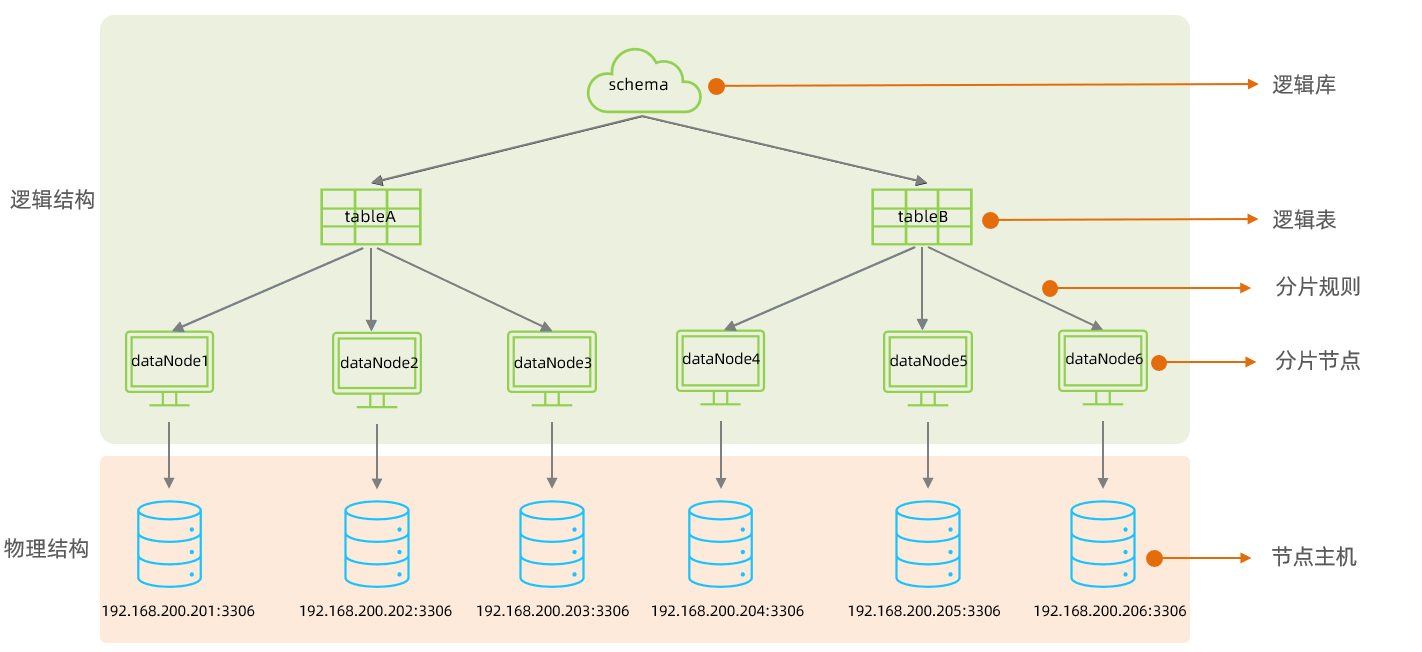
除了创建整型数组一样,也可以声明指针数组。
int *api[10];
为了弄清这个复杂的声明,我们假定它是一个表达式,并对它进行求值。下标引用的优先级高于间接访问,所以在这个表达式中,首先执行下标引用。因此,api是某种类型的数组(它包含的元素个数为10)。在取得一个数组元素之后,随即执行的是间接访问操作。这个表达式不再有其他操作符,所以它的结果是一个整型值。
那么api到底是什么东西?对数组的某个元素执行间接访问操作后,我们得到一个整型值,所以api肯定是个数组,它的元素类型是指向整型的指针。
举一个使用指针数组的例子:
char const *keyword[]={
"do",
"for",
"if",
"register",
"return",
"switch",
"while"
};
#define N_KEYWORD \
(sizeof(keyword)/sizeof(keyword[0]))
注意sizeof的用途,它用于对数组中的元素进行自动计数。sizeof(keyword)的结果是整个数组所占用的字节数,而sizeof(keyword[0])的结果则是数组每个元素所占用的字节数。这两个值相除,结果就是数组元素的个数。
这个数组可以用于一个计算C源文件中关键字个数的程序中。输入的每个单词将与列表中的字符串进行比较,所有的匹配都将被计数。程序8.2遍历整个关键字列表,查找是否存在与参数字符串相同的匹配。当它找到一个匹配时,函数就返回这个匹配在列表中的偏移量。调用程序必须
知道0代表do,1代表for等,此外它还必须知道返回值如果是-1表示没有关键字匹配。这个信息很可能是通过头文件所定义的符号获得的。
keyword.c关键字查找
/*
** 判断参数是否与一个关键字列表中的任何单词匹配,并返回匹配的索引值。如果未** 找到匹配,函数返回-1。
*/
#include <string.h>
int
lookup_keyword( char const * const desired_word,
char const *keyword_table[], int const size )
{
char const **kwp;
