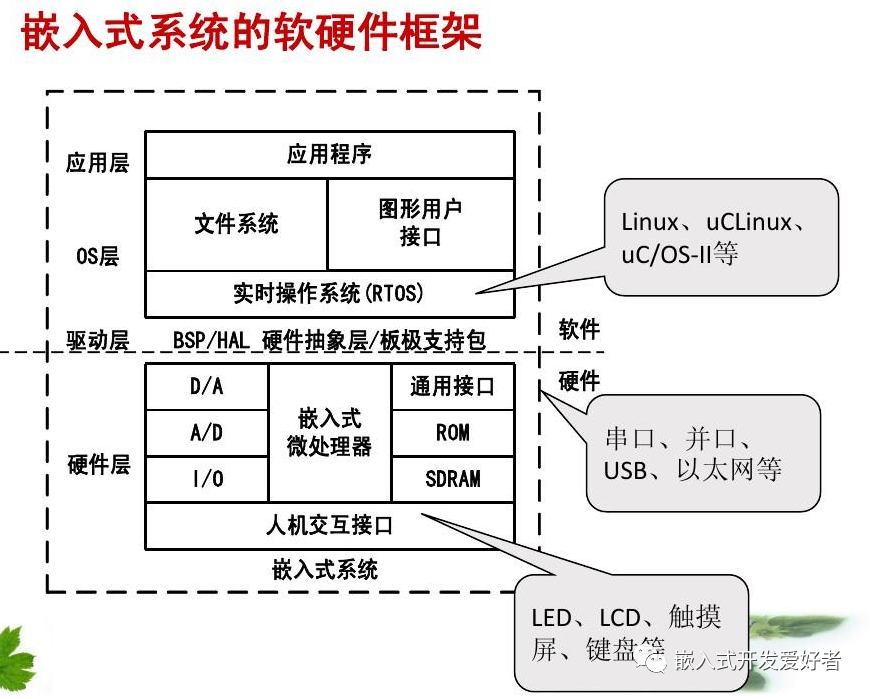
什么是bug
在学习编程的过程中,应该都听说过bug吧,那么bug这个词究竟是怎么来的呢?
其实Bug的本意是“虫子”或者“昆虫”,在1947年9月9日,格蕾丝·赫柏,一位为美国海军工作的电脑专家,也是最早将人类语言融入到电脑程序的的人之一,这天他对Harvard Mark II 设置好了17000个继电器进行编程之后,技术人员正在进行整机运行时,它突然停止了工作。于是它们爬进去找原因,发现这台巨大的计算机内部有一组继电器的触点之间有只飞蛾。之后,赫柏用胶条贴上飞蛾,并把“bug”来表示“一个在电脑程序里的错误”,“bug”这个说法一直沿用到今天。

调试的重要性
在我们初学阶段,可能并不太会注意调试,代码遇到问题可能就是简单看看逻辑问题。但是如果遇到了一些难以寻找的问题时,调试是真的一个很不错的方法让你快速的找到你的bug。
调试的基本步骤
- 发现程序的错误的存在
- 以隔离、消除等方式对错误进行定位
- 确定错误产生的原因
- 提出纠正错误的解决办法
- 对程序错误予以改正,重新测试
debug和release介绍

在VS2022中,有两种不同的版本,一种叫做Debug版本,一种叫做Release版本。而这两种的本质区别就是release版本是不能调试的。
