Overview
低资源下的命名实体识别主要分为两个方面,一种是in-domain下的N-way-K-shot类型的少样本,一种是cross-domain下现在资源丰富的sourc-domain上进行微调,之后再迁移到低资源的target-domain进一步微调。
基于prompt的方法在少样本分类的任务中取得了不错的效果(这里的效果不错一定程度上指的是基于微调的方法需要修改模型的结构来增加新的预测类别,而prompt只需要加上新的回答词即可,因为prompt是基于LM head来预测的)。但是在token-level的任务中却存在着天生的缺陷,对于一个句子,prompt需要枚举句子中所有的span,然后对其进行prompt组装预测。这种方法在较短的句子中或许可行,但在文档级别的任务中,却遇到了灾难性的问题,随着句子长度的变长,需要枚举的span成指数上升。这使得prompt在命名实体识别的任务中困难重重。
Prompt在命名实体识别中通常会有三方面的任务。一是在标准的全监督设置下进行性能的测试。二是在in-domain的情况下对每种类型的实体,选择K个实例,研究其在少样本下的性能。三是在cross-domain(domain adaptation)下的应用,其在source domain下进行预训练,之后在target domain下根据N-way-K-shot的规则选择一定的语料进行adaptation。如今流行的方法是使用prompt来进行in-domain和cross-domain下的任务,然后进行性能地比较。有趣地是prompt作为一种弥补预训练和fine-tune之间gap的一种方式,理应比fine-tune取得更高的性能,然而在全监督地情况下却无法和fine-tune进行相比,这是counter-intuitive的。
值得注意的是,在现实场景中少样本的情况下,应当只有训练集和测试集。我感觉这是现在做的不好的一个点,都少样本了为什么还会有开发集的存在。显然这不是一个合理的场景或者不是一个合理的应用诉求。这点《Template-free Prompt Tuning for Few-shot NER》做得很好,他们使用了最后一个epoch的模型作为推理的模型。
还有一个值得关注的问题,如今的少样本的训练集都是作者自己选取的,不同的实验或论文中提到的数据集都是不一样的,难以形成一个benchmark,不清楚大家为什么不在fewnerd的数据集上做实验,可以方便的进行比较。同时,这种自行选取的数据集在很大程度上会影响实验的性能,且由于在少样本的情况下进行实验,有时候一个轻微的改动,例如随机数的变化都会很大程度上影响实验的最终效果。这使得我们难以有效的判断每种方法的有效性。
原型网络在少样本的情况下取得了不错的效果,但是当遇到少样本的情况,个人感觉原型网络的表示能力是不够的,对少数的几个实体类型进行表示再泛化到没见过的实体上面取得的性能真的好吗?
元学习在少样本的情况下确实取得了很高的性能,但是其需要不断地学习,这种方法比较time-cousming、labor-intensive 并且一定程度上是expensive的。
一、Template-based Named Entity Recognition Using BART(TemplateNER,ACL2021)
Descriptions:
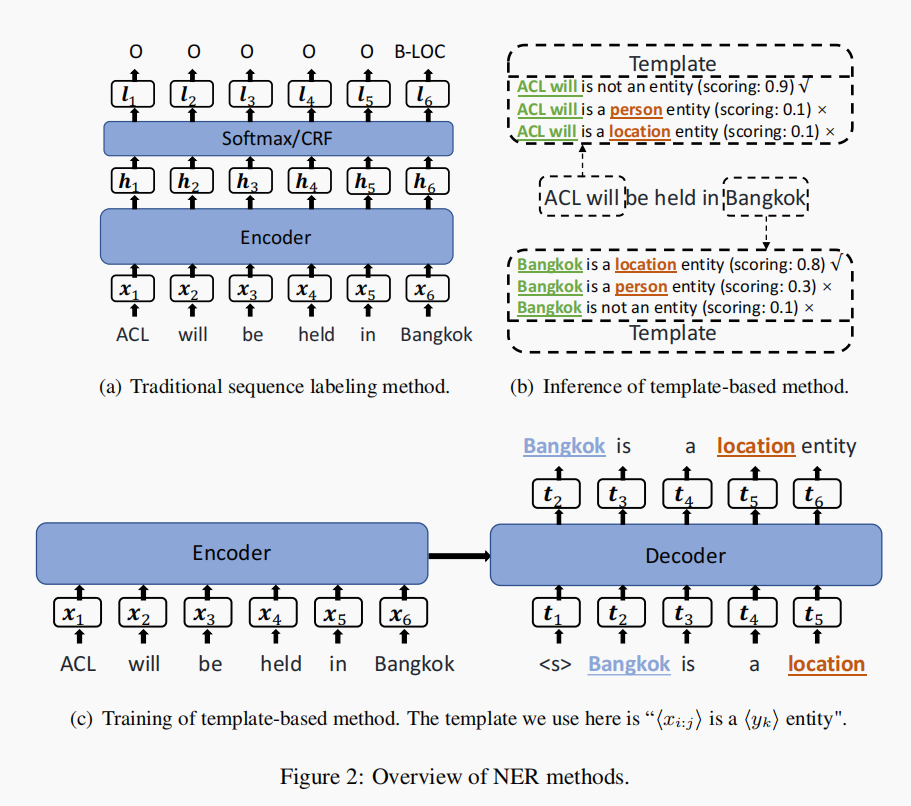
本文提出了使用prompt基于BART研究NER在少样本情况下的性能。在训练时,在编码中输入原始文本,在解码器中输入实体和实体类型构成的prompt。由于需要枚举所有的span造成复杂度的上升,本文仅仅对glod-label的实体和非gold-label的实体负采样进行训练,在训练时通过减小损失函数来使模型拟合。在推理的时候,需要枚举所有的span和实体类型进行组合放入到解码器中,进行打分,注意这里的打分是根据损失函数来看的,这里使用的损失函数是训练时使用损失函数的相反数,也就是在前面加了一个负号,他们选择分数最高的模板作为当前span的实体类型。本文中没有对嵌入实体进行处理,如果出现了嵌入实体的情况,他们会选择分数最高的那个实体作为gold实体类型。
Advantages:
相比传统的基于metric的少样本方法,本文在cross-domain的任务中并不需要source-domain的数据,即可直接进行,这metric-based的方法所做不到的。
Disadvantages:
训练时枚举了所有的片段复杂度比较高。
推理时枚举了所有的片段和实体类型组合,这在多分类和长文本的场景下不太现实,为什么不直接使用生成的方式呢?
