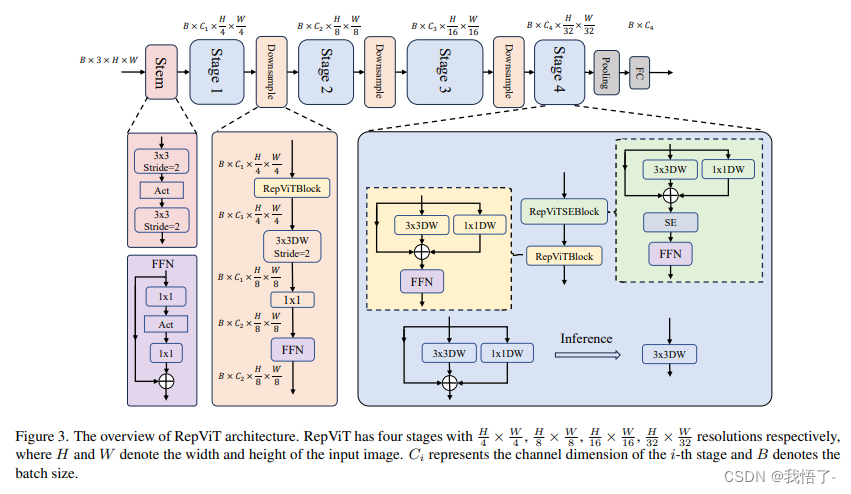
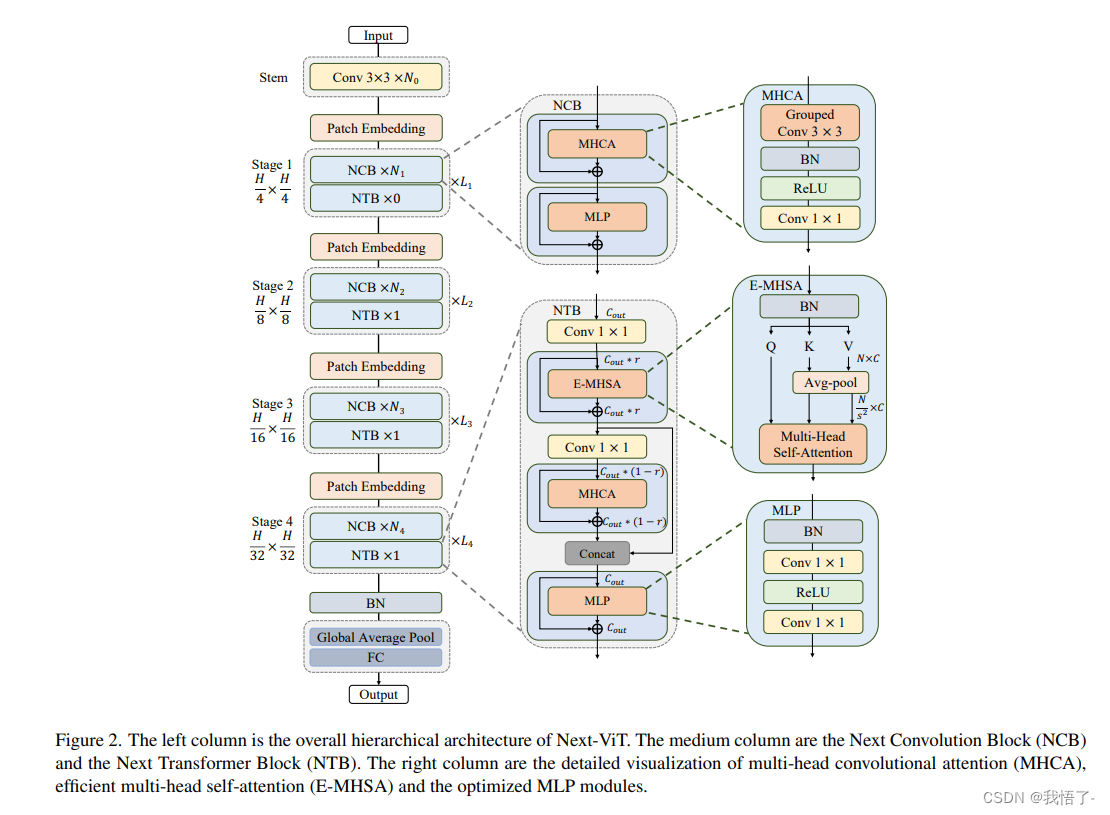
NextViT介绍
由于复杂的注意力机制和模型设计,大多数现有的视觉Transformer(ViTs)在现实的工业部署场景中不能像卷积神经网络(CNNs)那样高效地执行,例如TensorRT 和 CoreML。这带来了一个明显的挑战:视觉神经网络能否设计为与 CNN 一样快的推理和与 ViT 一样强大的性能?最近的工作试图设计 CNN-Transformer 混合架构来解决这个问题,但这些工作的整体性能远不能令人满意。
为了结束这些,我们提出了在现实工业场景中有效部署的下一代视觉Transformer,即 Next-ViT,从延迟/准确性权衡的角度来看,它在 CNN 和 ViT 中均占主导地位。
原文地址:Next-ViT: Next Generation Vision Transformer for Efficient Deployment in Realistic Industrial Scenarios
