一、说明
在所有关于生成式AI的讨论中,为生成式AI提供动力背后的概念可能有点压倒性。在这篇文章中,我们将重点介绍一个功能概念,它为人工智能的潜在认知能力提供支持,并为机器学习模型提供学习和成长的能力:向量嵌入。
向量嵌入的核心是将一段数据表示为数学方程的能力。谷歌对向量嵌入的定义是“一种将数据表示为n维空间中的点的方式,以便相似的数据点聚集在一起”。对于具有强大数学背景的人来说,我相信这些词是完全有意义的,但对于我们这些在数学概念的视觉表示中挣扎的人来说,这听起来可能像胡言乱语。
查看 Ania Kubow 的这个很棒的教程,了解有关向量嵌入的更多信息
因此,让我们从另一个角度来看这个问题,假设你有一个装满M&M的碗,你喜欢吃零食,你最小的后代决定将它们切开并混合在一个装满Skittles糖果的碗中。对于那些不一定熟悉这两件事的人来说,M&Ms和Skittles是两种五颜六色的糖果壳零食,看起来非常相似,但一种是巧克力,另一种是柑橘,这两种口味并没有很好地混合。因此,为了纠正这种情况,我们需要对糖果进行分类,我们决定按类型和颜色对它们进行分类。所以所有的绿色M&M都放在一堆,所有的绿色彩虹一起堆在另一堆,所有的红色M&M和所有的红色Skittles,依此类推。完成后,我们会有一堆明显的M&M和Skittles,按颜色分开,我们可以直观地排列它们,以便我们可以快速看到新糖果掉落的位置。
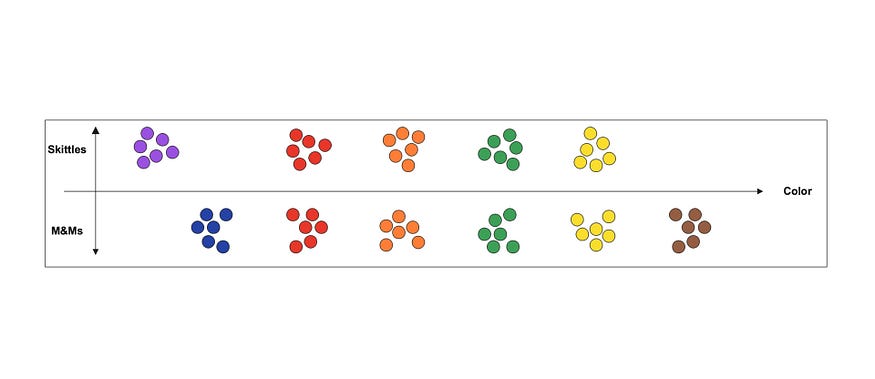
您可以看到,在对糖果进行分类时,我们已经开始布置模式和分组,以便更容易地将糖果关联在一起,并在找到新糖果时找到我们需要的堆。向量嵌入采用此视觉表示形式,并将数学表示形式应用于其位置。考虑这个问题的一个简单方法是,如果我们为每个位置分配不同的值。

使用我们的糖果,现在可以根据其属性为该糖果分配一个值,并根据该数字将新糖果放入正确的位置。这最终就是向量嵌入,尽管复杂性要高得多。
正是这种数学表示是认知能力的基础,使生成人工智能和机器学习模型(如自然语言处理、图像生成和聊天机器人)能够整理类似神经的输入并做出决策。单个嵌入就像一个神经元,就像单个神经元不能构成大脑,单个嵌入不会构成AI系统一样。嵌入越多,这些嵌入的关系就越多,具有越来越复杂的认知能力的能力就越强。当我们将大量嵌入分组到一个可以像大脑一样提供快速可扩展访问的存储库中时,它被称为矢量数据库,如由 Apache Cassandra 提供支持的 Datastax Astra。
但是,要真正了解什么是矢量嵌入以及它们为生成式AI提供的深远价值,我们必须了解如何使用它们,如何创建它们以及它们可以表示哪些类型的数据。
二、示例:使用向量嵌入
