == 27:
break
# 更新
old_gray = frame_gray.copy()
p0 = good_new.reshape(-1, 1, 2)
cv.destroyAllWindows()
cv.release()




![[思维模式-9]:《如何系统思考》-5- 认识篇 - 改变开环、组合逻辑的线性思考,实施闭环、时序逻辑的动态思考。](https://img-blog.csdnimg.cn/df87183378194fef920384ccdade9c9c.png)