本文将带你深入了解串的基本概念、表示方法以及串操作的常见算法。通过深入理解串的相关概念和操作,我们将能够更好地应用它们来解决算法问题。
无论你是初学者还是进阶者,本文将为你提供简单易懂、实用可行的知识点,帮助你更好地掌握串在数据结构和算法中的重要性,进而提升算法解题的能力。接下来让我们开启数据结构与算法的奇妙之旅吧。
目录
串的定义与基本操作
串的存储结构
串的模式匹配算法
串的常见应用
串的定义与基本操作
串(也称字符串)是由零个或多个字符组成的有限序列。在计算机科学中,串通常被定义为一个字符数组,其长度可以是任意的。一般记为 S = '····
' (n
0)
其中,S是串名,单引号括起来的字符序列是串的值;
可以是字母、数字或其他字符;串中字符的个数n称为串的长度。n = 0 时的串称为空串(用
表示)
例如:S = "HelloWorld!" T = 'iPhone 15 Pro Max' 注意:字符串有的语言用双引号,有的单引号
子串:串中任意个连续的字符组成的子序列。 Eg:‘iPhone’、'Pro M' 是串T的子串
主串:包含子串的串。 Eg:T是子串 'iPhone' 的主串
字符在主串中的位置”:字符在串中的序号。 Eg:'1' 在T中的位置是8(第一次出现)位序从1
子串在主串的位置:第一字符在主串的位置。 Eg:'11 Pro' 在T中的位置为8
空串: M = '' ;空格串:N = ' '
串是一种特殊的线性表,数据元素之间呈线性关系:
串的数据对象限定为字符集(如中文字符、英文字符、数字字符、标点字符等),串的基本操作如增删改查等通常以子串为操作对象。串的基本操作如下(以C语言举例,这里仅仅是介绍概念):
StrAssign(&T,chars):赋值操作。把串T赋值为chars。
StrCopy(&T,S):复制操作。由串复制得到串T。
StrEmpty(S):判空操作。若S为空串,则返回TRUE,否则返回FALSE。
StrLength(S):求串长。返回串S的元素个数。
ClearString(&S):清空操作。将S清为空串。
DestroyString(&S):销毁串。将串S销毁(回收存储空间)。
Concat(&T,S1,S2):串联接。用T返回由S1和S2联接而成的新串。
SubString(&Sub,S,pos,len):求子串。用Sub返回串S的第pos个字符起长度为len的子串。
Index(S,T):定位操作。若主串S中存在与串T值相同的子串,则返回它在主串S中第一次出现的位置;否则函数值为0。
StrCompare(S,T):比较操作。若S>T,则返回值>0;若S=T,则返回值=0;若S<T,则返回值<0。
假设有串 T='' ,S='iPhone 15 Pro Max?',W='Pro'
Eg:执行如下基本操作返回相应的结果如下:
Concat(&T,S,W)后,T='iPhone 15 Pro Max?Pro'
SubString(&T,S,4,6)后,T='one 15'
Index(S,W)后,返回值为11
回顾重点,其主要内容整理成如下内容:

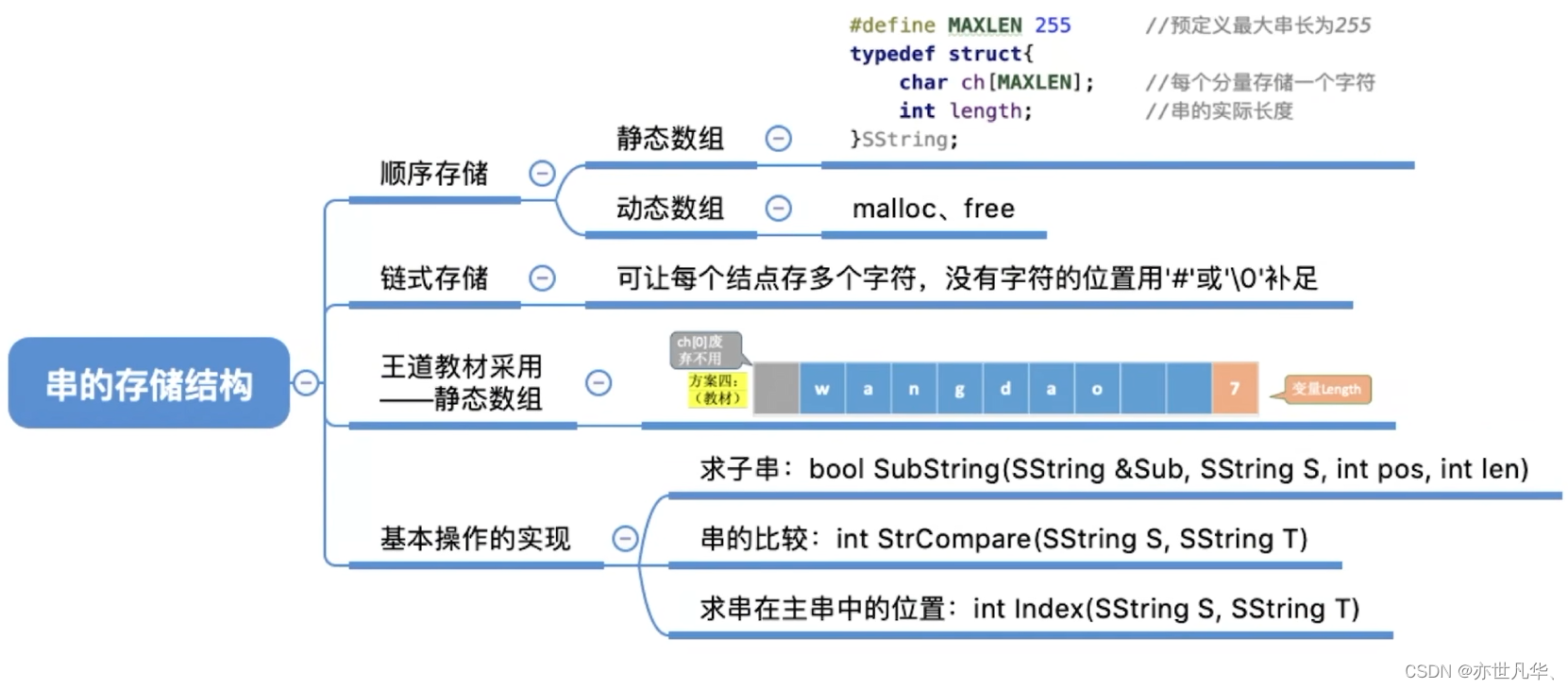
串的存储结构
串是一种特殊的线性表,我们以什么样的方式实现线性表同样我们也可以用什么样的方式实现串
顺序存储:将一个串中的各个字符按照顺序依次存放在一段连续的存储空间中,称为串的顺序存储,具有随机访问的特点。