这里对非实体类型的模板使用了不一样的模板类型,还是和前面一样的问题,为什么不使用统一的模板进行生成呢?
本文中在训练时对语料进行了负采样,看了下代码中的负采样语料,发现非实体的片段只占了一小部分,这和推理时实体和非实体片段的分布是不一致的,这种方法合理吗?
Results:
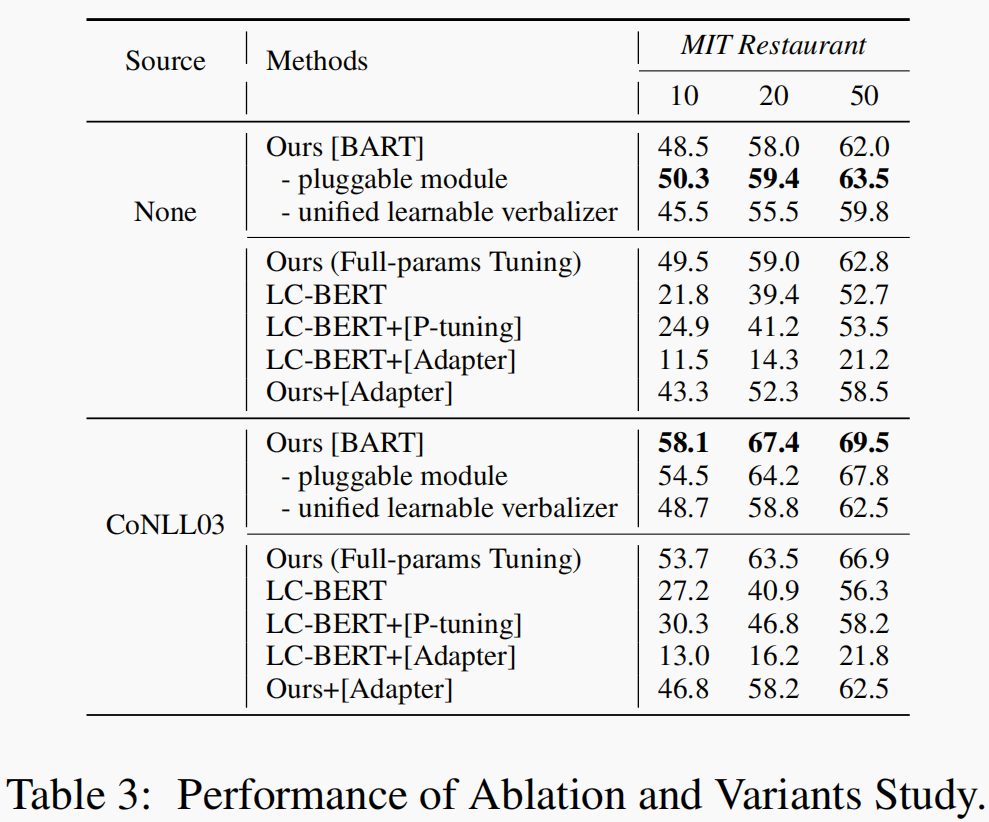
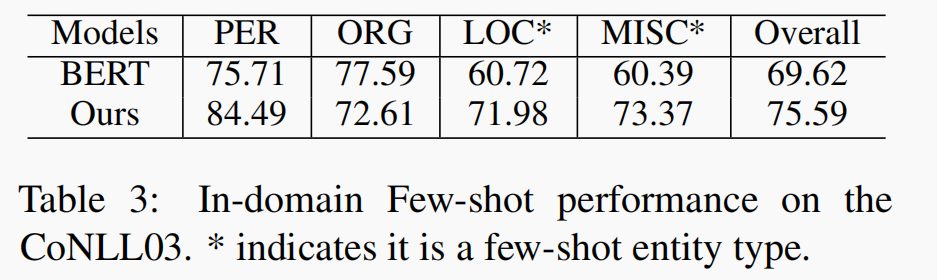
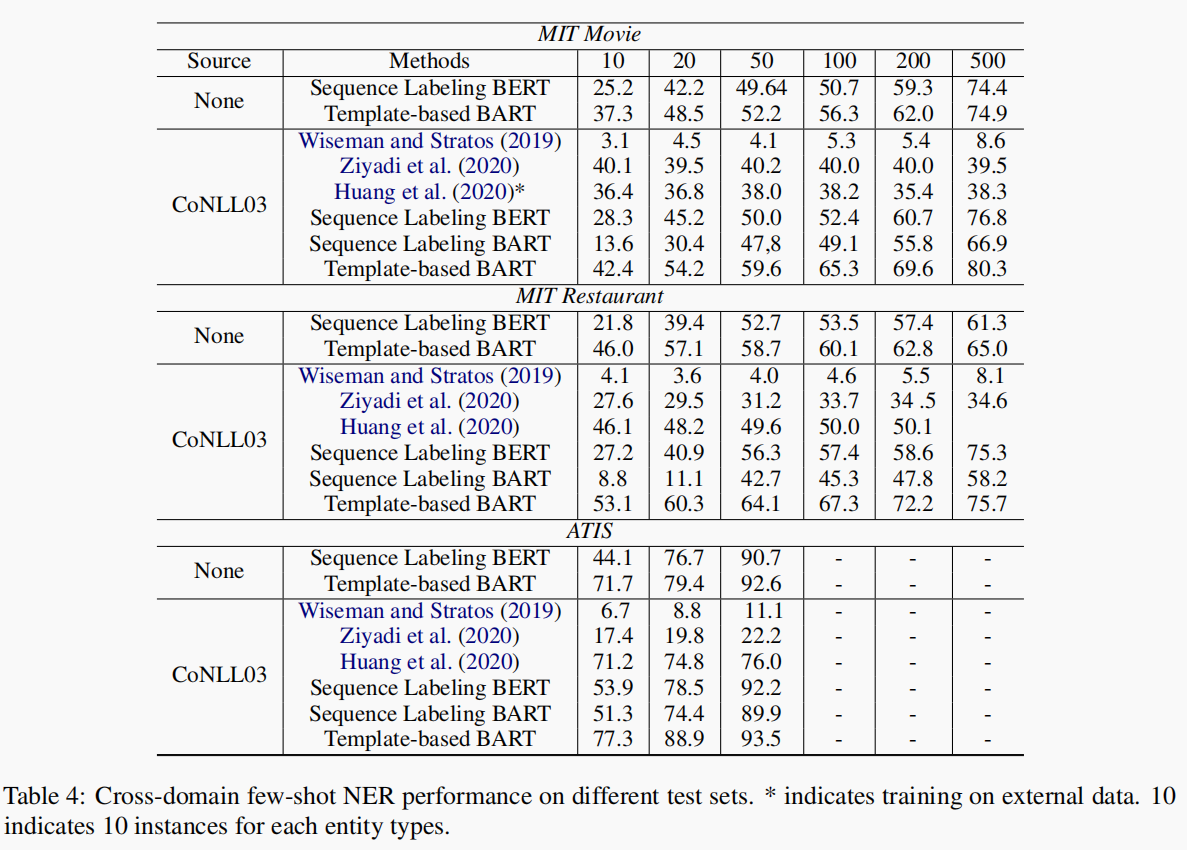
本文在in-domain的设置下仅仅对四种类型实体中的两种使用了少样本设置,实验结果如下表,带*的表示少样本类别。
二、Template-free Prompt Tuning for Few-shot NER(EntLM,NAACL2022)
Descriptions:
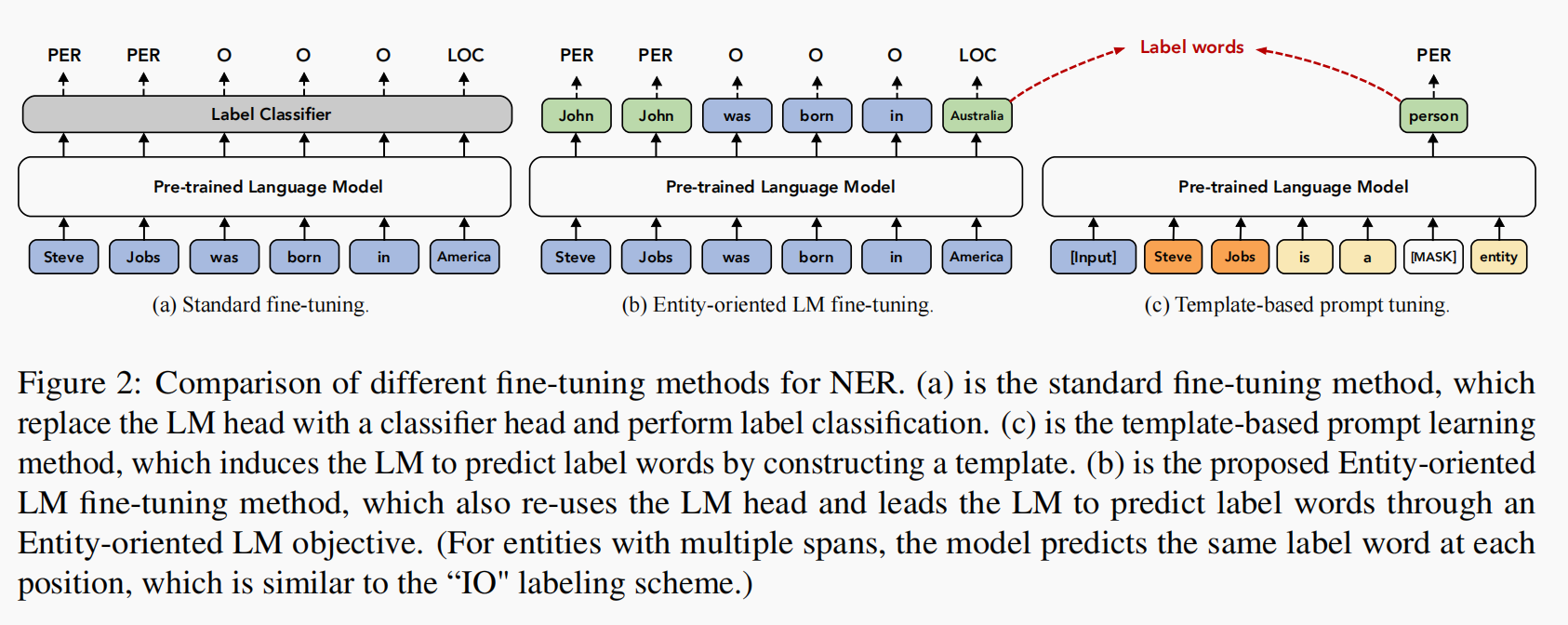
本文提出了一种无需模板的prompt的方式来进行少样本下的命名实体识别任务,实验结果显示这种方法对任务的性能有很大程度地提升,是一种effective and efficient的方法。