文章目录
- 前言:优秀notebook介绍
- 三、Open Book Q&A
- 3.1 概述
- 3.2 安装依赖,导入数据
- 3.3 数据预处理
- 3.3.1 处理prompt
- 3.3.2 处理wiki数据
- 3.4 使用faiss搜索获取匹配的Prompt-Sentence Pairs
- 3.5 查看context结果并保存
- 3.6 推理
- 3.6.1 加载测试集
- 3.6.2 定义预处理函数和后处理函数
- 3.6.3 开始推理
- 3.6.3.1 使用trainer进行推理(方法7)
- 3.6.3.2 使用Pytorch进行推理(方法8)
前言:优秀notebook介绍
本文完整kaggle notebook见《Open Book QA&debertav3-large详解》,如果觉得有用,请投一票,谢谢
本系列第一篇文章《Kaggle - LLM Science Exam(一):赛事概述、数据收集、BERT Baseline》中详细介绍了赛事背景、数据集、评测指标等等,以及下面列举优秀notebook中的方法1、3、4,可供参考。
以下是收集的部分优秀notebook:
-
《Starter Notebook: Ranked Predictions with BERT》:Bert Baseline,使用
bert-base-cased和比赛提供的200个训练集样本进行训练,Public Score=0.545。 -
《[EDA, Data gathering] LLM-SE ~ Wiki STEM | 1k DS》(制作训练数据):比赛提供的200个样本太少了,作者
LEONID KULYK先分析了比赛数据集,然后同样使用gpt3.5制作了1000个Wikipedia样本,数据集上传在Wikipedia STEM 1k。 -
《LLM-SE ~ deberta-v3-large -i | 1k Wiki》:
LEONID KULYK将自己收集的1000个Wikipedia样本和比赛训练集合并,一起训练,模型是deberta-v3-large。notebook中有最终模型权重,可直接推理,LB= 0.709。 -
《New dataset + DEBERTA v3 large training!》:
0.723→0.759-
Radek基于方法3,使用自己生成的500个额外数据训练DEBERTA v3 large,Public Score=0.723。 -
Radek后来又生成了6000条数据,跟之前的500条融合为6.5K数据集,并在此基础上进行三次训练,得到了三个模型权重,上传在Science Exam Trained Model Weights中。然后通过下面两种方法,进行推理:-
《Inference using 3 trained Deberta v3 models》:三个模型分别预测之后概率取平均,
Public Score=0.737。 -
An introduction to Voting Ensemble:作者在这个notebook中详细介绍了Voting Ensemble以及使用方法,
Public Score=0.759。
-
-
作者最后上传了15k high-quality train examples。
-
-
《Open Book LLM Science Exam》:
jjinho首次提出了Open Book方法,演示了如何在训练集中,使用faiss 执行相似性搜索,找到与问答数据最相似的context(Wikipedia数据),以增强问答效果。 -
《Open Book LLM Science Exam - Reduced RAM usage》:
quangbk改进了方法5中的内存效率。 -
《OpenBook DeBERTaV3-Large Baseline (Single Model》):
Anil将方法4和方法6结合起来。他将先测试集数据按照方法6搜索出context,然后将其与prompt合并,得到新的测试集。然后加载方法4训练的模型并使用trainer进行推理,Public Score=0.771。test_df["prompt"] = test_df["context"] + " #### " + test_df["prompt"] -
《Sharing my trained-with-context model》:
Mgoksu同样使用了方法7,只是使用了自己制作的数据集进行离线训练,得到一个更好的模型llm-science-run-context-2,然后进行推理(没有使用trainer),top publicLB=0.807。方法8和7只是模型以及最后推理部分代码不一样。 -
《How To Train Open Book Model - Part 1》、《How To Train Open Book Model - Part 2》:
CHRIS DEOTTE在part1中,参照方法8在自己制作的60k数据集进行训练,得到模型model_v2;然后在part2中使用方法8中的模型llm-science-run-context-2以及model_v2分别进行推理,得到的两个概率取平均,得到最终结果(Public Score=0.819)。- 在part1中,作者使用了竞赛指标MAP@3 来评估模型,并讨论了一些训练技巧,例如使用 PEFT或冻结model embeddings&model layers来减少训练参数、增加 LR 并减少 epochs来减少计算量、 使用gradient_checkpointing(这使用磁盘来节省RAM)、使用gradient_accumlation_steps模拟更大的批次等等。
-
《LLM Science Exam Optimise Ensemble Weights》:作者首先使用了方法9训练的模型权重;另外为了增加多样性,还融合了其它几个没有使用Open Book的deberta-v3-large模型,最终
Public Score=0.837。作者还写了以下notebook:- 《Incorporate MAP@k metrics into HF Trainer》:在Trainer中加入MAP@k指标
- 《Introducing Adversarial Weight Perturbation (AWP)》、《Adversarial Weight Perturbation (AWP) Inference》:介绍对抗性权重扰动AWP,以及推理方法。
- 《Using DeepSpeed with HF🤗 Trainer》,希望可以节约内存,以便训练更大的模型。
-