串的顺序存储结构通常使用字符数组来实现,每个字符都占据一个数组元素,因此在定义字符数组时需要保证空间足够容纳整个字符串。在C语言中,可以使用以下方式定义一个长度为n的字符数组str,用于存储最长长度为n-1的字符串:
char str[n];当然字符串的顺序存储结构也可以使用动态数组来实现,这种方法需要在运行时根据字符串的长度动态分配内存空间。
下面是C语言中实现字符串顺序存储的一些基本操作:
#include <stdio.h>
#include <stdlib.h> //需要include<stdlib.h>库函数
#define MAX_SIZE 1000 //定义字符串最大长度
typedef struct {
char str[MAX_SIZE];
int length;
} SeqString;
//初始化串
void InitSeqString(SeqString* S, char* str) {
int i = 0;
while (str[i]) { //统计字符串长度
++i;
}
S->length = i;
for (i = 0; i < S->length; ++i) {
S->str[i] = str[i];
}
}
//获取串长
int LengthSeqString(SeqString S) {
return S.length;
}
//获取某个位置的字符
char GetSeqString(SeqString S, int i) {
if (i < 1 || i > S.length) { //判断位置是否合法
printf("Position %d is invalid.\n", i);
exit(1);
}
return S.str[i - 1];
}
//修改某个位置上的字符
void SetSeqString(SeqString* S, int i, char ch) {
if (i < 1 || i > S->length) { //判断位置是否合法
printf("Position %d is invalid.\n", i);
exit(1);
}
S->str[i - 1] = ch;
}
//在某个位置插入字符
void InsertSeqString(SeqString* S, int i, char ch) {
if (i < 1 || i > S->length + 1) { //判断位置是否合法
printf("Position %d is invalid.\n", i);
exit(1);
}
if (S->length >= MAX_SIZE) { //判断是否越界
printf("The string is full.\n");
exit(1);
}
for (int j = S->length - 1; j >= i - 1; --j) { //从后往前依次向后移动字符
S->str[j + 1] = S->str[j];
}
S->str[i - 1] = ch;
++S->length; //串长加1
}
//删除某个位置上的字符
void DeleteSeqString(SeqString* S, int i) {
if (i < 1 || i > S->length) { //判断位置是否合法