NextViT代码实现
# Copyright (c) ByteDance Inc. All rights reserved.
from functools import partial
import numpy as np
import torch
import torch.utils.checkpoint as checkpoint
from einops import rearrange
from timm.models.layers import DropPath, trunc_normal_
from torch import nn
__all__ = ['nextvit_small', 'nextvit_base', 'nextvit_large']
NORM_EPS = 1e-5
class ConvBNReLU(nn.Module):
def __init__(
self,
in_channels,
out_channels,
kernel_size,
stride,
groups=1):
super(ConvBNReLU, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride,
padding=1, groups=groups, bias=False)
self.norm = nn.BatchNorm2d(out_channels, eps=NORM_EPS)
self.act = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv(x)
x = self.norm(x)
x = self.act(x)
return x
def _make_divisible(v, divisor, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
class PatchEmbed(nn.Module):
def __init__(self,
in_channels,
out_channels,
stride=1):
super(PatchEmbed, self).__init__()
norm_layer = partial(nn.BatchNorm2d, eps=NORM_EPS)
if stride == 2:
self.avgpool = nn.AvgPool2d((2, 2), stride=2, ceil_mode=True, count_include_pad=False)
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, bias=False)
self.norm = norm_layer(out_channels)
elif in_channels != out_channels:
self.avgpool = nn.Identity()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, bias=False)
self.norm = norm_layer(out_channels)
else:
self.avgpool = nn.Identity()
self.conv = nn.Identity()
self.norm = nn.Identity()
def forward(self, x):
return self.norm(self.conv(self.avgpool(x)))
class MHCA(nn.Module):
"""
Multi-Head Convolutional Attention
"""
def __init__(self, out_channels, head_dim):
super(MHCA, self).__init__()
norm_layer = partial(nn.BatchNorm2d, eps=NORM_EPS)
self.group_conv3x3 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1,
padding=1, groups=out_channels // head_dim, bias=False)
self.norm = norm_layer(out_channels)
self.act = nn.ReLU(inplace=True)
self.projection = nn.Conv2d(out_channels, out_channels, kernel_size=1, bias=False)
def forward(self, x):
out = self.group_conv3x3(x)
out = self.norm(out)
out = self.act(out)
out = self.projection(out)
return out
class Mlp(nn.Module):
def __init__(self, in_features, out_features=None, mlp_ratio=None, drop=0., bias=True):
super().__init__()
out_features = out_features or in_features
hidden_dim = _make_divisible(in_features * mlp_ratio, 32)
self.conv1 = nn.Conv2d(in_features, hidden_dim, kernel_size=1, bias=bias)
self.act = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(hidden_dim, out_features, kernel_size=1, bias=bias)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.conv1(x)
x = self.act(x)
x = self.drop(x)
x = self.conv2(x)
x = self.drop(x)
return x
class NCB(nn.Module):
"""
Next Convolution Block
"""
def __init__(self, in_channels, out_channels, stride=1, path_dropout=0,
drop=0, head_dim=32, mlp_ratio=3):
super(NCB, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
norm_layer = partial(nn.BatchNorm2d, eps=NORM_EPS)
assert out_channels % head_dim == 0
self.patch_embed = PatchEmbed(in_channels, out_channels, stride)
self.mhca = MHCA(out_channels, head_dim)
self.attention_path_dropout = DropPath(path_dropout)
self.norm = norm_layer(out_channels)
self.mlp = Mlp(out_channels, mlp_ratio=mlp_ratio, drop=drop, bias=True)
self.mlp_path_dropout = DropPath(path_dropout)
self.is_bn_merged = False
def forward(self, x):
x = self.patch_embed(x)
x = x + self.attention_path_dropout(self.mhca(x))
if not torch.onnx.is_in_onnx_export() and not self.is_bn_merged:
out = self.norm(x)
else:
out = x
x = x + self.mlp_path_dropout(self.mlp(out))
