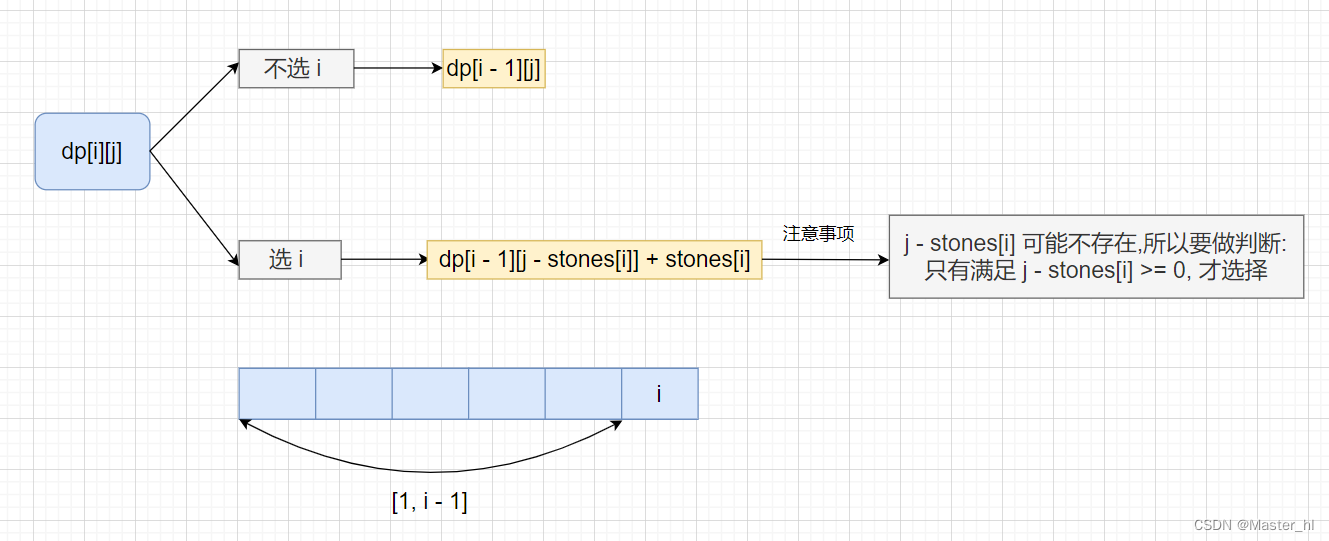
1 简介
了解过RabbitMQ后,可能我们会遇到不同的系统在用不同的队列。比如系统A用的Kafka,系统B用的RabbitMQ,但是没了解过Kafka,因此可以使用Spring Stream,它能够屏蔽地产,像JDBC一样,只关心SQL和业务本身,不关心数据库的具体实现。
创建一个新的项目测试
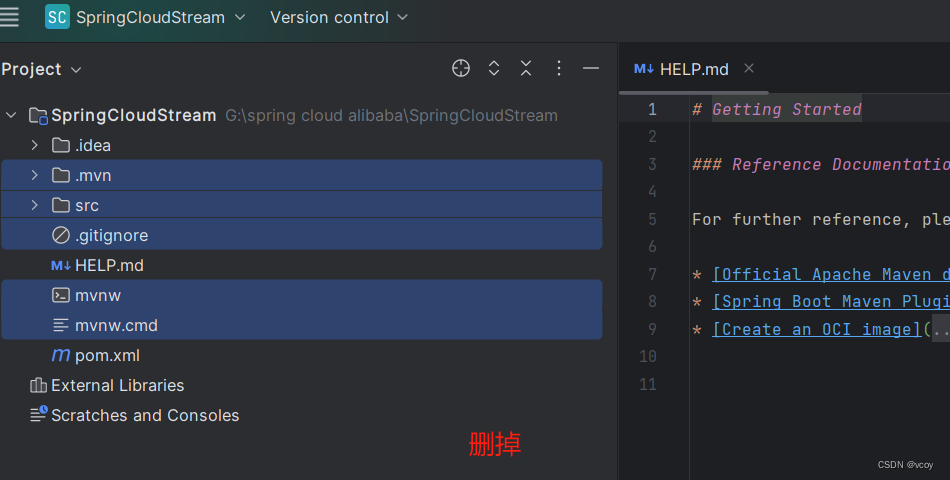
导入SpringCloud依赖
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>2021.0.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