本文提出的方法优点类似于序列标注,但和序列标注不同的是,这里仍然采用的是lm head进行标签词的生成。本文在实体的位置输出其标签词,标签词后面介绍,本文用了大量的工作来进行标签词工程。在非实体的位置输出其单词本身。最终结果显示这种方法对比之前的方法有显著性的提升,而且推理和训练的速度是其他系统无法比拟的。
本文提出了三种标签词的搜索方法。由于少样本的情况下无法选择到好的标签词,基于少量样本得到的标签词很可能是sub-optimal的。所以本文使用无标签数据和基于词典的标注作为标签词搜索的resource。为了通过实体词典获取实体标注,他们采用了基于知识库匹配的方法,主要利用率额外的知识库,wikidata,作为词典标注的来源。这种基于词汇的注释不可避免地会产生噪声。然而,我们的方法并没有受到噪声的影响,因为我们只把它看作是数据分布的指示,而没有直接用噪声注释来训练模型。
通过无标签数据和基于词典的方法得到了标签词的resource。本文使用了三种不同的标签词搜索方法,一种是基于数据分布(Data Search)的方法,即对于每个类找出频率最高的词作为标签词。第二种是通过将输入和候选标签词放入到语言模型中,得到每个位置上词表中每个词的概率分布,然后选取出现最大频率词作为标签词,这里的放入语言模型中没太理解,这是放入到fine-tune之后的语言模型吗?感觉没交代清楚。第三种是把前面两种方法结合起来找到最大频率的词作为标签词。同时,为了防止一些词作为标签词同时出现在两个类别中,作者使用阈值的方法对其进行了过滤,以防止出现重复词。
Advantages:
本文提出的方法是一种effective and efficient的方法。其在少样本情况下的性能,以及解码的速度方面远超于其他同类系统。
作者在目标词的选择方面做了大量的工作。
实验方法设置比较合理,尤其在少样本情况下,选择了最后一个epoch的模型作为推理模型。
本文使用了类似于IO的标签方式,如果使用BIO会进一步减少样本的数量(原以为IO不好,没想到既是缺点也是优点,funny)。
Disadvantages:
作者在标签工程中做了大量的实验,其中不同的标签工程方法性能之间存在较大的差异性,很难证明是作者提出方法的有效性。
本文仅使用了IO的标签方式,这使得在遇到连续的两个实体时,不能很好地解决实体边界地问题。
作者在和其他系统进行对比时,原论文中可能并没有涉及到对应k-shot地实验结果,不知道是怎么进行对比的呢?