printf("Position %d is invalid.\n", i);
exit(1);
}
for (int j = i; j < S->length; ++j) { //从前往后依次向前移动字符
S->str[j - 1] = S->str[j];
}
--S->length; //串长减1
}
//清空串
void ClearSeqString(SeqString* S) {
S->length = 0;
}
//复制串
void CopySeqString(SeqString S, SeqString* T) {
T->length = S.length;
for (int i = 0; i < S.length; ++i) {
T->str[i] = S.str[i];
}
T->str[T->length] = '\0'; //在复制后的字符串尾部加上结束符'\0'
}
//连接两个串
void ConcatSeqString(SeqString* S, SeqString T) {
if (S->length + T.length <= MAX_SIZE) { //判断是否超出最大长度
for (int i = 0; i < T.length; ++i) {
S->str[i + S->length] = T.str[i]; //将T中的字符复制到S末尾
}
S->length += T.length;
} else {
printf("The new string exceeds the maximum length.\n");
}
}
//比较两个串是否相等
int CompareSeqString(SeqString S, SeqString T) {
if (S.length != T.length) { //如果长度不相等,直接返回0
return 0;
}
for (int i = 0; i < S.length; ++i) {
if (S.str[i] != T.str[i]) { //如果某个字符不相等,返回0
return 0;
}
}
return 1;
}
int main() {
SeqString S, T;
char str1[] = "Hello World!";
char str2[] = "This is a test.";
InitSeqString(&S, str1);
printf("Length of S: %d\n", LengthSeqString(S)); //13
printf("Character at position 6 of S: %c\n", GetSeqString(S, 6)); //W
SetSeqString(&S, 7, 'X');
printf("Modified string: %s\n", S.str); //Hello WXrld!
InitSeqString(&T, str2);
InsertSeqString(&T, 3, 'x');
printf("Inserted string: %s\n", T.str); //Thix is a test.
DeleteSeqString(&S, 6);
printf("Deleted string: %s\n", S.str); //Hello Xrld!
CopySeqString(T, &S);
