文章目录
- 数据存储格式
- 1 行列存储比较
- 2 ORC文件格式
- 2.1 文件级
- 2.1.1 Post scripts
- 2.1.2 File Footer
- 2.1.3 File MetaData
- 2.2 Stripe级
- 2.2.1 Stripe Footer
- 2.2.2 Row Data
- 2.2.3 Index Data
- 3 Parquet文件格式
- 3.1 Header
- 3.2 Data
- 3.2.1 Row Group
- 3.2.2 Column Chunk
- 3.2.3 Page
- 3.3 Footer
- 3.3.1 Index
- 3.3.2 MetaData
- 4 ORC和Parquet对比
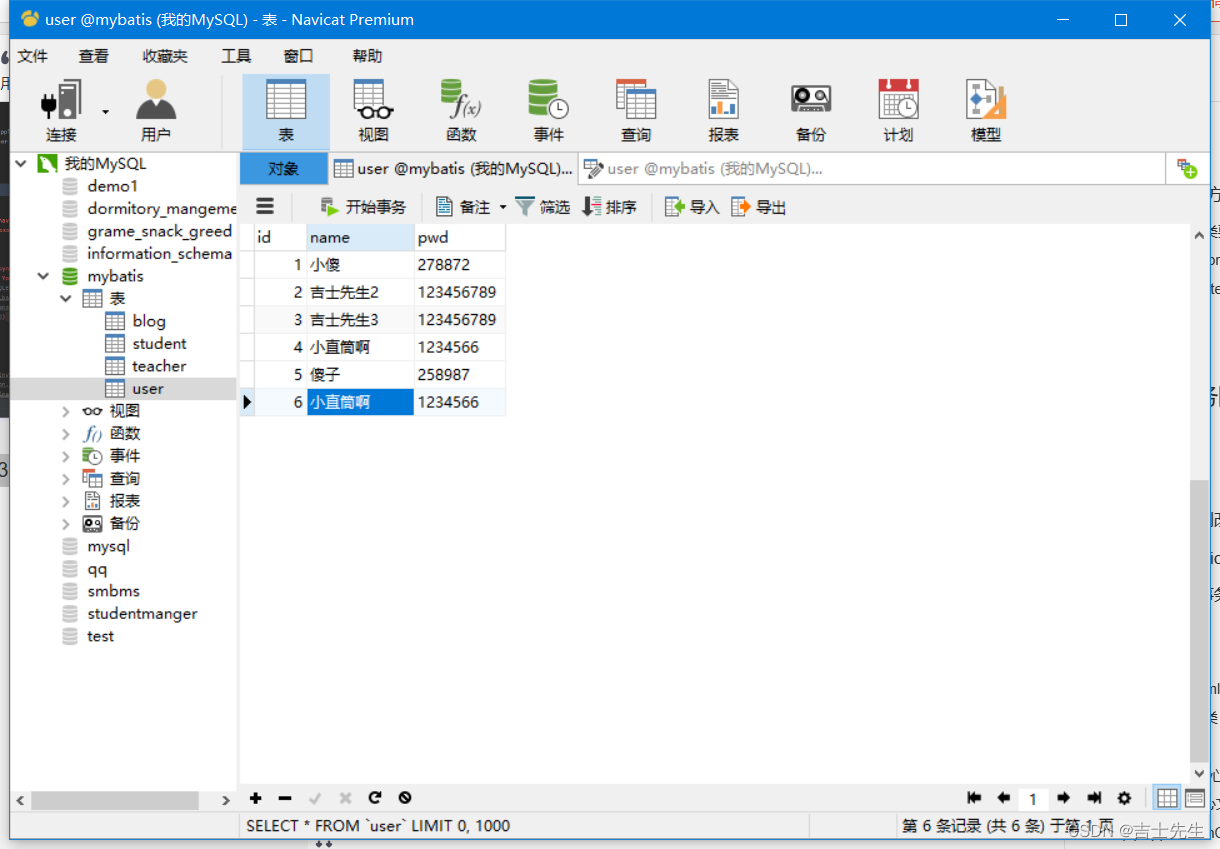
数据存储格式
1 行列存储比较
数仓实际开发中常用的数据存储格式主要分为3类,TextFile、ParquetFile、ORCFile。其中TextFIle为行式存储,Parquet和ORC都是列式存储,这里先说一下行式存储和列式存储区别。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OAMpqcKq-1671615081745)(/Users/jinlong/data/Typora_WorkSpase/存储格式01.png)]](https://img-blog.csdnimg.cn/9bf6fe30280e4c3abcc4df967f1cfbe8.png)
如上图所示,行式存储在查询的数据的时候是整行的扫描,不管查询的数据是否只是其中的几列都会把整行的数据进行扫描。而列式存储在查询数据的时候只会扫描所查询的列。这样比较列式存储的查询效率相对于行式存储的查询效率是要高出很多的。
| 行存储 | 列存储 | |
|---|---|---|
| 查询 | 查询时整行扫描,效率较低 | 查询时只扫描需要查询的列,效率较高 |
| 存储 | 不利于压缩,压缩比较差,占用空间多 | 列式存储的时候可以为每一列创建一个字典,存储的时候就仅存储数字编码即可,降低了存储空间需求 |
| 写入 | 每行包含所有字段,插入和修改效率较高 | 每列数据单独存储,插入和修改效率较低 |
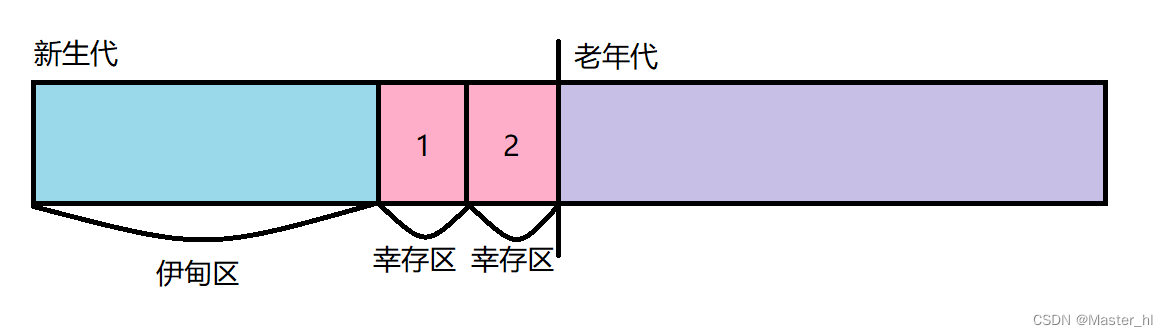
2 ORC文件格式
ORC文件的总体结构如下图