《LLM-SciEx Optimise Ensemble Weights(better models)》:类似方法10,通过模型融合,
Public Score=0.846。 -
《with only 270K articles》:作者自己制作了270K Wikipedia数据,使用
LongFormer模型而不是deberta-v3-large进行训练,Public Score=0.862。 -
《Platypus2-70B with Wikipedia RAG》:
SIMJEG结合了方法8和12,最终Public Score=0.872。ALI在 《Explained Platypus2-70B + Wikipedia RAG》中对此notebook做了详细的说明。
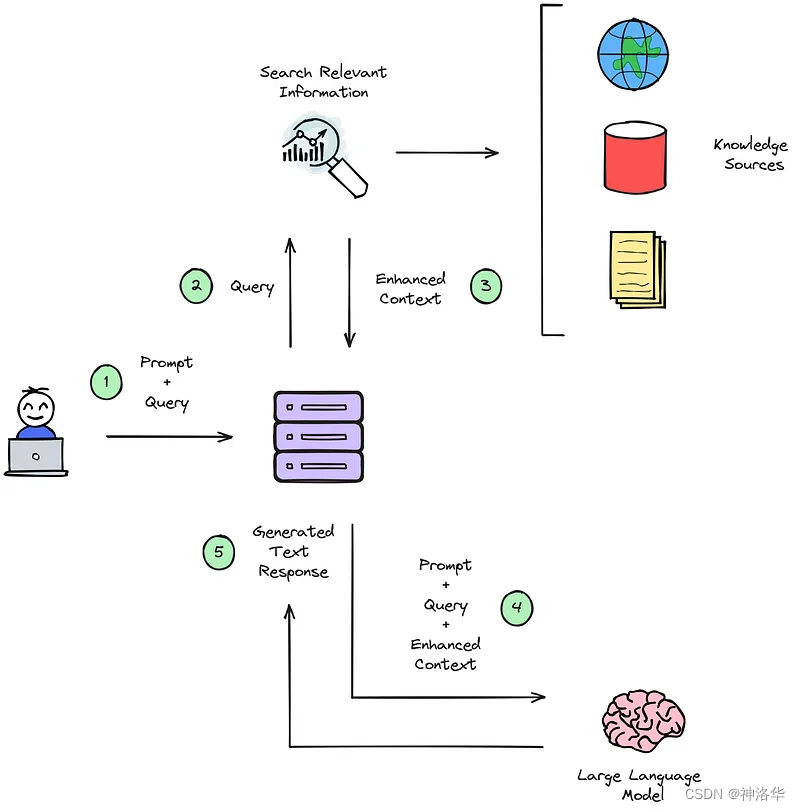
三、Open Book Q&A
3.1 概述
在方法5中,我们先搜索出跟每条样本的prompt_embeddings最相似维基百科文章,然后将这些文章分割为句子。然后综合prompt+answer得到question_embeddings进行第二次搜索,在上一步分割的句子中搜索出与每个question_embeddings最相似的句子,得到与问答最相关的上下文context。
方法7中,合并context与prompt,然后进行常规的推理过程,总的来说就是使用最有帮助的维基百科句子来增强问答数据。下面详细讲解。
- Open Book LLM Science Exam - Reduced RAM usage(方法5)
Open Book Q&A方法使用的Wikipedia Plaintext数据集,包含 2023 年 7 月 1 日维基百科转储中的 6,286,775 篇文章、标题、文本和类别。文章按字母数字顺序排序,并分成与文章标题的第一个字符对应parquet文件,即分区为 a - z 、 number (以数字开头的标题)和 other (以符号开头的标题)的 parquet 文件。

整个算法步骤如下:
- 读取Wikipedia Plaintext数据集
- 使用 sentence transformers(all-MiniLM-L6-v2 model)将训练集prompts(问题)和Wikipedia文章 转为embeddings,使用每篇文章的第一句增强上下文。
- 使用 faiss 执行相似性搜索,以查找出200条测试集问答数据prompt最可能具有其所需信息的前 k 篇文章的索引(本文取k=3,最终得到576篇文章而不是600篇,因为部分是重复的)
- 根据索引获取文章的全文(
wiki_text_data),使用 blingfire 库将它们分成句子 - 合并prompt和全部answer,执行相似性搜索以获得每个问答数据(question_embeddings)最匹配的前m个匹配句子(context)
- 将prompt、answer和context结合起来,要么直接进行问题回答(方法6),要么输入LLM(方法7)
- OpenBook DeBERTaV3-Large Baseline (Single Model)(方法7)
上一个notebook中,我们使用faiss 执行相似性搜索,得到了与prompt和answer最相似的context。将其与问答数据合并,增强上下文,得到新的测试集问答数据:
test_df["prompt"] = test_df["context"] + " #### " + test_df["prompt"]
然后对这个增强的测试集,执行常规的多选问答推理。
3.2 安装依赖,导入数据
# 因为是notebook比赛模式,不能联网,所以从input中安装依赖库
!pip install -U /kaggle/input/faiss-gpu-173-python310/faiss_gpu-1.7.2-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
!cp -rf /kaggle/input/sentence-transformers-222/sentence-transformers /kaggle/working/sentence-transformers
!pip install -U /kaggle/working/sentence-transformers
!pip install -U /kaggle/input/blingfire-018/blingfire-0.1.8-py3-none-any.whl
!pip install --no-index --no-deps /kaggle/input/llm-whls/transformers-4.31.0-py3-none-any.whl
#!pip install --no-index --no-deps /kaggle/input/llm-whls/peft-0.4.0-py3-none-any.whl
!pip install --no-index --no-deps /kaggle/input/llm-whls/datasets-2.14.3-py3-none-any.whl
#!pip install --no-index --no-deps /kaggle/input/llm-whls/trl-0.5.0-py3-none-any.whl
import os,gc,re,faiss
import pandas as pd
import numpy as np
import blingfire as bf
from tqdm.auto import tqdm
from collections.abc import Iterable
from faiss import write_index, read_index
from sentence_transformers import SentenceTransformer
import torch
import ctypes
libc = ctypes.CDLL("libc.so.6")
MODEL = '/kaggle/input/sentencetransformers-allminilml6v2/sentence-transformers_all-MiniLM-L6-v2'
DEVICE = 0
MAX_LENGTH = 384
BATCH_SIZE = 16
WIKI_PATH = "/kaggle/input/wikipedia-20230701"
wiki_files = os.listdir(WIKI_PATH) # ['x.parquet', 'h.parquet', 'w.parquet',...]