Debug版本
Debug版本,通常称为调试版本,它包含调试信息,并且不作任何优化,便于程序员调试程序。Debug版本就是为调试而生的,编译器在Debug版本中会假如调试辅助信息的,并且很少会进行优化,代码还是“原汁原味”的。
Release版本
Release版本,通常称为发布版本,它往往是进行了各种优化,使得程序在代码大小和运行速度上都是最优的,以便用户很好的使用。Release 是“发行”的意思,Release 版本就是最终交给用户的程序,编译器会使尽浑身解数对它进行优化,以提高执行效率,虽然最终的运行结果仍然是我们期望的,但底层的执行流程可能已经改变了。编译器还会尽量降低 Release 版本的体积,把没用的数据一律剔除,包括调试信息。最终,Release 版本是一个小巧精悍、非常纯粹、为用户而生的程序。
虽说两种版本有些差别,但是它们之间运行的结果是一样的。那么,它们之间的区别究竟在哪呢?为了直观一点,我们看一下下面的图片,
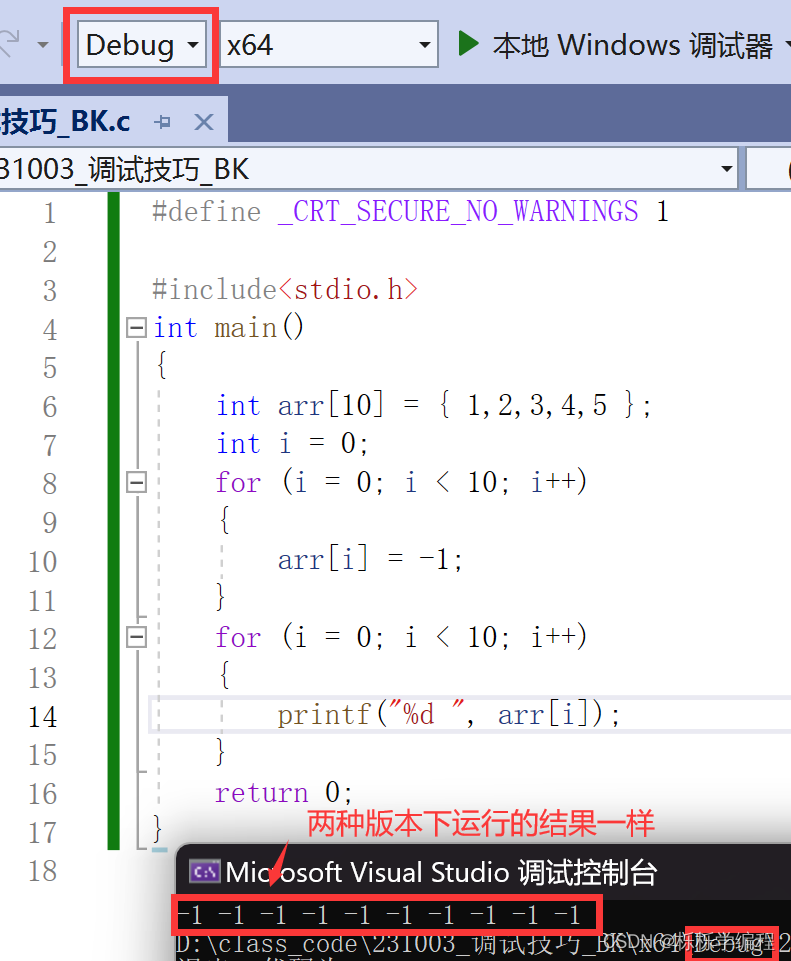
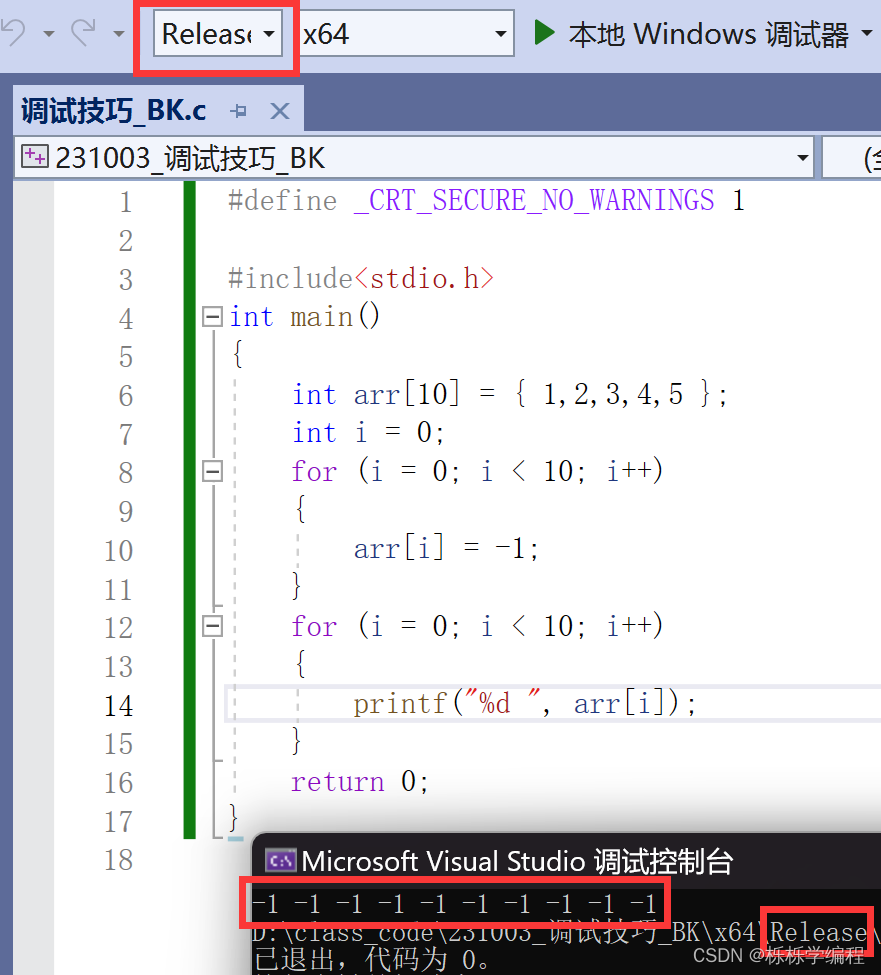
