✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。
🍎个人主页:小嗷犬的个人主页
🍊个人网站:小嗷犬的技术小站
🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。
本文目录
- imblearn 简介
- imblearn 安装
- 欠采样方法
- ClusterCentroids
- EditedNearestNeighbours
- CondensedNearestNeighbour
- AllKNN
- InstanceHardnessThreshold
- 过采样方法
- SMOTE
- SMOTE-NC
- SMOTEN
- ADASYN
- BorderlineSMOTE
- KMeansSMOTE
- SVMSMOTE
- 组合采样方法
- SMOTETomek
- SMOTEENN
- imblearn 库使用示例
- 导入库
- 查看原始数据分布
- 采样后的数据分布
- 不同采样方法的可视化对比
imblearn 简介
imblearn(全名为 imbalanced-learn )是一个用于处理不平衡数据集的 Python 库。在许多实际情况中,数据集中的类别分布可能是不均衡的,这意味着某些类别的样本数量远远超过其他类别。这可能会导致在训练机器学习模型时出现问题,因为模型可能会偏向于学习多数类别。
imblearn 库提供了一系列处理不平衡数据集的方法,包括:
- 欠采样方法:减少多数类别的样本以使其与少数类别相匹配。
- 过采样方法:通过生成合成样本来增加少数类别的样本数量,使其与多数类别相匹配。
- 组合采样方法:结合了欠采样和过采样的技术,以获得更好的平衡。
imblearn 库包含了许多常用的不平衡数据处理算法,例如SMOTE(Synthetic Minority Over-sampling Technique)、Tomek Links、RandomUnderSampler、RandomOverSampler 等等。
这个库对于处理各种类型的不平衡数据问题非常有用,可以提升在这类数据上训练模型的性能。
imblearn 安装
imblearn 库可以通过 pip 安装:
pip install imblearn
欠采样方法
欠采样方法通过减少多数类别的样本数量来平衡数据集。这些方法通常用于处理大型数据集,因为它们可以减少数据集的大小。
下面我们将介绍 imblearn 库中的一些常用欠采样方法。
ClusterCentroids
ClusterCentroids 是一种欠采样方法,它通过聚类算法来减少多数类别的样本数量。它通过将多数类别的样本聚类为多个簇,然后对每个簇选择其中心作为新的样本来实现。
具体来说,ClusterCentroids 采取以下步骤:
- 将多数类别的样本分成几个簇(clusters)。
- 对于每个簇,选择其中心点作为代表样本。
- 最终的训练集将包含所有少数类别样本以及选定的多数类别样本中心点。
EditedNearestNeighbours
EditedNearestNeighbours (简称 ENN)是一种欠采样方法,它通过删除多数类别中的异常值来减少多数类别的样本数量。它通过以下步骤实现:
- 对于每一个多数类别的样本,找到它的 k 个最近邻居(根据指定的距离度量)。
- 如果多数类别的样本的大多数最近邻居属于与它不同的类别(即多数类别样本的大多数邻居属于少数类别),则将该样本移除。
