环境介绍
系统:Windows11
显卡:4070ti
cuda:11.8
配置环境
python环境
安装python的虚拟环境anaconda。Free Download | Anaconda
成功安装后可以按Win键搜索anaconda,可以看到桌面版和命令行版本,我们这里直接用命令行版本。
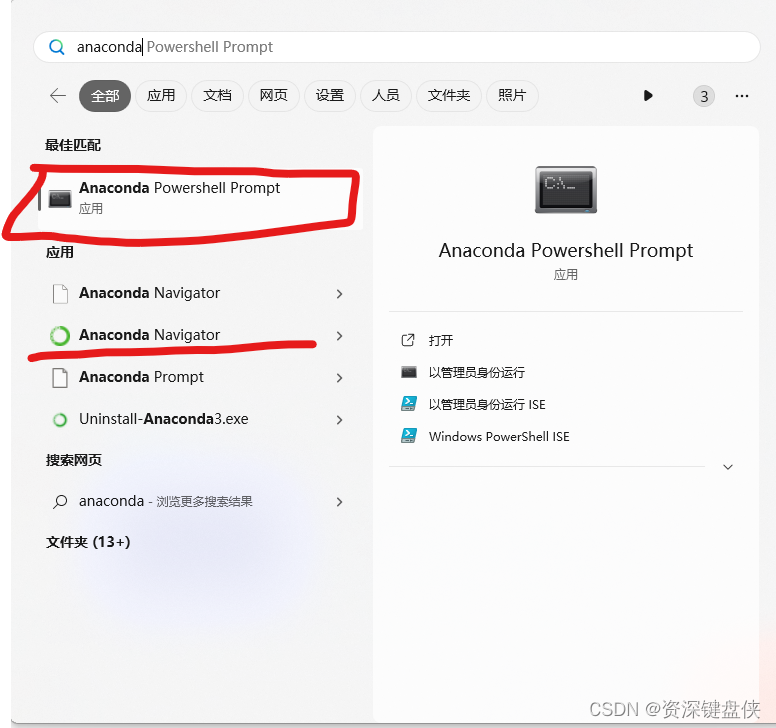
其中Anaconda powershell prompt为命令行的版本,点击进入。
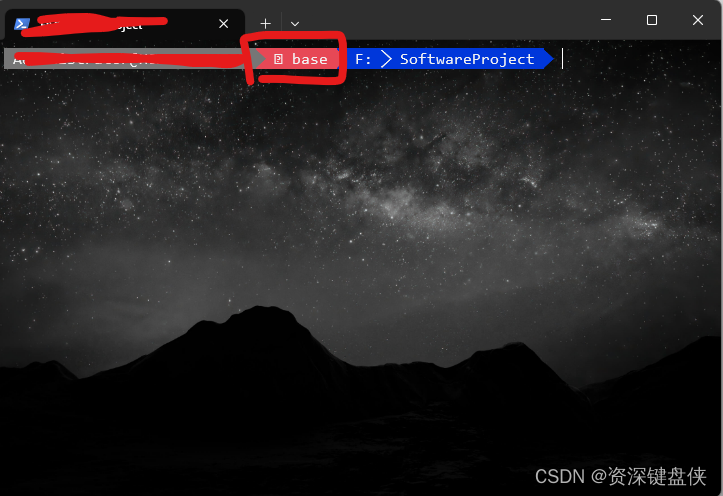
可看到默认已经有base的环境了。而我们需要创建一个环境,让YOLOv5可以正常运行。所以我们创建一个新的环境。使用命令行conda activate -n yolo 此命令的含义是建立一个名为yolo的虚拟python环境。而我们要安装的包都要在这个环境下安装,用于和其他环境隔离。 你也可以不用使用conda,直接在本机上安装yolov5的所有环境也是可以的,但是并不建议这样做。
cuda环境
如果没有显卡可以跳过cuda环境
查看自己的显卡可以使用的cuda版本,我这个显卡是可以安装cuda12的版本。但是我们yolov5依赖的深度学习框架pytorch 2.0.1版本最大支持11.8。下载链接。我安装了几个不同的cuda版本用于切换。
切换时可以找到环境变量->系统变量->Path
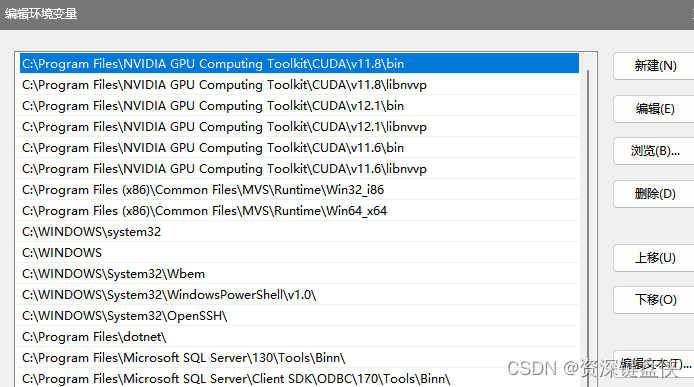