3.3 数据预处理
3.3.1 处理prompt
我们观察到prompt的主题几乎总是在最后。下面使用 sentence_transformers 对整个prompt进行编码,方便后续使用语义搜索来查找相关文章。
model = SentenceTransformer(MODEL, device='cuda')
model.max_seq_length = MAX_LENGTH
model = model.half()
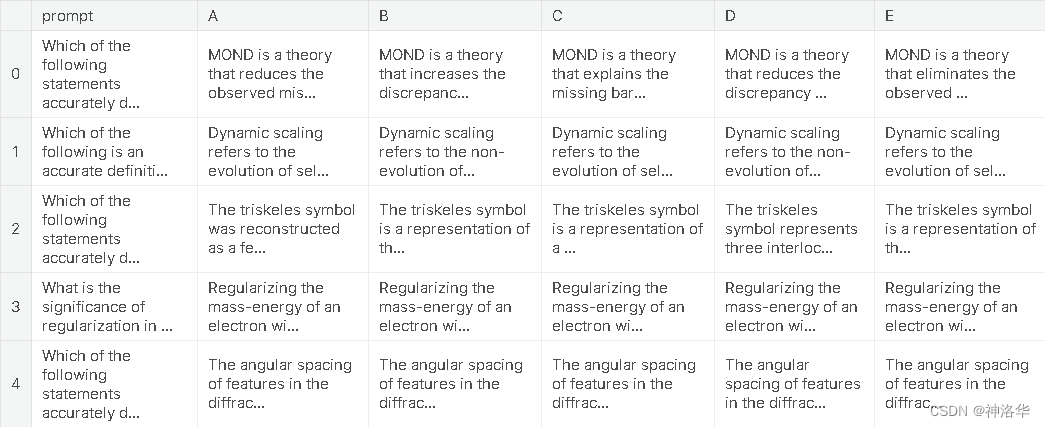
trn = pd.read_csv("/kaggle/input/kaggle-llm-science-exam/test.csv").drop("id", 1)
trn.head()
prompt_embeddings = model.encode(trn.prompt.values, batch_size=BATCH_SIZE, device=DEVICE, show_progress_bar=True, convert_to_tensor=True, normalize_embeddings=True)
# 将查询向量从GPU上的张量转换为NumPy数组,以便后续在Faiss中使用
prompt_embeddings = prompt_embeddings.detach().cpu().numpy()
print(prompt_embeddings,prompt_embeddings.shape)
# 手动触发Python的垃圾回收,以释放之前的不再使用的内存
_ = gc.collect()
prompt_embeddings加.half(),后面sentence_index.search会报错
TypeError: in method 'IndexFlat_search', argument 3 of type 'float const *'
array([[-4.5478687e-02, -1.6479595e-02, 4.3971878e-02, ...,
-5.1500157e-02, -9.1974944e-02, 7.7763526e-03],
[-2.6538833e-03, -5.8031674e-02, -4.0828194e-02, ...,
3.2339178e-02, 1.4145578e-02, -2.4660153e-02],
[-6.8248026e-02, 9.7041421e-02, -7.8083292e-02, ...,
4.0758580e-02, 4.6507336e-02, 2.7111586e-02],
...,
[-7.3988572e-02, -1.4278200e-02, -4.0605428e-05, ...,
-1.0465340e-02, -2.3960188e-02, -3.3164129e-02],
[-2.5413906e-02, 3.4185217e-04, -4.3551046e-02, ...,
-4.7686603e-02, 1.2639660e-01, -5.0002653e-02],
[-5.9531994e-02, -7.2587818e-02, -2.9483654e-02, ...,
2.7272794e-03, -2.6037039e-02, 2.4748029e-02]], dtype=float32)
(200, 384)
3.3.2 处理wiki数据
- 获取与prompt最关联的wiki文档
# 预计算的维基百科索引
# 使用read_index函数从读取Faiss索引文件(wikipedia_202307.index),并将其加载到sentence_index变量中
sentence_index = read_index("/kaggle/input/wikipedia-2023-07-faiss-index/wikipedia_202307.index")
# 查看第一条数据的embedding
first_embedding = sentence_index.reconstruct(0)
print( first_embedding,first_embedding.shape)
[-1.56402588e-03 1.73797607e-02 -5.81665039e-02 -6.96182251e-03
-6.85424805e-02 6.41479492e-02 1.04446411e-02 1.54647827e-02
...