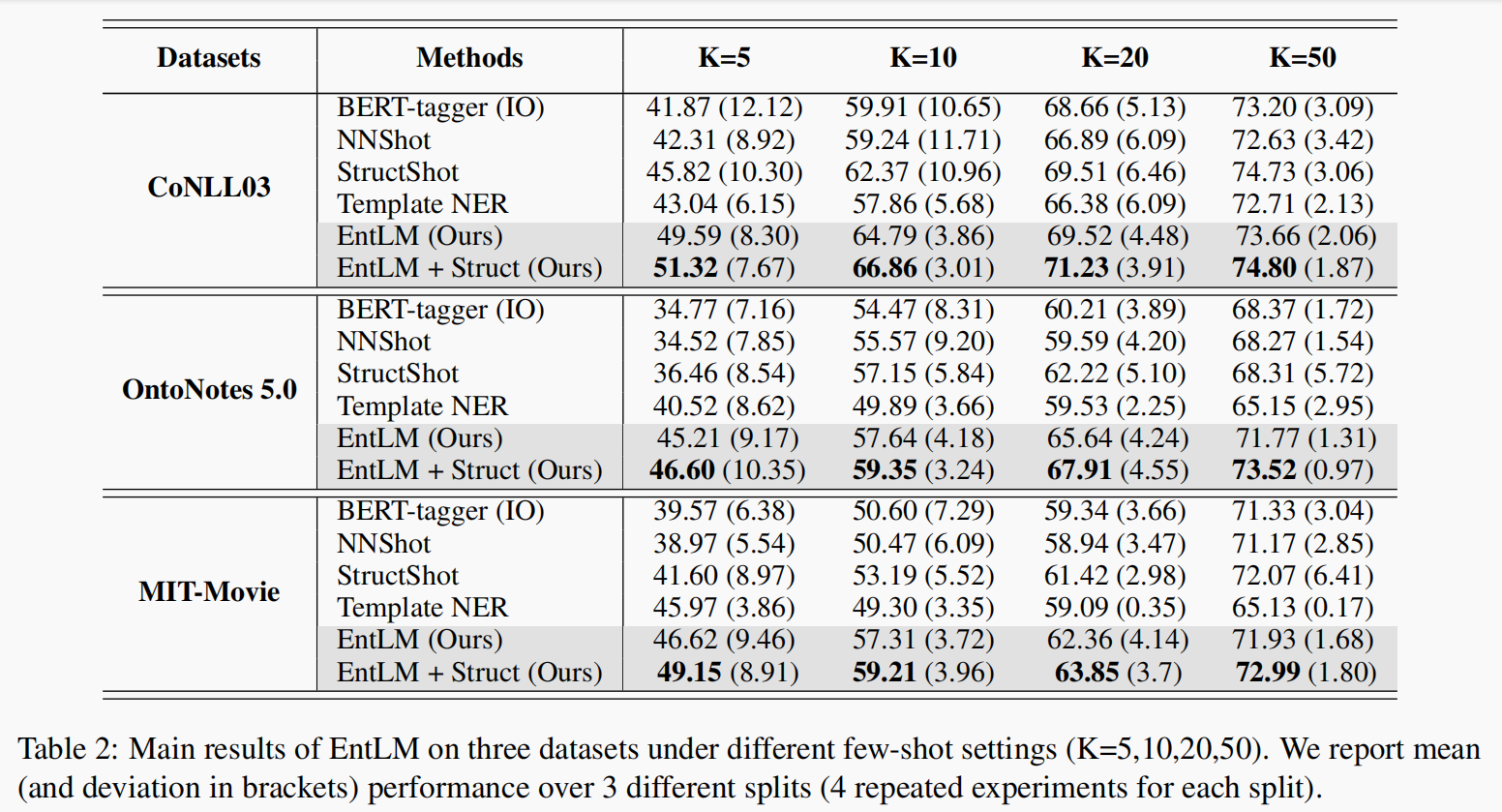
还有一个问题是我在复现的时候完全无法达到文章中所显示地性能,性能相差较大(conll03在5-shot情况下的性能为43.xx)。
Results:
三、Good Examples Make A Faster Learner Simple Demonstration-based Learning for Low-Resource NER(ACL2022)
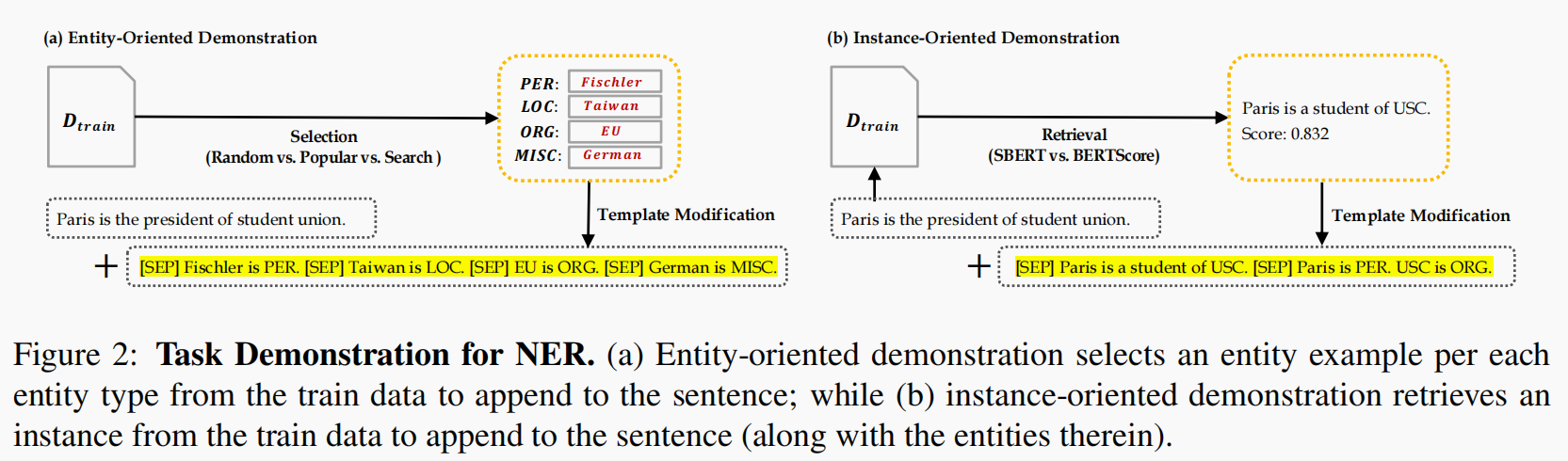
Descriptions:
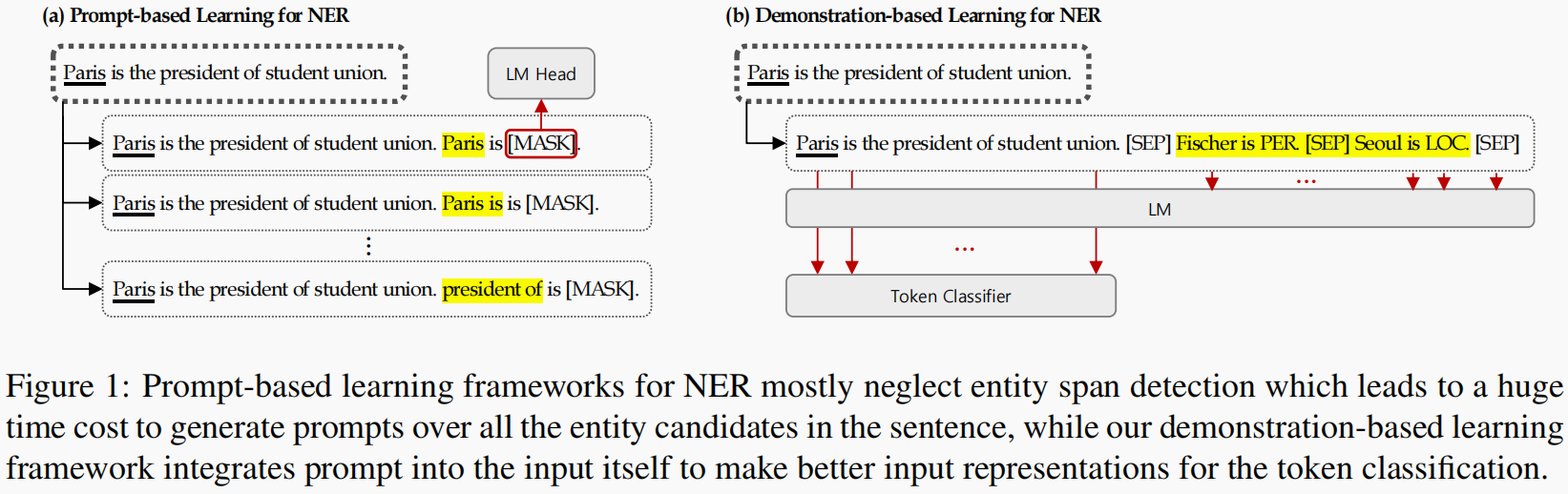
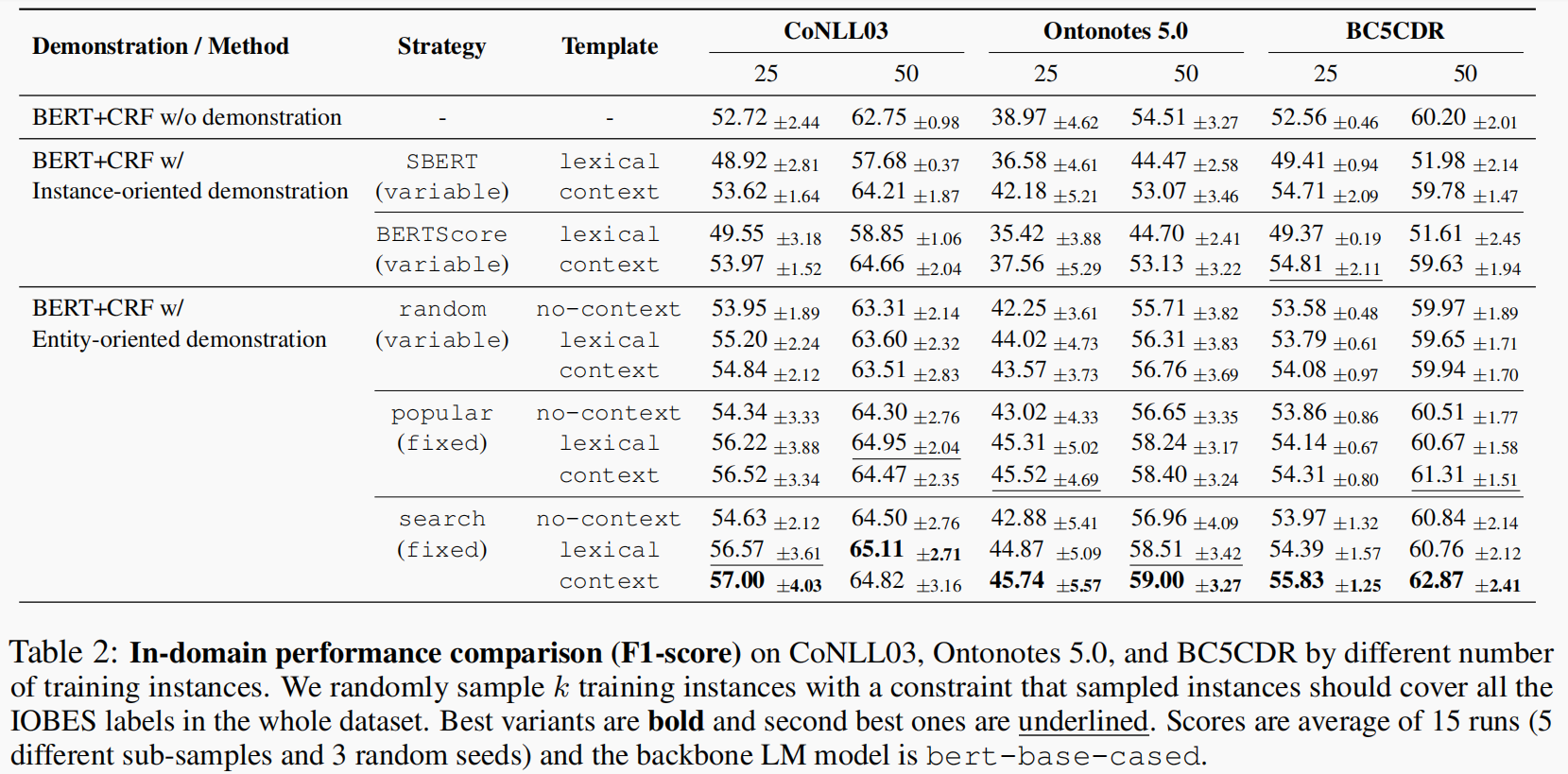
本文提出说基于prompt的方法需要高代价的枚举所有的span,同时也会忽略句子中token label之间的内在依赖关系(这种依赖关系是指在prompt模板的过程中仅对当前的一个span进行识别吗?但是前面的原始句子也会被编码器理解啊,这里没太理解)。本文提出使用基于demonstrations的in-context leanring方法在少样本的情况下进行使用。