新建两个模块,一个生产者一个消费者
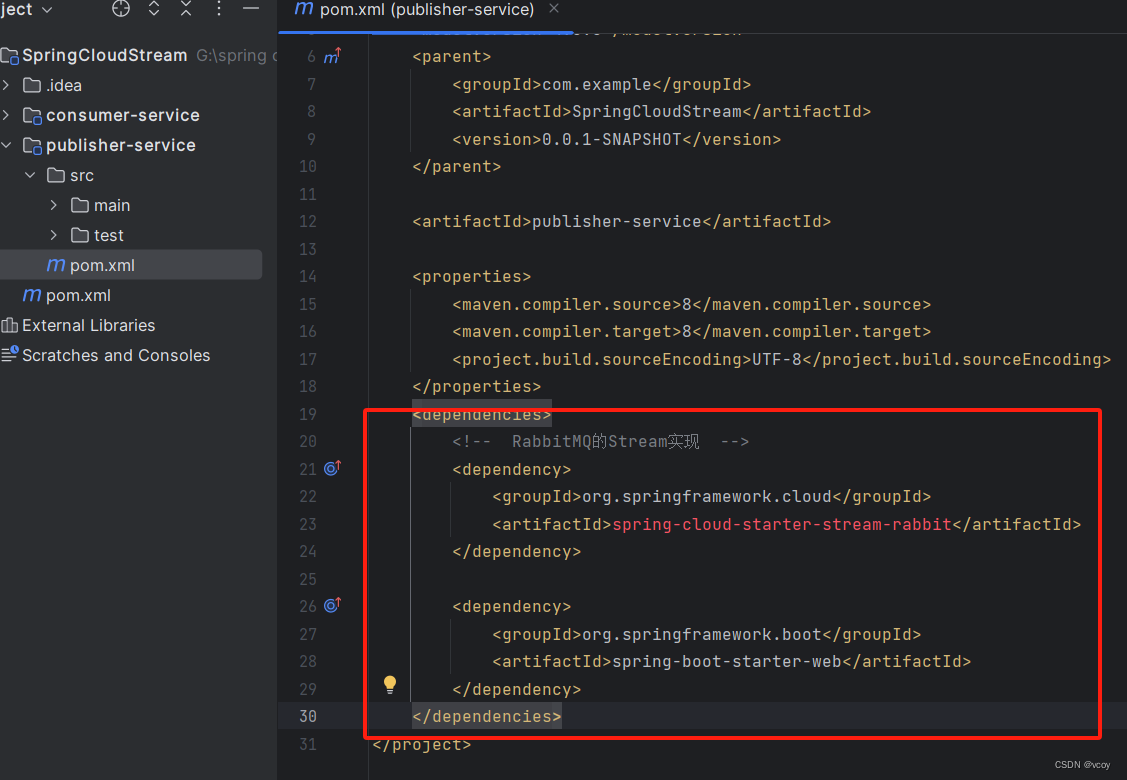
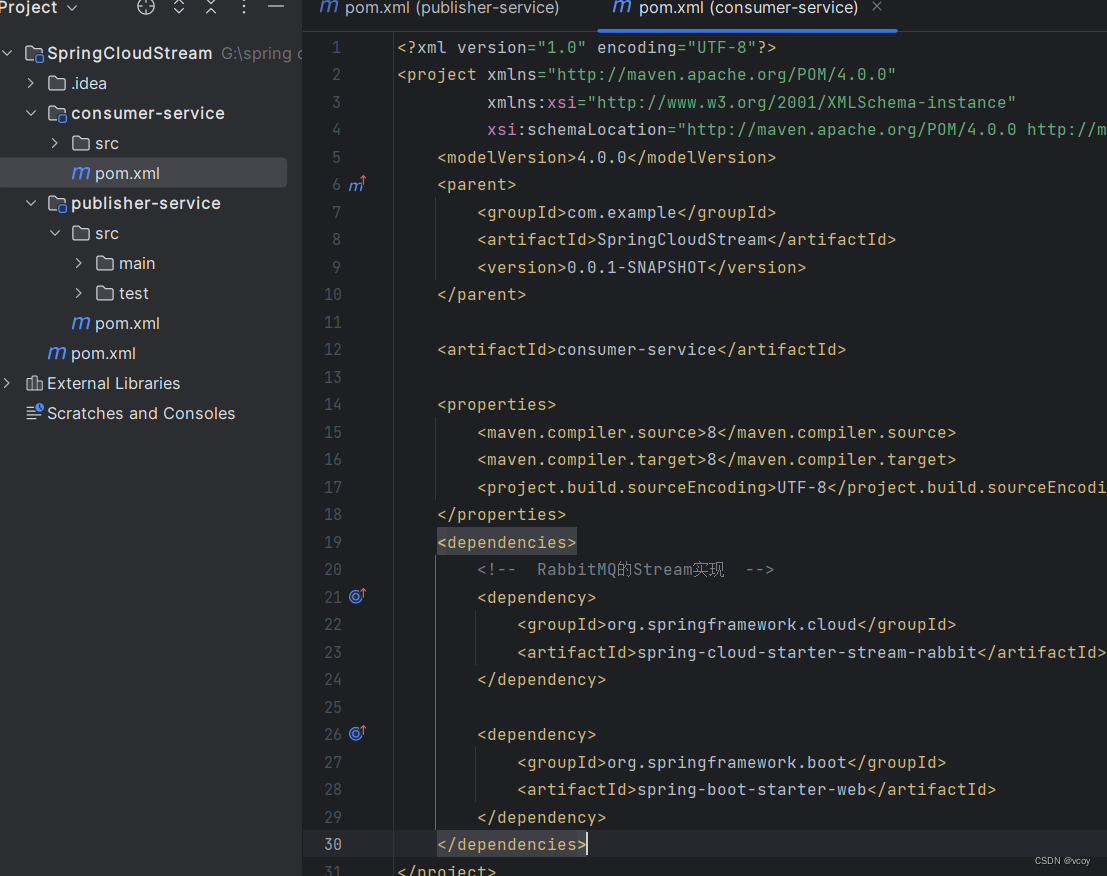
给两个模块导入依赖
<dependencies>
<!-- RabbitMQ的Stream实现 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
1.1 编写生产者
首先是配置文件
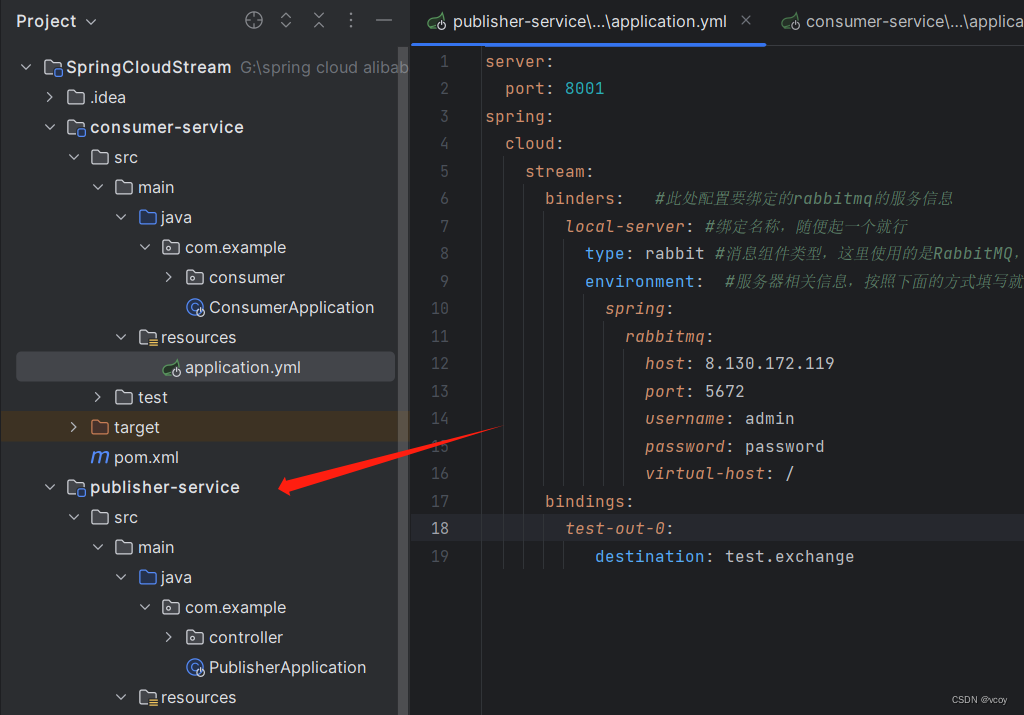
server:
port: 8001
spring:
cloud:
stream:
binders: #此处配置要绑定的rabbitmq的服务信息