我们在向量嵌入方面遇到的挑战之一是它们可以表示几乎任何类型的数据。如果你看一下计算机科学/编程语言中使用的大多数数据类型,它们都表示有限形式的数据。字符被设计为表示字符,整数被设计为表示整数,浮点数被设计为表示带有小数点的更有限的数字表示。已经创建了新的数据类型来增强这些基本数据类型,如字符串和数组,但是这些类型往往仍然只能表示特定类型的数据。
从表面上看,矢量数据类型似乎只是数组的扩展,它允许数组是多维的,并在绘制图形时提供方向性。然而,向量的最大进步是认识到在功能上任何类型的数据都可以表示为向量,更重要的是,数据可以与其他数据进行比较,并且相似性最终可以在这些多维平面内映射。
好吧,我们在这里必须解决的是,即使在写完上述内容之后,它仍然感觉像文字汤。这一切意味着什么?我认为要真正理解向量是什么以及如何使用它,来自早期的实现之一,谷歌在2年发明的Word2013Vec。
Word2Vec 是一种技术,用于将单词作为输入,将它们转换为向量并使用这些向量来创建可视化同义词集群的图形。
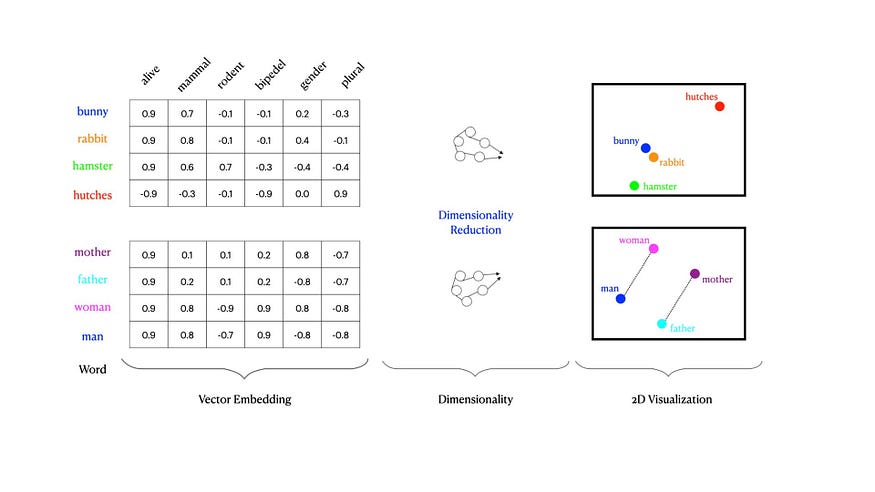
Word2Vec 在功能上的工作方式是每个创建 n 维坐标映射或向量。在我们上面的例子中,我们有一个 5 维坐标映射,真正的矢量映射可以有数百或数千个维度,太多了,我们的大脑无法想象或理解。正是高维数据为机器学习模型提供了关联和绘制语义搜索或矢量搜索等数据点的能力。
在上图中,您可以看到某些单词如何根据相似性自然地组合在一起。与仓鼠相比,兔子和兔子彼此之间的关系更密切,与仓鼠相比,兔子、兔子和仓鼠这三个词都根据彼此的矢量属性更紧密地组合在一起。正是n维空间内的这种方向性允许神经网络处理最近邻搜索等功能。
那么它是如何应用的呢?嗯,可视化这一点的最简单方法之一是在推荐引擎中。例如,如果我获取该节目的质量和方面并对其进行矢量化,然后我获取所有其他节目的质量和方面并对其进行矢量化,我现在可以使用这些品质来查找与我正在观看的节目密切相关的其他节目基于方向性。通过机器学习和人工智能,我观看的节目越多,系统从我感兴趣的n维图的哪些区域获得的信息就越多,并根据这些品质为我的口味提出建议。
如何应用此功能的另一个示例是在搜索之类的事情中。以谷歌的反向图像搜索为例。使用向量进行反向图像搜索非常快速且易于操作,因为当图像作为输入时,反向搜索引擎可以变成矢量,然后使用矢量搜索,它可以在 n 维图中找到图像应该在的特定位置,并为用户提供围绕该图像的任何其他元数据。
在这一点上,数据矢量化的应用确实是无限的。一旦数据转化为载体,就可以完成欺诈或异常检测等操作。数据处理、转换和映射可以作为机器学习模型的一部分完成。聊天机器人可以提供给生产文档,并提供一个自然语言界面,与试图弄清楚如何使用特定功能的用户进行交互。