将需要的版本上移。此处我将C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\bin、C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\libnvvp 均上移。记住上移之后重启电脑生效
重启电脑之后再命令行输入命令 nvcc -V 可以查看当前的cuda版本
然后还需要下载cuDNN
因为我们的cuda版本 是11.8,所以我下载了DNN版本Download cuDNN v8.9.4 (August 8th, 2023), for CUDA 11.x
下载压缩包之后就解压。
将解压之后的文件复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8 下,就是刚才环境变量中的那个版本路径
yolov5环境
下载yolov5的源码,可以直接从https://github.com/ultralytics/yolov5 下载,如果觉得慢可以去gitee搜索一下,肯定有人同步过。
下载完成之后使用刚才Figure 2的conda命令行,cd 到yolov5的目录下
pip install -r .\requirements.txt 使用该命令安装yolov5需要的环境。requirements.txt文件是源码中的文件,描述了这个程序运行需要的环境
如果使用显卡训练,则需要安装下显卡版本的pytorch,上面的环境默认只安装cpu的版本。
Start Locally | PyTorch 进入这个网页,选好环境。 我们这个选择的是windows和conda,cuda版本选择11.8,然后版本选择2.0.1 然后看到提示安装的命令行,复制这个命令到上图的powershell中运行。

运行之后pytorch的环境就配置好了。