-1.45645142e-02 -4.87670898e-02 4.37545776e-03 -7.89184570e-02
9.16137695e-02 -9.45434570e-02 2.29339600e-02 7.09838867e-02]
(384,)
sentence_index是Faiss索引对象(本示例中,它是从指定路径读取的 Faiss 索引文件),它的内容通常包括embeddings、索引结构(根据嵌入向量数据构建的,以便能够快速找到最相似的向量)以及 其他元信息(如索引维度、距离度量标准等)。
# 获取可能包含感兴趣主题的前3页
search_score, search_index = sentence_index.search(prompt_embeddings, 3)
search_score,search_index,search_index.shape
# search_score,shape为(200, 3)
array([[0.8242705 , 0.9412608 , 0.9816439 ],
[0.3884983 , 0.79613495, 0.82003427],
...
[0.6471102 , 0.6917976 , 0.73008466]], dtype=float32)
# search_index,shape为(200, 3)
array([[3573843, 4906500, 1830796],
[1431454, 5135549, 5135229],
...
[1464446, 363737, 1464453]]
sentence_index.search 是 Faiss 库中用于执行向量检索操作的方法,上述代码是对 prompt_embeddings 中的每个查询向量(每一行,也就是数据集中每个样本的嵌入向量)执行向量查找操作。对于每个查询向量,Faiss 库会在 sentence_index 中查找与其最相似的向量,并返回相似度分数search_score及相似向量的位置索引search_index(使用这些索引位置可以检索实际的嵌入向量或相关数据)。
以上操作的目的,是为了找到与一组查询向量最相似的数据点,以便进行相关任务,比如信息检索或推荐系统。
# 内存涨到12.3GB,删除不再需要变量,释放内存,降到3.3GB
del sentence_index
del prompt_embeddings
_ = gc.collect()
libc.malloc_trim(0)
_ = gc.collect():这行代码手动触发了 Python 的垃圾回收机制(Garbage Collection)。垃圾回收是一种用来识别和释放不再使用的内存的机制。虽然 Python 通常会自动执行垃圾回收,但在某些情况下,手动触发垃圾回收可以更快地释放内存。libc.malloc_trim(0):在特定情况下执行的系统级内存管理操作,用于释放更多内存。malloc_trim 是与 C 语言中的内存分配函数 malloc 相关的操作,它的目的是将未使用的内存返回给操作系统。
# 加载维基百科索引文件,仅包括'id'和'file'两列
df = pd.read_parquet("/kaggle/input/wikipedia-20230701/wiki_2023_index.parquet", columns=['id', 'file'])
df # 6286775 rows × 2 columns
id file
0 49495844 a.parquet
1 3579086 a.parquet
... ... ...
6286773 18920475 z.parquet
6286774 51132758 z.parquet
使用索引获取文章和关联的文件位置
wikipedia_file_data = []
# 遍历search_score和search_index,使用tqdm显示进度
for i, (scr, idx) in tqdm(enumerate(zip(search_score, search_index)), total=len(search_score)):
# scr_idx = idx[np.where(scr <= 0.85)] # 作者准备设置分数阈值,最后取消了
scr_idx = idx
_df = df.loc[scr_idx].copy() # 从df中选择与索引对应的行,并创建副本
_df['prompt_id'] = i
wikipedia_file_data.append(_df)
wikipedia_file_data # 长为200的列表,每个都包含prompt的索引以及最相似的维基百科文章的索引及其位置
id file prompt_id
3573843 55518323 m.parquet 0
4906500 15739602 r.parquet 0
1830796 12571 g.parquet 0
id file prompt_id
1431454 52303418 d.parquet 1
5135549 58495269 s.parquet 1
5135229 5782346 s.parquet 1,
...
wikipedia_file_data = pd.concat(wikipedia_file_data).reset_index(drop=True)
# drop_duplicates对数据去重,然后按file和id进行排序,最后重装索引
wikipedia_file_data = wikipedia_file_data[['id', 'prompt_id', 'file']].drop_duplicates().sort_values(['file', 'id']).reset_index(drop=True)
wikipedia_file_data
id prompt_id file
0 1141 151 a.parquet
1 11963992 185 a.parquet
2 1200 63 a.parquet
3 1234 130 a.parquet
4 1317 89 a.parquet
... ... ... ...
595 810077 27 x.parquet
596 1063160 46 y.parquet
597 31557501 49 y.parquet
598 47610211 49 y.parquet
599 34527 103 z.parquet
这样我们就得到了与200个问题最相似的维基百科文章的全部索引(id),以及每个文章所在的parquet文件。
# 删除不再需要的 df ,节省内存
del df
_ = gc.collect()
libc.malloc_trim(0)
下面我们遍历每个parquet文件名(file,需要去重),先获取所有当前parquet文件需要查找的文章索引(id),然后读取parquet文件的id和text两列;最后根据id筛选出其中的文档text,存储在wiki_text_data中。
wiki_text_data = []
# 遍历唯一的文件名列表
for file in tqdm(wikipedia_file_data.file.unique(), total=len(wikipedia_file_data.file.unique())):
# 从文件名相匹配的行中提取 'id' 列的值,并将其转为一个字符串列表
_id = [str(i) for i in wikipedia_file_data[wikipedia_file_data['file']==file]['id'].tolist()]
# 读取parquet文件中'id'和'text'列
_df = pd.read_parquet(f"{WIKI_PATH}/{file}", columns=['id', 'text'])
# 创建一个副本,筛选出parquet文件中搜索出的id行
_df_temp = _df[_df['id'].isin(_id)].copy()
del _df
_ = gc.collect() # 手动触发垃圾回收,释放内存
libc.malloc_trim(0) # 释放更多内存(这部分可能是特定于系统的内存管理操作)
wiki_text_data.append(_df_temp)
# 将结果列表中的数据合并成一个新的DataFrame,去除重复项,并重置索引
wiki_text_data = pd.concat(wiki_text_data).drop_duplicates().reset_index(drop=True)
wiki_text_data
id text
0 1550261 The American Petroleum Institute gravity, or A...