向量嵌入是实现机器学习和 AI 的核心组件。一旦数据被转换为向量,我们需要将所有向量存储在一个高度可扩展、高性能的存储库中,称为向量数据库。一旦数据被转换并存储为矢量,数据现在可以为多个不同的矢量搜索用例提供支持。
三、创建向量嵌入
那么向量嵌入是什么,它是如何创建的呢?创建向量嵌入从离散数据点开始,该数据点在高维空间中转换为向量表示。就我们的目的而言,在低 3D 空间中可视化可能是最简单的。假设我们有三个离散的数据点,单词cat,单词duck和单词弹涂鱼。我们将评估这些词是走路、游泳还是飞行。让我们以猫这个词为例。猫主要走路,所以让我们为走路分配一个值 3,猫会游泳,但大多数猫不喜欢游泳,所以让我们为此分配一个值 1,最后我不知道有任何猫可以自己飞行,所以让我们为此分配一个值 0。
所以猫的数据点是:
猫: (游泳 - 1, 苍蝇 - 0, 散步 — 3)
如果我们对鸭子和弹涂鱼(一种可以在陆地上行走的鱼)这个词做同样的事情,我们会得到:
鸭子:(游泳,苍蝇 - 2,散步 - 2)
弹涂鱼: (游泳 — 3, 苍蝇 — 0, 散步 — 1)
通过此映射,我们可以将每个单词绘制成三维图表,创建的线是向量嵌入。猫 [3,1,0], 鸭 [3,2,2], 弹涂鱼 [2,3,0]。

一旦我们所有的离散对象(单词)都转换为我们的向量,我们就可以根据语义相似性看到它们之间的紧密程度。例如,很容易看出所有三个词都被绘制在z轴上,因为所有的动物都可以走路。像机器学习这样的东西的真正力量在于当你查看图形平面上的向量表示时。例如,如果我们比较步行和游泳的动物,我们可以看到猫与鸭子与弹涂鱼的关系更密切。
在我们的例子中,我们只有一个三维空间,但有一个真正的向量嵌入,向量跨越一个 N 维空间。机器学习和神经网络使用这种多维表示来做出决策并启用分层最近邻搜索模式。
在创建向量嵌入时,可以采取两种方法,一种是特征工程,它利用领域知识和专业知识来量化将用于定义向量不同顶点的“特征”集,或者使用深度神经网络来训练模型以将对象转换为向量。训练模型往往是自特征工程以来最常见的方法,而提供对领域的详细了解需要太多的时间和费用来扩展,而训练模型可以生成密集的高维(1000s)向量。
四、预训练模型
预训练模型是为解决一般问题而创建的模型,可以按原样使用或作为解决复杂有限问题的起点。有许多预训练模型可用于不同类型的数据的示例。BERT、Word2Vec 和 ELMo 是可用于文本数据的众多模型中的一部分。这些模型已经在非常大的数据集中进行了训练,并将单词、句子、整个段落和文档转换为向量嵌入。但预训练模型不仅限于文本数据,图像和音频数据也有许多预训练模型通常可用。像Inception这样的模型使用卷积神经网络(CNNs)模型和DALL-E 2,它使用扩散模型。
五、可以嵌入哪些类型的东西?