代码介绍
使用vscode打开yolov5的文件夹。 其中核心的文件有train.py,detect.py文件,用于训练和检测任务。
训练
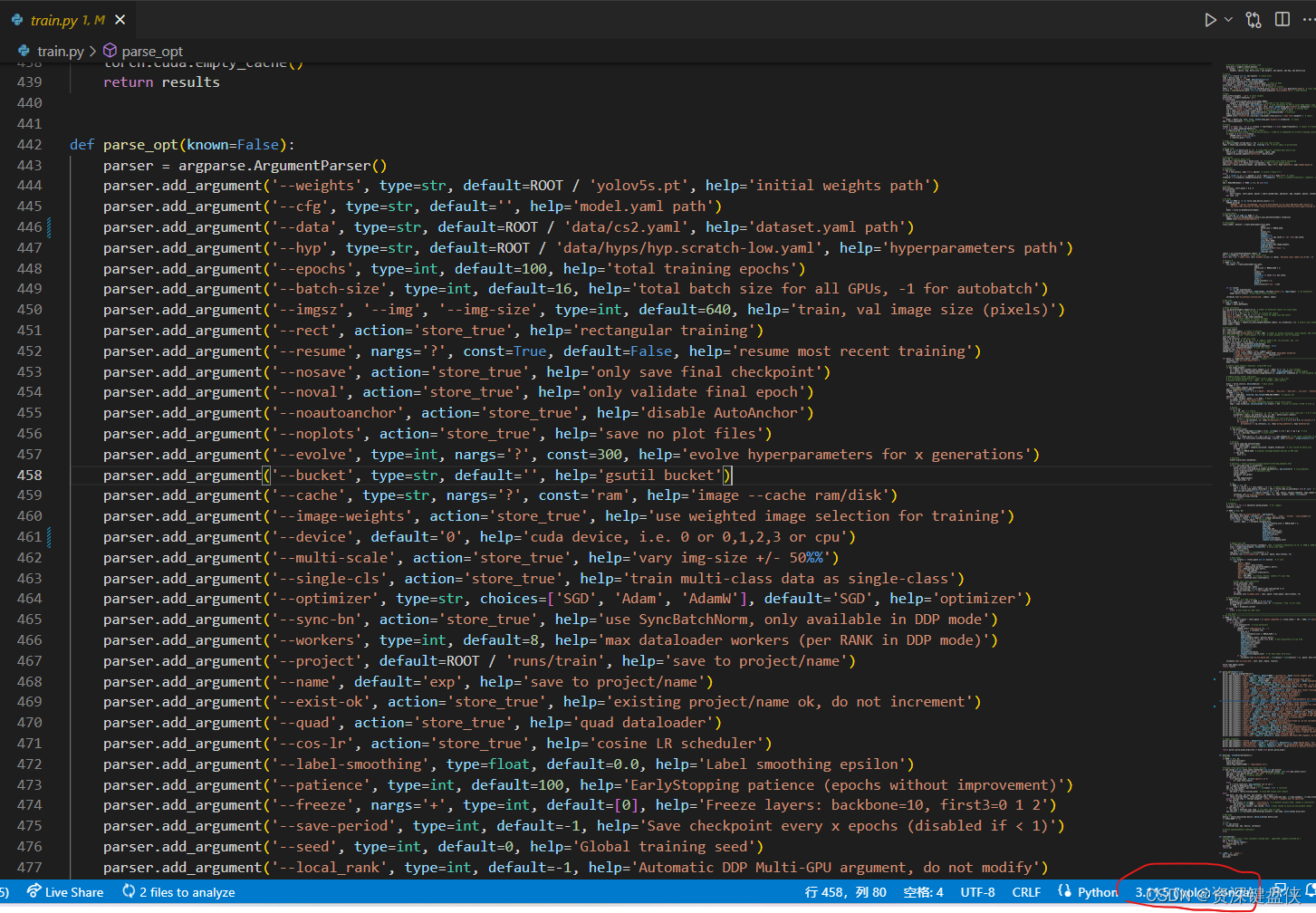
我这里只描述用法,打开train.py文件,大概442行左右就包含了我们需要传入的参数。

我这里就直接改default这里的参数了,正确做法应该是建立launch.json文件来传入这些参数
其中 --weights 为权重参数,可以给它一个预训练的权重文件,我这个直接用yolov5s.pt这个默认的,这个是原本就有的文件。
--device 表示用什么设备来训练,如果直接使用cpu可以不改。 我这里用的是gpu,所有默认值改成0
--epochs 表示训练次数
--data 这里需要给训练集和验证集的数据,这里执行我自己建立的在data目录下的cs2.yaml文件,这里的文件描述我参考。
 path表示数据集的根目录,我这里用的相对目录。 如果不熟的话可以直接使用绝对路径
path表示数据集的根目录,我这里用的相对目录。 如果不熟的话可以直接使用绝对路径
然后在这个目录下建立训练集和验证集的路径, 测试集可以不用。 然后训练集和验证集可以先设为一个路径,先跑通代码再说也是可以的。
names: 这里代表命名。 我这里有4个类别,其中0是匪、1是警、2是死亡人物、3是未激活的人物
这个是我的路径。 然后train和val分别代表数据集和验证集。
他们文件夹下的目录结构是一样的,分别有images和lables目录,分别存有图片和对这个图片的标注。例如