1 46674381 In mathematics and physics, acceleration is th...
2 424420 Accelerator physics is a branch of applied phy...
3 1234 Acoustic theory is a scientific field that rel...
4 68418053 Alan Louis Selman (April 2, 1941 – January 22,...
... ... ...
571 61265537 Xenambulacraria is a proposed clade of animals...
572 31557501 Year of No Light is a French post-metal band f...
573 47610211
574 1063160 was a Japanese-American physicist and professo...
575 34527 The zodiacal light (also called false dawn whe...
上述代码中,我们遍历唯一的文件名列表wikipedia_file_data.file.unique():
wikipedia_file_data[wikipedia_file_data['file']==file]:使用布尔索引来选择 wikipedia_file_data 中当前迭代的file(文件名 )的行。['id'].tolist():从过滤后的结果中选择 ‘id’ 列(Series格式),然后转为Python列表格式[str(i) for i in ...]:使用列表推导式,将这个列表中的每个值转换为字符串,并存储在 _id 列表中。
- 定义文档处理函数,将Wik文档拆分为句子并编码
# 主函数,用于处理文档
def process_documents(documents: Iterable[str],
document_ids: Iterable,
split_sentences: bool = True,
filter_len: int = 3,
disable_progress_bar: bool = False) -> pd.DataFrame:
"""
主要辅助函数,用于处理来自电子病历的文档。
:param documents: 包含文档的可迭代对象,每个元素是字符串
:param document_ids: 包含文档唯一标识符的可迭代对象
:param split_sentences: 标志,确定是否进一步将文档分割为句子
:param filter_len: 默认句子的最小字符长度为3,否则过滤掉。
:param disable_progress_bar: 是否禁用 tqdm 进度条
:return: DataFrame格式,包含列 `document_id`, `text`, `section`, `offset`
"""
# 调用 sectionize_documents 函数来获取文档的章节信息
df = sectionize_documents(documents, document_ids, disable_progress_bar)
# split_sentences默认为true,表示需要进一步分割句子
if split_sentences:
# 调用 sentencize 函数,传入文本、文档标识符、偏移量等信息
df = sentencize(df.text.values,
df.document_id.values,
df.offset.values,
filter_len,
disable_progress_bar)
return df
# 辅函数,用于提取文档的章节信息
def sectionize_documents(documents: Iterable[str],
document_ids: Iterable,
disable_progress_bar: bool = False) -> pd.DataFrame:
"""
获取imaging reports并仅返回所选章节(默认为 FINDINGS、IMPRESSION 和 ADDENDUM)。
:param documents: 包含文档的可迭代对象,每个元素是字符串
:param document_ids: 包含文档唯一标识符的可迭代对象
:param disable_progress_bar: 是否 tqdm 进度条的标志
:return: DataFrame格式,包含列 `document_id`, `text`, `offset`
"""
processed_documents = []
# 使用 tqdm 迭代处理文档,显示进度条
for document_id, document in tqdm(zip(document_ids, documents), total=len(documents), disable=disable_progress_bar):
row = {}
text, start, end = (document, 0, len(document))
row['document_id'] = document_id
row['text'] = text
row['offset'] = (start, end)
processed_documents.append(row)
# 创建 DataFrame 并根据 'document_id' 和 'offset' 进行排序
_df = pd.DataFrame(processed_documents)
if _df.shape[0] > 0:
return _df.sort_values(['document_id', 'offset']).reset_index(drop=True)
else:
return _df
# 辅函数,用于将文档分割为句子
def sentencize(documents: Iterable[str],
document_ids: Iterable,
offsets: Iterable[tuple[int, int]],
filter_len: int = 3,
disable_progress_bar: bool = False) -> pd.DataFrame:
"""
将文档分割为句子。可以与 `sectionize_documents` 一起使用,进一步将文档分割为更易处理的部分。
接受偏移量以确保分割后的句子可以与原始文档中的位置匹配。
:param documents: 包含文档的可迭代对象,每个元素是字符串
:param document_ids: 包含文档唯一标识符的可迭代对象
:param offsets: 可迭代的元组,表示开始和结束索引
:param filter_len: 句子的最小字符长度(否则过滤掉)
:return: 包含列 `document_id`, `text`, `section`, `offset` 的 Pandas DataFrame
"""
document_sentences = []
# 使用 tqdm 迭代处理文档,显示进度条
for document, document_id, offset in tqdm(zip(documents, document_ids, offsets), total=len(documents), disable=disable_progress_bar):
try:
# 使用 bf 库中的函数将文档转换为句子和偏移量
_, sentence_offsets = bf.text_to_sentences_and_offsets(document)
for o in sentence_offsets:
if o[1] - o[0] > filter_len:
sentence = document[o[0]:o[1]]
abs_offsets = (o[0] + offset[0], o[1] + offset[0])
row = {}
row['document_id'] = document_id
row['text'] = sentence
row['offset'] = abs_offsets
document_sentences.append(row)
except:
continue
return pd.DataFrame(document_sentences)
# 将完整的维基百科文档拆分为句子
processed_wiki_text_data = process_documents(wiki_text_data.text.values, wiki_text_data.id.values)
processed_wiki_text_data
document_id text offset
0 10087606 In group theory, geometry, representation theo... (0, 207)
1 10087606 For example, as transformations of an object i... (208, 329)
2 10087606 Such symmetry operations are performed with re... (330, 441)
3 10087606 In the context of molecular symmetry, a symmet... (442, 631)
4 10087606 Two basic facts follow from this definition, w... (632, 709)
... ... ... ...
