废话不多说,喊一句号子鼓励自己:程序员永不失业,程序员走向架构!本篇Blog的主题是【搜索算法】,使用【数组】这个基本的数据结构来实现,这个高频题的站点是:CodeTop,筛选条件为:目标公司+最近一年+出现频率排序,由高到低的去牛客TOP101去找,只有两个地方都出现过才做这道题(CodeTop本身汇聚了LeetCode的来源),确保刷的题都是高频要面试考的题。

明确目标题后,附上题目链接,后期可以依据解题思路反复快速练习,题目按照题干的基本数据结构分类,且每个分类的第一篇必定是对基础数据结构的介绍。
岛屿数量
来做这道传说中的岛屿数量,我们所熟悉的 **DFS(深度优先搜索)**问题通常是在树或者图结构上进行的。而我们今天要讨论的 DFS 问题,是在一种「网格」结构中进行的。岛屿问题是这类网格 DFS 问题的典型代表。网格结构遍历起来要比二叉树复杂一些,如果没有掌握一定的方法,DFS 代码容易写得冗长繁杂
题干

解题思路
首先明确下这一类题目该如何求解:
1 网格问题的基本概念
我们首先明确一下岛屿问题中的网格结构是如何定义的,以方便我们后面的讨论。网格问题是由 m×n个小方格组成一个网格,每个小方格与其上下左右四个方格认为是相邻的,要在这样的网格上进行某种搜索。
岛屿问题是一类典型的网格问题。每个格子中的数字可能是 0 或者 1。我们把数字为 0 的格子看成海洋格子,数字为 1 的格子看成陆地格子,这样相邻的陆地格子就连接成一个岛屿

在这样一个设定下,就出现了各种岛屿问题的变种,包括岛屿的数量、面积、周长等。不过这些问题,基本都可以用 DFS 遍历来解决
2 DFS 的基本结构
网格结构要比二叉树结构稍微复杂一些,它其实是一种简化版的图结构。要写好网格上的 DFS 遍历,我们首先要理解二叉树上的 DFS 遍历方法,再类比写出网格结构上的 DFS 遍历。我们写的二叉树 DFS 遍历一般是这样的:
void traverse(TreeNode root) {
// 判断 base case
if (root == null) {
return;
}
// 访问两个相邻结点:左子结点、右子结点
traverse(root.left);
traverse(root.right);
}
可以看到,二叉树的 DFS 有两个要素:「访问相邻结点」和「判断 base case」。
-
第一个要素是访问相邻结点。二叉树的相邻结点非常简单,只有左子结点和右子结点两个。二叉树本身就是一个递归定义的结构:一棵二叉树,它的左子树和右子树也是一棵二叉树。那么我们的 DFS 遍历只需要递归调用左子树和右子树即可。
-
第二个要素是 判断 base case。一般来说,二叉树遍历的 base case 是
root == null。这样一个条件判断其实有两个含义:一方面,这表示 root 指向的子树为空,不需要再往下遍历了。另一方面,在root == null的时候及时返回,可以让后面的root.left和root.right操作不会出现空指针异常。
