**10个与AI相关的技术领域**
除了与各个科学领域相关的具体挑战之外,AI在科学领域还存在一些共同的技术挑战。特别是,我们确定了以下四个共同的技术挑战:超出分布的泛化、可解释性、由自监督学习提供支持的基础模型和不确定性量化。尽管这些挑战在AI和机器学习领域长期以来已经得到认可,但由于涉及的数据和任务的独特特性,它们在AI为科学领域的背景下变得更加重要。在本节中,我们讨论了与这四个挑战相关的当前限制、现有方法以及潜在的研究机会。
**10.1 可解释性**
作者:Hongyi Ling,Yaochen Xie,Ada Fang,Marinka Zitnik,Shuiwang Ji
尽管在机器学习领域中可解释性非常普遍,但它缺乏统一的数学定义。其含义可以根据上下文而异。有时它指的是模型本身能够提供人类理解的预测解释的能力,这是在决策树等模型中常见的特征。另一方面,可解释性也可以指深入理解复杂模型。例如,一个解释可以突出显示不同的输入图模式,例如子结构,如何导致某种GNN行为,例如最大化目标预测。在本文的范围内,我们将焦点缩小到提供每个输入图的实例级解释,这些解释为每个输入图提供了与输入相关的解释。从这个角度来看,解释揭示了对其预测至关重要的输入图的重要模式或组件。值得注意的是,输入图的不同组件可能以不同程度对模型的预测产生影响。因此,有效的解释方法能够精确地识别那些显著影响预测的组件和模式,从而全面了解驱动模型预测的基本因素。
几何深度学习(GDL)模型已经在解决量子、分子、材料和蛋白质科学中的各种问题方面展现出显著潜力。然而,要评估GDL模型结果的科学可行性,必须实现结果的可解释性。不幸的是,大多数GDL模型缺乏可解释性,通常被视为黑匣子,这妨碍了它们的可靠性并限制了它们在科学领域的应用。在这里,我们探讨了通过引入可解释的人工智能(XAI)来实现解释性的重要性。XAI旨在跟踪特定输入示例对最终预测的贡献,并识别携带与预测标签相关信息的部分。通过了解模型输出是如何确定的,它们的预测的可信度增加。此外,XAI还可以检验模型预测是否符合物理法则,从而有助于提高现有GDL模型的质量。对模型权重和特征的精确解释技术为领域专家提供了对这些模型所学习的基本机制的深入洞察,使从模型获得的知识能够引导未来的研究方向。模型的可解释性对通过识别分子、材料和蛋白质的重要亚结构来设计新化合物特别有价值,以实现特定的性质。
**10.1.1 现有的XAI方法**
虽然已经开发了许多XAI方法来研究图神经网络[Ying等人,2019;Yuan等人,2021;Gui等人,2022b;Baldassarre和Azizpour,2019;Huang等人,2022;Schnake等人,2021;Xie等人,2022b],但它们主要集中在二维图上。根据Yuan等人[2023]的说法,现有的方法主要可以分为四类,即梯度/特征方法、扰动方法、分解方法和替代方法。梯度/特征方法依赖于特征值或梯度来评估特征的重要性,因为它们提供了关于特征重要性的简单性和直观性而变得特别流行。扰动方法分析输入特征发生扰动时预测的变化,以生成重要性分数。分解方法将预测分数分解并逐层反向传播这些分数,直到输入空间以计算重要性分数。这些方法提供了对图神经网络每个层的更多见解。替代方法采样与给定输入示例类似的一些数据,并拟合一个简单且可解释的模型,如决策树。来自替代模型的解释被用来解释原始预测。这些技术对解释复杂模型的行为非常有价值。要深入了解图形XAI,建议参考最近的调查[Yuan等人,2023]。