local-server: #绑定名称,随便起一个就行
type: rabbit #消息组件类型,这里使用的是RabbitMQ,就填写rabbit
environment: #服务器相关信息,按照下面的方式填写就行,爆红别管
spring:
rabbitmq:
host: 8.130.172.119
port: 5672
username: admin
password: password
virtual-host: /
bindings:
test-out-0:
destination: test.exchange
然后编写controller,访问一次接口,就向消息队列发送一个数据:
@RestController
public class PublishController {
@Resource
StreamBridge bridge; //通过bridge来发送消息
@RequestMapping("/publish")
public String publish(){
//第一个参数其实就是RabbitMQ的交换机名称(数据会发送给这个交换机,到达哪个消息队列,不由我们决定)
//这个交换机的命名稍微有一些规则:
//输入: <名称> + -in- + <index>
//输出: <名称> + -out- + <index>
//这里我们使用输出的方式,来将数据发送到消息队列,注意这里的名称会和之后的消费者Bean名称进行对应
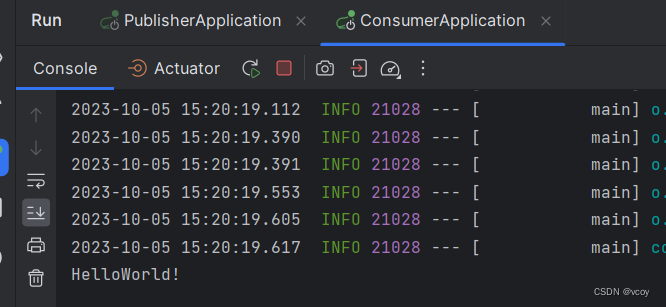
bridge.send("test-out-0", "HelloWorld!");