CondensedNearestNeighbour
CondensedNearestNeighbour 是一种欠采样方法,它通过选择多数类别样本的子集来减少多数类别的样本数量。它通过以下步骤实现:
- 将少数类别的样本全部保留在训练集中。
- 逐一考察多数类别的样本。对于每一个多数类别的样本,找到它的k个最近邻居(根据指定的距离度量)。
- 如果多数类别的样本能够被少数类别样本所代表,即该多数类别样本的最近邻居中存在少数类别样本,则将该多数类别样本移除。
AllKNN
AllKNN 是一种欠采样方法,它在执行时会多次应用 ENN(Edited Nearest Neighbours)算法,并在每次迭代时逐步增加最近邻的数量。
AllKNN 通过多次应用 ENN,并逐步增加最近邻的数量,可以更加彻底地清除位于类别边界附近的噪声样本。
InstanceHardnessThreshold
InstanceHardnessThreshold 是一种欠采样方法,它通过计算每个样本的难度分数来减少多数类别的样本数量。它通过以下步骤实现:
- 计算多数类别中每个样本的难度分数。
- 剔除难度分数低于指定阈值的样本。
- 将剩余样本与少数类别的样本组合成新的训练集。
过采样方法
过采样方法通过生成合成样本来增加少数类别的样本数量,使其与多数类别相匹配。这些方法通常用于处理小型数据集,因为它们可以增加数据集的大小。
下面我们将介绍 imblearn 库中的一些常用过采样方法。
SMOTE
SMOTE(Synthetic Minority Over-sampling Technique)是一种过采样方法,它通过生成合成样本来增加少数类别的样本数量,使其与多数类别相匹配。
SMOTE 的原理基于对少数类样本的插值。具体而言,它首先随机选择一个少数类样本作为起始点,然后从该样本的近邻中随机选择一个样本作为参考点。然后,SMOTE 通过在这两个样本之间的线段上生成新的合成样本来增加数据集的样本数量。
SMOTE-NC
SMOTE-NC(SMOTE for Nominal and Continuous features)是一种用于处理同时包含数值和分类特征的数据集的过采样方法。它是对传统的 SMOTE 算法的扩展,能够处理同时存在数值和分类特征的情况,但不适用于仅包含分类特征的数据集。
SMOTE-NC 的原理与 SMOTE 类似,但在生成合成样本时有所不同。它的生成过程如下:
- 对于选定的起始点和参考点,计算它们之间的差距,得到一个向量。
- 将连续特征(数值特征)的差距乘以一个随机数,得到新样本的位置。这一步与传统的 SMOTE 相同。
- 对于分类特征,随机选择起始点或参考点的特征值作为新合成样本的特征值。
- 对于连续特征和分类特征,分别使用插值和随机选择的方式来生成新样本的特征值。
通过这种方式,SMOTE-NC 能够处理同时包含数值和分类特征的数据集,并生成新的合成样本来增加少数类样本的数量。这样可以在平衡数据集的同时保持数值和分类特征的一致性。
SMOTEN
SMOTEN(Synthetic Minority Over-sampling Technique for Nominal)是一种专门针对分类特征的过采样方法,用于解决类别不平衡问题。它是对 SMOTE 算法的扩展,适用于仅包含分类特征的数据集。
SMOTEN 的原理与 SMOTE 类似,但在生成合成样本时有所不同。它的生成过程如下:
- 对于选定的起始点和参考点,计算它们之间的差距,得到一个向量。
- 对于每个分类特征,统计起始点和参考点之间相应特征的唯一值(类别)的频率。
- 根据特征的频率,确定新样本的位置。具体而言,对于每个分类特征,随机选择一个起始点或参考点的类别,并在该类别中随机选择一个值作为新合成样本的特征值。
- 对于连续特征,采用传统的 SMOTE 方式,通过在差距向量上乘以一个随机数,确定新样本的位置,并使用插值来生成新样本的特征值。
ADASYN
ADASYN(Adaptive Synthetic)是一种基于自适应合成的过采样算法。它与 SMOTE 方法相似,但根据类别的局部分布估计生成不同数量的样本。
ADASYN 根据样本之间的差距,计算每个样本的密度因子。密度因子表示该样本周围少数类样本的密度。较低的密度因子表示该样本所属的区域缺乏少数类样本,而较高的密度因子表示该样本周围有更多的少数类样本。
BorderlineSMOTE
BorderlineSMOTE(边界 SMOTE)是一种过采样算法,是对原始 SMOTE 算法的改进和扩展。它能够检测并利用边界样本生成新的合成样本,以解决类别不平衡问题。
BorderlineSMOTE 在 SMOTE 算法的基础上进行了改进,通过识别边界样本来更有针对性地生成新的合成样本。边界样本是指那些位于多数类样本和少数类样本之间的样本,它们往往是难以分类的样本。通过识别并处理这些边界样本,BorderlineSMOTE 能够提高分类器对难以分类样本的识别能力。
KMeansSMOTE
KMeansSMOTE 的关键在于使用 KMeans 聚类将数据样本划分为不同的簇,并通过识别边界样本来有针对性地进行合成样本的生成。这种方法可以提高合成样本的多样性和真实性,因为它仅在边界样本周围进行过采样,而不是在整个少数类样本集上进行。
SVMSMOTE
SVMSMOTE 是一种基于 SMOTE 算法的变体,其特点是利用支持向量机(SVM)算法来检测用于生成新的合成样本的样本。通过将数据集中的少数类样本划分为支持向量和非支持向量,SVMSMOTE 能够更准确地选择样本进行合成。对于每个少数类支持向量,它选择其最近邻中的一个作为参考点,并通过计算其与参考点之间的差距来生成新的合成样本。
组合采样方法
组合采样方法结合了欠采样和过采样的技术,以获得更好的平衡。
下面我们将介绍 imblearn 库中的一些常用组合采样方法。
SMOTETomek
SMOTETomek 是一种组合采样方法,它结合了 SMOTE 和 Tomek Links 算法。Tomek Links 是一种欠采样方法,它通过删除多数类别样本和少数类别样本之间的边界样本来减少多数类别的样本数量。
SMOTETomek 通过结合 SMOTE 和 Tomek Links 算法,能够同时处理多数类别和少数类别的样本,以获得更好的平衡。
SMOTEENN
SMOTEENN 是一种组合采样方法,它结合了 SMOTE 和 ENN 算法。
相比于 SMOTETomek,由于 SMOTEENN 结合了 ENN 算法,因此它能够更容易地清除位于类别边界附近的噪声样本。
imblearn 库使用示例
下面我们将通过一个示例来演示 imblearn 库的使用。
导入库
首先,我们需要导入一些需要用到的库:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_breast_cancer # sklearn 乳腺癌数据集