printf("Copied string: %s\n", S.str); //Thix is a test.
ConcatSeqString(&S, T);
printf("Concatenated string: %s\n", S.str); //Thix is a test.Thix is a test.
ClearSeqString(&S);
printf("Length of S: %d\n", LengthSeqString(S)); //0
printf("S and T are%s equal.\n", CompareSeqString(S, T) ? "" : " not"); //S and T are not equal.
return 0;
}链式存储: 使用链表的方式存储一个字符串。与顺序存储不同,链式存储可以实现动态分配内存,无需预先确定字符串长度,可以灵活地进行插入、删除等操作。
串的链式存储可以采用单向链表、双向链表或循环链表来实现,每个节点存储一个字符。为方便起见,通常在链表末尾添加一个空字符表示该串结束。对于空串,可以定义一个只包含头结点的链表。
下面是C语言中实现字符串链式存储的一些基本操作:
#include <stdio.h>
#include <stdlib.h> //需要include<stdlib.h>库函数
typedef struct LNode {
char data;
struct LNode *next;
} LNode, *LinkList;
//初始化一个空串
void InitString(LinkList* L) {
*L = (LinkList)malloc(sizeof(LNode)); //创建头结点
(*L)->next = NULL;
}
//判断是否为空串
int IsEmpty(LinkList L) {
return L->next == NULL;
}
//获取串长
int LengthString(LinkList L) {
int len = 0;
LNode *p = L->next;
while (p) {
++len;
p = p->next;
}
return len;
}
//获取某个位置的字符
char GetChar(LinkList L, int i) {
if (i < 1 || i > LengthString(L)) { //判断位置是否合法
printf("Position %d is invalid.\n", i);
exit(1);
}
LNode *p = L->next;
int k = 1;
while (k < i) {
p = p->next;
++k;
}
return p->data;
}
//在某个位置插入字符
void InsertChar(LinkList* L, int i, char ch) {
if (i < 1 || i > LengthString(*L) + 1) { //判断位置是否合法
printf("Position %d is invalid.\n", i);
exit(1);
}
LNode *p = *L, *q;
int k = 1;
while (k < i) {
p = p->next;
++k;
}
q = (LNode*)malloc(sizeof(LNode)); //创建新结点
q->data = ch;