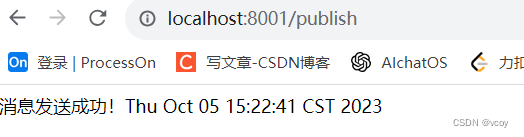
return "消息发送成功!"+new Date();
}
}
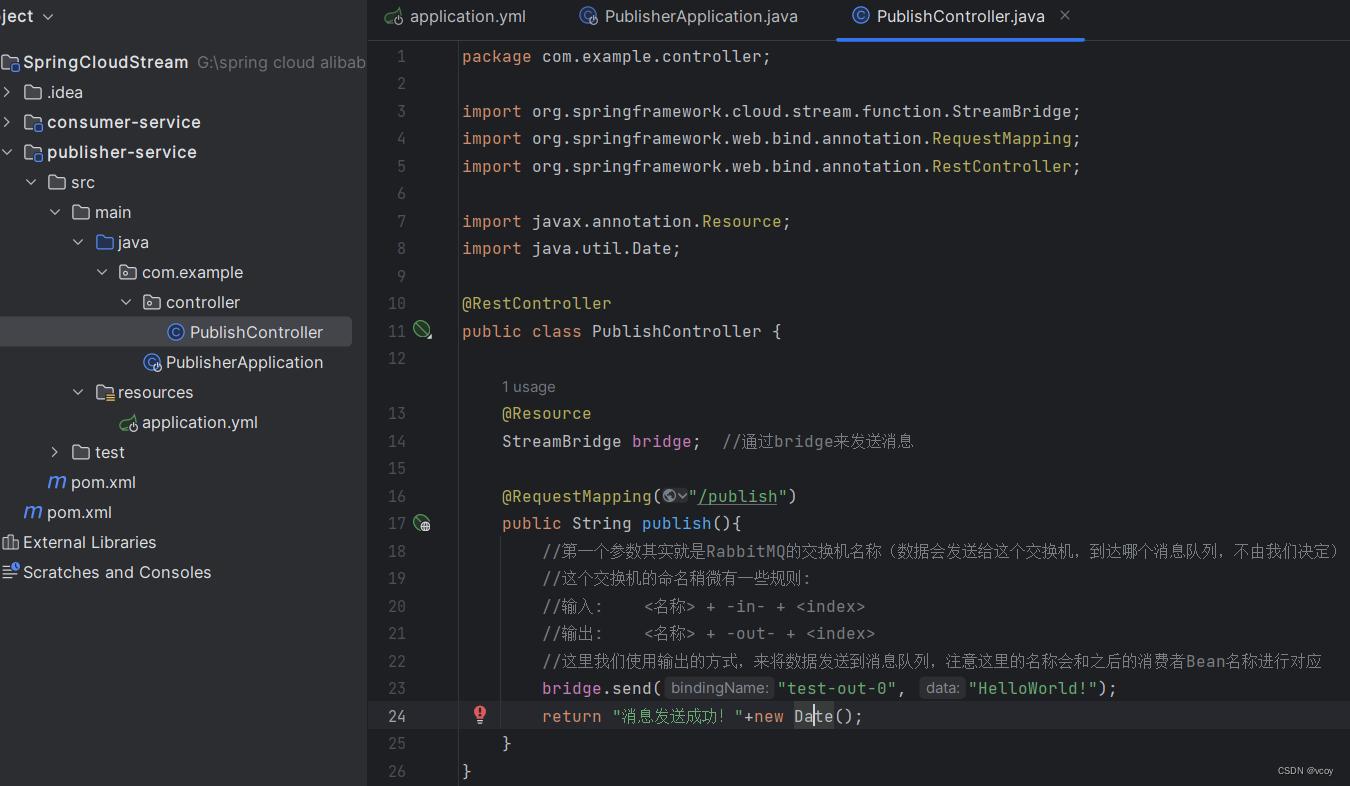
这里生产者就完成了
1.2 消费者
编写配置文件
因为消费者是输入,默认名称为 方法名-in-index,这里我们将其指定为我们刚刚定义的交换机
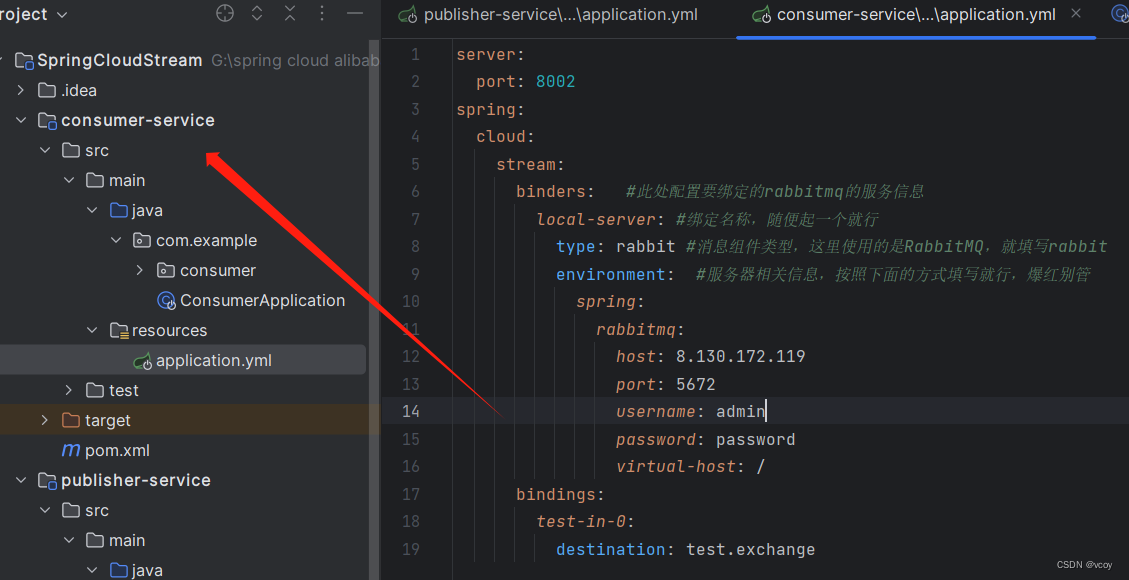
消费者启动类
直接定义一个consumer类型的bean即可
@Component
public class ConsumerComponent {