32308 9962772 Mit Beitr. (6031, 6041)
32309 9962772 Barth, 1957) == Selected publications == *Carl... (6049, 6223)
32310 9962772 (Received 7 September 1920, published in issue... (6224, 7033)
32311 9962772 Volume 1 Part 2 The Quantum Theory of Planck, ... (7034, 7169)
32312 9962772 (Springer, 1982) *Walker, Mark German National... (7170, 7553)
# 获取句子embeddings
wiki_data_embeddings = model.encode(processed_wiki_text_data.text, batch_size=BATCH_SIZE, device=DEVICE, show_progress_bar=True, convert_to_tensor=True, normalize_embeddings=True)
wiki_data_embeddings = wiki_data_embeddings.detach().cpu().numpy() # (32313, 384)
_ = gc.collect()
- 编码问答数据
在很多情况下,GPT3.5 似乎直接从文本中获取答案。因此,我们希望检索最相似的句子来提供上下文。下面将训练集prompt和所有answer进行合并,然后进行编码,后面会根据其编码结果来进行搜索,也就是搜索与question_embeddings(prompt+answer embeddings)最相似的wiki_data_embeddings。
# 组合所有答案
trn['answer_all'] = trn.apply(lambda x: " ".join([x['A'], x['B'], x['C'], x['D'], x['E']]), axis=1)
# 合并prompt+answer,然后编码
trn['prompt_answer_stem'] = trn['prompt'] + " " + trn['answer_all']
question_embeddings = model.encode(trn.prompt_answer_stem.values, batch_size=BATCH_SIZE, device=DEVICE, show_progress_bar=True, convert_to_tensor=True, normalize_embeddings=True)
question_embeddings = question_embeddings.detach().cpu().numpy()
3.4 使用faiss搜索获取匹配的Prompt-Sentence Pairs
NUM_SENTENCES_INCLUDE = 5 # 用于确定要包含多少个相关句子
#prompt_contexts = [] # 包含 Question, Choices, Context的列表
contexts = [] # 只包含 Context的列表
for r in tqdm(trn.itertuples(), total=len(trn)):
prompt_id = r.Index
prompt_indices = processed_wiki_text_data[processed_wiki_text_data['document_id'].isin(wikipedia_file_data[wikipedia_file_data['prompt_id']==prompt_id]['id'].values)].index.values
if prompt_indices.shape[0] > 0:
prompt_index = faiss.index_factory(wiki_data_embeddings.shape[1], "Flat")
prompt_index.add(wiki_data_embeddings[prompt_indices])
context = ""
# 获取最相似的
ss, ii = prompt_index.search(question_embeddings, NUM_SENTENCES_INCLUDE)
for _s, _i in zip(ss[prompt_id], ii[prompt_id]):
context += processed_wiki_text_data.loc[prompt_indices]['text'].iloc[_i] + " "
contexts.append(context)
3.5 查看context结果并保存
trn['context'] = contexts
trn[["prompt", "context", "A", "B", "C", "D", "E"]].to_csv("./test_context.csv", index=False)
model.cpu()
del model
del question_embeddings, wiki_data_embeddings
_ = gc.collect()
libc.malloc_trim(0)
torch.cuda.empty_cache()
下面我们打印10条训练数据,可以看到这些数据不仅提供了问题和选择,还提供了维基百科的上下文。这些上下文可能会提供关键的提示,甚至答案本身!