对于网格上的 DFS,我们完全可以参考二叉树的 DFS,写出网格 DFS 的两个要素:
- 首先,网格结构中的格子有多少相邻结点?答案是上下左右四个。对于格子 (r, c) 来说(r 和 c 分别代表行坐标和列坐标),四个相邻的格子分别是 (r-1, c)、(r+1, c)、(r, c-1)、(r, c+1)。换句话说,网格结构是「四叉」的
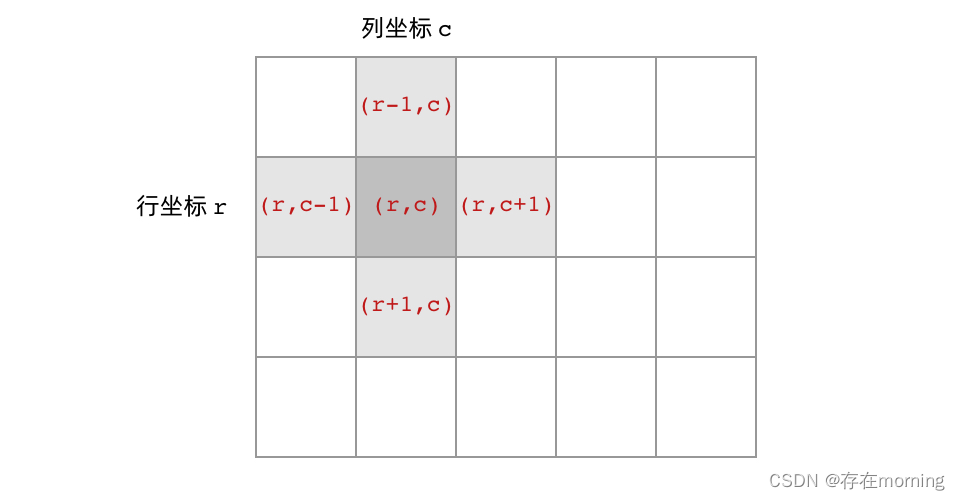
- 其次,网格 DFS 中的 base case 是什么?从二叉树的 base case 对应过来,应该是网格中不需要继续遍历、grid[r][c] 会出现数组下标越界异常的格子,也就是那些超出网格范围的格子

这一点稍微有些反直觉,坐标竟然可以临时超出网格的范围?这种方法我称为「先污染后治理」—— 甭管当前是在哪个格子,先往四个方向走一步再说,如果发现走出了网格范围再赶紧返回。这跟二叉树的遍历方法是一样的,先递归调用,发现 root == null 再返回。
这样,我们得到了网格 DFS 遍历的框架代码
void dfs(int[][] grid, int r, int c) {
// 判断 base case
// 如果坐标 (r, c) 超出了网格范围,直接返回
if (!inArea(grid, r, c)) {
return;
}
// 访问上、下、左、右四个相邻结点
dfs(grid, r - 1, c);
dfs(grid, r + 1, c);
dfs(grid, r, c - 1);
dfs(grid, r, c + 1);
}
// 判断坐标 (r, c) 是否在网格中
boolean inArea(int[][] grid, int r, int c) {
return 0 <= r && r < grid.length
&& 0 <= c && c < grid[0].length;
}
3 如何避免重复遍历
网格结构的 DFS 与二叉树的 DFS 最大的不同之处在于,遍历中可能遇到遍历过的结点。这是因为,网格结构本质上是一个「图」,我们可以把每个格子看成图中的结点,每个结点有向上下左右的四条边。在图中遍历时,自然可能遇到重复遍历结点

如何避免这样的重复遍历呢?答案是标记已经遍历过的格子。以岛屿问题为例,我们需要在所有值为 1 的陆地格子上做 DFS 遍历。每走过一个陆地格子,就把格子的值改为 2,这样当我们遇到 2 的时候,就知道这是遍历过的格子了。也就是说,每个格子可能取三个值:
- 0 —— 海洋格子
- 1 —— 陆地格子(未遍历过)
- 2 —— 陆地格子(已遍历过)
我们在框架代码中加入避免重复遍历的语句:
void dfs(int[][] grid, int r, int c) {
// 判断 base case