q->next = p->next;
p->next = q;
}
//删除某个位置上的字符
void DeleteChar(LinkList* L, int i) {
if (i < 1 || i > LengthString(*L)) { //判断位置是否合法
printf("Position %d is invalid.\n", i);
exit(1);
}
LNode *p = *L, *q;
int k = 1;
while (k < i) {
p = p->next;
++k;
}
q = p->next;
p->next = q->next;
free(q); //释放被删除的结点
}
//清空串
void ClearString(LinkList* L) {
LNode *p = (*L)->next, *q;
while (p) {
q = p->next;
free(p); //释放结点内存
p = q;
}
(*L)->next = NULL;
}
//复制串
void CopyString(LinkList S, LinkList* T) {
LNode *p = S->next, *q, *r;
*T = (LinkList)malloc(sizeof(LNode)); //创建头结点
r = *T;
while (p) {
q = (LNode*)malloc(sizeof(LNode)); //创建新结点
q->data = p->data;
r->next = q;
r = q;
p = p->next;
}
r->next = NULL;
}
//连接两个串
void ConcatString(LinkList* S, LinkList T) {
LNode *p = (*S)->next;
while (p->next) { //找到S的尾结点
p = p->next;
}
p->next = T->next; //将T中的结点添加到S末尾
free(T); //释放T的头结点
}
//比较两个串是否相等
int CompareString(LinkList S, LinkList T) {
LNode *p = S->next, *q = T->next;
while (p && q && p->data == q->data) { //依次比较两个串中每个字符
p = p->next;
q = q->next;
}
if (!p && !q) { //如果两个串长度相等且所有字符相等,返回1
return 1;
} else {
return 0;
}
}
int main() {
LinkList S, T;
InitString(&S);
printf("Is S empty? %s\n", IsEmpty(S) ? "Yes" : "No"); //Yes
InsertChar(&S, 1, 'H');
InsertChar(&S, 2, 'e');
InsertChar(&S, 3, 'l');
InsertChar(&S, 4, 'l');
InsertChar(&S, 5, 'o');
printf("Length of S: %d\n", LengthString(S)); //5
printf("Character at position 3 of S: %c\n", GetChar(S, 3)); //l