尽管在2D图神经网络的XAI方面取得了进展,但针对GDL模型或3D图的XAI仍然是一个未被充分探索的领域。现有的GDL方法[Wang等人,2022d;Tubiana等人,2022]旨在通过对学习表示的系统分析和可视化来解释它们的体系结构。这些表示被归类为不同的簇,与特定的物理或化学性质相对应。然而,这些模型的预测机制以及输入图组件对预测的贡献仍然未知。由于几何数据的更高维度和模型的复杂性,这个领域存在独特的挑战和机会。尽管梯度/特征方法和扰动方法很有用,但它们不足以完全解释几何特征的重要性。另一方面,分解方法和替代方法不容易应用于GDL模型。最近,Miao等人[2023]提出了一种专门针对3D点设计的新的扰动方法。该方法使用一个可学习的解释模型向每个3D点引入随机噪声。解释模型与用于预测标签的GDL模型一起训练。然后,学习到的随机噪声量用于生成每个输入点的重要性分数。然而,这项工作只关注解释具有不变预测的GDL模型,并没有考虑解释的不变性和等变性[Crabbé和van der Schaar,2023]。因此,需要更多的XAI技术,专门用于等变GDL模型。
**10.1.2 潜在的应用场景**
XAI对研究科学的可解释性的贡献可以大致分为以下四个角度,每个角度都有若干潜在的适用场景。
**提高GDL模型的可信度:** XAI技术旨在提供关于模型行为和预测的见解,例如识别输入的重要特征和子结构。模型预测的可解释性允许研究人员更好地理解模型的底层机制,从而提高模型的可信度。在分子性质预测中,XAI可以验证GDL模型输出是否符合物理规则,例如分子结构和功能基团在决定分子性质方面的作用。同样,在蛋白质折叠分类中,XAI技术可以帮助识别用于预测特定折叠的最重要的氨基酸残基或二级结构元素,从而验证GDL模型是否捕捉到了二级结构特征,并协助科学家使用模型输出做出研究决策。在材料性质预测中,XAI可以用来验证模型是否关注了材料中的正确元素和结构以进行预测。对于学习量子自旋系统的基态,使用XAI来探索自旋构型和电子位置的扰动如何改变系统的能量将有助于验证所学习的能量是否在物理上一致。通过识别子结构、特征重要性和扰动效应,将XAI应用于GDL模型可以是一种有价值的方法,用于验证模型是否表现出科学上一致的行为,从而提高模型预测的可信度。
**促进更多的科学知识发现:** XAI可以揭示模型预测中的模式和见解,有助于研究人员发现新的假设和研究问题,可能导致新的科学知识的发现。例如,在进行分子能量预测时,XAI可以提供有关不同构型的同一分子的子结构和特征扰动以及它们相应能级重要性的重要见解,有助于未来研究分子构型的生成。此外,在蛋白质科学中,它可以识别关键的二级结构或氨基酸残基,这些残基负责给定的预测性质。这可以指导进一步研究已识别的蛋白质的子结构。在研究量子机制和偏微分方程等复杂系统的情况下,可以使用XAI来了解系统的行为,并识别对系统感兴趣的行为的最重要的变量和因素。通过使用XAI来洞察特征和权重如何影响模型的内部表示和决策过程,科学家可以深入了解底层物理原则,并测试关于未知和未充分探索的系统的新假设。
**诊断和改进现有模型:** XAI使研究人员能够通过检查和确保GDL模型符合物理规则来改进现有模型。科学上错误的模型解释的存在还有助于揭示模型中潜在的偏见或错误,从而提高模型的质量。例如,在使用浅水方程建模全球气象模式时,确保用于解决这些方程的GDL模型满足物理定律(如质量、动量和能量守恒)是很重要的。在分子机器学习中
,研究人员还可以使用XAI来探讨特征的重要性,并验证其是否与化学上预期的特征(如原子数、键角等)一致。XAI技术可以帮助研究人员确定GDL模型的预测是否符合这些物理定律,并确定模型需要更好满足哪些物理约束。这在找到多电子基态方面是适用的,通过检查输出是否满足费米子反对称性约束。对GDL模型的XAI对领域专家的结果验证非常重要,有助于揭示模型预测的局限性,以改进现有模型。