return x
class E_MHSA(nn.Module):
"""
Efficient Multi-Head Self Attention
"""
def __init__(self, dim, out_dim=None, head_dim=32, qkv_bias=True, qk_scale=None,
attn_drop=0, proj_drop=0., sr_ratio=1):
super().__init__()
self.dim = dim
self.out_dim = out_dim if out_dim is not None else dim
self.num_heads = self.dim // head_dim
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, self.dim, bias=qkv_bias)
self.k = nn.Linear(dim, self.dim, bias=qkv_bias)
self.v = nn.Linear(dim, self.dim, bias=qkv_bias)
self.proj = nn.Linear(self.dim, self.out_dim)
self.attn_drop = nn.Dropout(attn_drop)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
self.N_ratio = sr_ratio ** 2
if sr_ratio > 1:
self.sr = nn.AvgPool1d(kernel_size=self.N_ratio, stride=self.N_ratio)
self.norm = nn.BatchNorm1d(dim, eps=NORM_EPS)
self.is_bn_merged = False
def forward(self, x):
B, N, C = x.shape
q = self.q(x)
q = q.reshape(B, N, self.num_heads, int(C // self.num_heads)).permute(0, 2, 1, 3)
if self.sr_ratio > 1:
x_ = x.transpose(1, 2)
x_ = self.sr(x_)
if not torch.onnx.is_in_onnx_export() and not self.is_bn_merged:
x_ = self.norm(x_)
x_ = x_.transpose(1, 2)
k = self.k(x_)
k = k.reshape(B, -1, self.num_heads, int(C // self.num_heads)).permute(0, 2, 3, 1)
v = self.v(x_)
v = v.reshape(B, -1, self.num_heads, int(C // self.num_heads)).permute(0, 2, 1, 3)
else:
k = self.k(x)
k = k.reshape(B, -1, self.num_heads, int(C // self.num_heads)).permute(0, 2, 3, 1)
v = self.v(x)
v = v.reshape(B, -1, self.num_heads, int(C // self.num_heads)).permute(0, 2, 1, 3)
attn = (q @ k) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class NTB(nn.Module):
"""
Next Transformer Block
"""
def __init__(
self, in_channels, out_channels, path_dropout, stride=1, sr_ratio=1,
mlp_ratio=2, head_dim=32, mix_block_ratio=0.75, attn_drop=0, drop=0,
):
super(NTB, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.mix_block_ratio = mix_block_ratio
norm_func = partial(nn.BatchNorm2d, eps=NORM_EPS)
self.mhsa_out_channels = _make_divisible(int(out_channels * mix_block_ratio), 32)
self.mhca_out_channels = out_channels - self.mhsa_out_channels
self.patch_embed = PatchEmbed(in_channels, self.mhsa_out_channels, stride)
self.norm1 = norm_func(self.mhsa_out_channels)
self.e_mhsa = E_MHSA(self.mhsa_out_channels, head_dim=head_dim, sr_ratio=sr_ratio,
attn_drop=attn_drop, proj_drop=drop)
self.mhsa_path_dropout = DropPath(path_dropout * mix_block_ratio)
self.projection = PatchEmbed(self.mhsa_out_channels, self.mhca_out_channels, stride=1)
self.mhca = MHCA(self.mhca_out_channels, head_dim=head_dim)
self.mhca_path_dropout = DropPath(path_dropout * (1 - mix_block_ratio))
self.norm2 = norm_func(out_channels)
self.mlp = Mlp(out_channels, mlp_ratio=mlp_ratio, drop=drop)
self.mlp_path_dropout = DropPath(path_dropout)
self.is_bn_merged = False
def forward(self, x):
x = self.patch_embed(x)
B, C, H, W = x.shape
if not torch.onnx.is_in_onnx_export() and not self.is_bn_merged:
out = self.norm1(x)
else:
out = x
out = rearrange(out, "b c h w -> b (h w) c") # b n c
out = self.mhsa_path_dropout(self.e_mhsa(out))
x = x + rearrange(out, "b (h w) c -> b c h w", h=H)
out = self.projection(x)
out = out + self.mhca_path_dropout(self.mhca(out))
x = torch.cat([x, out], dim=1)
if not torch.onnx.is_in_onnx_export() and not self.is_bn_merged:
out = self.norm2(x)
else:
out = x
x = x + self.mlp_path_dropout(self.mlp(out))
return x
class NextViT(nn.Module):
def __init__(self, stem_chs, depths, path_dropout, attn_drop=0, drop=0, num_classes=1000,
strides=[1, 2, 2, 2], sr_ratios=[8, 4, 2, 1], head_dim=32, mix_block_ratio=0.75,