结构说明
| 主体 | 说明 |
|---|---|
| Stripe | 是ORC文件存储数据的地方,默认250M。 |
| Index Data | 轻量级的index,默认是每10000行数据做一个索引。索引记录的是字段在’Row Data’中的offset(偏移量),并且还记录了每个字段的最大值和最小值,如感兴趣可查看源码。 |
| Row Data | 就是存储具体数据的地方,存储方式是先取部分行,再将部分行中的数据按列存储,每列还可能分为多个Stream。 |
| Stripe Footer | 存储各个Stream的类型长度等信息。 |
| File Footer | 存储每个Stripe的行数、每个Column的数据类型、每列的最值和聚合信息等内容。 |
| Postscript | 记录了整个文件的压缩类型、文件版本、File Footer的长度相关信息。 |
ORC格式的文件对数据的查询和索引分为3个层次:文件级、Stripe级、Row Group级。也就是说在扫描数据的时候只会扫描到这个文件的某个Stripe下的部分Row Group,这样就大大减少了需要读取的数据量。读取步骤如下图:

2.1 文件级
ORC文件首先是通过file tail来记录文件级别的元数据信息,这样有利于在SQL查询时更快的跳过没必要查询的文件。file tail主要由postscripts、file footer、file metastore自下而上组成,这三部分都是使用Protocol Buffer存储(提供添加字段不需要改写reader的能力),如下图所示:

2.1.1 Post scripts
上面有提到Post scripts存储了File Footer、File MetaData长度信息、文件版本信息、文件压缩类型信息。这里再对Post scripts做一个详细说明,Post scripts部分永远不会被压缩并且在文件末尾前一个字节结束(也就是说整个File tail的长度=FooterSize + MetaDataSize + PostscriptsSize + 1byte)。ORC文件的读取过程是从底部向上读取,通常ORC Reader会直接读取文件的最后16KB,这部分同时包含了Footer和Postscripts。文件的最后一个字节包含了Post scripts的序列化长度,该长度必须小于256byte。当Post script被解析后,Footer的压缩序列化长度就可以获得,从而就可以被解压缩和解析。

