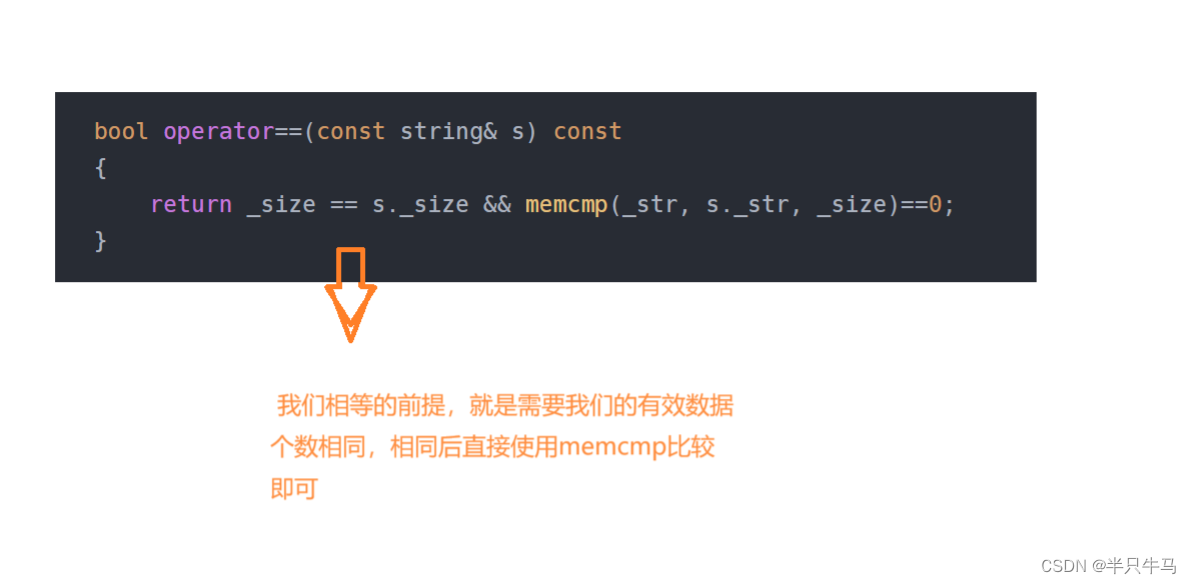
1.自编码器存在的局限性
自编码器的隐空间的规则性是一个难点,其取决于初始空间中数据的分布、隐空间的大小和编码器的结构。我们很难先验地确保编码器与生成过程兼容并智能地组织隐空间,因此可能导致隐空间的某些点将在解码时给出无意义的内容。注意:自编码器结构仅以尽可能少的损失为目标进行训练,缺无所谓隐空间的组织形式,因此网络会利用过拟合可能性来完成学习任务。为解决该问题,我们提出变分自编码器(VAE)
2.变分自编码器
为了解决自编码器上述的局限,我们必须对隐空间进行规范/正规化。因此提出变分自编码器,其训练经过正规化以避免过度拟合,并确保隐空间具有能够进行数据生成过程的良好属性。
同标准自编码器一样,变分自编码器也是一种由编码器和解码器组成的结构,经过训练以使编码解码后的数据与初始数据之间的重构误差最小。但修改了编码-解码过程:不是将输入编码为隐空间中的单个点,而是将其编码为隐空间中的概率分布
1.首先将将输入数据编码为在隐空间上的分布;
2. 然后从该分布中采样隐空间中的一个点;
3. 接着对采样点进行解码并计算出重建误差;
4. 最后重建误差通过网络反向传播
实践中,通常选择正态分布作为编码的分布,使得可以训练编码器来返回描述高斯分布的均值和协方差矩阵
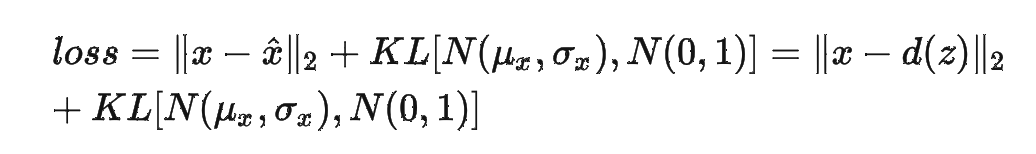
在训练VAE时最小化的损失函数由一个重构损失和一个正则化项(KL散度)组成,重构损失倾向于使编码解码方案尽可能高性能,而一个正则化项通过使编码器返回的分布接近标准正态分布,来规范隐空间的组织。
参考大佬博客:https://zhuanlan.zhihu.com/p/605724474