目录
- 1 监控解决方案
- 2 prometheus
- 2.1 容器监控
- 2.2 节点监控
- 2.3 资源对象监控
- 2.4 metrics--server
- 3 prometheus-operator vs kube-prometheus vs helm
- 3.1 prometheus-operator
- 3.2 kube-prometheus
- 3.3 helm
- 参考文档
1 监控解决方案
从实现方案来说,监控分为3个部分:数据采集、数据存储、数据分析。
数据采集是指获取采集对象的指标数据,而数据数据可以分成2种模式:推和拉。推就是agent主动将数据进行上报,拉就是服务端主动从agent拉取数据。
数据存储是指将采集的指标数据存储起来供后续的数据查询和分析,现在通常用时序数据库存储监控数据。
数据分析就是对数据的合理性进行判断,从而发现异常的数据,用于发现现网的问题。
2 prometheus
在容器领域,提到监控就不得不提到prometheus。prometheus是一个开源的解决方案,而且可以很方便的进行扩展。
prometheus的体系中也包含上面提到的三个部分:
- exporter:负责数据采集
- prometheus:数据存储和数据分析
- alertmanager:告警推送
具体的工作流程是:exporter提供采集数据的接口,但自身并不存储数据,只是获取采集对象的数据然后格式化成指标数据,prometheus会定期从exporter拉取数据,然后将数据存储起来,prometheus自身也是个时序数据库,之后prometheus会定期执行用户配置的告警规则,如果满足配置的规则条件,就会调用alertmanager发送告警,alertmanager会对告警进行聚合以及执行一些抑制规则,同时,alertmanager会负责将告警发送到具体的告警通道,例如,短信、钉钉等,也可以开发alerthook程序对接用户自己的告警接口。
因此,使用prometheus监控除了需要部署prometheus以外,重要的是需要采集的对象以及告警规则。
2.1 容器监控
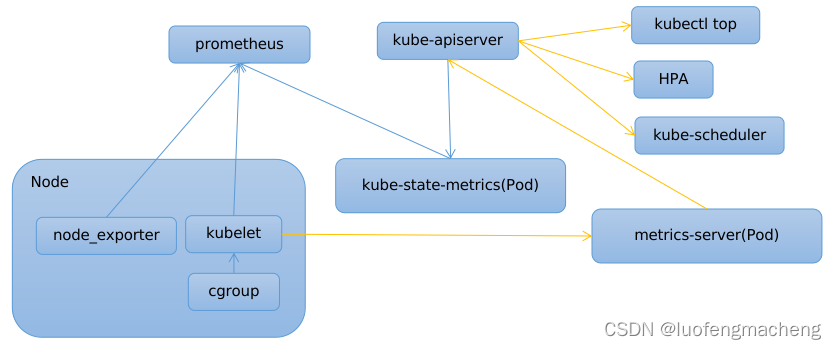
容器的监控依赖cAdvisor组件,该组件会获取容器维度的指标数据,包含容器的CPU、文件读写、内存、网络、线程等指标,当前该组件已经集成到kubelet中,可以直接访问/api/v1/nodes/{node_name}/proxy/metrics/cadvisor接口查看某个节点上的容器指标数据。
2.2 节点监控
当需要监控Node的指标时,需要安装node_exporter:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
labels:
name: node-exporter
k8s-app: node-exporter
spec:
selector:
matchLabels:
name: node-exporter
template:
metadata:
labels:
name: node-exporter
app: node-exporter
spec:
hostPID: true
hostIPC: true
hostNetwork: true
containers:
- name: node-exporter
image: prom/node-exporter:v0.16.0
ports:
- containerPort: 9100
resources:
requests:
cpu: 0.15
securityContext:
privileged: true
args:
- --path.procfs
- /host/proc
- --path.sysfs
- /host/sys
- --collector.filesystem.ignored-mount-points
- '"^/(sys|proc|dev|host|etc)($|/)"'
volumeMounts:
- name: dev
mountPath: /host/dev
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: rootfs
mountPath: /rootfs
tolerations:
- key: "node-role.kubernetes.io/master"
operator: "Exists"
effect: "NoSchedule"
volumes:
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: rootfs
hostPath:
path: /
安装完成后,可以用ss -lntp | grep node_exporter查看node_exporter监听的端口,默认是9100,可以用curl 127.0.0.1:9100/metrics命令查看相应的节点的指标数据。
2.3 资源对象监控
涉及到k8s的资源监控,可以使用kube-state-metrics获取集群资源指标。
rbac.yaml:
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-state-metrics
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-state-metrics
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups: [""]
resources:
- configmaps
- secrets
- nodes
- pods
- services
- resourcequotas
- replicationcontrollers
- limitranges
- persistentvolumeclaims
- persistentvolumes
- namespaces
- endpoints
verbs: ["list", "watch"]
- apiGroups: ["apps"]