from imblearn.under_sampling import ClusterCentroids, EditedNearestNeighbours
from imblearn.over_sampling import SMOTE, ADASYN
from imblearn.combine import SMOTEENN, SMOTETomek
查看原始数据分布
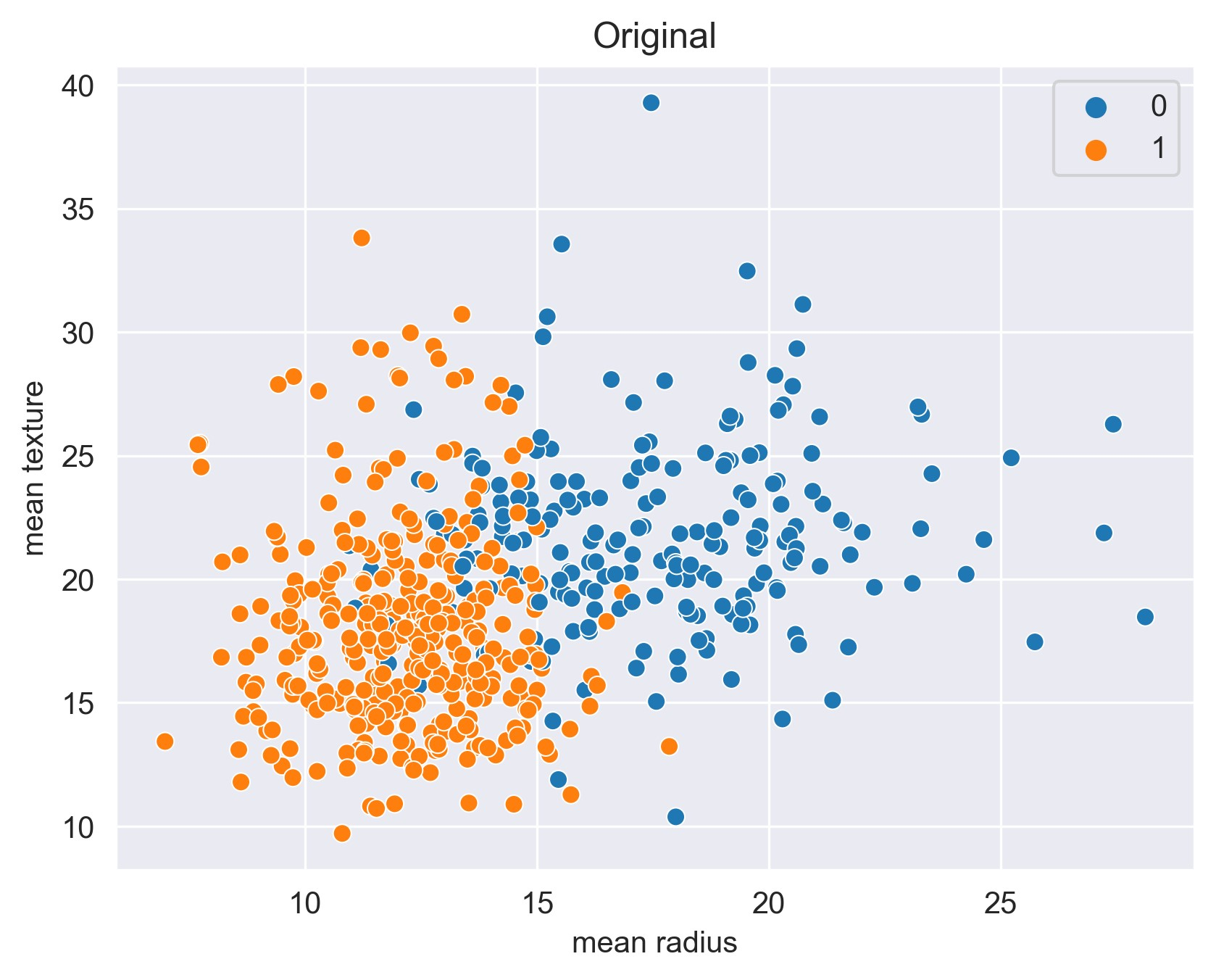
我们使用 sklearn 自带的乳腺癌数据集作为示例数据集。首先,我们导入数据集,并查看数据集的基本信息:
data = load_breast_cancer()
X = data.data
y = data.target
print(f"类别为 0 的样本数: {X[y == 0].shape[0]}, 类别为 1 的样本数: {X[y == 1].shape[0]}")
sns.set_style("darkgrid")
sns.scatterplot(data=data, x=X[:, 0], y=X[:, 1], hue=y)
plt.xlabel(f"{data.feature_names[0]}")
plt.ylabel(f"{data.feature_names[1]}")
plt.title("Original")
plt.show()
输出结果如下:
类别为 0 的样本数: 212, 类别为 1 的样本数: 357
采样后的数据分布
接下来,我们使用 imblearn 库中的一些采样方法来处理数据集,以获得更好的平衡。
data = load_breast_cancer()
X = data.data
y = data.target
sampler1 = ClusterCentroids(random_state=0)
sampler2 = EditedNearestNeighbours()
sampler3 = SMOTE(random_state=0)
sampler4 = ADASYN(random_state=0)
sampler5 = SMOTEENN(random_state=0)
sampler6 = SMOTETomek(random_state=0)
X1, y1 = sampler1.fit_resample(X, y)
X2, y2 = sampler2.fit_resample(X, y)
X3, y3 = sampler3.fit_resample(X, y)
X4, y4 = sampler4.fit_resample(X, y)
X5, y5 = sampler5.fit_resample(X, y)
X6, y6 = sampler6.fit_resample(X, y)
print(
f"ClusterCentroids: 类别为 0 的样本数: {X1[y1 == 0].shape[0]}, 类别为 1 的样本数: {X1[y1 == 1].shape[0]}"
)
print(
f"EditedNearestNeighbours: 类别为 0 的样本数: {X2[y2 == 0].shape[0]}, 类别为 1 的样本数: {X2[y2 == 1].shape[0]}"
)
print(
f"SMOTE: 类别为 0 的样本数: {X3[y3 == 0].shape[0]}, 类别为 1 的样本数: {X3[y3 == 1].shape[0]}"