向量嵌入可以提供的关键机会之一是能够将任何类型的数据表示为向量嵌入。目前有许多示例,其中文本和图像嵌入被大量用于创建解决方案,例如使用 GPT-4 等工具的自然语言处理 (NLP) 聊天机器人或 DALL-E 2 等生成图像处理器。
5.1 文本嵌入
文本嵌入可能是最容易理解的,我们一直在使用文本嵌入作为大多数示例的基础。文本嵌入从基于文本的对象的数据语料库开始,因此对于像Word2Vec这样的大型语言模型,它们使用来自维基百科等大型数据集。但是,文本嵌入几乎可用于任何类型的基于文本的数据集,您希望快速轻松地搜索最近邻或语义相似的结果。
例如,假设您想创建一个 NLP 聊天机器人来回答有关您的产品的问题,您可以使用产品文档和产品常见问题解答的文本嵌入,允许聊天机器人根据提出的问题回复查询。或者,将您多年来收集的所有食谱作为数据语料库,并使用该数据根据储藏室中的所有成分提供食谱。文本嵌入带来的是获取单词、段落和文档等非结构化数据并以结构化形式表示它们的能力。
5.2 图像嵌入
图像嵌入(如文本嵌入)可以表示图像的多个不同方面。从完整图像到单个像素,图像嵌入提供了对图像具有的特征集进行分类的能力,并以数学方式呈现这些特征,以供机器学习模型分析或供Dall-E 2等图像生成器使用。
图像嵌入最常见的用法之一可能是用于分类和反向图像搜索。例如,我有一张在我后院拍摄的蛇的照片,我想知道它是什么类型的蛇,它是否有毒。有了所有不同类型的蛇的大数据语料库,我可以将蛇的图像输入到所有蛇的矢量嵌入的矢量数据库中,并找到离我的图像最近的邻居。从语义搜索中,我可以提取离我的蛇最近的最近邻图像的所有“属性”,并确定它是哪种蛇以及我是否应该关注。
如何使用矢量嵌入的另一个例子是自动图像编辑,如谷歌魔术照片编辑器,它允许生成AI编辑图像,对图像的特定部分进行编辑,例如从背景中删除人物或添加更好的构图。
5.3 产品嵌入
如何使用向量嵌入的另一个示例是在推荐引擎中。产品嵌入可以是任何东西,从电影、歌曲到洗发水。通过产品嵌入,电子商务网站可以通过搜索结果、点击流和购买模式观察购物者的行为,并根据语义提出推荐,类似地推荐新产品或利基产品。例如,假设我访问了我最喜欢的在线零售商。我正在仔细阅读该网站,并为我刚刚得到的新小狗在我的购物车中添加了一堆东西。我添加了我用完的小狗食物,新的租约,一个狗碗和一个水盘。然后我搜索网球,因为我希望我的新小狗有一些玩具可以玩。现在我真的对网球或狗玩具感兴趣吗?如果我在当地的宠物店,有人在帮助我,他们会清楚地看到我对网球并不真正感兴趣,我实际上对狗玩具感兴趣。产品嵌入带来的是能够从我的购买经验中收集这些信息,使用为每个产品生成的矢量嵌入,专注于狗,并预测我实际上在寻找什么狗玩具而不是网球。
六、如何开始使用向量嵌入
向量嵌入的概念可能非常压倒性。每当我们尝试可视化n维并使用这些来寻找语义相似性时,都将是一个挑战。值得庆幸的是,有许多工具可用于创建矢量嵌入,如Word2Vec,CNN和许多其他工具,可以将您的数据转换为矢量。
如何处理这些数据,如何存储和访问以及如何更新这些数据才是真正的挑战所在。
虽然这听起来很复杂,但 Astra DB 上的矢量搜索通过一个完全集成的解决方案为您处理所有这些问题,该解决方案提供了为 AI 构建上下文数据所需的所有部分。从数字神经系统 Astra Streaming,建立在提供内联矢量嵌入的数据管道之上,一直到实时大容量存储、检索、访问和处理,通过当今市场上最具可扩展性的矢量数据库 Astra DB,在一个易于使用的云平台中。立即免费试用DataStax Astra DB。

![哈希/散列--哈希表[思想到结构]](https://img-blog.csdnimg.cn/4417c76f041e4fc2b7b10a2c25917b0e.png)