labels.cache是训练过程中的中间文件,不用管。 val下也是一样的文件目录结构。下面讲解如果生产lables和训练用的图片
标注
图片可以直接打开游戏,玩上两把然后录屏。在播放器中播放,等播放到有人物的时候暂停截图。例如我截图
截图之后放到某一个目录下。
然后下载标注软件,我这里用的是Labeling
 打开刚才存有截屏的目录,而且记得将标注文件格式改成yolo。
打开刚才存有截屏的目录,而且记得将标注文件格式改成yolo。
最好记得快捷键 a 上张图、 d 下张图 、w 标注。 而且记得改下他的predefined_classes.txt 文件,不然它会预加载一些用不到的类别。可以设置为自动保存,方便标注。
标注完成之后,在图片的目录下就有同名不同格式的标注文件的,将目录下的图片复制到上述的cs2/train/images文件中、而对应的标注文件 cs2/trian/lables中。 当然留一些样本给验证集,就是放一些到cs/val中,和训练集一样。
训练结果
回到vscode中,打开train.py文件,并将右下角的环境改成conda 'yolo'
然后F5运行
训练结束后会在输出窗口显示,训练结果文件在哪输出。 默认在 yolov5/runs/train/exp* 文件下,exp后面接的数字代表第几次训练。找到最大的数字的目录,里面就是结果,有很多结果的图表。最重要就是 Weights文件夹下的两个权重文件,我们使用best.pt 这个是训练结果最好的权重文件,last.pt只是最后一轮的结果。
测试
vscode 打开detect.py文件, 我这里还是创建了launch.json文件,用来传入检测参数。
