文章链接: https://arxiv.org/abs/2308.08998
大模型(LLMs)爆火的背后,离不开多种不同基础算法技术的支撑,例如基础语言架构Transformer、自回归语言建模、提示学习和指示学习等等。这些技术造就了像GPT-3、PaLM等基座生成模型,在这些基座模型之上,研究人员通过引入人类反馈的强化学习算法(RLHF)开发出了例如ChatGPT这些与人类偏好保持一致的可聊天模型,才将LLMs真正带领到公众视野中。RLHF由于自身在线更新的限制带来了较大的训练计算代价,且容易遭到”外部攻击“。
为了解决上述问题,来自Google DeepMind的研究团队提出了一种全新的强化自训练算法(Reinforced Self-Training,ReST),ReST相比RLHF,可以以更高的效率使LLMs的输出与人类偏好保持一致。ReST的设计灵感来源于他们将语言模型的对齐问题视为一个不断增长的批量强化学习问题,因此本文作者首先从一个初始LLMs策略出发,并根据该策略生成一个离线数据集,然后使用离线RL算法使用这些样本反过来更新LLMs策略。作者重点在基础NLP任务中的机器翻译任务上对ReST算法的性能进行了评估,实验结果表明,ReST相比RLHF可以更明显的提高模型的翻译质量。
01. 引言
如何将LLMs的输出与人类偏好或价值观进行高效的对齐,是目前提升LLMs性能的关键问题,如果没有进行适当的对齐处理,LLMs可能会产生风险高或完全错误的内容,这对于下游应用程序具有毁灭性的影响。目前常用的RLHF方法通常使用人类反馈的标注数据来学习一个奖励模型,然后将其用于强化学习目标来对LLM进行微调对齐。但是RLHF通常依赖于在线RL方法,例如PPO[1]和A2C[2],这就需要在模型训练过程中多次使用奖励模型来从更新后的策略中采样新样本,这会带来高昂的计算代价。为了解决这一问题,本文提出了一个自训练强化学习算法ReST,ReST将人类标注员从反馈训练循环中丢弃,自行生成并使用离线数据进行反馈训练。作者巧妙地设计了一个内外循环机制,如下图所示。

其中外循环称为Grow循环,模型会根据当前的策略来采样生成一个对齐数据集,内循环称为Improve循环,模型会对外循环生成的数据集进行过滤(使用人类偏好评分函数对样本进行排序过滤),并将过滤后的数据继续用于微调优化策略,内外循环相互影响,以降低采样数据带来的训练成本。ReST不再依赖在线的RL损失,因而成为了一种通用的强化学习框架,允许在执行Improve循环时使用不同的离线RL损失,使整体框架更具灵活性。
02. 本文方法
2.1 ReST的整体流程

2.2 Grow外循环



2.2 Improve内循环


03. 实验效果
本文的实验主要在机器翻译基准上进行,作者选取了IWSLT 2014、WMT 2020和Web Domain三个数据集,其中前两者为常见的机器翻译数据集,后者为内部测试数据集,这些数据集都包含一组语言文本和对应人类标注员给出的真实参考翻译。作者选取了几种不同的离线强化学习算法作为baseline对比方法,包括OAC、BVM、PO、GOLD和BC。
3.1 对Improve循环进行分析
作者首先分析了ReST的两个循环步骤对最终性能的影响,例如增加Improve循环的次数是否会增加奖励模型的分数,如下图所示,灰色柱状为监督学习baseline的分数,通过调整损失函数类型、Improve steps(I)和Grow steps(G)来构成不同的ReST变体,其分数为紫色柱状所示。

可以看到,随着Improve steps数量的不断增加,ReST在所有三个数据集上的平均奖励分数都得到了提高。
3.2 对Grow循环进行分析
Grow步骤可以不断增加离线训练的样本数量,因此作者对比了执行单次Grow步骤和执行两次Grow步骤后的模型性能,如下图所示,执行两次Grow步骤的ReST变体在IWSLT 2014和Web Domain数据集上都有明显的提升。

3.3 对损失函数进行分析
在下图中作者展示了本文方法与监督训练模型,以及使用不同损失函数的ReST变体的平均奖励分数对比,可以观察到,即使只使用单次Grow步骤,ReST的不同变体(紫色)也显着优于监督学习模型(灰色)得到的奖励分数。

此外,我们也可以观察到,BC损失在单次Grow步骤的情况下,明显优于使用其他损失函数的效果。
3.4 ReST与在线RL算法进行对比
作者选取PPO算法作为对比在线RL算法,PPO广泛用于各式RLHF流程中。在实验中,PPO算法可以通过单次Grow步骤访问与ReST算法相当数量的训练数据,对比结果如下表所示。
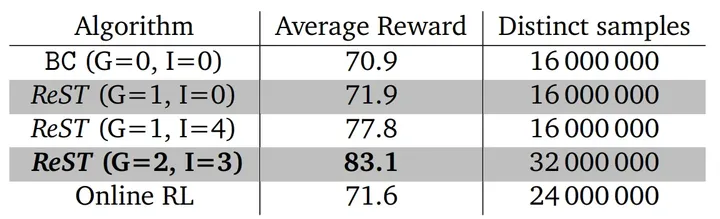
可以看到,在线PPO算法的平均奖励分数基本与ReST算法持平,但是这只是在单次Grow步骤的情况下,当ReST使用多步Grow和Improve后(并且参与训练的数据量相同),性能会得到显著的提升。
04. 总结
本文提出了一种名为ReST的自训练离线强化学习算法,其中包含了一种新型的内外循环机制(分为Grow外循环和Improve内循环)来高效的调度RL过程中的策略生成和更新。同时其具有良好的拓展性,可以灵活的应用在多种不同的RL损失中,本文作者在机器翻译基准上的实验表明,使用常用的BC损失可以使ReST在多种不同的环境中得到更高的奖励分数。ReST的提出也向社区宣布,在对LLMs执行与人类偏好对齐时,可以尝试除PPO等在线RL算法之外的更多RL优化手段。
参考
[1] J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
[2] V. Mnih, A. P. Badia, M. Mirza, A. Graves, T. Harley, T. P. Lillicrap, D. Silver, and K. Kavukcuoglu. Asynchronous methods for deep reinforcement learning. In International Conference on Learning Representations, 2016.
作者:seven_
关于TechBeat人工智能社区
▼
TechBeat(www.techbeat.net)隶属于将门创投,是一个荟聚全球华人AI精英的成长社区。
我们希望为AI人才打造更专业的服务和体验,加速并陪伴其学习成长。
期待这里可以成为你学习AI前沿知识的高地,分享自己最新工作的沃土,在AI进阶之路上的升级打怪的根据地!
更多详细介绍>>TechBeat,一个荟聚全球华人AI精英的学习成长社区