同一种代码,在不同的版本下,会生成各自的文件夹以及exe程序,因为debug版本,会包含各种调试辅助信息,所以在debug版本下生成的文件的内存是大于在release版本下的内存的。
Windows环境调试介绍
调试的快捷键
Ctrl+F5
开始执行不调试,如果你想让程序直接运行起来而不调试就可以直接使用。
F10
逐过程,通常用来处理一个过程,一个过程可以是一次函数调用,或者是一条语句。
F11
逐语句,就是每次都执行一条语句,但是这个快捷键可以使我们的执行逻辑进入函数内部。
F9
创建断点和取消断点。
断点的重要作用,可以在程序的任意位置设置断点。
这样就可以使得程序在想要的位置随意停止执行,继而一步步执行下去。
F5
启动调试,经常用来直接跳到下一个断点处。
断点的使用还有一些小的技巧,如果说是假设还是上面的代码,想要在i=5时,就让其程序停止执行,那么先在那一条语句中设置断点,随后单击右键,点击“条件”,并且设置所需要的情况条件即可。

调试的时候查看程序当前信息
下面这些功能,必须是在开始调试之后,才能在窗口中看到这些信息。
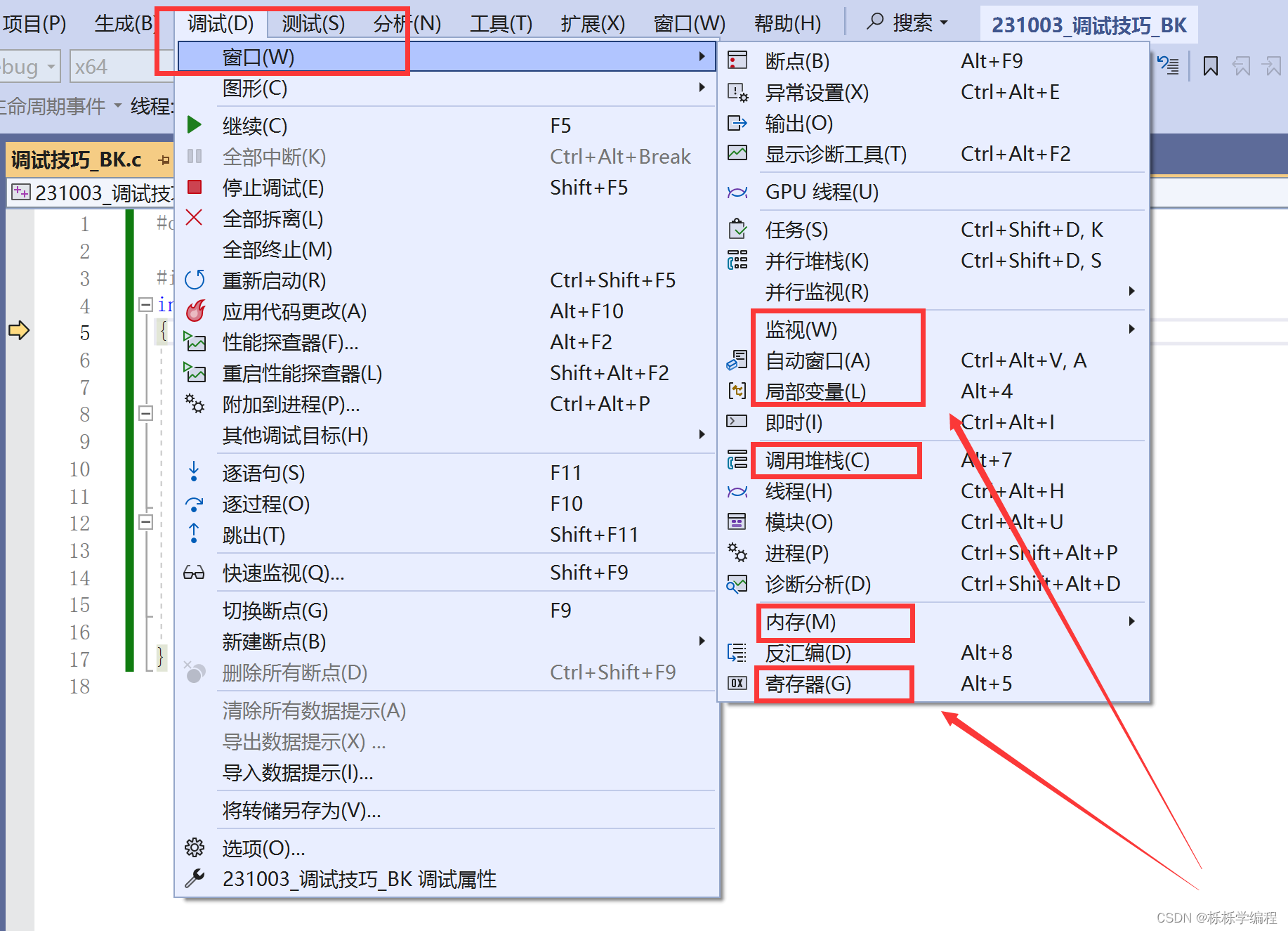
自动窗口