for i, p in enumerate(contexts[:2]):
print(f"Question {i}")
print(p)
print()
Question 0
The presence of a clustered thick disk-like component of dark matter in the Galaxy has been suggested by Sanchez-Salcedo (1997, 1999) and Kerins (1997).Kerins, E. J. 1997, Astronomy and Astrophysics, 322, 709-718 (ADS entry )Sánchez-Salcedo, F. J. 1997, Astrophysical Journal, 487, L61-L64 (ADS entry )Sánchez-Salcedo, F. J. 1999, Monthly Notices of the Royal Astronomical Society, 303, 755-772 (ADS entry ) ==See also== * Dark matter * Brown dwarfs * White dwarfs * Microlensing * Hypercompact stellar system * Massive compact halo object (MACHOs) * Weakly interacting massive particles (WIMPs) ==References== Category:Star clusters Category:Open clusters Observations of the Bullet Cluster are the strongest evidence for the existence of dark matter; however, Brownstein and Moffat have shown that their modified gravity theory can also account for the properties of the cluster. == Observational methods == Clusters of galaxies have been found in surveys by a number of observational techniques and have been studied in detail using many methods: * Optical or infrared: The individual galaxies of clusters can be studied through optical or infrared imaging and spectroscopy. The observed distortions can be used to model the distribution of dark matter in the cluster. == Temperature and density == Clusters of galaxies are the most recent and most massive objects to have arisen in the hierarchical structure formation of the Universe and the study of clusters tells one about the way galaxies form and evolve. A 2021 article postulated that approximately 50% of all baryonic matter is outside dark matter haloes, filling the space between galaxies, and that this would explain the missing baryons not accounted for in the 2017 paper. == Current state == Currently, many groups have observed the intergalactic medium and circum-galactic medium to obtain more measurements and observations of baryons to support the leading observations. In cosmology, the missing baryon problem is an observed discrepancy between the amount of baryonic matter detected from shortly after the Big Bang and from more recent epochs.
Question 1
Many of these systems evolve in a self-similar fashion in the sense that data obtained from the snapshot at any fixed time is similar to the respective data taken from the snapshot of any earlier or later time. Many other seemingly disparate systems which are found to exhibit dynamic scaling. The form of their proposal for dynamic scaling was: :f(x,t)\sim t^{-w}x^{-\tau} \varphi \left( \frac x {t^z} \right), where the exponents satisfy the following relation: :w=(2-\tau)z. == Test for dynamic scaling == In such systems we can define a certain time-dependent stochastic variable x. Dynamic scaling (sometimes known as Family-Vicsek scaling) is a litmus test that shows whether an evolving system exhibits self-similarity. Essentially such systems can be termed as temporal self-similarity since the same system is similar at different times. == Examples == Many phenomena investigated by physicists are not static but evolve probabilistically with time (i.e. Stochastic process).
3.6 推理
3.6.1 加载测试集
import torch
import numpy as np
import pandas as pd
from datasets import Dataset
from transformers import AutoTokenizer
from transformers import AutoModelForMultipleChoice, TrainingArguments, Trainer
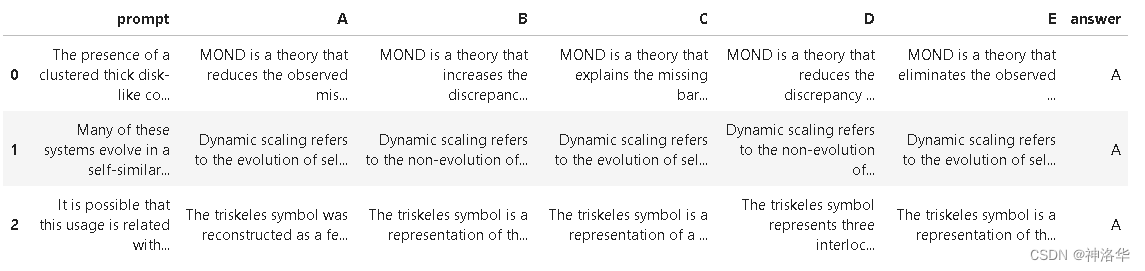
test_df = pd.read_csv("test_context.csv")
test_df["prompt"] = test_df["context"] + " #### " + test_df["prompt"]
#test_df["prompt"] = test_df["context"].apply(lambda x: x[:1750]) + " #### " + test_df["prompt"]
test_df=test_df.drop(columns=['context'])
# 添加答案列以保持和训练集格式一致,这样可以使用和训练集一样的预处理函数
test_df['answer'] = 'A'
test_df.head(3)
3.6.2 定义预处理函数和后处理函数
下面定义预处理函数,用于将待推理数据编码为多选问答需要的格式;定义后处理 函数,将推理结果转为提交的格式,这部分和方法1中完全一样。
- 将问题和5个答案选项组合,并进行解码
options = 'ABCDE'
indices = list(range(5))
option_to_index = {option: index for option, index in zip(options, indices)}
index_to_option = {index: option for option, index in zip(options, indices)}
def preprocess(example):
# AutoModelForMultipleChoice 需要的是question/answer对,所以问题被复制5次
first_sentence = [example['prompt']] * 5
second_sentence = []
# 遍历选项(A 到 E)并将它们添加到 second_sentence 列表中
for option in options:
second_sentence.append(example[option])
tokenized_example = tokenizer(first_sentence, second_sentence, truncation=True)
# 将答案映射为索引,并将其添加到 tokenized_example 中作为标签
tokenized_example['label'] = option_to_index[example['answer']]
return tokenized_example