代码信息如下:
message PostScript {
// Footer长度
optional uint64 footerLength = 1;
// 压缩类型
optional CompressionKind compression = 2;
// 压缩块大小
optional uint64 compressionBlockSize = 3;
// writer的版本信息
repeated uint32 version = 4 [packed = true];
// 文件元数据长度
optional uint64 metadataLength = 5;
// 魔数,为了确定此结构式符合规范的ORC文件
optional string magic = 8000;
}
enum CompressionKind {
NONE = 0;
ZLIB = 1;
SNAPPY = 2;
LZO = 3;
LZ4 = 4;
ZSTD = 5;
}
2.1.2 File Footer
File footer部分包含了文件主体的布局,类型schema信息、行数、每列的统计信息。从‘ORC File’的整体结构图中可以看出ORC文件整体主要分为三大部分Header、Body、Tail,Header部分由’ORC’组成、Body包含索引和行、Tail则是文件信息,File Footer就包含这三部分的元信息。
代码信息如下:
message Footer {
// Header长度,始终为3
optional uint64 headerLength = 3;
// 文件头和正文长度
optional uint64 contentLength = 2;
// Stripes的数量
repeated StripeInformation stripes = 3;
// 结构类型信息
repeated Type types = 4;
// 用户元数据信息
repeated UserMetadataItem metadata = 5;
// 行数
optional uint64 numberOfRows = 6;
// 文件中每列的统计信息
repeated ColumnStatistics statistics = 7;
// 索引项中的最大行数
optional uint32 rowIndexStride = 8;
// Each implementation that writes ORC files should register for a code
// 0 = ORC Java
// 1 = ORC C++
// 2 = Presto
// 3 = Scritchley Go from https://github.com/scritchley/orc
// 4 = Trino
optional uint32 writer = 9;
2.1.3 File MetaData
File MetaData主要记录的Stripe级别的统计信息,上面File Footer中的ColumnStatistics是文件级别的信息。这些统计信息可以通过谓词下推跳过部分Stripe的读取。代码信息如下:
message StripeStatistics {
repeated ColumnStatistics colStats = 1;
}
message Metadata {
repeated StripeStatistics stripeStats = 1;
}
2.2 Stripe级
ORC文件的主体就是由一系列的Stripe组成的,通常每个Stripe的大小约为250M且彼此独立。ORC文件中每列都是由多个Steam组成的,这些Steam彼此相邻,通过文章最开始的图是可以看到的。
对于二进制数ORC使用三个Steam:Present、Data、Length,它们存储每个值的长度。每个Stripe都是由Stripe Footer、Row Data、Index Data组成,如下图;

2.2.1 Stripe Footer
Stripe Footer包含了每列的编码信息、Stream的元信息(如位置等),代码信息如下:
message StripeFooter {
// Stream的位置信息
repeated Stream streams = 1;
// 字段编码信息
repeated ColumnEncoding columns = 2;
optional string writerTimezone = 3;
// 字段加密信息
repeated StripeEncryptionVariant encryption = 4;
}
2.2.2 Row Data
Row Data存储了真正的数据内容,这也是ORC文件核心所在。一个文件分为多个Stripe,每个Stripe负责一个或多个Row Group(每个Row Group默认为10000行),如下图:

Stream类型说明
| 类型 | 位置 | 说明 |
|---|---|---|
| PRESENT | Row Data | 基本上在各Stripe对应所有列的位置都会出现,按位标记是否非NULL。 |
| D | Row Data | 在各Stripe的基本类型列中出现(也就是不包含struct、map、list等复杂嵌套类型),记录数据内容本身。 |
| LENGTH | Row Data | 在各Stripe中string、varchar、char、list、map等需要记录每个值的长度的列出现,顾名思义。 |
| DICTIONARY_DATA | Row Data | 在各Stripe中string、varchar、char等采用了字典编码(类似RLE也是一种减小文件占用存储的技术,重复值只记录一次,并记录各重复值在文中出现的位置)的字符类型列出现,用来记录该列所有的distinct值(即重复内容只记录一次)。 |
| SECONDARY | Row Data | 在各Stripe中decimal、timestamp等列中出现,用来和DATA Stream搭配(副手),例如timestamp类型的列中,DATA Stream中记录该列在当前Stripe范围中每一行的秒值,而SECONDARY Stream就记录该列在当前Stripe范围中每一行的纳秒值。 |
| ROW_INDEX | Index Data | 存储当前列在该Stripe中某一个Stream的某个row group的起始位置和列偏移量,以及当前列在该Stripe的某个row group中的Statistics统计信息。 |
| BLOOM_FILTER | Index Data | 用于记录当前列在该Stripe中每一个row group的布隆过滤器信息,用于谓词下推跳过不用读取的行组。 |
2.2.3 Index Data
关于Index Data上面介绍过,索引记录的是字段在’Row Data’中的offset(偏移量),并且还记录了每个字段的最大值和最小值。而实际上Index Data同样是以Stripe Stream的形式存在,Bloom Filter Stream与Row Group Index Stream是在每个Stripe头上交错存储的。 这种布局便于在单次读取操作中同时读取bloom stream和row index stream,如下图所示:

3 Parquet文件格式
Parquet文件同样是列式存储,下面介绍一下Parquet文件的内部存储结构。
官网文件结构:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xd745MLx-1671615081746)(/Users/jinlong/data/Typora_WorkSpase/存储格式09.gif)]](https://img-blog.csdnimg.cn/f3a8ff027b3c46228ef38ea4d883a80c.gif)
上图就是官网上文件结构图,个人感觉这个结构图看起来不是很直观,这里对文件结构做了一个简单的拆解,如下图:

结构说明
| 主体 | 说明 |
|---|---|
| Header | 只有4byte,用来体现文件类型,PAR1代表平普通Partquet文件,PARE代表加密Partquet文件 |
| Data | 存放真实数据的地方,以Row Group为单位,Row Group又拆分成Column,Column继续拆分成Page,Page就是最小存储单元。 |
| Index | 记录所有的索引包括Min-Max Index、Column Index 、Offset Index、Bloom Index。其实Index归属于Footer内的,这里单独列出来了是为了更直观体现Parquet文件结构。 |
| Footer | Footer内部包含了索引信息和元数据信息,索引上面介绍了,元数据包括File MetaData、Row Group MetaData、、Column MetaData。 |
3.1 Header
Header在上面的表格中已经进行阐述了,Header内部记录的信息很少,说直白就是起到了一个铭牌作用。Header内部会有一个魔数(Magic Number)同ORC文件类似,这个魔数会标记Parquet文件的类型,是属于普通文件还是加密文件。
3.2 Data
Data在这里是指一个逻辑概念,内部细分成了Row Group、Column Chunk、Page,这里先对Row Group进行一下说明。
3.2.1 Row Group
实际生产环境中,我们以一个数据集作为一个对象进行存储,数据集中包含的数据从几十条到几十亿条不等,所以在存储成Parquet文件时会先进行一次水平的切分,就会讲数据切成一个或多个切片,这些个切片就是我们说到的’Row Group’。进行水平切分的主要原因还是因为HDFS存储数据的单位是数据块(Block),一般默认是128M一个数据块,如果没有将数据集进行水平切分,只要数据集足够大(超过128M),一条record的数据就会跨越多个数据块,这会导致什么呢?显而易见会大大增加IO开销。在Parquet的官方文档中可以看到,是建议我们将HDFS中的数据块大小设置为1G的,并且把Parquet的parquet.block.size设置为1G,目的就是将一个Row Group存放在一个数据块中。
HDFS中数据块和实际Parquet文件的Row Group对照关系如下图:

这里的对照图只是理想状态下的对照关系,在实际生产中存在各种复杂的业务,并不容易做到这样理想的存储方式。
3.2.2 Column Chunk
上面提到了会将数据集进行水平切分,其中的切片就是Row Group,而Column Chunk就是再将Row Group进行垂直切分得到的,将Row Group进行垂直切分后会得到一个或多个列,每一列就是Column Chunk,切分完成后,再将这些Column Chunk顺序保存。
结构切分如下图所示:

上图只是对切分过程做一个更直观的展示,最终切分完成数据结构并不是如图所示。最终的数据还是以列进行顺序存储。
3.2.3 Page
Page就是Parquet文件存储数据的最小单元,每个Page的大小默认为1M,其实将数据切分到Column Chunk时结构已经很简单了,再将结构进行进一步切分主要是为了让数据读取的粒度足够小,便于单条或者小批次的数据查询,而且由于Page是最小的存储单位,所以同时Page也就作为压缩的最小单位,如果没有Page这一级别就会对整个Column Chunk进行压缩,将整个Column Chunk压缩后就不能读取中间的数据,必须将整个Column Chunk进行解压才能读取数据,这样就会降低查询效率。
Page结构如下图:

| 名称 | 说明 |
|---|---|
| Page Header | 这里面记录的就是一种数据交换格式同ORC文件相同使用的都是Protocol Buffer。 |
| Repetition levels | 主要用来表达数组类型字段的长度,但它并不直接记录长度,而是通过记录嵌套层级的变化来间接地表达长度,即如果嵌套层级不变,那么说明数组还在延续,如果嵌套层级变了,说明前一个数组结束了 |
| Definition levels | 与repetition level类似的,definition level主要用来表达null的位置。因为Parquet文件里不会显式地存储null,所以通过definition level来判断某个值是否是null。 |
| values | 顾名思义,记录的就是实际数据值。 |
3.3 Footer
其实Footer中主要包含了两种内容,一是Index,二是MetaData。Footer实际就是Parquet元数据大本营,读取Parquet文件的时候第一步就是读取Footer中的内容,通过Footer中记录的元数据和索引数据进一步查找对应的实际数据。
3.3.1 Index
Parquet文件中的索引数据主要分为Min-Max Index、Column Index、Offset Index、Bloom Index。
| 名称 | 说明 |
|---|---|
| Min-Max Index | 记录Page内部Column的Min_Value和Max_Value的索引位置。 |
| Column Index | 记录了每个ColumnChunk的全部Page的Min-Max Value索引位置。 |
| Offset Index | 记录Page在文件中的offset和Row Range索引位置。 |
| Bloom Index | 记录布隆过滤器的索引位置。对于基数较大,或者非排序的过滤场景,Min_Max很难发挥作用,BloomFilter可以加速过滤匹配。 |
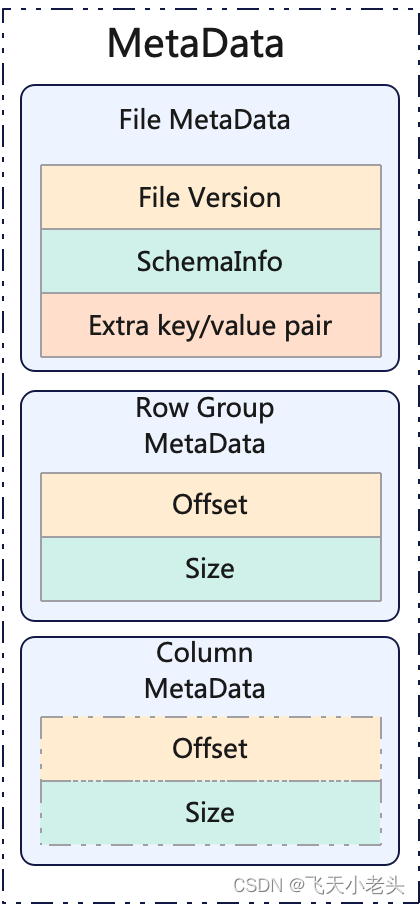
3.3.2 MetaData
Footer中的元数据主要分类三类,文件元数据(File MetaData)、行组元数据(Row Group MetaData)、字段元数据(Column MetaData)
| 名称 | 说明 |
|---|---|
| File MetaData | 记录了文件的版本信息、结构信息(SchemaInfo)、键值对信息(Extra key/value pair)。 |
| Row Group MetaData | Row Group即为Block,这部分记录的就是Block的offset和size。 |
| Column MetaData | 记录了Column Chunk的offset和size。 |
如下图:
4 ORC和Parquet对比
| 比较项 | Parquet | ORC |
|---|---|---|
| 现状 | Apache顶级项目、来源、列式存储 | Apache顶级项目、来源、列式存储 |
| 公司 | Twitter/Cloudera | Hortonworks |
| 列编码 | 支持多种编码、字典。REL、delta等 | 支持主流编码,与Parquet类似 |
| 嵌套式结构 | 支持比较完美 | 多层级嵌套,表达起来复杂,底层未采用google dremel类似实现,性能和空间损失较大 |
| ACID | 不支持 | 支持 |
| Update | 不支持 | 支持 |
| 索引统计信息 | 粗粒度索引,block/group/chunk级别统计信息 | 粗粒度索引,file/Stripe/row级别统计信息 |
| 查询性能 | ORC较高 | ORC较高 |
| 数据压缩能力 | ORC较高 | ORC较高 |
| 支持查询引擎 | hive/impala/drill | Hive |