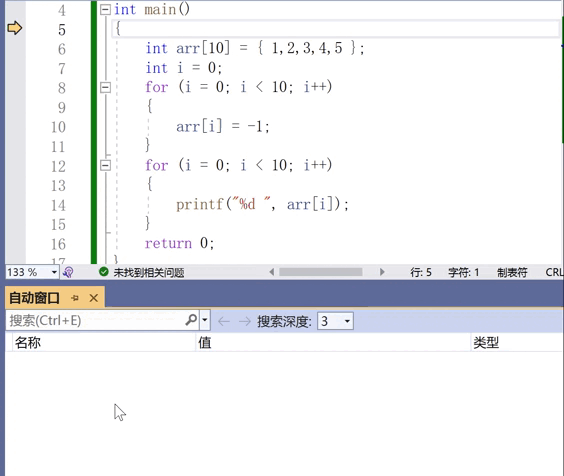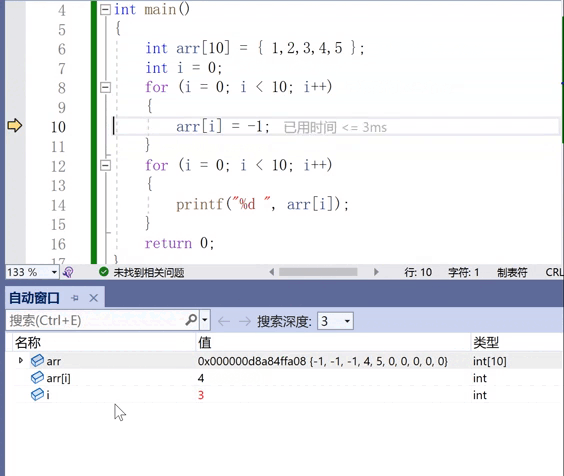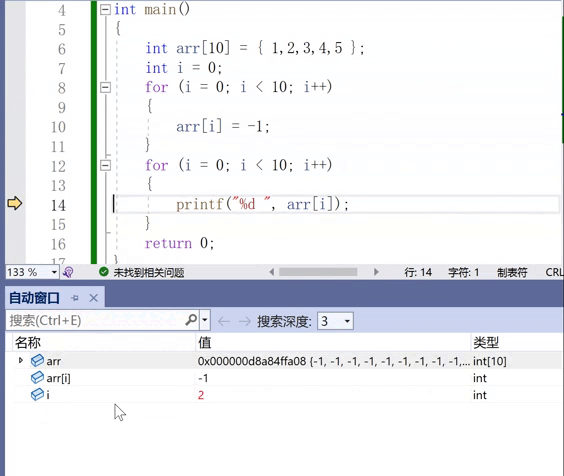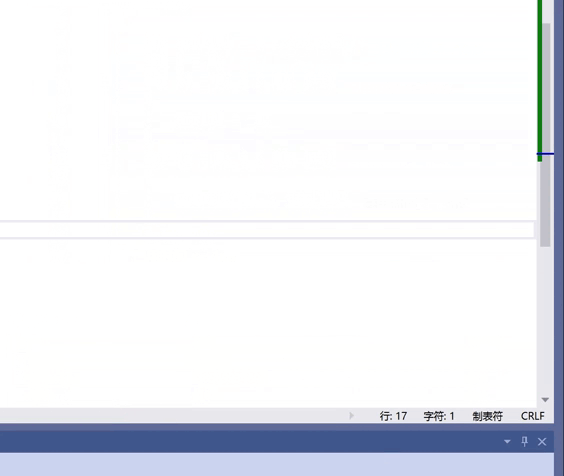
但是,这种自动窗口是有些弊端,让我们不能持续地关注到一个数值。其实我们更想要随意地观察一个数值,常用的一个窗口是“监视”。
监视窗口
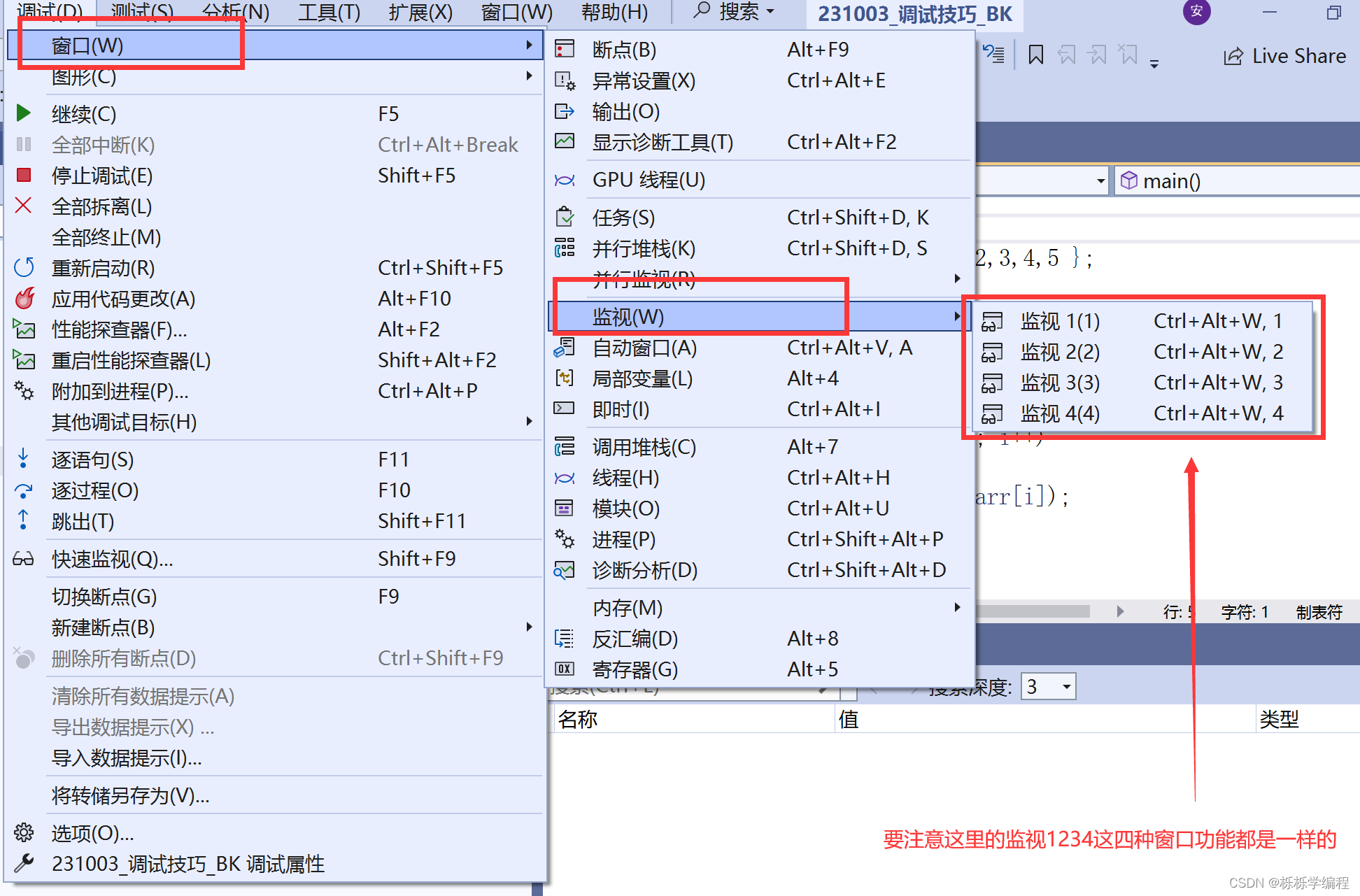 根据自己的需求,可以打开多个窗口。
根据自己的需求,可以打开多个窗口。
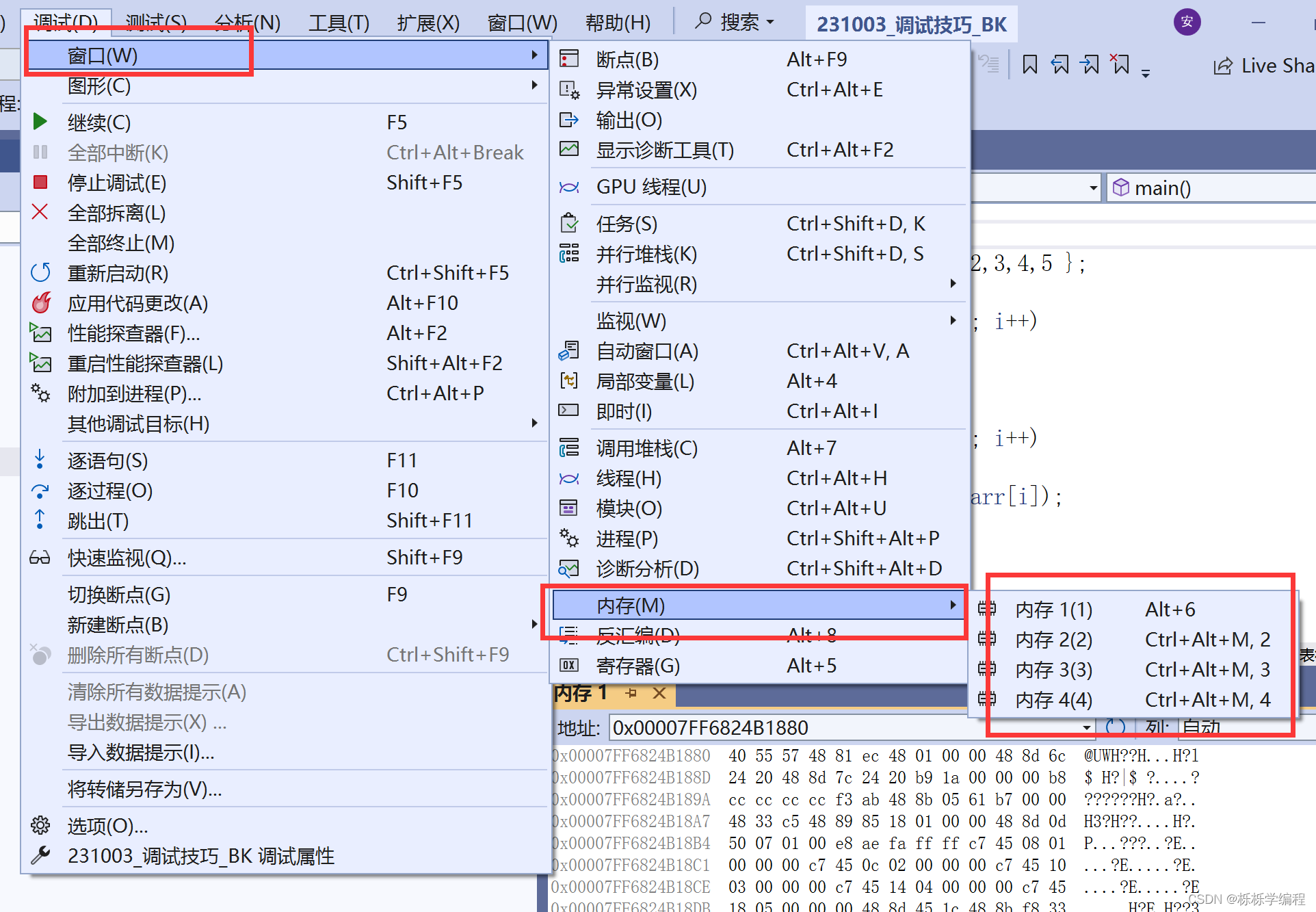
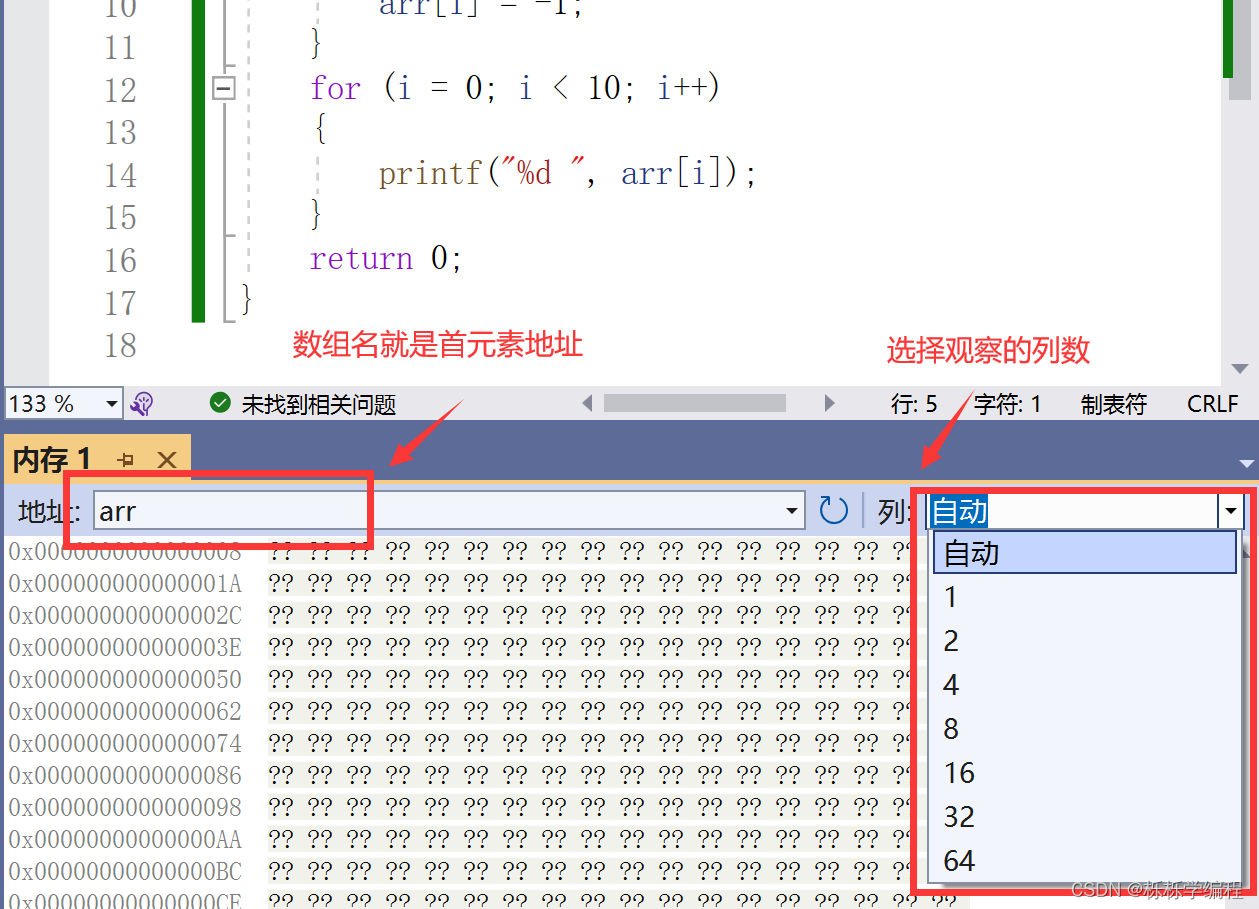
内存
调用堆栈
调用堆栈,反应的就是函数的调用逻辑。例如,将下面的代码,在调用堆栈中观察:
#include <stdio.h>
void test2()
{
printf("test2\n");
}
void test1()
{
test2();
}
void test()
{
test1();
}
int main()//main函数也是被其他函数调用的
{
test();
return 0;
}
- 在学习完了调试一些小技巧之后,小编要给大家来建议一些事情啦~