DeleteChar(&S, 2);
printf("Modified string: ");
for (LNode *p = S->next; p; p = p->next) {
printf("%c", p->data);
}
printf("\n"); //Hello
InitString(&T);
InsertChar(&T, 1, 'W');
InsertChar(&T, 2, 'o');
InsertChar(&T, 3, 'r');
InsertChar(&T, 4, 'l');
InsertChar(&T, 5, 'd');
printf("Are S and T equal? %s\n", CompareString(S, T) ? "Yes" : "No"); //No
ClearString(&S);
printf("Is S empty? %s\n", IsEmpty(S) ? "Yes" : "No"); //Yes
CopyString(T, &S);
printf("Copied string: ");
for (LNode *p = S->next; p; p = p->next) {
printf("%c", p->data);
}
printf("\n"); //World
ConcatString(&S, T);
printf("Concatenated string: ");
for (LNode *p = S->next; p; p = p->next) {
printf("%c", p->data);
}
printf("\n"); //WorldWorld
return 0;
}回顾重点,其主要内容整理成如下内容:
串的模式匹配算法
串的模式匹配算法用于在一个主串中查找某个子串的出现位置或匹配情况。常见的模式匹配算法包括朴素算法(暴力算法)和 KMP算法。
朴素算法:
原理:从主串的第一个字符开始,逐个比较主串和子串对应位置的字符,若不匹配,则将子串向后移动一位,再进行比较,直到子串完全匹配或主串遍历完毕。
实现方式:使用两个指针分别指向主串和子串,进行逐个比较。
代码示例:
int naiveStringMatch(const string& text, const string& pattern) {
int n = text.length();
int m = pattern.length();
for (int i = 0; i <= n - m; i++) {
int j;
for (j = 0; j < m; j++) {
if (text[i + j] != pattern[j]) {
break;
}
}
if (j == m) {
return i; // 匹配成功,返回子串在主串中的起始位置
}
}
return -1; // 未找到匹配的子串
}回顾重点,其主要内容整理成如下内容:
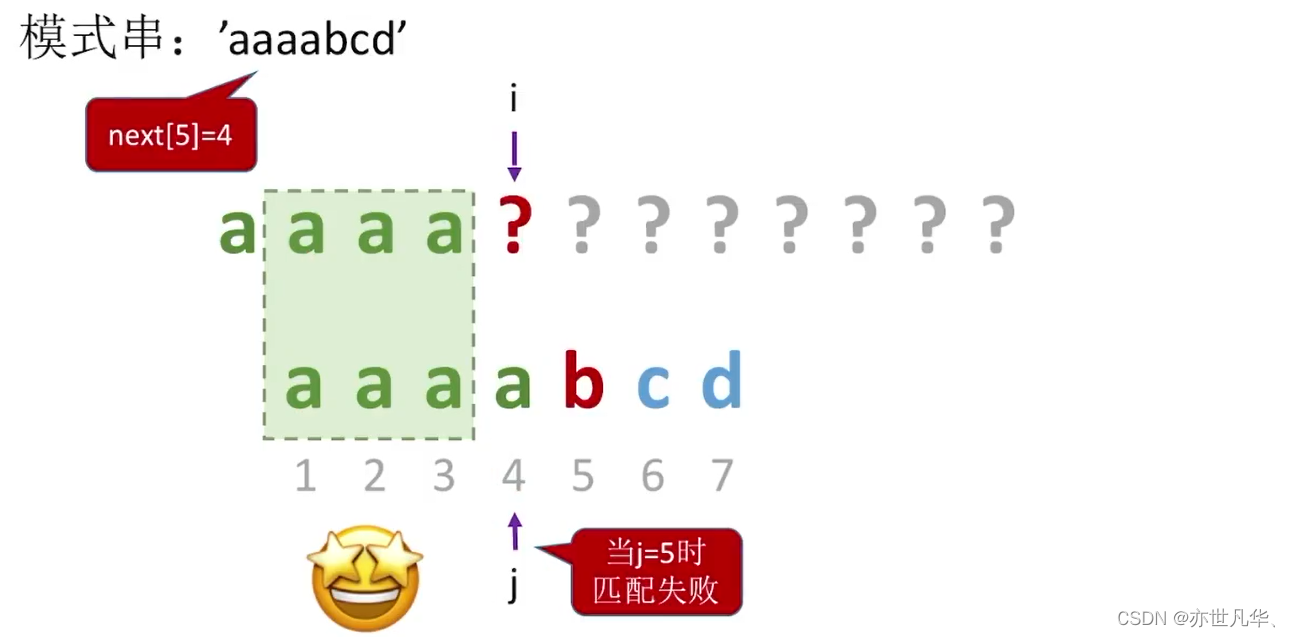
KMP算法:
原理:通过预处理模式串构建部分匹配表,根据部分匹配表中的信息进行跳跃匹配,避免重复比较已经匹配过的字符。
实现方式:使用两个指针分别指向主串和子串,并维护一个部分匹配表。
相关图例如下:

代码示例:
void buildPartialMatchTable(const string& pattern, vector<int>& table) {