**促进药物和材料的设计:** XAI可以识别对于药物发现和材料设计中所需属性的关键子结构或功能基团。例如,在小分子与蛋白质之间的分子相互作用中,XAI技术可以识别对于预测结合亲和力至关重要的蛋白质和配体的关键部分。通过获取有关确定亲和力并且与所需蛋白质相互作用的特定氨基酸残基组的信息,研究人员可以设计更具选择性的药物,仅与所需蛋白质相互作用,降低了非特定作用的风险。在材料科学中,识别导致分子性质预测的元素和排列方向可以帮助指导发现具有特定性质的新材料。对于蛋白质科学,XAI可以识别与预测性质相关的特定蛋白质的子结构,研究人员可以利用这些信息设计具有类似性质的全新蛋白质。用于药物和材料的生成模型也可以受益于XAI,以更好地理解提出的设计。例如,在为给定的蛋白质生成药物时,使用XAI来强调蛋白质和生成药物中特定子结构的重要性对于研究人员理解生成的化合物并指导未来的设计是有帮助的。XAI可以通过识别对于所需或不希望的性质重要的模式和特征来引导新化合物的设计。
**10.2 领域外泛化**
作者:李欣儿,桂书瑞,季水旺
**领域外泛化(OOD)** 问题关注的是常见的学习情景,其中测试分布与训练分布不匹配,这会显著降低科学发现任务的模型性能,如图36所示。分布不匹配通常被称为分布偏移,包括协变量偏移[Shimodaira 2000]、概念偏移[Widmer和Kubat 1996]和先验偏移[Quiñonero-Candela等人2008]等概念。这个问题出现在各种应用场景中[Miller等人2020;Sanchez-Gonzalez等人2020;Myers等人2014;Gui等人2020],与各个领域相关,如迁移学习[Weiss等人2016;Torrey和Shavlik 2010;Zhuang等人2020]、领域自适应[Wang和Deng 2018]、领域泛化[Wang等人2022c]、因果关系[Pearl 2009;Peters等人2017]和不变学习[Arjovsky等人2019;Ahuja等人2021]。
目前,在科学AI领域,OOD泛化方法和研究可以显著提高各个领域的任务性能以及泛化能力。尽管存在许多关于通用OOD泛化[Arjovsky等人2019;Peters等人2016;Tzeng等人2017;Lu等人2021c;Rosenfeld等人2020;Ahuja等人2021;Sun和Saenko 2016;Ganin等人2016]和非欧几里得OOD泛化[Wu等人2022b;Chen等人2022b;Zhu等人2021;Bevilacqua等人2021;Li等人2023a;Gui等人2023]的研究,但在科学应用领域的OOD方法仍然是一个未被充分探索的领域。在本节中,我们旨在总结科学AI领域关于OOD方法的研究,并强调进一步探索的重要性。
**10.2.1 背景和设置**
分布偏移问题在各种情景下研究,包括迁移学习[Weiss等人2016;Torrey和Shavlik 2010;Zhuang等人2020]、领域自适应[Wang和Deng 2018]、领域泛化[Wang等人2022c]、因果关系[Pearl 2009;Peters等人2017]和不变学习[Arjovsky等人2019;Ahuja等人2021]等。
在领域自适应情景中,我们的目标是在不同领域之间存在分布偏移的情况下从一个(源)领域转移知识到另一个(目标)领域。具体而言,我们可以访问具有标签的源领域样本和目标领域样本。根据目标领域中标签的可访问性,领域自适应通常分为半监督和无监督设置。无监督领域自适应[Pan等人2010;Patel等人2015;Wilson和Cook 2020]是最流行的设置,因为它不需要目标领域中的任何标记样本。基本和最常见的想法是对齐源领域和目标领域之间的分布,减轻分布偏移。这个目标通常可以通过减小差异[Long等人2015;Sun和Saenko 2016;Kang等人2019]和对抗训练[Ganin和Lempitsky 2015;Tsai等人2018;Ajakan等人2014;Ganin等人2016;Tzeng等人2015,2017]来实现。然而,领域自适应需要预先收集目标领域样本,从而限制了其应用范围,例如对隐私敏感的应用。