- 多多动手,尝试调试,才能有进步。
- 一定要掌握调试的技巧。
- 初学者可能在80%的时间在写代码,20%的时间在调试。但是一个程序员可能是在20%的时间在写程序,但是80%的时间在调试。
- 我们目前不懈的都是简单代码的调试。
- 但是在以后可能会出现很复杂的调试场景:多线程程序的调试等。
- 多多使用快捷键,提升效率。
一些调试的实例
接下来,我们看几个实例,并且利用调试来分析其中的错误在哪。
实例一:求1!+2!+3!+...+n!,不考虑溢出。
#include <stdio.h>
int main()
{
int i = 0;
int sum = 0;//保存最终结果
int n = 0;
int ret = 1;
scanf("%d", &n);//输入3
//1!+2!+3!=1+2+6=9
for (i = 1; i <= n; i++)//n项之和
{
int j = 0;
for (j = 1; j <= i; j++)
{
ret *= j;
}
sum += ret;
}
printf("%d\n", sum);
return 0;
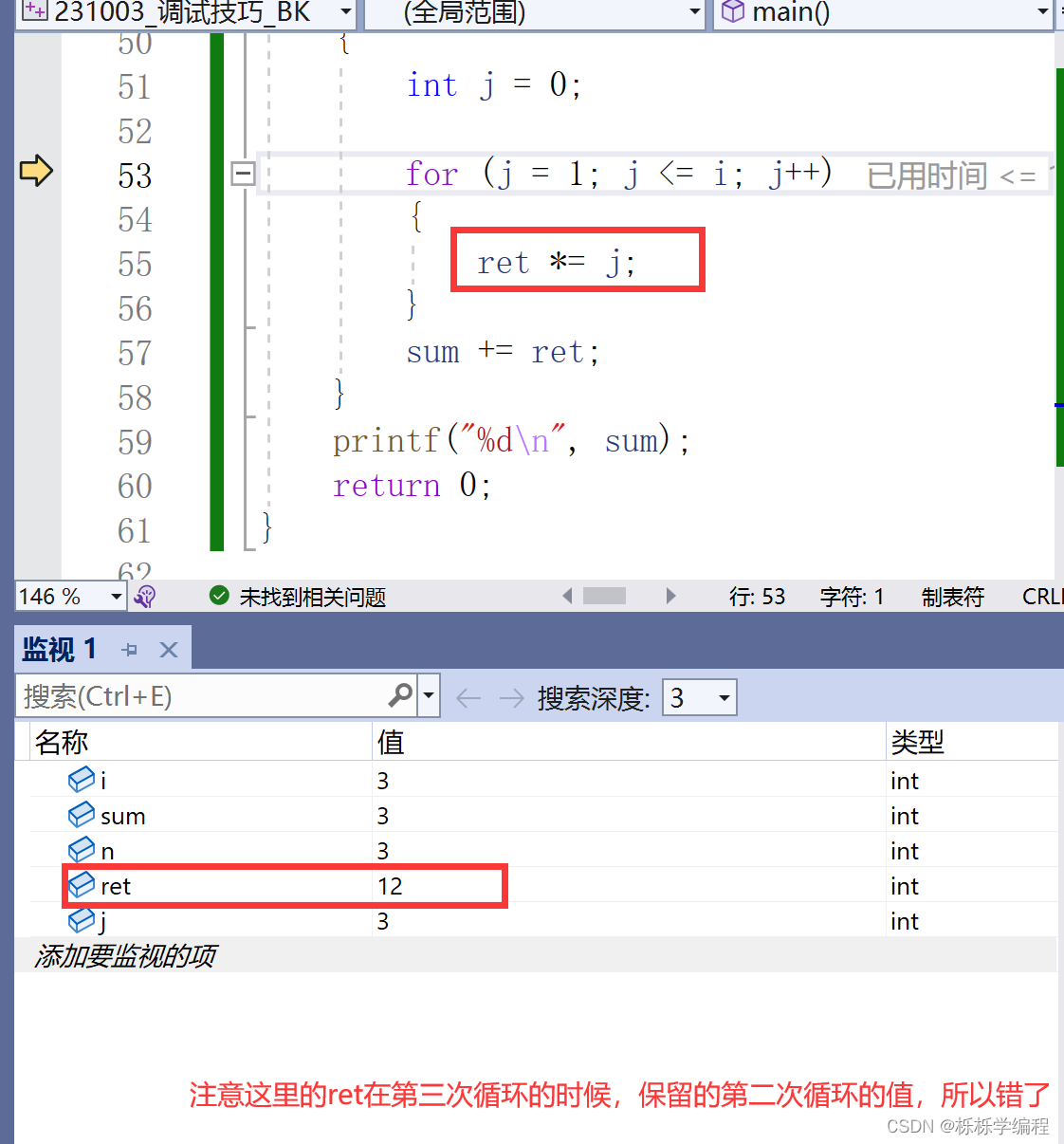
}本应该在这个程序中输入“3”,其结果应该是“9”,为何会是“15”呢?