if (!inArea(grid, r, c)) {
return;
}
// 如果这个格子不是岛屿,直接返回
if (grid[r][c] != 1) {
return;
}
grid[r][c] = 2; // 将格子标记为「已遍历过」
// 访问上、下、左、右四个相邻结点
dfs(grid, r - 1, c);
dfs(grid, r + 1, c);
dfs(grid, r, c - 1);
dfs(grid, r, c + 1);
}
// 判断坐标 (r, c) 是否在网格中
boolean inArea(int[][] grid, int r, int c) {
return 0 <= r && r < grid.length
&& 0 <= c && c < grid[0].length;
}

代码实现
给出代码实现基本档案
基本数据结构:数组
辅助数据结构:无
算法:搜索算法
技巧:无
其中数据结构、算法和技巧分别来自:
- 10 个数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie 树
- 10 个算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法
- 技巧:双指针、滑动窗口、中心扩散
当然包括但不限于以上
import java.util.*;
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
* 判断岛屿数量
* @param grid char字符型二维数组
* @return int整型
*/
public int solve (char[][] grid) {
// 记录岛屿数量
int count = 0;
for (int r = 0; r < grid.length; r++) {
for (int c = 0; c < grid[0].length; c++) {
// 找到岛屿入口
if (grid[r][c] == '1') {
// 记录岛屿数量
count++;
// 发现并设置出完整岛屿轮廓
dfsFind(grid, r, c);
}
}
}
return count;
}
private void dfsFind(char[][] grid, int r, int c) {
// 遍历到边界则返回
if (!isInArea(grid, r, c)) {
return;
}
// 遍历到非陆地的地方直接返回【海洋以及已探索陆地】
if (grid[r][c] != '1') {
return;
}
// 遍历过的陆地设置为2,防止重复计数
grid[r][c] = '2';
dfsFind(grid, r, c + 1);
dfsFind(grid, r, c - 1);
dfsFind(grid, r + 1, c);