不需要预先收集目标样本的情况下,领域泛化[王等人2022c;李等人2017a;Muandet等人2013;Deshmukh等人2019]则涉及对未知领域的预测,提供了更实际的解决方案。尽管这些领域繁荣发展,但领域自适应和泛化方法仍然需要进行稳健的理论和直观分析。与此同时,随着因果关系的发展[Pearl 2009;Peters等人2017],一个常识是,在没有干预和归纳偏见的情况下,泛化在逻辑上是不可能的。因此,环境划分[Ganin等人2016;Zhang等人2022]通常被用作暗示分布来自哪些干预的指示器。
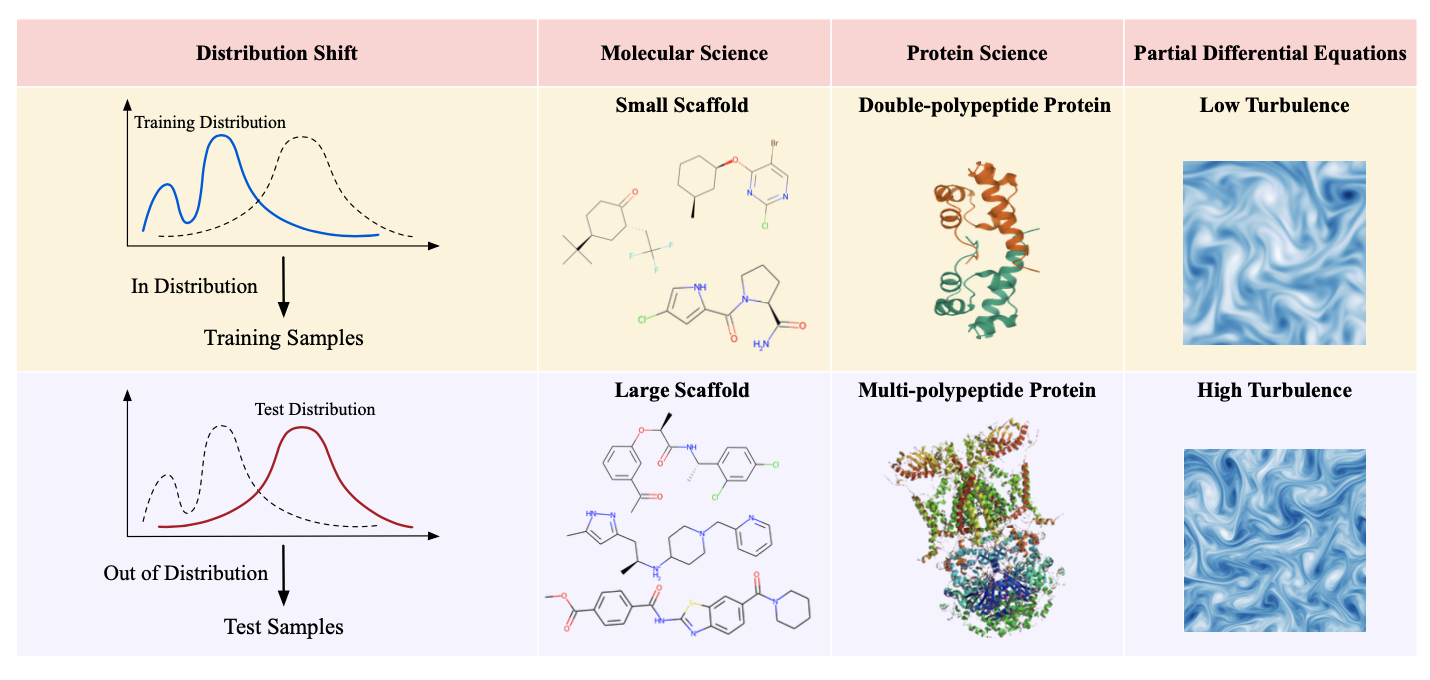
图36. 科学AI领域的OOD示例。领域外泛化(OOD)问题在科学任务中是普遍存在的,其中训练和测试样本来自不同的分布。在分子科学中,不同的分子大小和骨架是分布偏移的主要来源。在蛋白质科学中,3D蛋白质结构的复杂性,以及在组成和折叠方面可能存在的大量变化,使得对未知分布的泛化成为一项艰巨的挑战。在PDEs中,从高粘度到低粘度的时间演化建模的泛化是一项困难的任务,因为低粘度导致更多的湍流流动,产生更多的混乱动态和模拟中的挑战。
**10.2.2 AI中的量子力学领域中的OOD问题**
在量子力学领域,OOD问题经常在确定量子系统的波函数时出现 [Yang等人2020;Kochkov等人2021a;Roth和MacDonald 2021;Fu等人2022c]。例如,随着量子系统的大小增加,模拟波函数所需的空间呈指数增长,自旋或粒子之间的相互作用变得更加复杂。此外,系统的不同几何结构也会显著改变基础物理相互作用。将波函数构想应用于更大的晶格或不同的分子是具有挑战性的。一些研究通过更好地编码可以在不同系统大小和几何形状之间共享的内在相互作用模式来解决OOD问题。Botu和Ramprasad [2015]比较了新结构与训练数据集中的结构的指纹,并要求在结构的指纹的一个或多个分量位于训练范围之外时,进行新的量子力学计算。QM-GNN [Guan等人2021]实施了补充的QM描述符,以促进对域外未见示例的预测。Caro等人 [2022]在量子机器学习(QML)中开展了一项域外泛化的研究。他们证明了在广泛的训练和测试分布中学习未知酉操作的任务的域外泛化,这是一系列QML算法的基本原语,表明只能学习对已训练的乘积态进行干预的酉操作的作用。
**10.2.3 AI中的密度泛函理论领域中的OOD问题**
在DFT领域,OOD情况通常出现在量子张量学习的背景下。对于量子张量预测任务,由于计算复杂性,当前模型仅在具有数十个原子的系统上进行训练 [Schütt等人2019;Unke等人2021a;Li等人2022e]。然而,在实际中,系统可能包含数百甚至数千个原子。量子系统的大小变化使得在没有平凡解决方案的情况下进行预测变得困难。一些现有的研究提出了在定义的适用性领域之外性能严重下降的问题 [Pereira等人2017;Li等人2016a],但很少有研究提供了解决这个问题的可行解决方案。未来研究的一个普遍而现实的方向是在不变风险最小化框架下使用不同大小的数据进行训练 [Peters等人2016;Arjovsky等人2019],以大小作为环境。
**10.2.4 AI中的分子科学领域中的OOD问题**
分子科学领域中的OOD挑战源于AI模型必须遍历的庞大复杂化学空间,许多潜在挑战源于数据限制、模型架构和评估指标 [Gómez-Bombarelli等人2018;Chen等人2018b;Feinberg等人2018]。一个主要挑战是训练数据对化学空间的覆盖有限,这可能导致对未见分子的预测产生偏见并导致模型性能下降。这个问题源于化学空间的巨大大小和复杂性,其中有几乎无限数量的潜在化合物 [Polishchuk等人2013]。例如,一般的GNN在训练时无法泛化到大分子。受开创性的因果相关的不变学习工作 [Arjovsky等人2019;Peters等人2016]的启发,Bevilacqua等人 [2021]提出通过引入大小不变的图表示来解决大小偏移问题。随着最近涌现的许多基于子图的图OOD学习方法 [Wu等人2022b;Chen等人2022b;Gui等人2023],Yang等人 [2022]为药物发现引入了一种分子特定的不变学习方法。