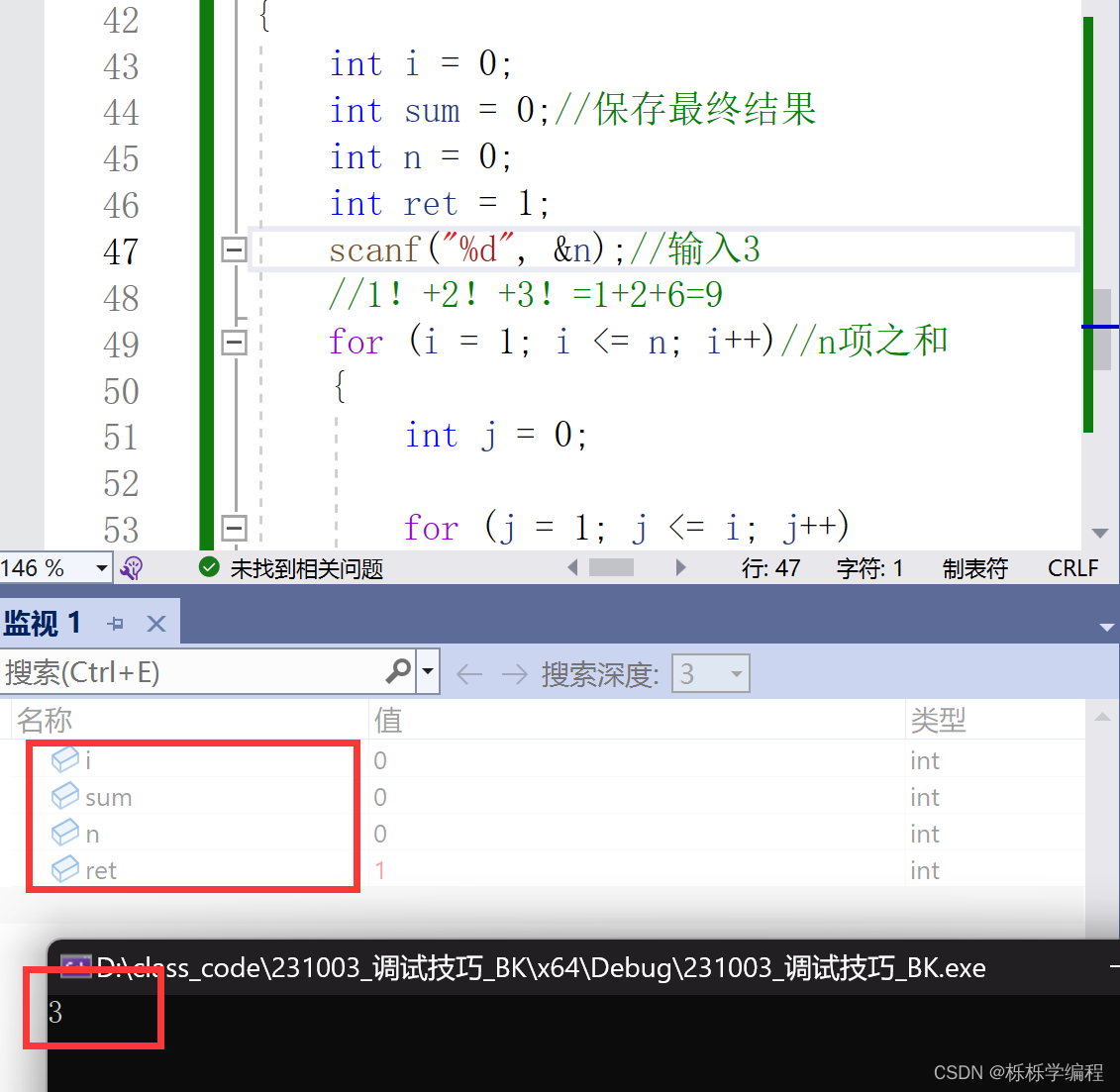 经过调试之后,可以观察到:其实是ret的值,没有在适当的位置进行初始化。
经过调试之后,可以观察到:其实是ret的值,没有在适当的位置进行初始化。
实例二:研究程序死循环的原因。
int main()
{
int i = 0;
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
for (i = 0; i <= 12; i++)
{
arr[i] = 0;
printf("hehe\n");
}
return 0;
}注意,这道题仅限在VS上X86的Debug模式下验证和讲解的。
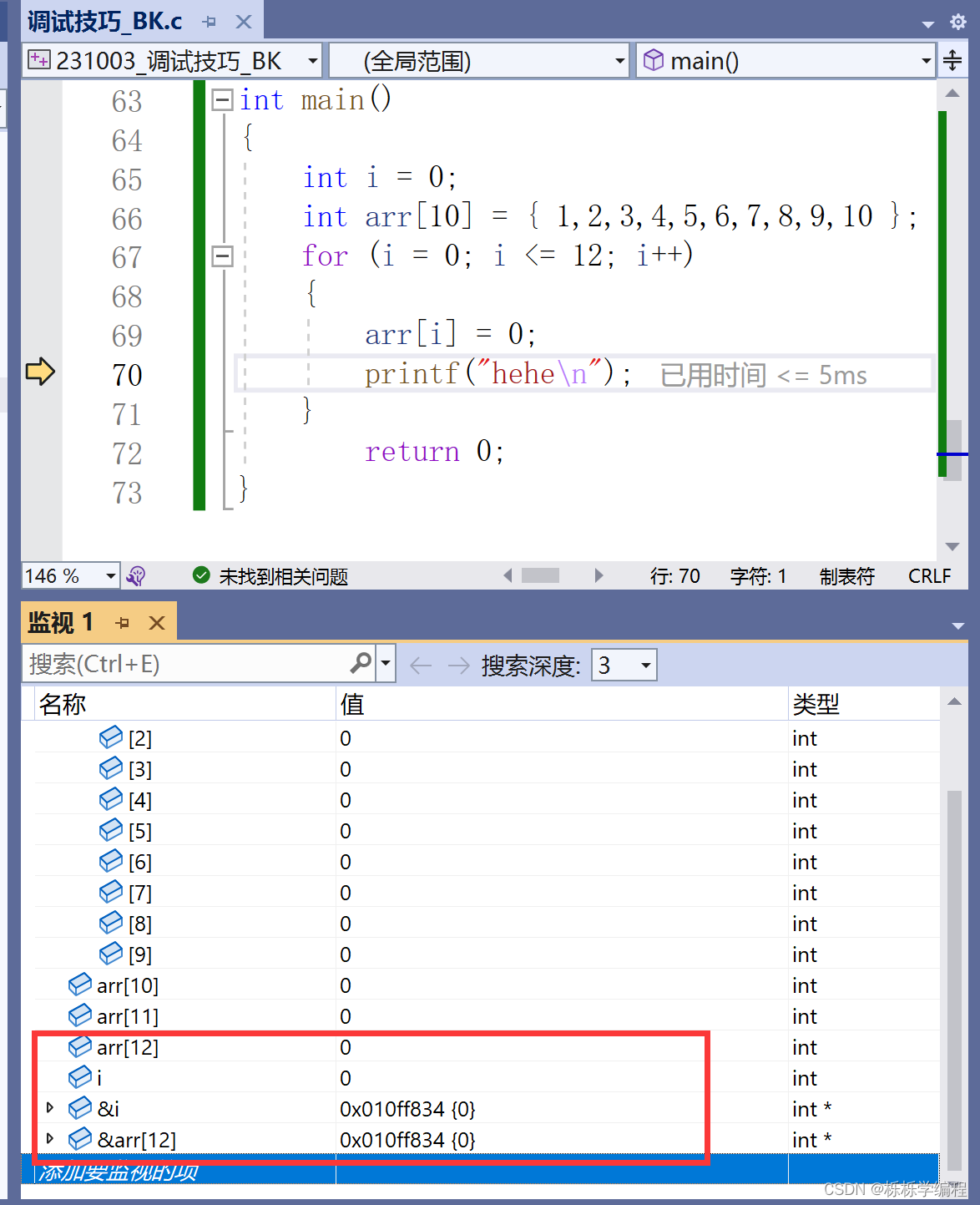
我们在调试的过程中,竟然发现,arr[12]与 i 同时发生变化,并且 arr[12]与 i 的存储地址也是一样的。
那么这里,就要讲一下这个内存的创建变量了。

- 栈区上内存使用习惯是:从高地址向低地址处使用
- 正常情况下:i 先创建,arr后创建
- i的地址一定是大于arr地址
- 数组随着下标的增长,地址是由低到高变化的
- 这个代码中i和arr之间空2个整型,完全是巧合,取决于编译器
而在Release版本中,它会自动优化,那么如何优化呢?例如下图,让其打印出在Release版本下的数组以及i的地址:

我们可以清晰地观察到 i 的地址是比 arr 数组的地址小, 所以Release版本在这样情况下,优化了两者之间的地址。
如何写出好的代码
优秀的代码
- 代码运行正常
- bug很少
- 效率高
- 可读性高
- 可维护性高
- 注释清晰
- 文档齐全
常见的coding技巧
- 使用assert断言
- 尽量使用const
- 养成良好的编码风格
- 添加必要的注释
- 避免编码的陷阱
- 编程常见的错误
实例三:模拟实现strcpy库函数
我们先学习一下这个strcpy库函数是如何使用的。
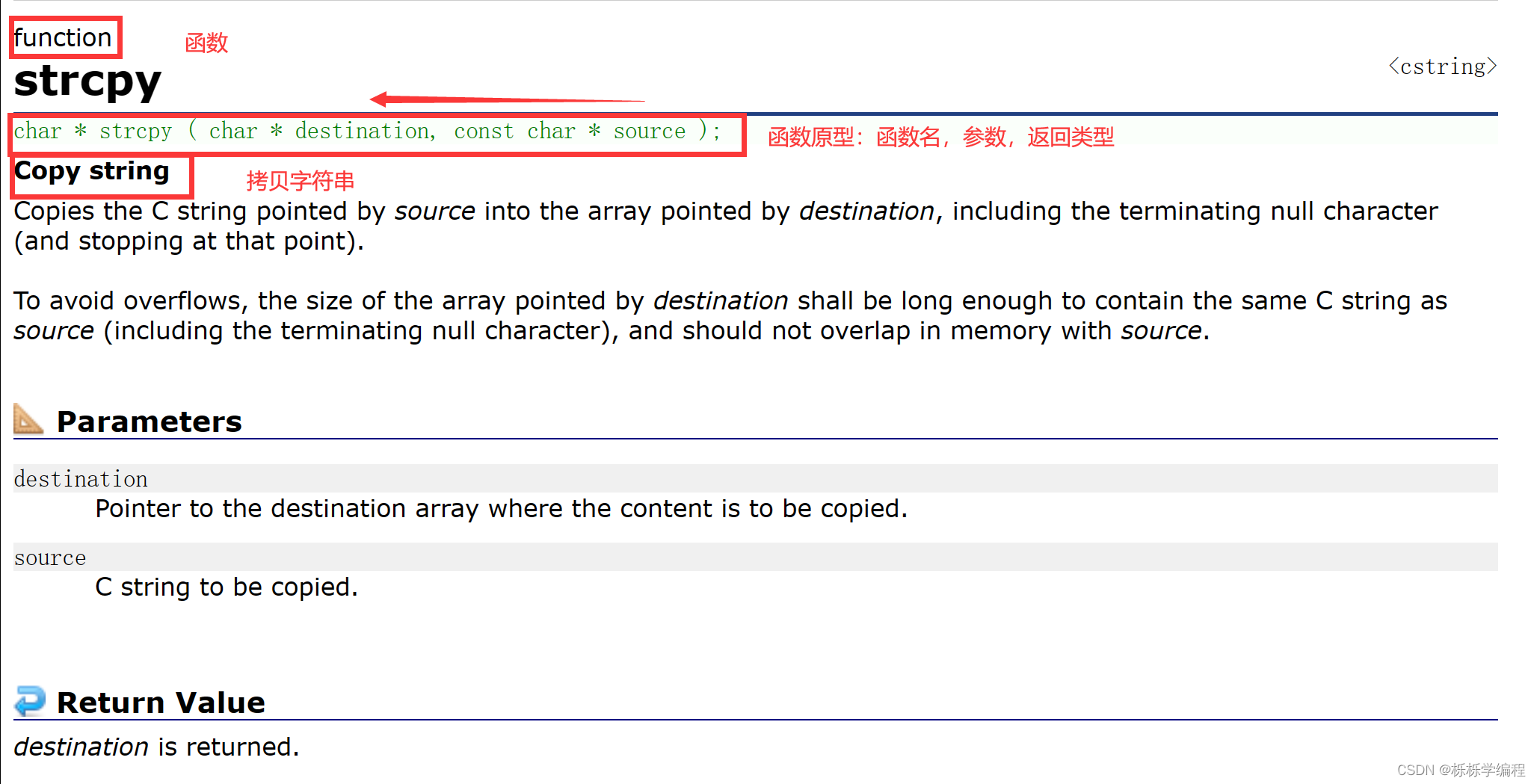
【strcpy函数】:
- function
- 函数原型:char * strcpy ( char * destination , const char * source ) ;//传参传入地址
- 函数原型:函数名、参数、返回类型
- strcpy功能:从源头拷贝到目的地
- destination is returned.将目标地址返回来
- including the terminating null character(and stopping at the point)包括‘\0’
- strcpy函数需要头文件[string.h]
- 库函数strcpy返回的是目标空间的起始地址
我们先练习一下这个函数的使用。
#include <stdio.h>
#include <string.h>
int main()
{
char arr1[20] = { 0 };
char arr2[] = "hello bit";
strcpy(arr1, arr2);
printf("%s\n", arr1);
return 0;
}模拟实现strcpy函数,假设这个新的函数命名是my_strcpy,要注意在模拟的过程中,我们的函数原型是要保持一致的,所以函数声明为void my_strcpy(char * dest , char * src);
要将是src中所有的字符串都复制到dest中,那么肯定需要遍历的方法让其循环,直到将'\0'也复制过去。
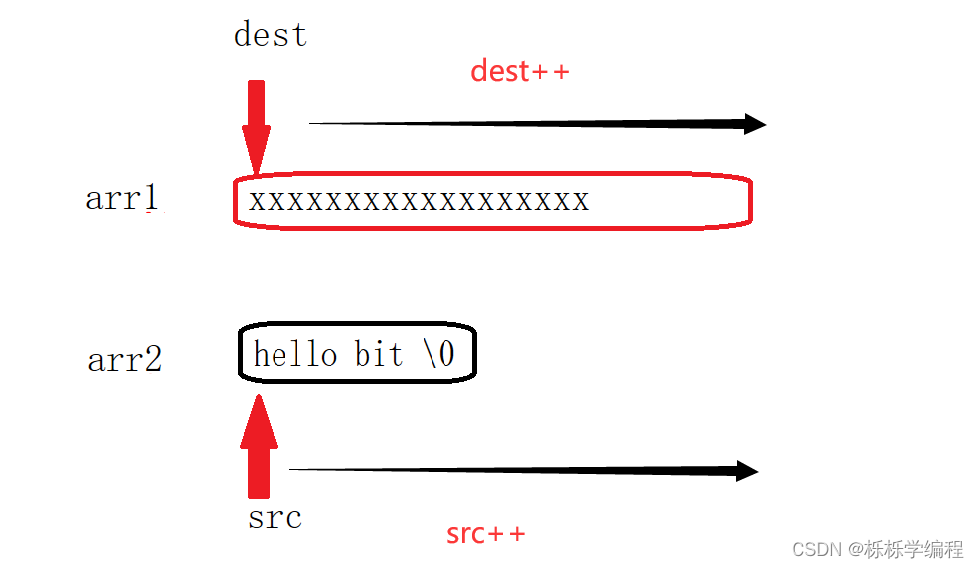