dfsFind(grid, r - 1, c);
}
private boolean isInArea(char[][] grid, int r, int c) {
// 判断当前坐标是否仍然在岛屿范围内
return r >= 0 && r < grid.length && c >= 0 && c < grid[0].length;
}
}
复杂度分析
计算岛屿数量的问题通常通过深度优先搜索(DFS)或广度优先搜索(BFS)来解决。以下是使用深度优先搜索(DFS)算法来计算岛屿数量的时间和空间复杂度分析:
时间复杂度: 在最坏情况下,DFS需要访问矩阵中的每个格子一次,因此时间复杂度为O(M*N),其中M是矩阵的行数,N是矩阵的列数。
空间复杂度: 空间复杂度取决于递归调用的深度。在最坏情况下,如果整个矩阵都是陆地,DFS的递归深度可能达到MN,因此空间复杂度为O(MN)。通常,DFS的空间复杂度还包括了用于存储访问标记的数据结构(如一个额外的矩阵或集合),因此实际的空间复杂度可能稍微高一些。
需要注意的是,如果使用迭代而不是递归来实现DFS,可以通过使用栈来降低空间复杂度,但时间复杂度仍然是O(M*N)。
总之,岛屿数量问题的时间复杂度是O(MN),空间复杂度通常为O(MN),但在一些优化的情况下可以降低到O(min(M, N))。这取决于具体的实现方式和问题的输入。
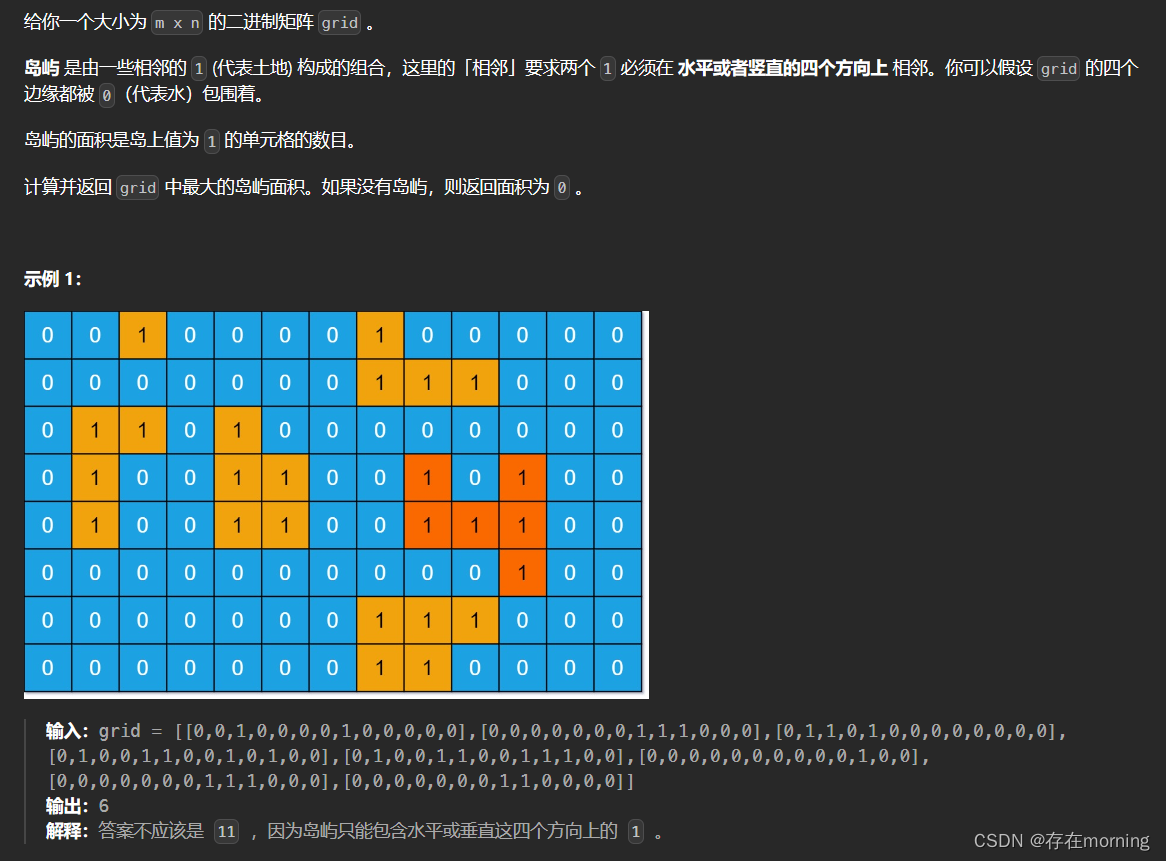
岛屿的最大面积【MID】
接着岛屿数量的题,继续做与之相关的岛屿最大面积的计算
题干
解题思路
这道题目只需要对每个岛屿做 DFS 遍历,求出每个岛屿的面积就可以了。求岛屿面积的方法也很简单,代码如下,每遍历到一个格子,就把面积加一
int area(int[][] grid, int r, int c) {
return 1
+ area(grid, r - 1, c)
+ area(grid, r + 1, c)
+ area(grid, r, c - 1)
+ area(grid, r, c + 1);
}
代码实现
给出代码实现基本档案
基本数据结构:数组
辅助数据结构:无
算法:搜索算法
技巧:无
其中数据结构、算法和技巧分别来自:
- 10 个数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie 树
- 10 个算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法
- 技巧:双指针、滑动窗口、中心扩散
当然包括但不限于以上
class Solution {
public int maxAreaOfIsland(int[][] grid) {
int maxArea = 0;
for (int r = 0; r < grid.length; r++) {