在科学领域,Sharifi-Noghabi等人 [2021]将癌症中的药物响应预测形式化为OOD问题,并在半监督设置下提出了Velodrome。除了OOD学习策略外,分子的OOD生成也是一个新兴的现实方向。当前的药物发现实验成本高昂,而在分布内生成不会提供创新的分子结构。因此,OOD分子生成对于药物发现至关重要。最近,随着基于能量的方法 [Elflein 2023] 和分子生成 [Liu等人2021d] 的出现,Lee等人 [2022b]结合了基于能量的生成和OOD检测,以生成知道的分子分布之外的分子。此外,提出了一种基于分数的方法分子OOD扩散(MOOD)[Lee等人2022a],通过利用梯度来引导生成过程到高性能评分区域,以生成新颖且具有化学意义的分子。
**10.2.5 蛋白质科学领域的AI中的OOD问题**
在蛋白质科学领域,OOD问题是一个关键的研究课题,因为蛋白质结构和功能的巨大多样性,以及蛋白质序列-结构-功能关系的不断演化的知识 [Koehl和Levitt 2002;Petrey和Honig 2005]。AI模型在预测蛋白质结构、蛋白质-蛋白质相互作用甚至药物-蛋白质相互作用方面的泛化能力超越训练数据分布将加速药物发现、精准医学 [Ashley 2016] 和蛋白质工程 [Goldenzweig等人2016] 等领域的进展。在这一背景下的一个主要挑战是高质量实验数据的有限可用性,因为缺乏领域对于OOD泛化至关重要。因此,一个潜在的解决方案是将领域知识和物理原理纳入AI模型 [Jumper等人2021]。这些方法可以帮助AI模型学习更具传递性和鲁棒性的特征,从而更好地泛化到新的蛋白质序列或复合物。ProGen [Madani等人2020]是一种使用语言模型的无监督蛋白质序列生成方法,包括非平凡的OOD性能评估。Gruver等人 [2021]发现在OOD蛋白质设计上,集成模型比其他方法更稳健。Kucera等人 [2022]提出了一种创新的蛋白质序列生成方法,并进行了OOD生成评估。最后,蛋白质科学中的一个可能方向是不确定性估计或OOD检测 [Hamid和Friedberg 2018,2019],这方面的研究尚未深入开展。
**10.2.6 材料科学中的AI中的OOD问题**
对于材料科学,OOD问题通常由于材料和其独特性质的巨大多样性而产生。对于未知的OOD材料和成分,它们的结构、相互作用和性质的复杂性对于基于AI的材料发现和优化构成了重大挑战。此外,将领域知识和物理原理纳入AI模型可以有助于学习更具传递性和鲁棒性的特征,从而更好地泛化到新材料和结构 [Murdock等人2020]。Kailkhura等人 [2019]将简单模型集成并提出了一种利用不同材料性质之间的相关性的迁移学习技术,以可靠地预测分布不均匀和分布偏斜数据中的材料性质。Sutton等人 [2020]使用子组发现来确定材料类别内模型的适用性领域。材料科学的另一个方面是材料设计和发现 [Ghiringhelli等人2015;Xue等人2016a;Guo等人2019],受到材料结构和性质的复杂性的影响。最后,在化学相互作用领域探索OOD检测 [Musil等人2018],这方面研究仍然未开展,可能是未来的有前景的研究方向。
**10.2.7 化学相互作用中的AI中的OOD问题**
化学相互作用中的OOD挑战是一个关键问题,特别是在分子相互作用研究中 [Cai等人2022b,a],在这种研究中,当应用于新的和未知的结合时,模型可能难以泛化并提供准确的预测。例如,在设计有效的治疗方法方面,准确预测候选药物在与训练数据中明显不同的靶蛋白上的对接效力至关重要。最近,Zhang和Liu [2023]提出通过亚口袋级别的相似性考虑蛋白质-分子相互作用,以提高模型的泛化能力。对于药物-药物相互作用(DDIs),Tang等人 [2023]设计了一个亚结构相互作用模块,DSIL-DDI,用于学习DDI任务的域不变表示,提高了泛化能力和可解释性。为了探索暗基因家族,Cai等人 [2023]提出了一种创新的OOD元学习算法PortalCG,从不同基因家族到暗基因家族进行泛化。由于受到受体活性数据稀缺的挑战,Cai等人 [2022a]提出了一种自监督方法DeepREAL来减轻分布偏移。为了评估先前药物靶标相互作用工作的OOD泛化能力,Torrisi等人 [2022]通过包括系统性的测试样本分离提供了泛化能力评估。