作者分别在in-domain和label sharing和different labels的cross-domain下进行评测。作者认为这种基于demonstrations能添加先验知识的同时也可以诱导出模型本身的知识(即更好的表征)。作者分别使用了两种不同的demonstrations方法,分别是面向实体的demonstration,面向实例的demonstration。这种面向实体的demonstrations实际上就是选择较好的一个example,作者用了三种方法来选择,分别是随机选择,根据频率选择以及网格搜索每个标签可能的实体候选,他们选择k个可能的实体候选然后在开发集中选择出效果最好的那个用于测试集。而面向实例的demonstrations就是根据当前输入的句子从训练集中搜索有助于当前句子的example。他们使用了SBERT和BERTScore作为检索的策略,SBERT通过计算两个句子的语义相似性来选择对应的demonstrations。BERTScore通过计算两个句子中token表征的相似性。SBERT可能会检索出句子相似,但是句子中不包含有对应的命名实体。最后他们将策略分为固定的和变化的demonstrations,固定的是popular和search,变化的是random,SBERT以及BERTScore。
Advantages:
本文提出了基于demonstrations的少样本命名实体识别方法,可以省去大量的模板设计工作。同时他们提出的策略相比传统的fine-tune方法有效的解决了few-shot NER问题。
Disadvantages:
本文提出的方法相比基于prompt的方法仍然是不够有效的。但是本文提出的方法为解决少样本NER问题提供了一个新的视角。
Results:
四、LightNER:A Lightweight Tuning Paradigm for Low-resource NER via Pluggable Prompting(COLING2022)
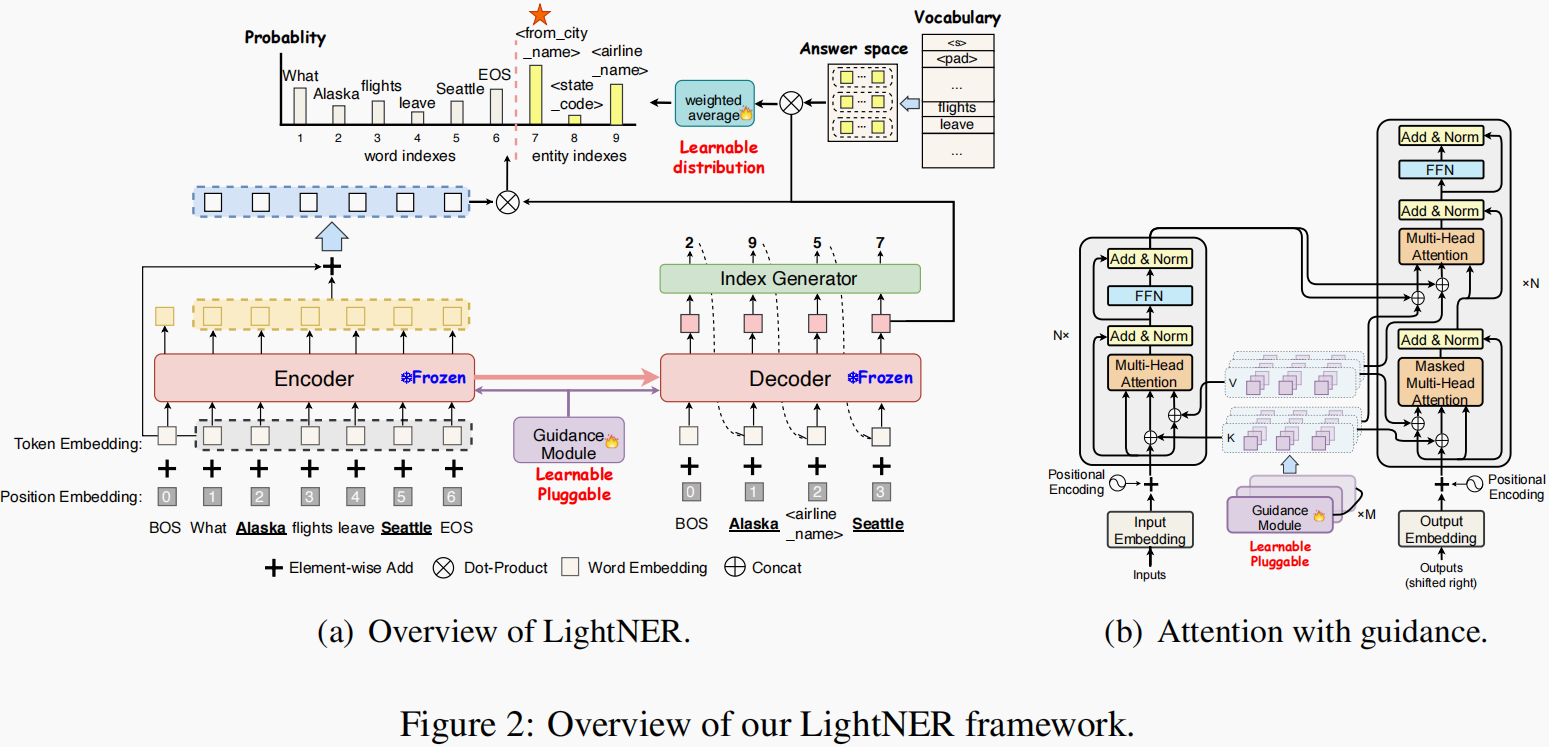
Descriptions:
本文主要关注本文引入了额外的可学习的参数(统一的可学习地verbalizerh和额外的prompt参数提示)与encoder和decoder的注意力输入进行注意力交互,起到了提示的作用,其作用类似一个知识向导。在这个工作中,只针对额外的参数进行tuning,从而让这个模块学习到领域迁移的能力。