for (int c = 0; c < grid[0].length; c++) {
// 找到岛屿入口
if (grid[r][c] == 1) {
// 发现并设置出完整岛屿轮廓
int area = area(grid, r, c);
// 比较并设置最大面积
maxArea = Math.max(maxArea, area);
}
}
}
return maxArea;
}
private int area(int[][] grid, int r, int c) {
// 遍历到边界则返回0
if (!isInArea(grid, r, c)) {
return 0;
}
// 遍历到非陆地的地方直接返回0【海洋以及已探索陆地】
if (grid[r][c] != 1) {
return 0;
}
// 遍历过的陆地设置为2,防止重复计数
grid[r][c] = 2;
// 每发现一格岛屿,面积就加1
return 1 + area(grid, r, c + 1) + area(grid, r, c - 1) + area(grid,
r + 1, c) + area(grid, r - 1, c);
}
private boolean isInArea(int[][] grid, int r, int c) {
// 判断当前坐标是否仍然在岛屿范围内
return r >= 0 && r < grid.length && c >= 0 && c < grid[0].length;
}
}
复杂度分析
计算岛屿的最大面积通常也使用深度优先搜索(DFS)或广度优先搜索(BFS)来解决。以下是使用DFS算法来计算岛屿最大面积的时间和空间复杂度分析:
时间复杂度: 在最坏情况下,DFS需要访问矩阵中的每个格子一次,因此时间复杂度仍然是O(MN),其中M是矩阵的行数,N是矩阵的列数。每次访问一个岛屿格子时,需要递归地访问与之相邻的陆地格子,但总体的时间复杂度仍然是O(MN)。
空间复杂度: 空间复杂度取决于递归调用的深度。在最坏情况下,如果整个矩阵都是陆地,DFS的递归深度可能达到MN,因此空间复杂度为O(MN)。通常,DFS的空间复杂度还包括了用于存储访问标记的数据结构(如一个额外的矩阵或集合),因此实际的空间复杂度可能稍微高一些。
与计算岛屿数量类似,如果使用迭代而不是递归来实现DFS,可以通过使用栈来降低空间复杂度,但时间复杂度仍然是O(M*N)。
总结一下,计算岛屿的最大面积问题的时间复杂度是O(MN),空间复杂度通常为O(MN),但在一些优化的情况下可以降低到O(min(M, N))。这仍然取决于具体的实现方式和问题的输入。
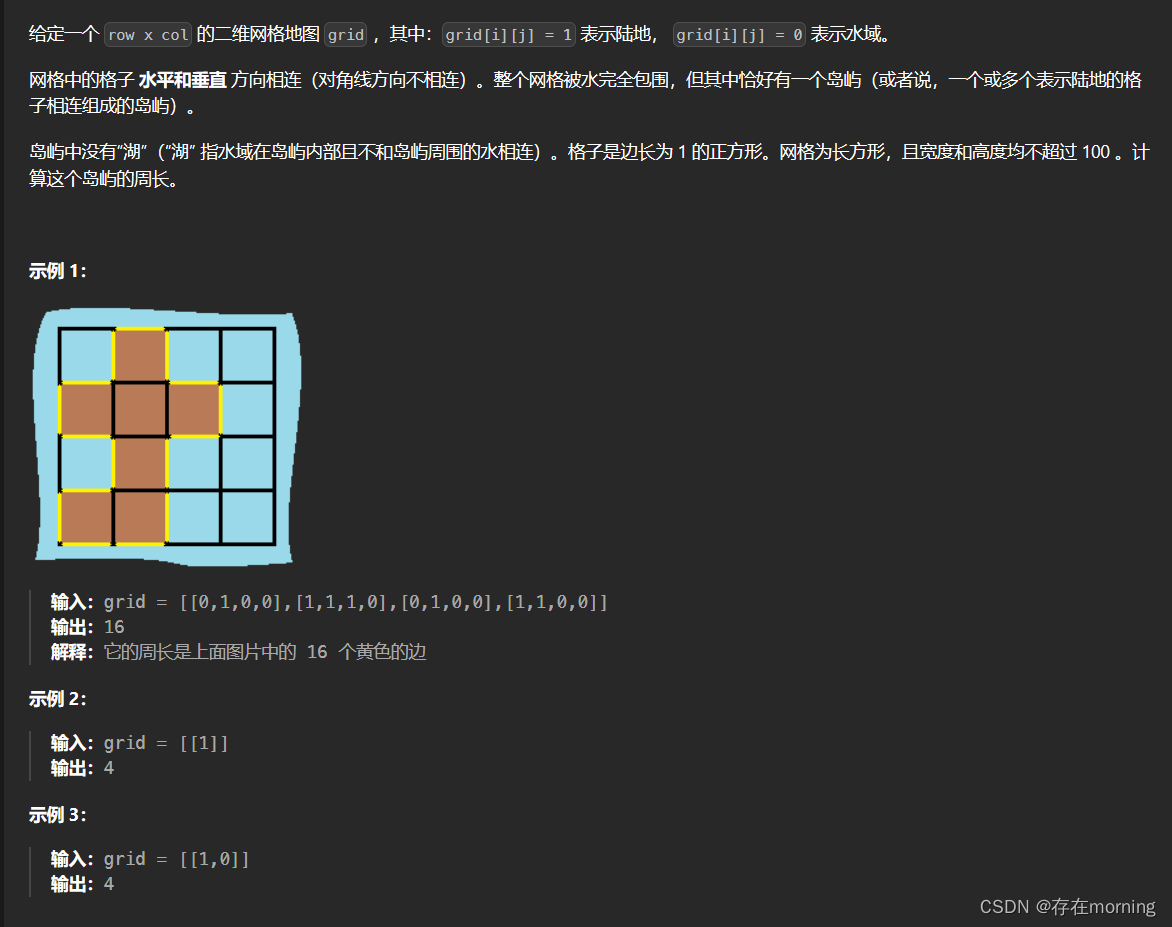
岛屿的周长
继续用DFS网络搜索框架解这道题
题干
解题思路