/*
** 对于表中的每个单词 ...
*/
for( kwp = keyword_table; kwp < keyword_table + size; kwp++ )
/*
** 如果这个单词与我们所查找的单词匹配,返回它在表中的位置。
*/
if( strcmp( desired_word, *kwp ) == 0 )
return kwp - keyword_table;
/*
** 没有找到。
*/
return -1;
}
书里没有把怎么使用的代码给出来,这里测试了一下,在这里写出:
#include <string.h>
#include <stdio.h>
char const *keyword[] = {
"do",
"for",
"if",
"register",
"return",
"switch",
"while"};
#define N_KEYWORD \
(sizeof(keyword) / sizeof(keyword[0]))
int lookup_keyword(char const *const desired_word,
char const *keyword_table[], int const size)
{
char const **kwp;
/*
** 对于表中的每个单词 ...
*/
for (kwp = keyword_table; kwp < keyword_table + size; kwp++)
/*
** 如果这个单词与我们所查找的单词匹配,返回它在表中的位置。
*/
if (strcmp(desired_word, *kwp) == 0)
return kwp - keyword_table;
/*
** 没有找到。
*/
return -1;
}
int main()
{
int a = lookup_keyword("while", keyword, N_KEYWORD );
printf("%d", a);
}
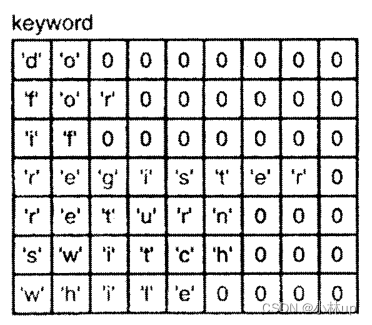
也可以把关键字存储在一个矩阵中,如下所示:
char const keyword[][9] = {
"do",
"for"
"if",
"register",
"return",
"switch",
"while"
};
这个声明和前面那个声明的区别在什么地方呢?第2个声明创建了一个矩阵,它每一行的长度刚好可以容纳最长的关键字(包括作为终止符的NUL字节)。这个矩阵的样子如下所示:
第1个声明创建了一个指针数组,每个指针元素都初始化为指向各个不同的字符串常量,如下所示:
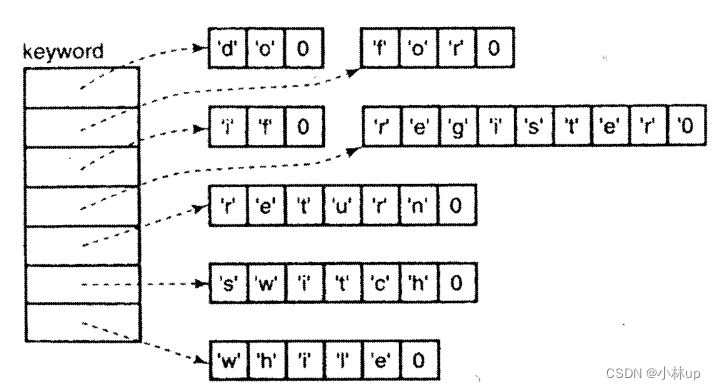
注意这两种方法在占用内存空间方面的区别。矩阵看上去效率低一些,因为它的每一行的长度都被固定为刚好能容纳最长的关键字。但是,它不需要任何指针。另一方面,指针数组本身也要占用空间,但是每个字符串常量占据的内存空间只是它本身的长度。
如果我们需要对之前的程序进行修改,改用矩阵代替指针数组,我们应该怎么做呢?答案可能会令你吃惊,我们只需要对列表形参和局部变量的声明进行修改就可以了,具体的代码无需变动。由于数组名的值是一个指针,所以无论传递给函数的是指针还是数组名,函数都能运行。书里忽略了具体的代码,这里写一下:
#include <string.h>
#include <stdio.h>
char const keyword[][9] = {
"do",
"for",
"if",
"register",
"return",
"switch",
"while"};
int lookup_keyword(char const *const desired_word,
char const (*keyword_table)[9], int const size)//列表第二个形参发生改变
{
char const(*kwp)[9];//这里发生了改变
/*
** 对于表中的每个单词 ...
*/
for (kwp = keyword_table; kwp < keyword_table + size; kwp++)
/*
** 如果这个单词与我们所查找的单词匹配,返回它在表中的位置。
*/
if (strcmp(desired_word, *kwp) == 0)
return kwp - keyword_table;
/*
** 没有找到。
*/
return -1;
}
int main()
{
int a = lookup_keyword("while", keyword, 7);//size等于7总共是7行
printf("%d", a);
}
实际上,除了非常巨大的表,这些差别非常之小,所以根本不重要。人们时常选择指针数组方案,但略微对其作些改变:
char const *keyword[] = {
"do",
"for",
"if",
"register",
"return",
"switch",
"while",
NULL
};
这里,我们在表的末尾增加了一个NULL指针。这个NULL指针使函数在搜索这个表时能够检测到表的结束,而无需预先知道表的长度,如下所示:
for( kwp = keyword_table; *kwp != NULL; kwp++ )
参考
- 《C和指针》


![[React源码解析] React的设计理念和源码架构 (一)](https://img-blog.csdnimg.cn/75242141fe5646f2a123486823875d6a.png)