use_checkpoint=False):
super(NextViT, self).__init__()
self.use_checkpoint = use_checkpoint
self.stage_out_channels = [[96] * (depths[0]),
[192] * (depths[1] - 1) + [256],
[384, 384, 384, 384, 512] * (depths[2] // 5),
[768] * (depths[3] - 1) + [1024]]
# Next Hybrid Strategy
self.stage_block_types = [[NCB] * depths[0],
[NCB] * (depths[1] - 1) + [NTB],
[NCB, NCB, NCB, NCB, NTB] * (depths[2] // 5),
[NCB] * (depths[3] - 1) + [NTB]]
self.stem = nn.Sequential(
ConvBNReLU(3, stem_chs[0], kernel_size=3, stride=2),
ConvBNReLU(stem_chs[0], stem_chs[1], kernel_size=3, stride=1),
ConvBNReLU(stem_chs[1], stem_chs[2], kernel_size=3, stride=1),
ConvBNReLU(stem_chs[2], stem_chs[2], kernel_size=3, stride=2),
)
input_channel = stem_chs[-1]
features = []
idx = 0
dpr = [x.item() for x in torch.linspace(0, path_dropout, sum(depths))] # stochastic depth decay rule
for stage_id in range(len(depths)):
numrepeat = depths[stage_id]
output_channels = self.stage_out_channels[stage_id]
block_types = self.stage_block_types[stage_id]
for block_id in range(numrepeat):
if strides[stage_id] == 2 and block_id == 0:
stride = 2
else:
stride = 1
output_channel = output_channels[block_id]
block_type = block_types[block_id]
if block_type is NCB:
layer = NCB(input_channel, output_channel, stride=stride, path_dropout=dpr[idx + block_id],
drop=drop, head_dim=head_dim)
features.append(layer)
elif block_type is NTB:
layer = NTB(input_channel, output_channel, path_dropout=dpr[idx + block_id], stride=stride,
sr_ratio=sr_ratios[stage_id], head_dim=head_dim, mix_block_ratio=mix_block_ratio,
attn_drop=attn_drop, drop=drop)
features.append(layer)
input_channel = output_channel
idx += numrepeat
self.features = nn.Sequential(*features)
self.norm = nn.BatchNorm2d(output_channel, eps=NORM_EPS)
self.stage_out_idx = [sum(depths[:idx + 1]) - 1 for idx in range(len(depths))]
self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]
self._initialize_weights()
def _initialize_weights(self):
for n, m in self.named_modules():
if isinstance(m, (nn.BatchNorm2d, nn.GroupNorm, nn.LayerNorm, nn.BatchNorm1d)):
nn.init.constant_(m.weight, 1.0)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if hasattr(m, 'bias') and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Conv2d):
trunc_normal_(m.weight, std=.02)
if hasattr(m, 'bias') and m.bias is not None:
nn.init.constant_(m.bias, 0)
def forward(self, x):
res = []
x = self.stem(x)
for idx, layer in enumerate(self.features):
if self.use_checkpoint:
x = checkpoint.checkpoint(layer, x)
else:
x = layer(x)
if idx in self.stage_out_idx:
res.append(x)
res[-1] = self.norm(res[-1])
return res
def update_weight(model_dict, weight_dict):
idx, temp_dict = 0, {}
for k, v in weight_dict.items():
if k in model_dict.keys() and np.shape(model_dict[k]) == np.shape(v):
temp_dict[k] = v
idx += 1
model_dict.update(temp_dict)
print(f'loading weights... {idx}/{len(model_dict)} items')
return model_dict
def nextvit_small(weights=''):
model = NextViT(stem_chs=[64, 32, 64], depths=[3, 4, 10, 3], path_dropout=0.1)
if weights:
pretrained_weight = torch.load(weights)['model']
model.load_state_dict(update_weight(model.state_dict(), pretrained_weight))
return model
def nextvit_base(weights=''):
model = NextViT(stem_chs=[64, 32, 64], depths=[3, 4, 20, 3], path_dropout=0.2)
if weights:
pretrained_weight = torch.load(weights)['model']
model.load_state_dict(update_weight(model.state_dict(), pretrained_weight))
return model
def nextvit_large(weights=''):
model = NextViT(stem_chs=[64, 32, 64], depths=[3, 4, 30, 3], path_dropout=0.2)