岛屿的周长是计算岛屿全部的「边缘」,而这些边缘就是我们在 DFS 遍历中,dfs 函数返回的位置。观察题目示例,我们可以将岛屿的周长中的边分为两类,如下图所示。黄色的边是与网格边界相邻的周长,而蓝色的边是与海洋格子相邻的周长。
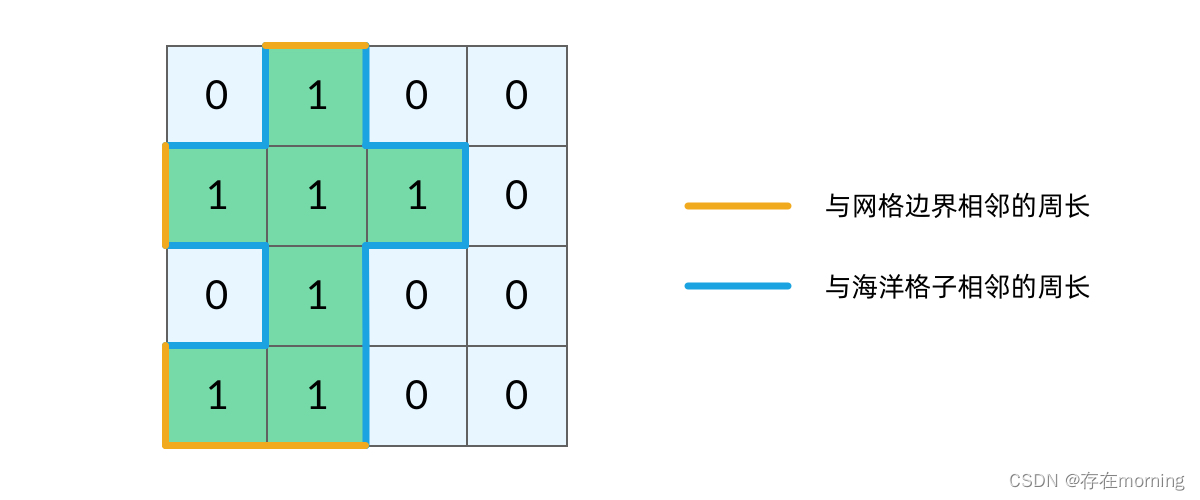
当我们的 dfs 函数因为「坐标 (r, c) 超出网格范围」返回的时候,实际上就经过了一条黄色的边;而当函数因为「当前格子是海洋格子」返回的时候,实际上就经过了一条蓝色的边。这样,我们就把岛屿的周长跟 DFS 遍历联系起来了
代码实现
给出代码实现基本档案
基本数据结构:数组
辅助数据结构:无
算法:搜索算法
技巧:无
其中数据结构、算法和技巧分别来自:
- 10 个数据结构:数组、链表、栈、队列、散列表、二叉树、堆、跳表、图、Trie 树
- 10 个算法:递归、排序、二分查找、搜索、哈希算法、贪心算法、分治算法、回溯算法、动态规划、字符串匹配算法
- 技巧:双指针、滑动窗口、中心扩散
当然包括但不限于以上
class Solution {
public int islandPerimeter(int[][] grid) {
int perimeter = 0;
for (int r = 0; r < grid.length; r++) {
for (int c = 0; c < grid[0].length; c++) {
if (grid[r][c] == 1) {
perimeter = dfsLength(grid, r, c);
}
}
}
return perimeter;
}
private int dfsLength(int[][] grid, int r, int c) {
// 1 函数因为「坐标 (r, c) 超出网格范围」返回,对应一条黄色的边
if (!isInArea(grid, r, c)) {
return 1;
}
// 2 分开讨论非陆地【海洋以及已探索陆地】
// 2-1 函数因为「当前格子是海洋格子」返回,对应一条蓝色的边
if (grid[r][c] == 0) {
return 1;
}
// 2-2 函数因为「当前格子是已遍历的陆地格子」返回,和周长没关系
if (grid[r][c] ==2 ) {
return 0;
}
grid[r][c] = 2;
// 继续向四面拓展
return dfsLength(grid, r, c + 1) + dfsLength(grid, r, c - 1) + dfsLength(grid,
r + 1, c) + dfsLength(grid, r - 1, c);
}
private boolean isInArea(int[][] grid, int r, int c) {
return r >= 0 && r < grid.length && c >= 0 && c < grid[0].length;
}