@Bean("test") //注意这里需要填写我们前面交换机名称中"名称",这样生产者发送的数据才会正确到达
public Consumer<String> consumer(){
return System.out::println;
}
}
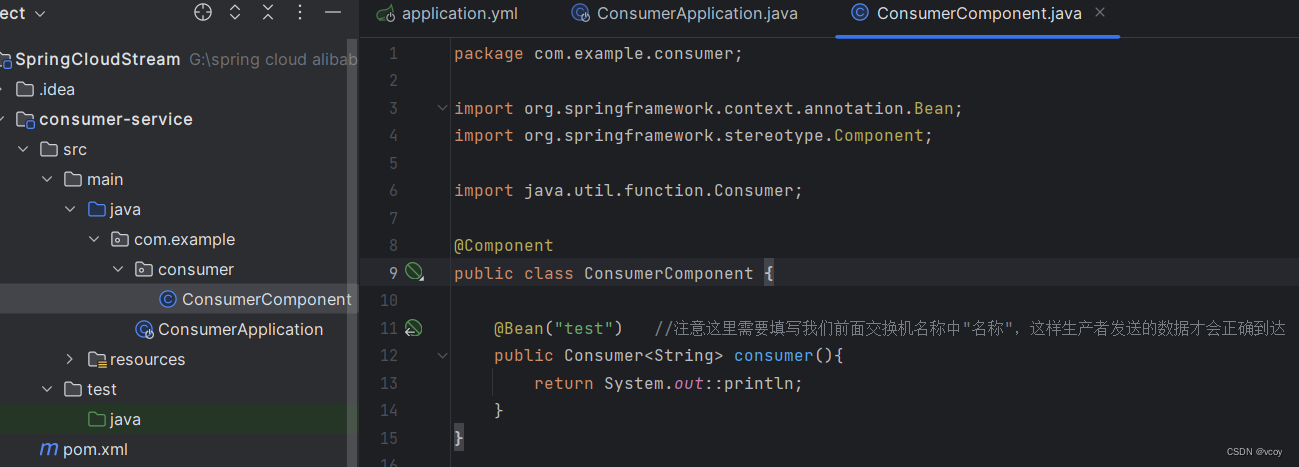
此时消费者就编写完成
1.3 启动测试
启动两个服务
访问controller
消费者接收到消息
这样就通过SpringCloud Stream屏蔽掉底层RabbitMQ来直接进行消息的操作了








![[NISACTF 2022]join-us - 报错注入无列名注入](https://img-blog.csdnimg.cn/f250de7824494bfebf962d7d8c67ab8f.png)