my_strcpy(char* dest, char* src)
{
//将源头的字符串拷贝到目的地的空间里面去
while (*src!='\0')
{
*dest = *src;
dest++;
src++;
}
*dest = *src;
}
int main()
{
char arr1[20] = "xxxxxxxxxxxxxxx";
char arr2[] = "hello bit";
my_strcpy(arr1, arr2);
printf("%s\n", arr1);
//打印出来arr1只是‘hello bit’,是因为‘\0’也被拷贝进去了,使其字符串结束了
return 0;
}而这里我们要注意,我们是为了写出更好的代码,所以我们再次完善上面的代码。
在上面的代码中,我们可以利用后置加加,将这个代码简化一下:
while (*src!='\0')
{
*dest++ = *src++;
//后置加加:先使用后加假
}我们可以知道,上面的代码,是分成了两次拷贝的,第一次是遇到‘\0’的时候,拷贝‘\0’之前的,另一次是拷贝‘\0’,这样这个代码并不是那么高效,我们能不能让它一次就将‘\0’也拷贝进去呢?
while (*dest++ = *src++)
//利用ASCII码值,直到将'\0'拷贝进去之后,因为'\0'的ASCII码值是0,所以为假
{
;
}在经过上面的修缮之后,我们现在的完整代码如下:
my_strcpy(char* dest, char* src)
{
while (*dest++ = *src++)
{
;
}
}
int main()
{
char arr1[20] = "xxxxxxxxxxxxxxx";
char arr2[] = "hello bit";
my_strcpy(arr1, arr2);
printf("%s\n", arr1);
return 0;
}那么如果arr1中传入了一个空指针呢?要怎么办呢?
my_strcpy(NULL, arr2);
assert断言的使用
所以我们需要判断一下,是否为空指针。判断空指针有两种方法:
第一种就是简单的if语句,但是这里就是会使得if语句一直执行,效率很低。
if(dest == NULL || src == NULL)第二种就是assert宏的使用:
- assert(条件),如果条件为假,那么程序会直接报错。
- assert的头文件:assert.h
- 在release版本中,代码会自动优化assert。
assert(dest != NULL);
assert(src != NULL);然后,要注意的是strcpy函数返回的是是目标空间的起始地址。所以如下代码:
char * my_strcpy(char* dest, char* src)
{
char * ret = dest;
assert(dest!=NULL);
assert(src!=NULL);
while (*dest++ = *src++)
{
;
}
return ret;
}
int main()
{
char arr1[20] = "xxxxxxxxxxxxxxx";
char arr2[] = "hello bit";
my_strcpy(arr1, arr2);
printf("%s\n", arr1);
return 0;
}const修饰变量
我们在这里了解一下const有什么作用:const修饰变量的时候,是在语法层面上限制了const修改。但是本质上,num还是变量,是一种不能被修改的变量。
const修饰变量
const修饰指针
我们现在用下面的例子解释:
#include<stdio.h>
int main()
{
const int num = 10;