)
print(
f"ADASYN: 类别为 0 的样本数: {X4[y4 == 0].shape[0]}, 类别为 1 的样本数: {X4[y4 == 1].shape[0]}"
)
print(
f"SMOTEENN: 类别为 0 的样本数: {X5[y5 == 0].shape[0]}, 类别为 1 的样本数: {X5[y5 == 1].shape[0]}"
)
print(
f"SMOTETomek: 类别为 0 的样本数: {X6[y6 == 0].shape[0]}, 类别为 1 的样本数: {X6[y6 == 1].shape[0]}"
)
输出结果如下:
ClusterCentroids: 类别为 0 的样本数: 212, 类别为 1 的样本数: 212
EditedNearestNeighbours: 类别为 0 的样本数: 212, 类别为 1 的样本数: 320
SMOTE: 类别为 0 的样本数: 357, 类别为 1 的样本数: 357
ADASYN: 类别为 0 的样本数: 358, 类别为 1 的样本数: 357
SMOTEENN: 类别为 0 的样本数: 304, 类别为 1 的样本数: 313
SMOTETomek: 类别为 0 的样本数: 349, 类别为 1 的样本数: 349
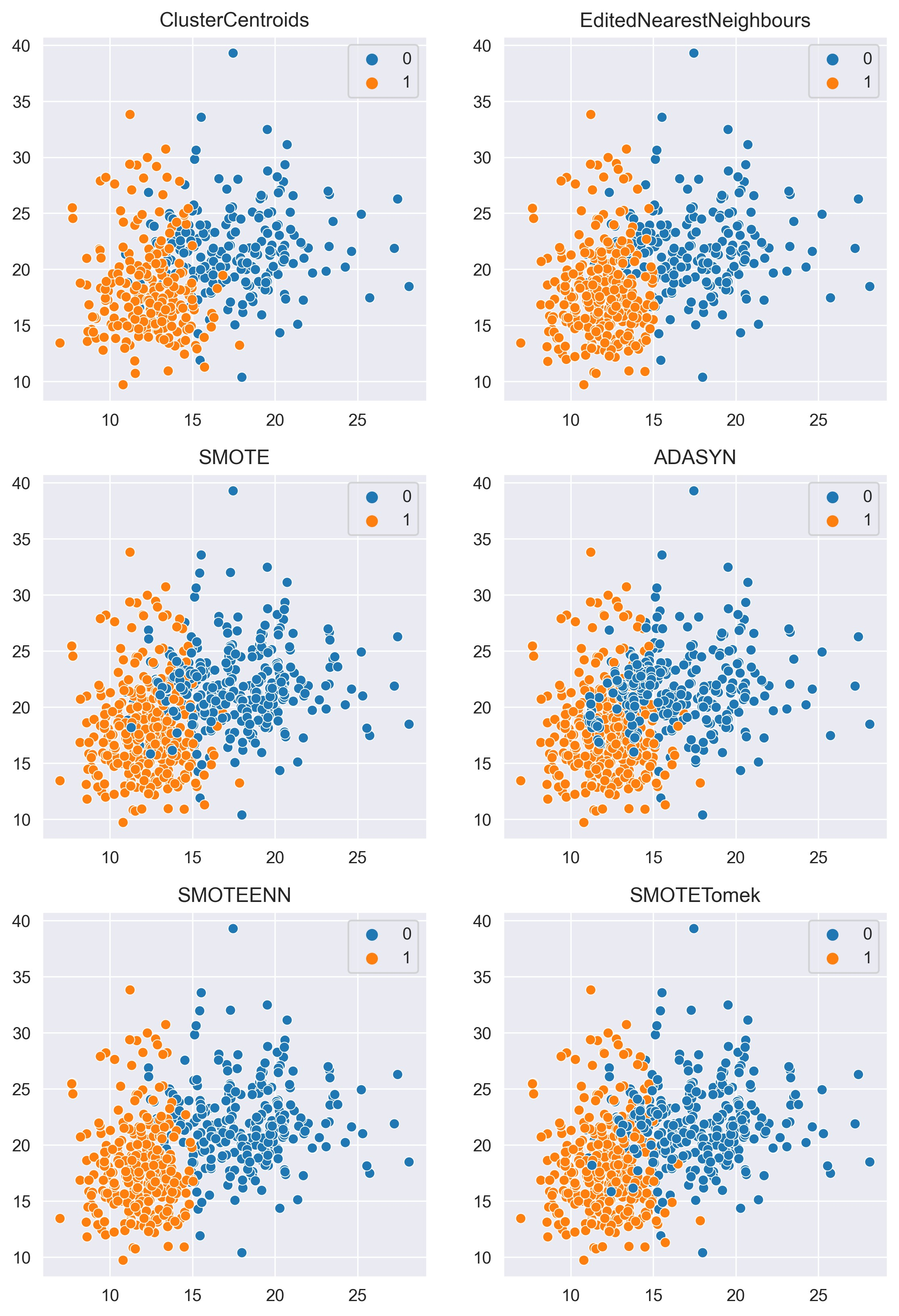
不同采样方法的可视化对比
下面我们将使用 matplotlib 和 seaborn 库来可视化不同采样方法的效果。
sns.set_style("darkgrid")
plt.figure(figsize=(9, 18))
plt.subplot(4, 2, 1)
sns.scatterplot(data=data, x=X1[:, 0], y=X1[:, 1], hue=y1)
plt.title("ClusterCentroids")
plt.subplot(4, 2, 2)
sns.scatterplot(data=data, x=X2[:, 0], y=X2[:, 1], hue=y2)
plt.title("EditedNearestNeighbours")
plt.subplot(4, 2, 3)
sns.scatterplot(data=data, x=X3[:, 0], y=X3[:, 1], hue=y3)
plt.title("SMOTE")
plt.subplot(4, 2, 4)
sns.scatterplot(data=data, x=X4[:, 0], y=X4[:, 1], hue=y4)
plt.title("ADASYN")
plt.subplot(4, 2, 5)
sns.scatterplot(data=data, x=X5[:, 0], y=X5[:, 1], hue=y5)
plt.title("SMOTEENN")
plt.subplot(4, 2, 6)
sns.scatterplot(data=data, x=X6[:, 0], y=X6[:, 1], hue=y6)
plt.title("SMOTETomek")
plt.show()
对比结果如下:





![[sping] spring core - 依赖注入](https://img-blog.csdnimg.cn/a3c76dc697604e5bb00837dc50493e10.png)