}
复杂度分析
计算岛屿的周长通常可以在深度优先搜索(DFS)或广度优先搜索(BFS)的基础上实现。以下是使用DFS算法来计算岛屿周长的时间和空间复杂度分析:
时间复杂度: 在最坏情况下,DFS需要访问矩阵中的每个岛屿格子一次,因此时间复杂度为O(M*N),其中M是矩阵的行数,N是矩阵的列数。对于每个岛屿格子,DFS会探索与之相邻的四个方向,所以在最坏情况下,访问一个岛屿格子的操作的时间复杂度是O(1)。
空间复杂度: 空间复杂度取决于递归调用的深度。在最坏情况下,如果整个矩阵都是陆地,DFS的递归深度可能达到MN,因此空间复杂度为O(MN)。通常,DFS的空间复杂度还包括了用于存储访问标记的数据结构(如一个额外的矩阵或集合),因此实际的空间复杂度可能稍微高一些。
与计算岛屿数量和最大面积不同,计算岛屿周长问题的时间复杂度是O(M*N),因为它只涉及到对每个岛屿格子的一次访问和检查。
需要注意的是,虽然DFS是一种递归算法,但在实际应用中,可以考虑使用迭代的方式来实现,以避免潜在的栈溢出问题。此时,空间复杂度会有所降低。
总结一下,计算岛屿周长问题的时间复杂度是O(MN),空间复杂度通常为O(MN),但在一些优化的情况下可以降低到O(min(M, N))。这取决于具体的实现方式和问题的输入。
拓展知识:DFS在网格中的应用
深度优先搜索(Depth-First Search,DFS)是一种用于图遍历和搜索的算法,它可以应用于各种问题,包括在网格中的问题。在网格中,DFS通常用于解决以下类型的问题:
-
迷宫求解:DFS可用于寻找从一个起始点到达目标点的路径。在一个网格迷宫中,你可以使用DFS来探索不同的路径,直到找到通向目标的路径或者确定没有可行的路径。
-
岛屿计数:给定一个由陆地和水组成的网格,DFS可以用于计算陆地区域的数量。通过从一个陆地格子开始,DFS可以递归地标记与之相连的所有陆地格子,从而统计出岛屿的数量。
-
联通分量计算:DFS还可用于计算一个网格中的连通分量数量。连通分量是指由相互连接的格子组成的区域。DFS可以用于标记和计数这些连通分量。
-
单词搜索游戏:在字母矩阵中查找给定单词的存在是另一个DFS的应用。DFS可用于从一个字母格子出发,尝试构建单词并逐步扩展搜索路径,直到找到单词或确定不存在。
-
图像填充:DFS可以用于图像处理,例如在图像上进行填充操作。你可以从一个起始像素开始,使用DFS来填充相邻像素,直到达到某个条件为止。
在DFS的应用中,关键是选择适当的起始点,并设计好递归函数或迭代算法,以便在网格中进行深度优先搜索。DFS通常需要使用一个数据结构来记录已经访问过的格子,以防止重复访问,通常可以使用一个集合(集合或哈希表)来实现这个目的。
需要注意的是,DFS是一种递归算法,可能会导致栈溢出问题,因此在实际应用中,可能需要考虑使用迭代的方式来实现DFS,或者使用递归的时候设置递归深度限制,以避免潜在的问题。