printf("num=%d\n", num);
int* p = #
*p = 20;
printf("num=%d\n", num);
return 0;
}在这里我们需要先注意两个点:
- p是一个变量,用来存放地址
- *p是p指向的对象——num
根据上面所说的,那么我们可以知道的这里就有两种写法用来改变num的值:
int* p = #
*p = 20; //*p是p所指向的对象
int n = 1000;
p = &n; //p是一个变量,用于存放地址const放在*左边
const int* p = #
*p = 20; //error //*p是p所指向的对象
int n = 1000;
p = &n; //p是一个变量,用于存放地址当const放在*的左边,那么就限定的是*p,*p是不能被修改。
const放在*左边,限制的是指针指向的内容,也就是说:不能通过指针来修饰指针指向的内容。但是指针变量是可以修改的,也就是指针指向其他的变量。
const放在*右边
int * const p = #
*p = 20; //*p是p所指向的对象
int n = 1000;
p = &n; //error //p是一个变量,用于存放地址当const放在*的右边,那么限定的就是p,p不能被修改。
const放在*的右边,限制的是指针变量本身,指针变量不能再指向其他对象,但是可以通过指针变量修改指向的内容。
const放在*前和后
const int * const p = #
*p = 20; //error //*p是p所指向的对象
int n = 1000;
p = &n; //error //p是一个变量,用于存放地址这里两种都会报错,都不能被修改。
所以为了上面的strcpy函数中,它的源头地址里的内容,是不能被修改的,所以利用const,将上面的完善一下就是:
char * my_strcpy(char* dest, const char* src)
{
char * ret = dest;
assert(dest!=NULL);
assert(src!=NULL);
while (*dest++ = *src++)
{
;
}
return ret;
}
int main()
{
char arr1[20] = "xxxxxxxxxxxxxxx";
char arr2[] = "hello bit";
my_strcpy(arr1, arr2);
printf("%s\n", arr1);
return 0;
}实例四:模拟实现strlen函数
#include <stdio.h>
#include <assert.h>
size_t my_strlen(const char* str)
{
assert(str != NULL);
//起初让这个end末尾的值与str起始值相等
//让这个end值一直++,直到为‘\0’,结束
//让这个end-起始值-1'\0'就是strlen的长度了
const char* end = str;
while (* end++)
{
;
}
return end - str - 1;
}
int main()
{
char arr[] = "abcdef";
size_t len = my_strlen(arr);
printf("%zd\n", len);
return 0;
}编程常见的错误
编译型错误
直接看错误提示信息(双击),解决问题。或者是凭借经验就可以搞定。相对来说简单。
链接型错误
一般是标识符名不存在或者是拼写错误。
运行时错误
借助调试,逐步定位问题。也是最难搞的。
好啦~今天我们就先学到这里啦,希望大家可以帮忙纠正错误哦。祝大家国庆快乐~~~