int m = pattern.length();
table.resize(m);
table[0] = 0;
int len = 0;
int i = 1;
while (i < m) {
if (pattern[i] == pattern[len]) {
len++;
table[i] = len;
i++;
} else {
if (len > 0) {
len = table[len - 1];
} else {
table[i] = 0;
i++;
}
}
}
}
int kmpStringMatch(const string& text, const string& pattern) {
int n = text.length();
int m = pattern.length();
vector<int> table;
buildPartialMatchTable(pattern, table);
int i = 0; // 主串的指针
int j = 0; // 子串的指针
while (i < n) {
if (text[i] == pattern[j]) {
i++;
j++;
if (j == m) {
return i - j; // 匹配成功,返回子串在主串中的起始位置
}
} else {
if (j > 0) {
j = table[j - 1]; // 根据部分匹配表进行跳跃
} else {
i++;
}
}
}
return -1; // 未找到匹配的子串
}next数组:在KMP算法中,next数组(也称为部分匹配表)是用于辅助模式串匹配的数据结构。它存储了在模式串中,每个位置的最长相同前缀后缀的长度。在考研的过程中我们也需要根据提供的模式串T来求解出next数组:

接下来我们已google模式串进行举例如何计算出相应的next数组的值:
next[1]第一个字符不匹配时:
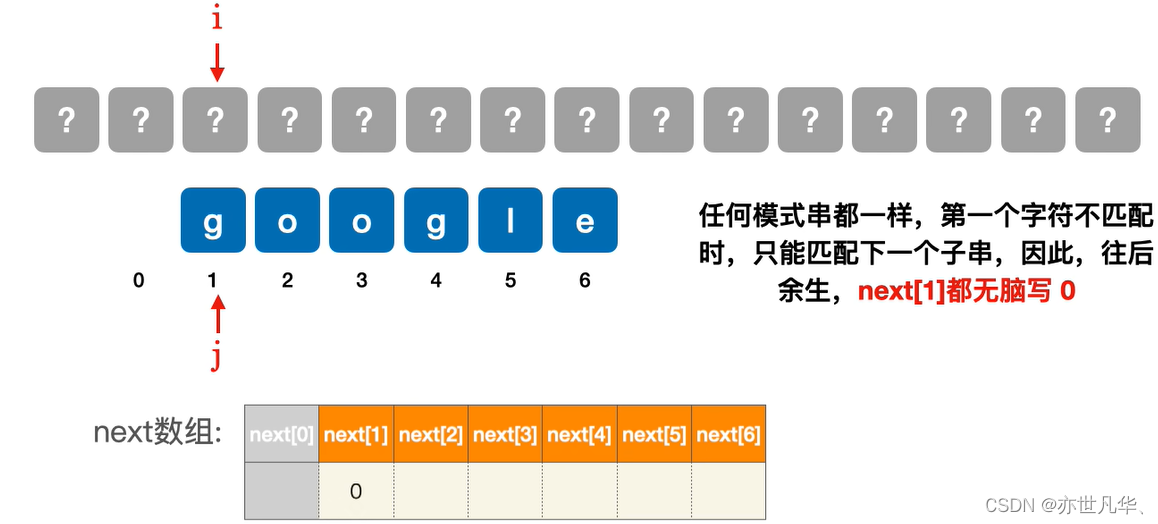
next[2]第二个字符不匹配时:
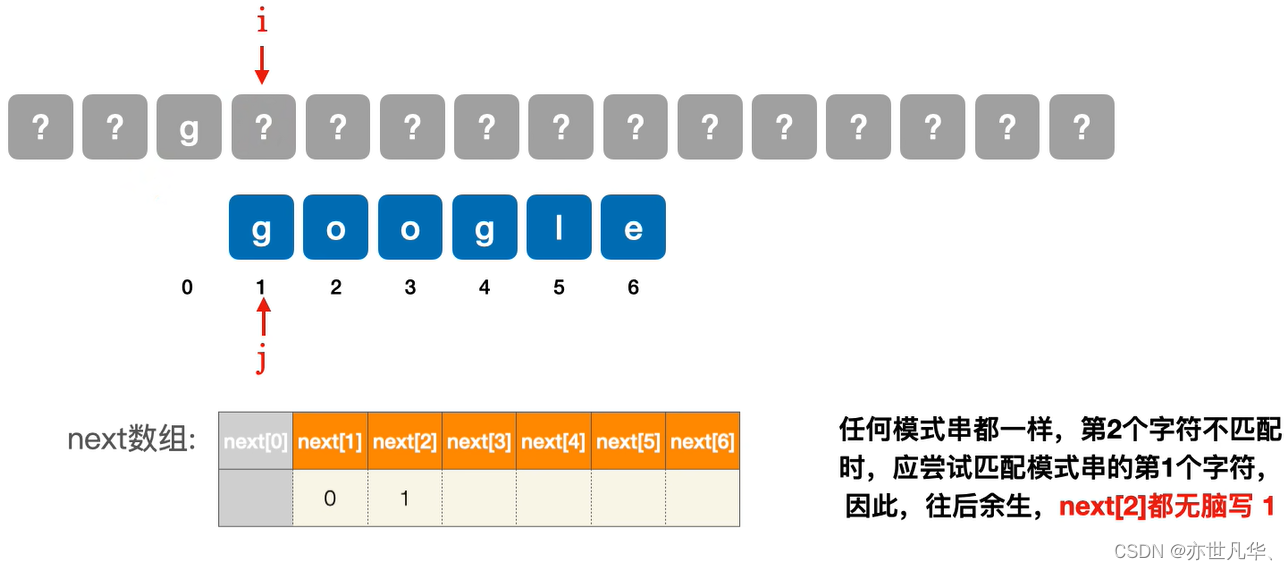
next[3]第三个字符不匹配时:
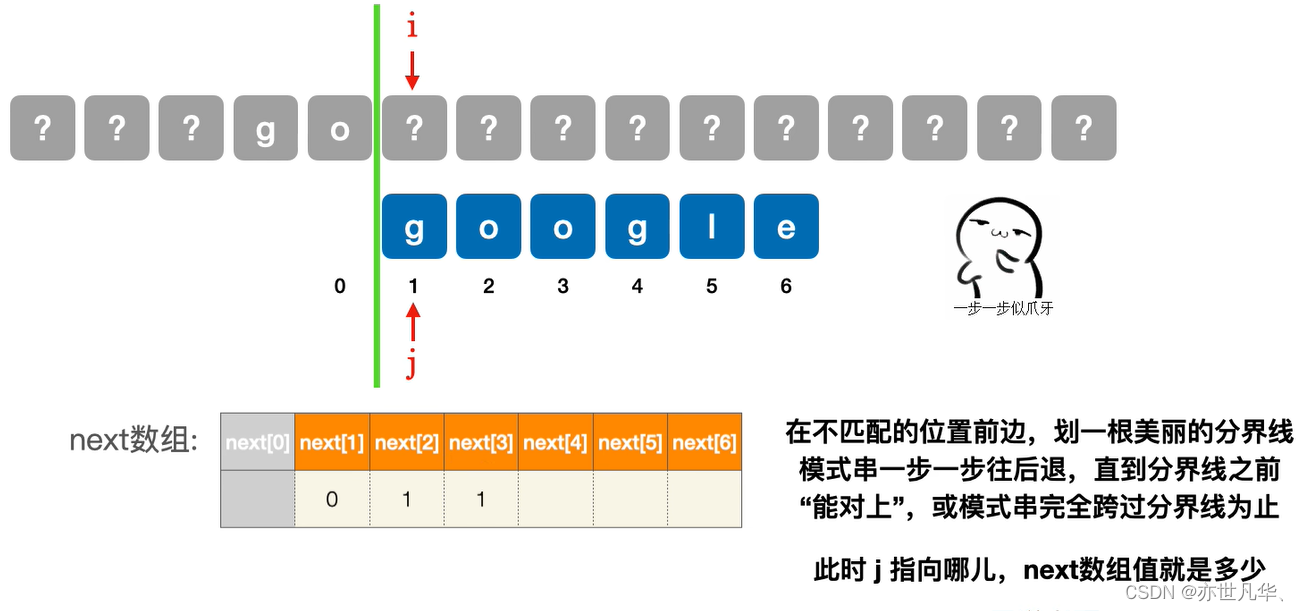
next[4]第四个字符不匹配时:
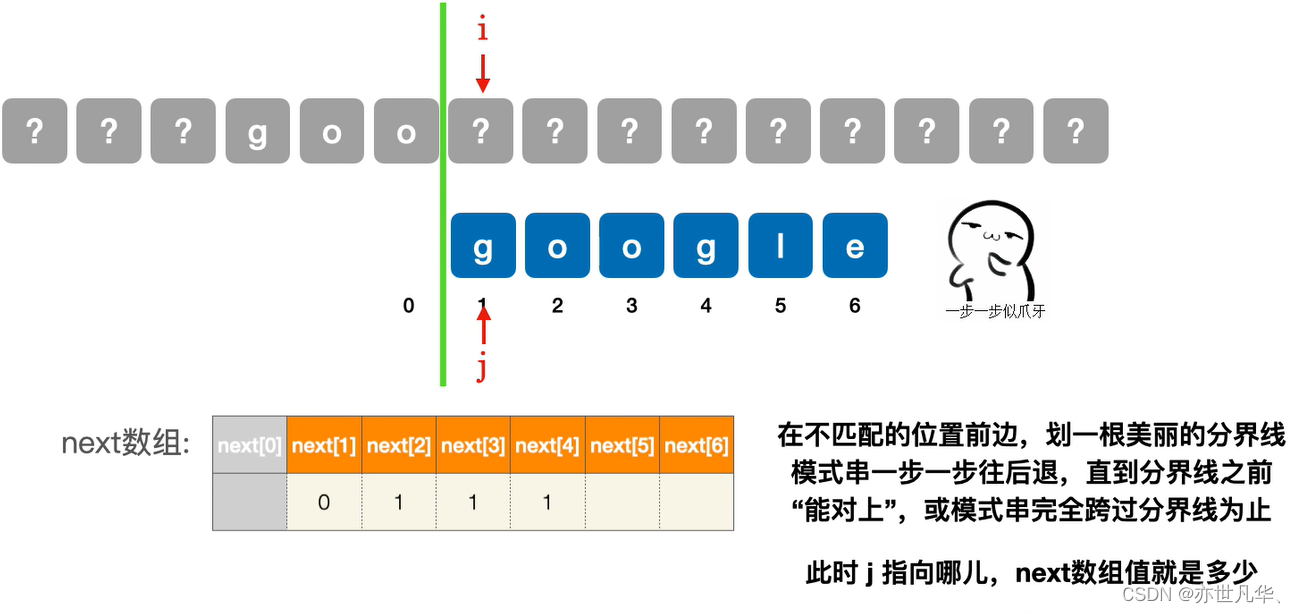
next[5]第五个字符不匹配时:
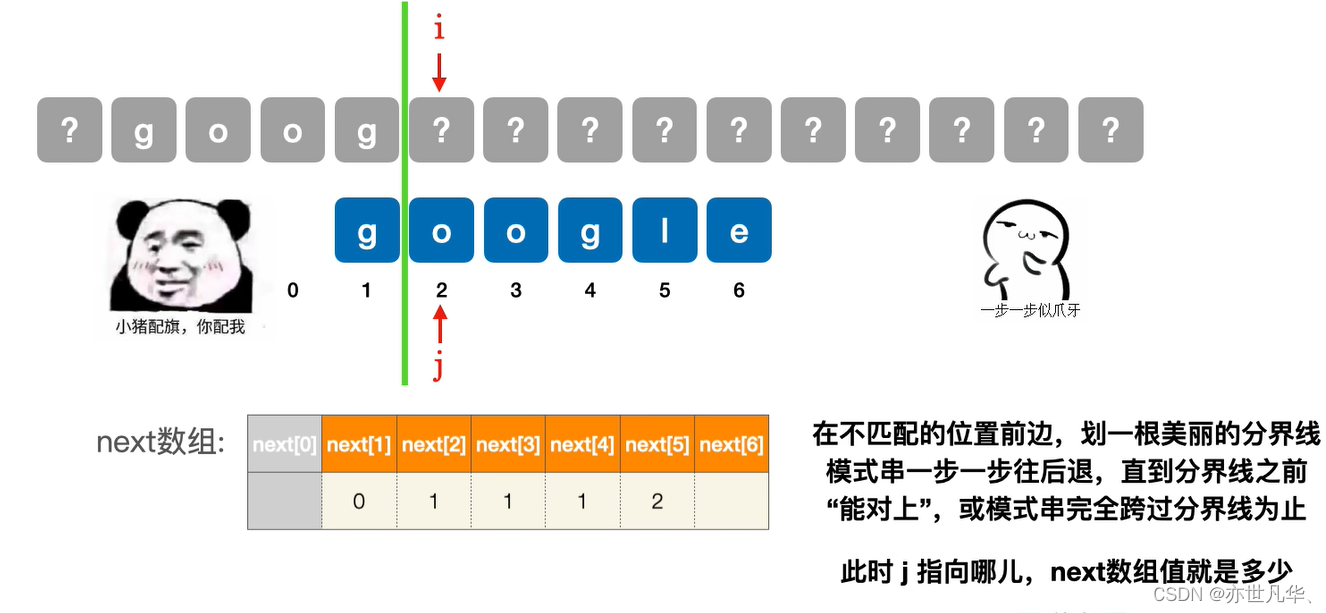
next[6]第六个字符不匹配时:
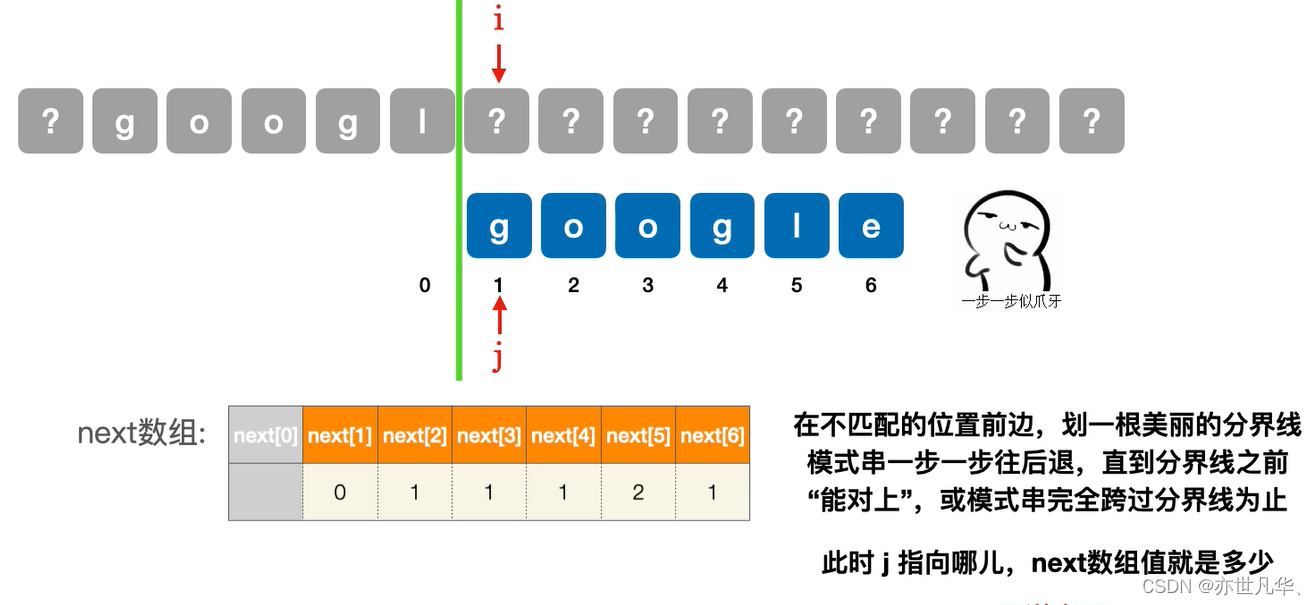
使用next数组:在上文我们已经通过手算的方式得出next数组,接下来我们开始对该next数组进行相应的使用,起具体的主串如下,模式串就用我们之前得到next数组的字符串google:
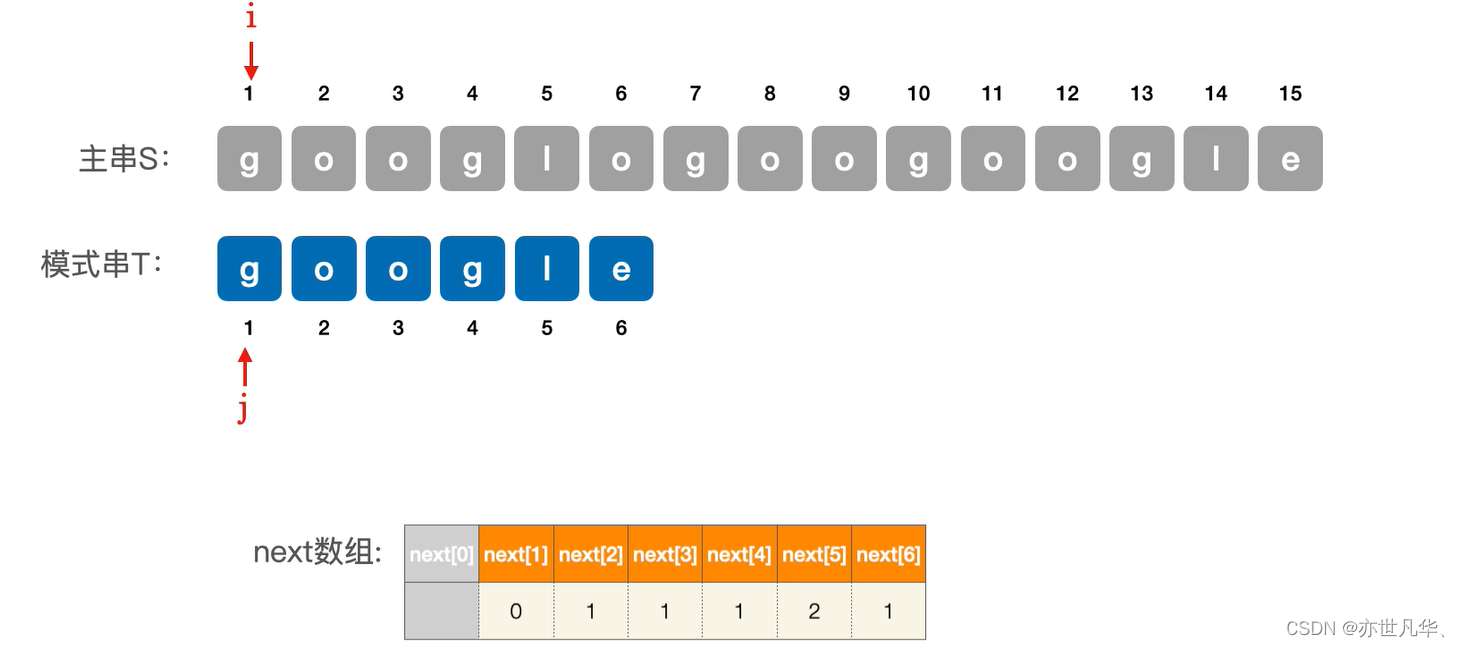
在上面我们给出了具体的主串,这里我们将主串和模式串进行依次的匹配,直到第六个没有匹配成功, 也就是说当j为6的时候匹配失败,所以我们需要令 j = next[j] = 1 (j=6)。所以接下来我们需要令模式串在下面的这个位置开始匹配:
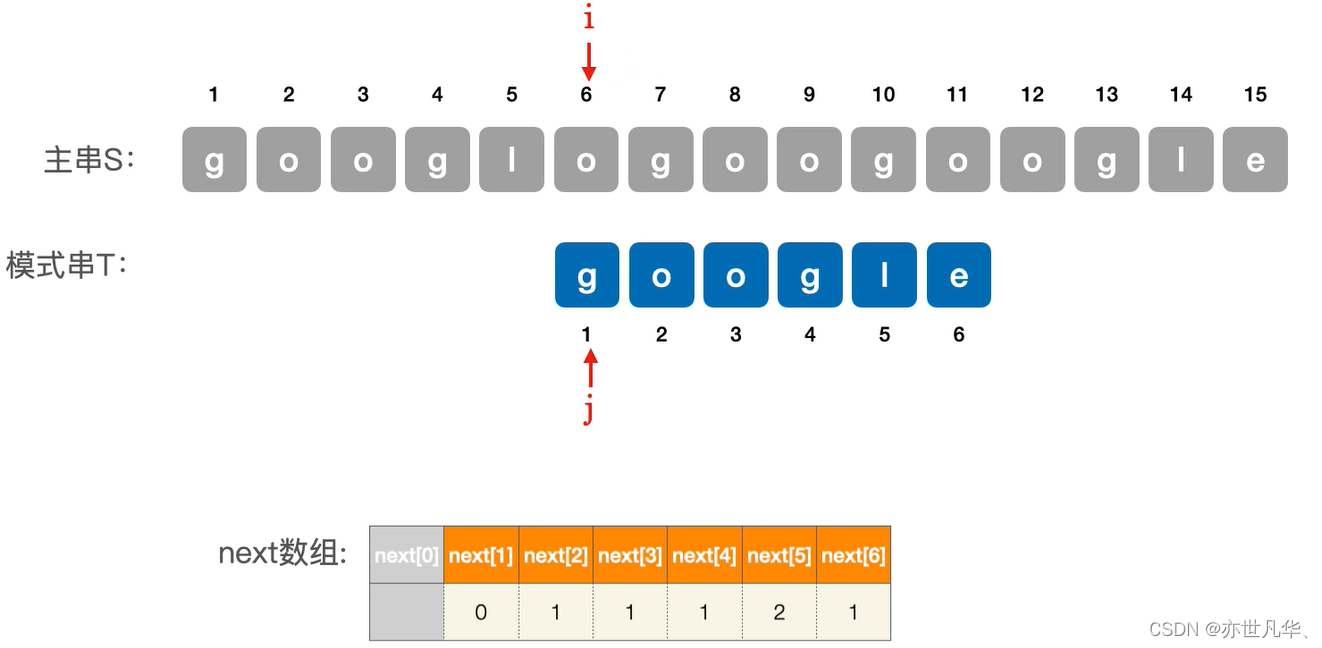
在上面的位置我们还是发现主串和模式串不匹配,而且是在第一个字符情况下,所以这里我们我们的 j = next[1] = 0,如果我们检测到j为0的话就需要i和j都进行++操作,也就是开始匹配下一个字符串:
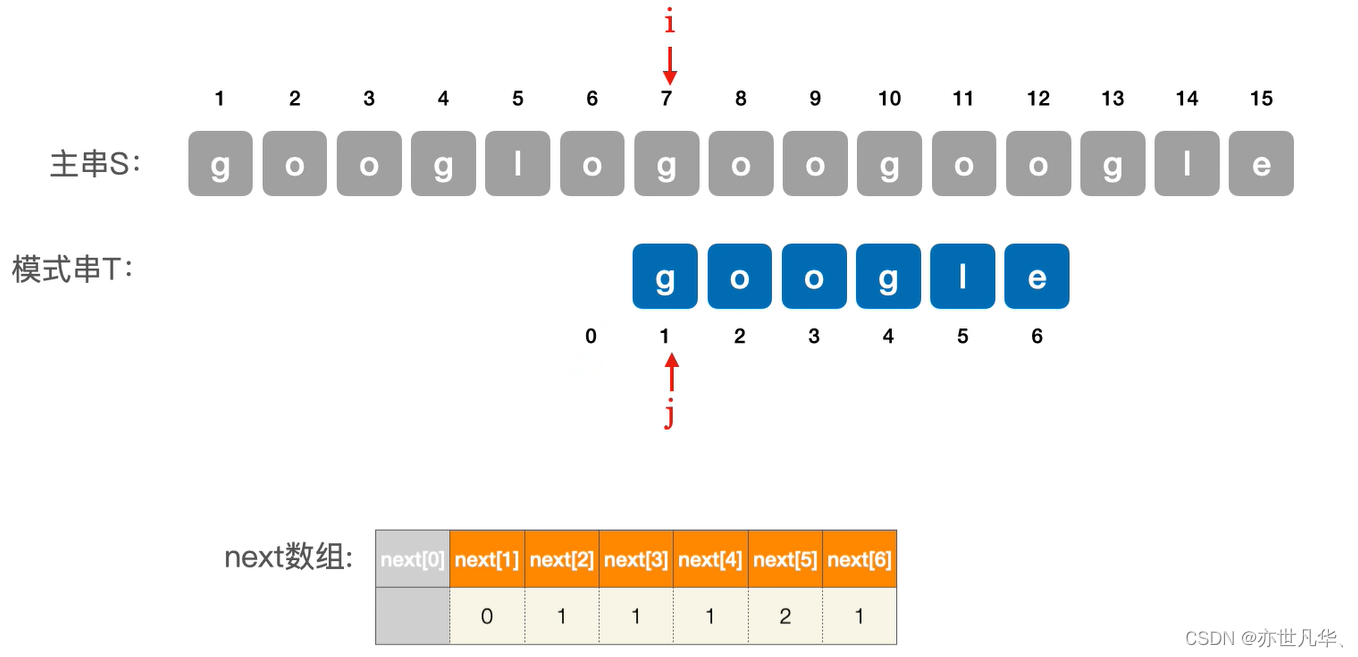
在上面的主串和模式串对比中我们发现在第五个字符串的时候出现了不同如下:
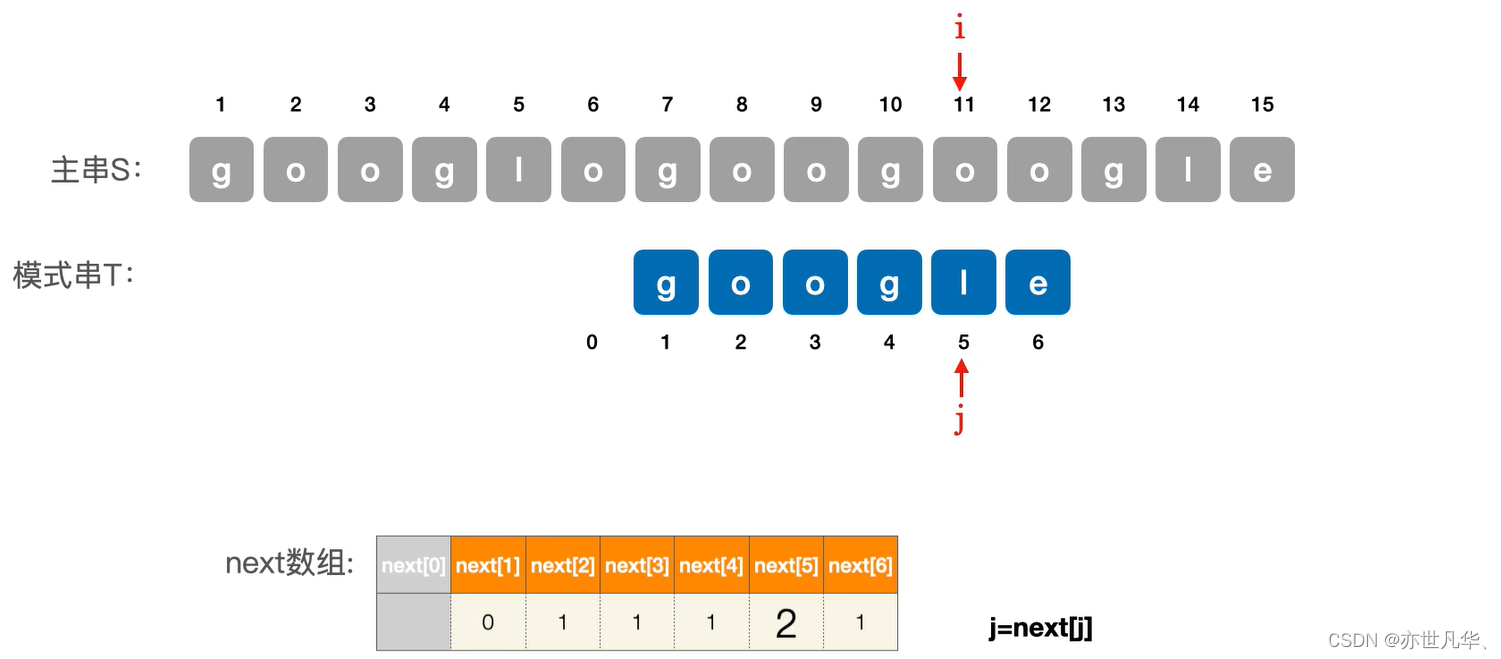
·所以在保持i不变的情况下,我们需要令 j = next[5] = 2 ,也就是从j为2的时候开始匹配:
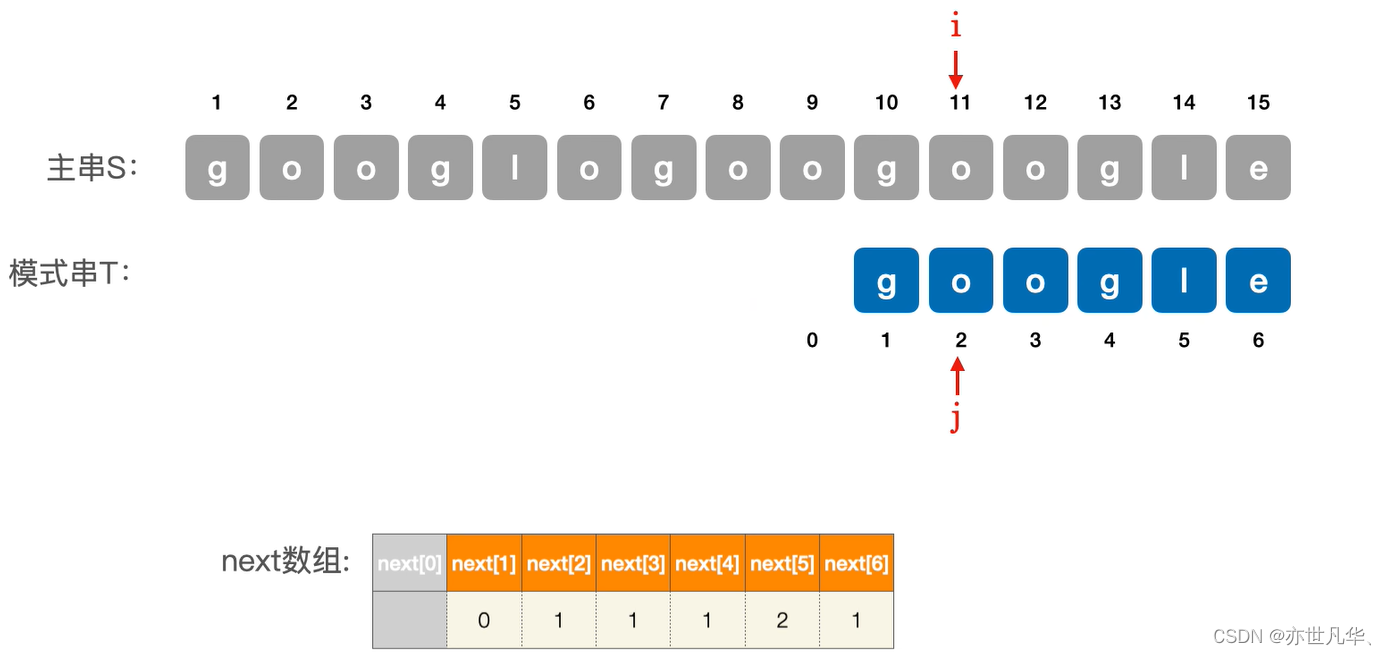
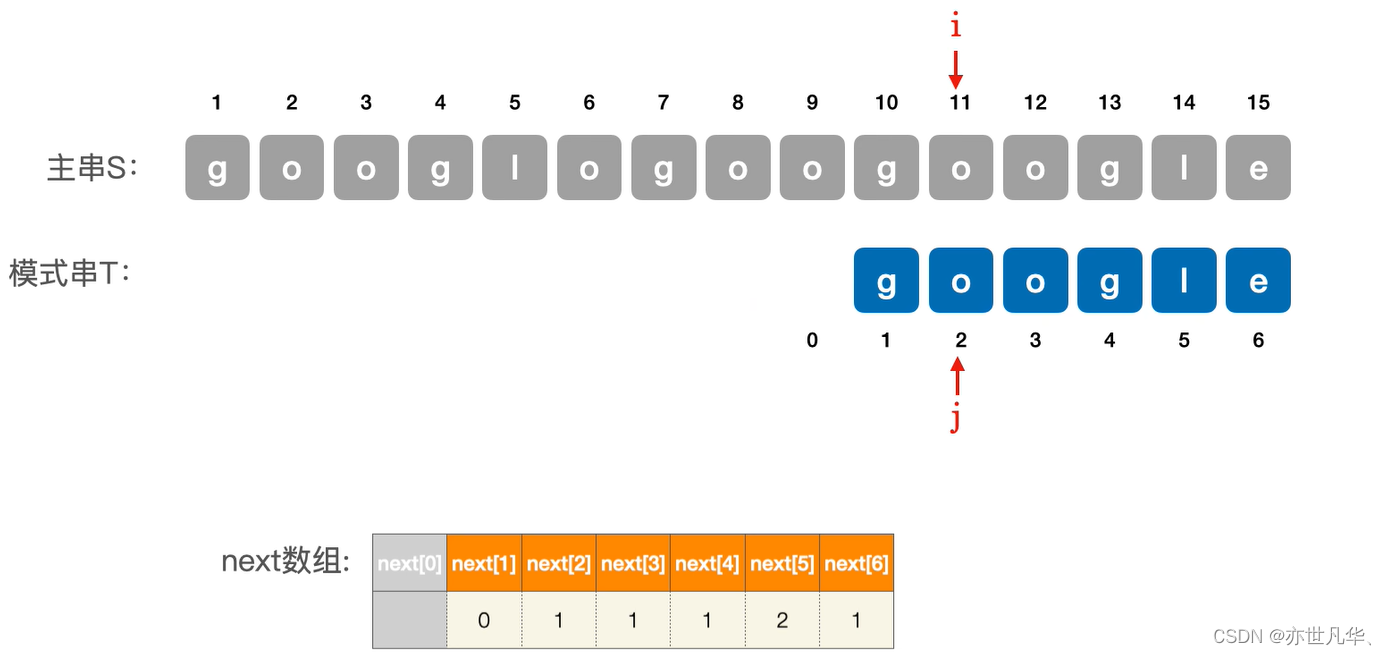
到此为止我们发现主串和模式串的所以字符都能匹配, 所以google的模式串就匹配成功了:
优化next数组后的nextval数组:在上文讲解的next数组是有地方可以进行优化的,这里不再讲解其原因,就直接告诉你如何在得知next数组相应值的情况下求出nextval数组:
nextval首位无脑写0
next[2]=1这里我们看到next数组序号2模式串b与序号1 a不等,即nextval[2]=next[2]=1
next[3]=1这里我们看到next数组序号3模式串a与序号1 a相等,即nextval[3]=next[1]=0
next[4]=2这里我们看到next数组序号4模式串b与序号2 b相等,即nextval[4]=next[2]=1
next[5]=3这里我们看到next数组序号5模式串a与序号3 a相等,即nextval[5]=next[3]=0
next[6]=4这里我们看到next数组序号6模式串a与序号4 b不等,即nextval[6]=next[6]=4

串的常见应用
串(String)是由零个或多个字符组成的有限序列,在数据结构中有着广泛的应用。下面是串在数据结构中常见的应用:
文本处理:串广泛应用于文本编辑、搜索和替换等操作。例如,可以使用串来表示、存储和处理文本文件、文章、代码等。
数据压缩:在数据压缩算法中,串有着重要的作用。常见的压缩算法如LZW、Huffman编码等利用了串的统计特性,对文本数据进行压缩和解压缩操作。
数据库系统:在数据库系统中,经常需要处理字符串类型的数据,如存储用户的姓名、地址、电话号码等信息。串的操作如匹配、比较、拼接等在数据库查询和数据处理中非常常见。
编译器和解释器:在编译器和解释器中,串被广泛用于表示源代码、词法分析、语法分析等。编译器通过对源代码进行分析和处理,将其转化为可执行的机器语言。
字符串匹配和搜索算法:串的匹配和搜索算法是串应用的核心领域之一。KMP算法、Boyer-Moore算法、正则表达式等算法都是基于串的匹配和搜索操作。
加密算法:在数据加密和安全领域,串常用于表示和处理密钥、密码、哈希值等信息。加密算法如AES、DES等对字符串进行加密和解密操作。
网络协议:在网络通信中,串被广泛应用于各种协议的数据传输中,如HTTP、SMTP等。通过串的拼接、分割等操作,实现了数据的可靠传输和通信。
这些只是串在数据结构中的一些常见应用领域,实际上串在计算机科学中的应用非常广泛,几乎涵盖了各个领域。