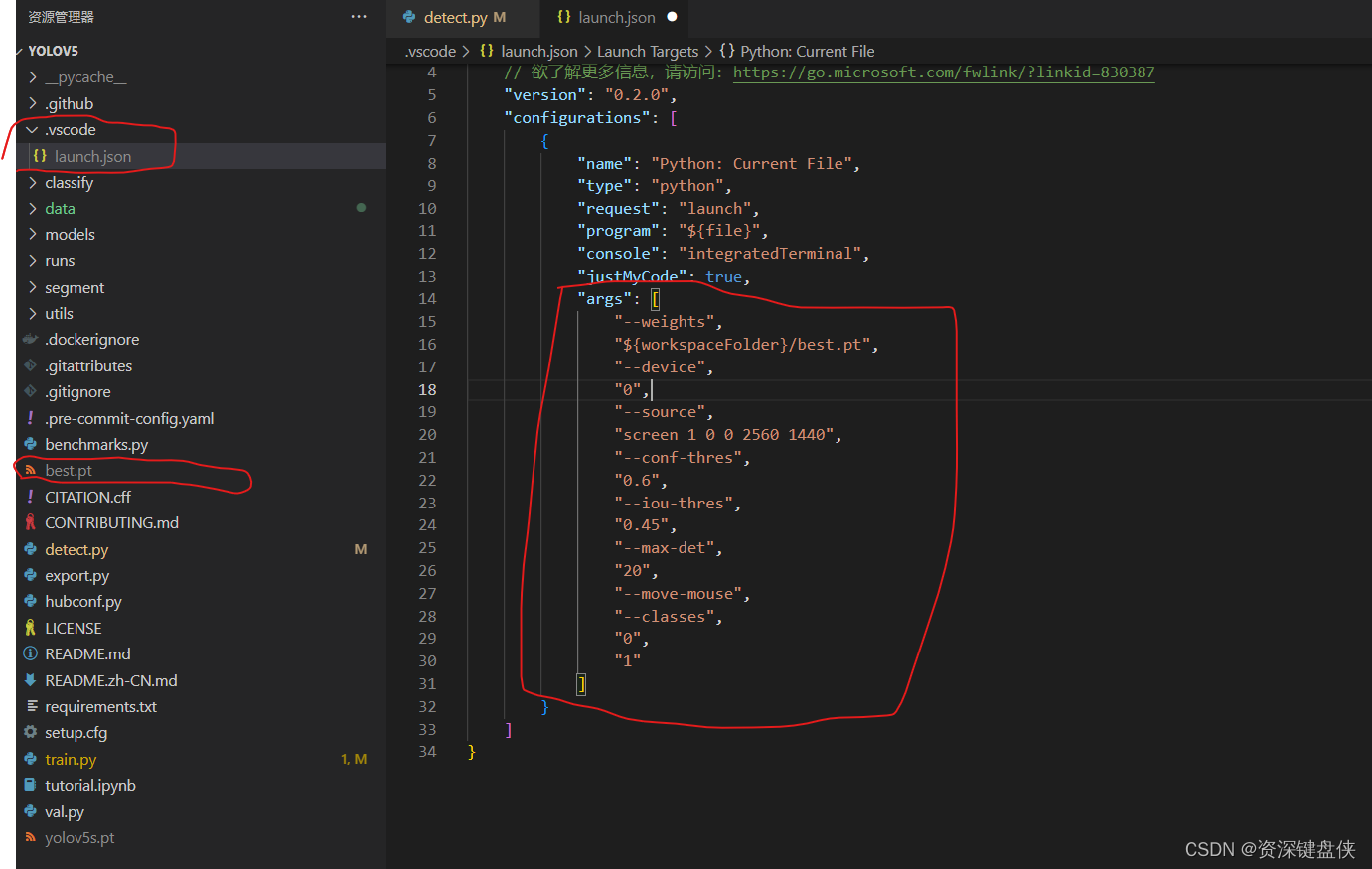 可以看到best.pt我直接复制到YOLOv5目录下,所以我的权重参数--weights也指向此地址。
可以看到best.pt我直接复制到YOLOv5目录下,所以我的权重参数--weights也指向此地址。
--source 这个参数作为检测源,这个直接使用屏幕截屏。 它会边截屏边检测。参数是 "screen 1 0 0 2560 1440" 含义是,第一个屏幕,坐标为0,0 长为2560 宽1440的区域截屏。 可以看出我的显示器是2K的。
--conf-thres 置信度过滤 我这里设置为低于0.6不返回结果
--iou-thres 可以认为是检测框能框到人物的这个坐标的精度
--max-det 是最大能检测的目标总数
--move-mouse 不要管,这个是我自己写的自动瞄准选项
--classes 表示只检测哪些目标
这个文件写好之后就可以返回detect.py文件 F5启动
然后打开游戏,晚上一把。 结束之后
 此处可以按 Ctrl+C启动
此处可以按 Ctrl+C启动
当然也可以不使用Python启动这个。 可以打开conda命令行,切换到yolo环境。 直接Python detect.py -- 参数 这样启动也可以。
结束之后就可以在默认的目录找到输出的结果,一般在上述的runs/detect/exp* 目录下,这个截图的方式检测会返回一个视频。 下面是一些结果的演示
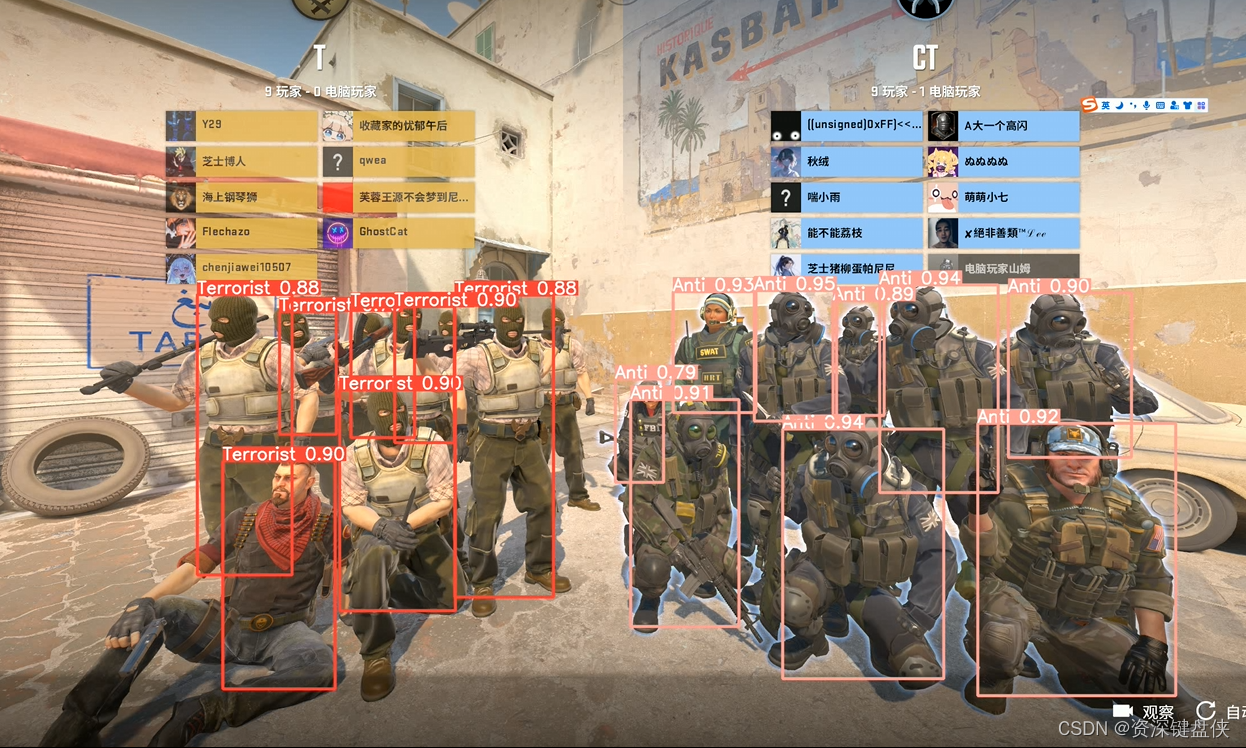
检测效果
其他任务的建议
如果想进一步操作鼠标。 在游戏普通的win32api是无法自动挪移的,建议使用pyautoti模块的鼠标部分。然后最好开窗口模式