**10.2.8 AI中的偏微分方程领域的OOD问题**
在神经PDE求解
器领域,从经典求解器中导出训练数据可能成本过高。因此,实际上有用的神经PDE求解器应该能够泛化到不同的系统,包括具有不同的初始条件、边界条件和PDE参数的系统。MAgNet [Boussif等人2022]可以实现对未见网格的零次泛化,解决了与训练过程中看到的分辨率不同的分布的PDE。Brandstetter等人 [2022c]在训练过程中添加噪声以鼓励稳定性并解决分布偏移问题。NCLaw [Ma等人2023]嵌入了一个网络架构,严格保证了标准的构成先验(包括旋转等价性和未变形状态平衡)在可微分模拟中,并基于模拟和运动观察之间的差异进行优化。NCLaw可以在训练一个运动轨迹后泛化到新的几何、初始/边界条件、时间范围,甚至多物理系统,实现了在这些典型的OOD任务上与以前的神经网络方法相比性能的数量级提高。其他研究 [Kochkov等人2021b;Stachenfeld等人2021] 研究了学习模型的各种OOD泛化能力,包括泛化到训练分布之外的条件、滚动时长和环境尺寸。未来的工作可以将先前的物理知识纳入深度学习替代模型中,以遵守基础物理定律并捕捉不变信息,从而提高对不同系统的泛化能力。
**10.2.9 数据集和基准**
为了促进科学任务中OOD的发展,先前已经有一些针对科学任务中OOD问题的基准工作,为各种实际数据集上的OOD学习提供了方案和评估。OGB [Hu等人2020]关注图数据集,识别并分割了多个领域的不同分布。Wilds [Koh等人2021;Sagawa等人2021] 研究了多个领域和数据模态的野外数据集中的数据收集变化。GOOD [Gui等人2022a]考虑了分布变化的完整性,并在众多数据集和方法上进行了多样化的图任务基准测试。DrugOOD [Ji等人2022] 和CardioTox [Han等人2021] 关注分子图OOD问题,基于大规模生物测定数据库ChEMBL [Mendez等人2019]、NCATS和FDA [Siramshetty等人2020] 进行策划。ImDrug [Li等人2022g] 对不平衡学习的几个药物发现任务进行了评估。未来的AI中的OOD研究可以在这些基础上受益于科学任务。
**10.2.10 开放的研究方向**
OOD场景在科学领域的AI中是普遍存在的,会导致任务性能的显著下降;因此,保护科学领域的AI模型不会在这种情况下出现故障,以防止不利的现实世界后果,是至关重要的。我们强调了在科学学科的AI应用背景下继续研究OOD策略的重要性。对于进一步的研究,我们指出一个有希望的方向是识别和利用训练数据中的因果因素 [Peters等人2016],这些因素可以约束优化模型在未见测试数据上的行为。如果目标分布变化的性质是先验已知的,例如,通过在SE(3)等价性中构建模型来实现OOD泛化,那么模型可以泛化到OOD。
**10.3 基础模型和大型语言模型**
通常,深度模型的监督学习需要大量带标签的数据。然而,在科学发现的情况下,由于需要专业领域知识、高计算或实验成本或物理限制等因素,获取带标签的数据可能会尤其具有挑战性。例如,使用DFT方法计算分子的能量可能需要每个分子几个小时到几天的时间,具体取决于分子的大小。此外,为药物发现实验获取正标记数据成本高昂且耗时,使深度模型在全球大流行病(如COVID-19)早期的快速药物发现阶段应用有限。这一困难导致了一个新兴的研究领域,专注于自监督学习(SSL)。