可以看到,每个样本的问题被重复5次后和5个选项合并,解码后的结果input_ids、token_type_ids、attention_mask都是5个元素的嵌套列表,等于一个样本被拆成5个样本。
- 定义data_collator
# datacollator 来自 https://huggingface.co/docs/transformers/tasks/multiple_choice
# 每个batch中对问答对进行动态填充(dynamically pad),所以不需要将每个问答对都填充到模型最大序列长度
from dataclasses import dataclass
from transformers.tokenization_utils_base import PreTrainedTokenizerBase, PaddingStrategy
from typing import Optional, Union
@dataclass
class DataCollatorForMultipleChoice:
tokenizer: PreTrainedTokenizerBase
padding: Union[bool, str, PaddingStrategy] = True
max_length: Optional[int] = None
pad_to_multiple_of: Optional[int] = None
def __call__(self, features):
# features就是4个样本(batch size=4)
label_name = "label" if 'label' in features[0].keys() else 'labels'
# 对每个样本(feature,字典格式)使用pop删除key为label的键值对,返回被删除的值
# 所以feature被删除了label键值对,而labels的值是四个样本label列表[0, 0, 1, 0]
labels = [feature.pop(label_name) for feature in features]
batch_size = len(features) # 批次大小
num_choices = len(features[0]['input_ids']) # 选项数
flattened_features = [
[{k: v[i] for k, v in feature.items()} for i in range(num_choices)] for feature in features
]
flattened_features = sum(flattened_features, [])
batch = self.tokenizer.pad(
flattened_features,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors='pt',
)
batch = {k: v.view(batch_size, num_choices, -1) for k, v in batch.items()}
batch['labels'] = torch.tensor(labels, dtype=torch.int64)
return batch
最终返回的batch格式为:
{'input_ids': tensor([[[ 101, 2627..., 0]]]),
'token_type_ids': tensor([[[0, 0, 0, ..., 0, 0]]]),
'attention_mask': tensor([[[1, 1, 1, ..., 0, 0]]]),
'labels': tensor([0, 0, 1, 0])}
- 定义后处理函数,用于将预测结果(概率)转为比赛规定的提交格式
def predictions_to_map_output(predictions):
sorted_answer_indices = np.argsort(-predictions)
top_answer_indices = sorted_answer_indices[:,:3] # Get the first three answers in each row
top_answers = np.vectorize(index_to_option.get)(top_answer_indices)
return np.apply_along_axis(lambda row: ' '.join(row), 1, top_answers)
3.6.3 开始推理
3.6.3.1 使用trainer进行推理(方法7)
方法7加载llm-se-debertav3-large模型,方法8加载llm-science-run-context-2模型
- 加载模型和分词器
model_dir = "/kaggle/input/llm-se-debertav3-large"
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModelForMultipleChoice.from_pretrained(model_dir)
model.eval()
- 数据预处理
test_ds = Dataset.from_pandas(test_df)
# 使用数据集映射(map)预处理函数到训练数据集,同时删除不需要的列
tokenized_test_ds = test_ds.map(preprocess, batched=False, remove_columns=['prompt', 'A', 'B', 'C', 'D', 'E', 'answer'])
tokenized_test_ds
Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'label'],
num_rows: 200
})
- 开启训练
trainer = Trainer(
model=model,
tokenizer=tokenizer,
data_collator=DataCollatorForMultipleChoice(tokenizer=tokenizer)
)
test_predictions = trainer.predict(tokenized_test_ds)
- 提交结果
submission_df = pd.DataFrame({"id": np.arange(len(test_df))})
submission_df['prediction'] = predictions_to_map_output(test_predictions.predictions)
submission_df.to_csv('submission.csv', index=False)
submission_df.head()
id prediction
0 0 D B A
1 1 A B E
2 2 A C D
3 3 C E B
4 4 D A B
3.6.3.2 使用Pytorch进行推理(方法8)
model_dir = "/kaggle/input/llm-science-run-context-2"
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModelForMultipleChoice.from_pretrained(model_dir)
model.eval()
from torch.utils.data import DataLoader
tokenized_test_dataset = Dataset.from_pandas(test_df).map(preprocess, remove_columns=['prompt', 'A', 'B', 'C', 'D', 'E', 'answer'])
data_collator = DataCollatorForMultipleChoice(tokenizer=tokenizer)
test_dataloader = DataLoader(tokenized_test_dataset, batch_size=1, shuffle=False, collate_fn=data_collator)
test_predictions = []
for batch in test_dataloader:
for k in batch.keys():
batch[k] = batch[k].cuda()
with torch.no_grad():
outputs = model(**batch)
test_predictions.append(outputs.logits.cpu().detach())
test_predictions = torch.cat(test_predictions)
submission_df = pd.DataFrame({"id": np.arange(len(test_df))})
submission_df['prediction'] = predictions_to_map_output(test_predictions)
submission_df.to_csv('submission.csv', index=False)
submission_df.head()
id prediction
0 0 D B E
1 1 A B D
2 2 A D B
3 3 C D E
4 4 D A B
《Open Book QA&debertav3-large 详解》使用的是llm-se-debertav3-large模型,得分是0.771。如果改成llm-science-run-context-2,得分会是0.807。只使用openbook方法,而是直接用llm-science-run-context-2模型进行推理,得分是0.746。
Tips:有一版我导出这篇博客的md格式,使用
jupytext --set-formats ipynb,md filename.md将其转为ipynb格式,上传到kaggle上跑第一遍没有问题,但是提交后显示Submission CSV Not Found,而我明明是有保存提交文件的,output中也看得到。
后面在本地jupyterlab中打开这份ipynb文件报错,估计是这个原因导致最后提交没有结果。后面将md文件在jupyterlab中以ipynb打开,再保存为ipynb格式,导入kaggle,提交比赛,就没问题了。
![[每周一更]-(第65期):Docker容器监控工具推荐](https://img-blog.csdnimg.cn/90e97478c8c64ec0949fb6086ad7840e.png#pic_center)