本文基于了BART对模型的注意力机制进行修改,利用一个额外的可插拔的模块对其进行cross-domain领域的知识学习,利用unified learnable verbalizer进行类型的提示,实验结果表明,这个可插拔的模块中学习到了丰富的领域知识。
Advantages:
可插拔的模块与模型本身的注意力进行计算,引入了少量的参数学习到了大量的知识,这是parameter-efficient的。同时unified learnable verbalizer为cross-domain的类型提示提供了有效的帮助。
pluggable module在cross-domain的情况下取得了不错的性能。
无需更新模型本身的参数,即插即用很方便,但是这个迁移到其他模型中会有效吗?每个模型的分布应该是不一样的才对。
Disadvantages:
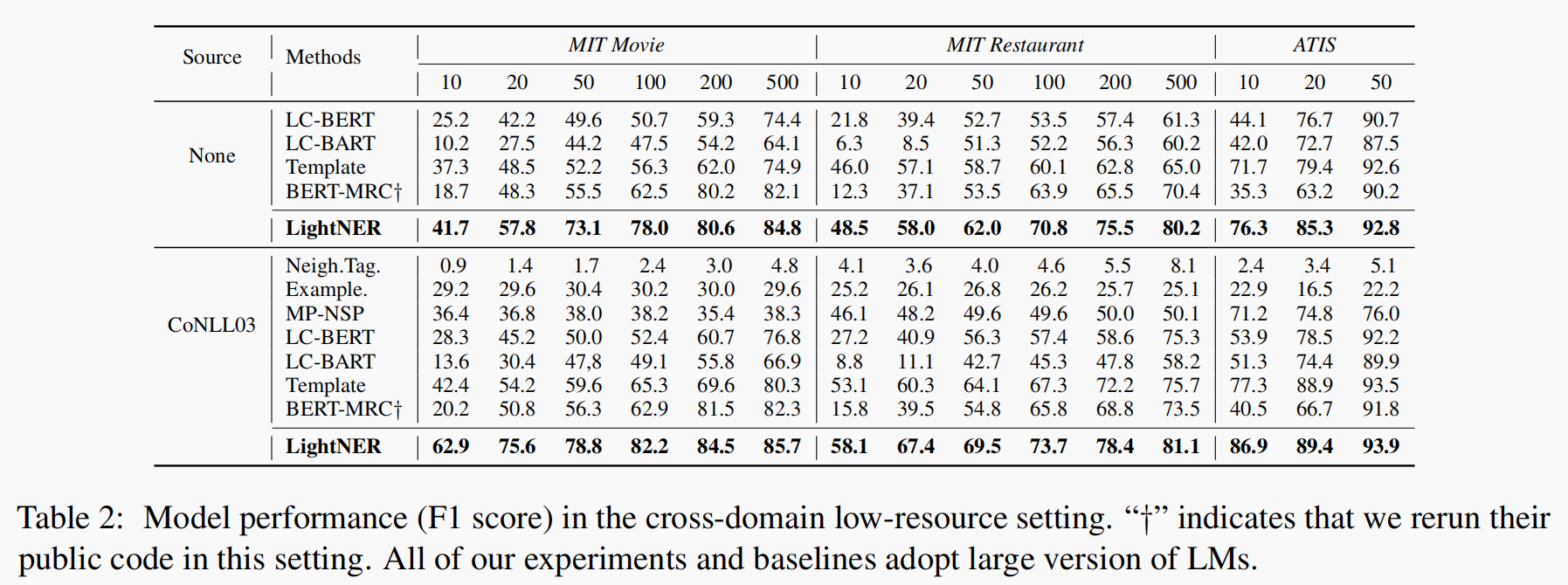
实验结果显示, pluggable module在in-domain的少样本下性能不如纯BART模型。
引入额外的参数提升了推理的时间(这个或许可以不计较,太苛求了有点)。
Results:
Abalation studies