想写一个读取doc文档中表格数据,来对文档进行重命名。经查资料,py-docx无法读取doc文档,原因是这种是旧格式。所以,采用pywin32来进行读取。
import win32com.client as win32
word = win32.gencache.EnsureDispatch('Word.Application',)
word.Visible = 0
Ndoc = word.Documents.Add()
doc = word.Documents.Open(file_path)
for t in doc.Tables:
for row in t.Rows:
for cell in row.Cells:
print(cell.Range.Text)
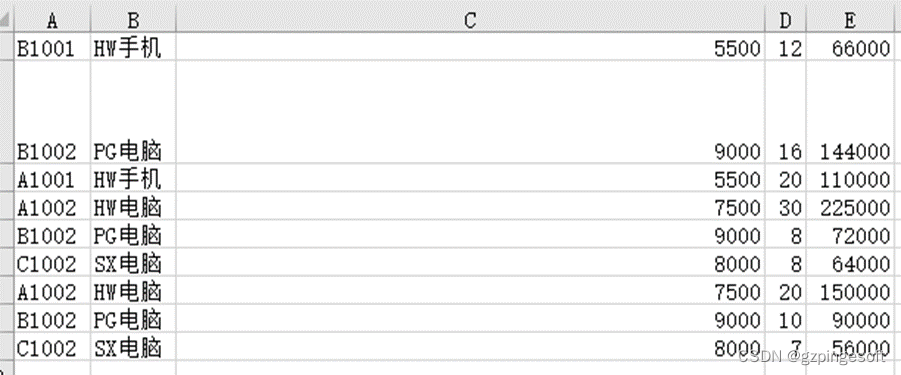
一运行,结果都是一个框一个框:

以为是编码出了问题,在网上找了原因,gbk/utf-8/utf-16,甚至iso-8859-1各种encode/decode,发现能输出一些字符。无奈一decode都是无果。

各种网站解析无果,我跑去问“文心一言”,居然能翻出来。说明是解析出问题,但是咋都找不到原因。

检查代码,跟其他人写的也一样,这时只能怀疑编译环境了。目前我的版本是3.9,但是这步没办法排查。我只能试试输出到其他地方是什么结果了。 我直接把文件名给改了,结果看到了这样的错误。

看到输出文字,我很高兴,并且留意到\r\x07这个字符,复制到网上一搜,果然看到同样的问题。原来是出现这些转义符号,输出异常了。只要把它们删除即可。
print(cell.Range.Text.replace("\r\x07", ""))总算是可以了,一个小小的问题折腾的一天,果然是生蔬了。同时也感慨人工智能的进步,写程序提高效率肉眼可见!