SSL技术使深度模型能够利用未标记数据并学习现实数据先验,例如物理规则和对称性,而无需依赖大量带标签的数据集。基于SSL,基础模型将这个利用没有任务标签的数据的思想推向极端,旨在对这些数据进行预训练,以便适应所有任务[Bommasani等人2021]。它本质上允许知识从通常是自监督任务的通用任务以有限带标签数据的方式转移到感兴趣的各种特定任务中。具体来说,大型语言模型(LLMs)到目前为止是迄今最多才多艺和功能最强大的基础模型,这要归功于文本数据中包含的无标签和丰富的监督。由于文本数据中包含的强知识获取和推理能力,LLMs使知识捕获和转移更加灵活,适用于物理学、计算机科学、化学、生物学、医学科学等科学领域[Boiko等人2023;OpenAI 2023;Nori等人2023;Gupta等人2022]。LLMs在科学中最令人兴奋的应用之一是生成建模。虽然幻觉是许多LLM用例的常见问题,但对于发现新药物[Liu等人2021b]、材料[Xie等人2023a]和研究思路[Wang等人2023b],这成为一种优势。到目前为止,由SSL驱动的基础和大型语言模型是解决标签获取挑战并使AI应用能够应对更广泛的科学问题的最有前途的方向之一。在以下小节中,我们将讨论科学发现领域中SSL技术、单模基础模型和LLMs的当前挑战、焦点和进展。
**10.3.1 自监督学习**
自监督学习的目标是通过从数据本身中提取标签,基于其中的关联关系来构建信息丰富的学习任务。根据Xie等人 [2023b],SSL方法可以根据在学习过程中是否需要成对数据,大致分为对比和预测方法两类。具体而言,对比方法涉及多个数据模态或增强,以获得要与随机抽样的负对进行区分的正数据对,而预测方法则从数据的某些维度子集中自动生成易于计算和信息丰富的标签作为学习目标。SSL在各个领域已经显示出其有效性和必要性,包括表示学习、预训练和辅助学习[Xie等人2023b]。
**用于分子和蛋白质表示的SSL:** 在AI科学领域,大多数现有的SSL工作都集中在从它们的2D图形表示中学习分子表示方面。特别是,通用图SSL工作 [You等人2020;Xie等人2022c] 已经将分子表示学习视为一个重要的用例。相比之下,其他研究已经专门为分子图开发了SSL方法,这允许集成领域知识,如功能基团(动机)的共现 [Hu等人2019b;Rong等人2020;Li等人2021f]、原子-键关联 [Rong等人2020] 和反应背景 [Wang等人2022e]。
**这些方法已被证明在利用分子图的拓扑结构方面是有效的,如化学键所示,但对于某些任务(如量子属性预测)而言,可能会错过某些几何信息,这些信息对于某些任务来说具有更高的重要性。为了进一步利用分子的3D几何信息,Liu等人[2022e]和Stärk等人[2022a]提出了基于跨模态关联的分子SSL任务。从技术上讲,这些方法学习最大化分子的2D和3D模态的表示之间的互信息,以便这些表示对多个下游任务具有信息价值。此外,Noisy Nodes技术已被提出作为3D分子的预测SSL方法,用于预训练[Zaidi等人2022]和辅助学习[Godwin等人2022]范式。具体来说,Noisy Nodes方法通过破坏原子坐标并训练GNN来估计注入的噪声来提供自监督,这与去噪自编码器的思想一致[Vincent等人2008;Xie等人2020;Batson和Royer 2019]。这种简单的策略被证明对于3D分子是有效的,并已在各种后续工作中使用[Luo等人2023b;Masters等人2022]。除了小分子外,还有一些工作致力于开发用于蛋白质的SSL方法。具体而言,Yu等人[2023a]使用对比学习训练了一个模型,该模型可以将蛋白质序列与功能注释(如酶委员会编号)进行比较,以实现对功能的理解。
**SSL用于神经PDE求解器:** SSL还被用于训练神经PDE求解器,其中由昂贵的数值方法生成的训练数据的成本是监督求解器的主要限制。为了降低这一成本,Raissi等人[2019]提出了物理信息神经网络(PINN),它直接将网络参数化为PDE解的解。