if weights:
pretrained_weight = torch.load(weights)['model']
model.load_state_dict(update_weight(model.state_dict(), pretrained_weight))
return model
Backbone替换
yolo.py修改
def parse_model函数
def parse_model(d, ch): # model_dict, input_channels(3)
# Parse a YOLOv5 model.yaml dictionary
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
anchors, nc, gd, gw, act = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple'], d.get('activation')
if act:
Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()
LOGGER.info(f"{colorstr('activation:')} {act}") # print
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
is_backbone = False
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
try:
t = m
m = eval(m) if isinstance(m, str) else m # eval strings
except:
pass
for j, a in enumerate(args):
with contextlib.suppress(NameError):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except:
args[j] = a
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in {
Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x}:
c1, c2 = ch[f], args[0]
if c2 != no: # if not output
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:
args.insert(2, n) # number of repeats
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
# TODO: channel, gw, gd
elif m in {Detect, Segment}:
args.append([ch[x] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
if m is Segment:
args[3] = make_divisible(args[3] * gw, 8)
elif m is Contract:
c2 = ch[f] * args[0] ** 2
elif m is Expand:
c2 = ch[f] // args[0] ** 2
elif isinstance(m, str):
t = m
m = timm.create_model(m, pretrained=args[0], features_only=True)
c2 = m.feature_info.channels()
elif m in {nextvit_small}: #可添加更多Backbone
m = m(*args)
c2 = m.channel
else:
c2 = ch[f]
if isinstance(c2, list):
is_backbone = True
m_ = m
m_.backbone = True
else:
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type, m_.np = i + 4 if is_backbone else i, f, t, np # attach index, 'from' index, type, number params
LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # print
save.extend(x % (i + 4 if is_backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
if isinstance(c2, list):
ch.extend(c2)
for _ in range(5 - len(ch)):
ch.insert(0, 0)
else:
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
def _forward_once函数
def _forward_once(self, x, profile=False, visualize=False):
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
if hasattr(m, 'backbone'):
x = m(x)
for _ in range(5 - len(x)):
x.insert(0, None)
for i_idx, i in enumerate(x):
if i_idx in self.save:
y.append(i)
else:
y.append(None)
x = x[-1]
else:
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
return x
创建.yaml配置文件
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# 0-P1/2
# 1-P2/4
# 2-P3/8
# 3-P4/16
# 4-P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, nextvit_small, [False]], # 4
[-1, 1, SPPF, [1024, 5]], # 5
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]], # 6
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 7
[[-1, 3], 1, Concat, [1]], # cat backbone P4 8
[-1, 3, C3, [512, False]], # 9
[-1, 1, Conv, [256, 1, 1]], # 10
[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 11
[[-1, 2], 1, Concat, [1]], # cat backbone P3 12
[-1, 3, C3, [256, False]], # 13 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]], # 14
[[-1, 10], 1, Concat, [1]], # cat head P4 15
[-1, 3, C3, [512, False]], # 16 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]], # 17
[[-1, 5], 1, Concat, [1]], # cat head P5 18
[-1, 3, C3, [1024, False]], # 19 (P5/32-large)
[[13, 16, 19], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]