resources:
- statefulsets
- daemonsets
- deployments
- replicasets
verbs: ["list", "watch"]
- apiGroups: ["batch"]
resources:
- cronjobs
- jobs
verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]
resources:
- horizontalpodautoscalers
verbs: ["list", "watch"]
- apiGroups: ["networking.k8s.io", "extensions"]
resources:
- ingresses
verbs: ["list", "watch"]
- apiGroups: ["storage.k8s.io"]
resources:
- storageclasses
verbs: ["list", "watch"]
- apiGroups: ["certificates.k8s.io"]
resources:
- certificatesigningrequests
verbs: ["list", "watch"]
- apiGroups: ["policy"]
resources:
- poddisruptionbudgets
verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: kube-state-metrics-resizer
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups: [""]
resources:
- pods
verbs: ["get"]
- apiGroups: ["extensions","apps"]
resources:
- deployments
resourceNames: ["kube-state-metrics"]
verbs: ["get", "update"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-state-metrics
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: kube-state-metrics
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: kube-state-metrics-resizer
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-system
deployment.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: kube-state-metrics
namespace: kube-system
labels:
k8s-app: kube-state-metrics
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
version: v1.3.0
spec:
selector:
matchLabels:
k8s-app: kube-state-metrics
version: v1.3.0
replicas: 1
template:
metadata:
labels:
k8s-app: kube-state-metrics
version: v1.3.0
annotations:
scheduler.alpha.kubernetes.io/critical-pod: ''
spec:
priorityClassName: system-cluster-critical
serviceAccountName: kube-state-metrics
containers:
- name: kube-state-metrics
image: lizhenliang/kube-state-metrics:v1.8.0
ports:
- name: http-metrics
containerPort: 8080
- name: telemetry
containerPort: 8081
readinessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 5
- name: addon-resizer
image: lizhenliang/addon-resizer:1.8.6
resources:
limits:
cpu: 100m
memory: 30Mi
requests:
cpu: 100m
memory: 30Mi
env:
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MY_POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
volumeMounts:
- name: config-volume
mountPath: /etc/config
command:
- /pod_nanny
- --config-dir=/etc/config
- --container=kube-state-metrics
- --cpu=100m
- --extra-cpu=1m
- --memory=100Mi
- --extra-memory=2Mi
- --threshold=5
- --deployment=kube-state-metrics
volumes:
- name: config-volume
configMap:
name: kube-state-metrics-config
---
apiVersion: v1
kind: ConfigMap
metadata:
name: kube-state-metrics-config
namespace: kube-system
labels:
k8s-app: kube-state-metrics
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
data:
NannyConfiguration: |-
apiVersion: nannyconfig/v1alpha1
kind: NannyConfiguration
2.4 metrics–server
以上的三个采集器分别采集容器、节点、资源对象的指标数据,指标都比较多,并且节点和资源对象还需要安装额外的组件。
但是,在k8s中还存在这样一种场景:
- 只需要节点和Pod的简单指标数据,例如cpu和内存,不需要太多数据
- 访问k8s apiserver的接口就可以访问这些数据
- 只需要访问近期的数据就行,不需要保存太长时间
因此,在k8s上加入了metrics-server这样一个插件,它定时访问kubelet的接口获取Node和Pod当前的cpu和memory并保存到内存,当其他功能调用k8s apiserver的接口获取指标数据时,metrcis-server会直接读取内存中的数据返回。
对于minikube,可以通过minikube addons enable metrics-server命令启用,对于k8s就需要额外安装了。
当前有三种场景会访问该接口:
- kubectl top:根据Node和Pod的cpu和memory使用率进行排序
- HPA:根据Pod的cpu和memory使用率进行扩缩容
- kube-scheduler:在调度的优选阶段,会考虑Node的cpu和memory使用率
以上讲解的基本都是数据采集,它们的关系如下:
3 prometheus-operator vs kube-prometheus vs helm
使用prometheus进行监控,可以直接使用prometheus的镜像部署,将配置文件放到configmap,使用pv存储数据,但是这样做的话需要考虑prometheus上下游的组件及其容灾,因此,在kubernetes环境下,提供了operator的部署方式。
operator就是CRD+Controller,通过将prometheus中的配置抽象成kubernetes的CRD,当用户使用CRD进行部署时,Controller就会自动将用户提交的信息转换成prometheus上下游的配置,同时在信息变更时自动执行更新。
部署prometheus-operator有三种方式:
- prometheus-operator:只包含CRD+operator(bundle.yaml),但是并没有部署prometheus、exporter等组件,用户需要自行创建对应的资源进行部署。
- kube-prometheus:除了上面的CRD和operator,还会将整个监控体系都部署,例如,kube-state-metrics、node-exporter、prometheus、alertmanager。
- helm:跟kube-prometheus一样,会部署整个监控体系,只是使用了helm工具。
3.1 prometheus-operator
从prometheus-operator release页面下载bundle.yaml。
执行上面的bundle.yaml后,会创建2部分资源:
- CRD:kubectl get crd | grep monitoring
- operator:kubectl -n monitoring get pods
CRD包含以下的资源:
- AlertManager:部署alertmanager
- PodMonitor:选择需要监控的Pod
- Prometheus:部署prometheus
- PrometheusRule:创建prometheus的监控规则
- ServiceMonitor:选择需要监控的服务
- ThanosRuler
而operator的作用就是让这些资源生效,当这些资源变更或者相关资源变更时,执行相应的变更逻辑。
所以,如果只部署上面的yaml文件,本身并没有部署任何跟监控相关的组件,只是让k8s中多了一些资源的类型,但是这些资源的变化需要operator控制器去执行一些操作,例如,如果需要部署prometheus,就需要创建Prometheus资源,在创建这些后,prometheus-operator就会去部署prometheus;如果需要创建监控规则,就需要创建PrometheusRule资源,prometheus-operator就会将这些规则加入到prometheus的规则配置文件中并让其生效。
3.2 kube-prometheus
git clone https://github.com/prometheus-operator/kube-prometheus
kubectl apply --server-side -f manifests/setup # 创建namespace和CRD
kubectl apply -f manifests/
上面的manifests目录中包含prometheus-operator以及整个监控体系的所有组件,包含:
- The Prometheus Operator
- Highly available Prometheus:高可用的Prometheus
- Highly available Alertmanager:高可用的AlertManager
- Prometheus node-exporter
- Prometheus Adapter for Kubernetes Metrics APIs
- kube-state-metrics
- Grafana
3.3 helm
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo update
helm install [RELEASE_NAME] prometheus-community/kube-prometheus-stack
使用上面的命令可以直接安装整个监控体系。
参考文档
- 使用Operator部署Prometheus监控k8s集群
- 从kubectl top看K8S监控