该网络使用基于PDE指定的解上的约束来推导自监督物理信息损失进行优化,并通过在一维空间中解薛定谔方程来进行经验验证。在更具挑战性的SSL设置中,Raissi等人[2020]使用带有由Navier-Stokes方程和流体流动中的标量场(如由流动运输的染料)的快照指定的约束进行训练的PINNs来推断流体流动的速度和压力场。这种应用在需要压力和速度测量但只能访问快照的设置中尤为相关,例如生物医学分析中用于检测冠状狭窄的血流[Raissi等人2020]。此外,通过在物理信息损失中纳入物理知识,已经将在监督设置中构思的神经求解器(如DeepONet [Lu等人2019])扩展到SSL设置[Wang等人2021b]。与普通的PINNs [Raissi等人2019]不同,物理信息DeepONet是由Wang等人[2021b]提出的,它不仅针对PDE的一个特定实例,而且可以推广到一类PDE,例如,初始条件,甚至在OOD范围内的实验中表现出了成功的性能。此外,Wang等人[2021b]报告物理信息DeepONet在性能上优于其监督对应物。
**10.3.2 单模基础模型**
SSL技术的成功催生了在视觉[Rombach等人2022;Kirillov等人2023;Li等人2022f;Wang等人2022f]、语言[Radford等人2018;Devlin等人2019]和医学[Moor等人2023]领域发展基础模型。通常,基础模型是在自监督或可泛化监督下进行预训练的大规模模型,允许在少量或甚至零数据的情况下执行各种下游任务,可以进行轻松微调,或者可以基于学到的嵌入来构建。与SSL技术类似,它们使知识从大量未标记的数据转移到具体任务,而这些任务具有有限甚至零数据。在本节中,我们重点讨论不过多依赖自然语言模态的领域模型的发展,尤其是在蛋白质和分子分析领域,这些领域的多才多艺和潜在影响尤为明显。
**蛋白质发现和建模:** 基础模型在科学AI领域已经显示出巨大潜力,用于解决与蛋白质发现和分析相关的各种挑战。AlphaFold [Jumper等人2021] 和RoseTTAFold [Baek等人2021] 是两个基础模型,已在预测蛋白质折叠几何结构方面取得了显著进展。训练后的模型可以扩展到执行更多下游任务,包括蛋白质生成和蛋白质-蛋白质相互作用(PPI)。具体而言,RFdiffusion [Watson等人2022] 对RoseTTAFold进行微调,以实现具有扩散模型的蛋白质结构生成。RFdiffusion不是根据序列预测结构,而是从随机噪声进行无条件生成,可以进一步根据特定的功能模体或结合靶标进行条件生成。类似地,Chroma [Ingraham等人2022] 被开发为基础蛋白质扩散模型,以实现根据所需性质(包括亚结构和对称性)进行条件生成的蛋白质,从而促进了多个下游应用,如治疗开发。此外,AlphaFold Multimer [Evans等人2021] 和Humphreys等人[2021] 分别扩展了AlphaFold2 [Jumper等人2021] 和RoseTTAFold [Baek等人2021],以执行PPI的预测任务,或者在不进行进一步微调的情况下进行蛋白质复合物的预测。除了对蛋白质结构和几何形状进行建模外,语言模型还在与蛋白质设计相关的多个任务中显示出有效性[Madani等人2023;Melnyk等人2022;Zheng等人2023;Hie等人2023],即使只涉及蛋白质的顺序形式。
**分子分析和生成:** 对于与分子相关的任务,虽然已经提出了各种自监督学习(SSL)技术,但目前在该领域尚没有主导的非语言基础模型。然而,出现了两个有前途的研究方向,重点关注分子的不同模态:分子图,无论是2D结构还是3D几何,以及以SMILES [Weininger 1988;Weininger等人1989] 为代表的顺序表示。对于2D分子图的情况,研究人员已经扩展了基于图的SSL研究的成功[Wang等人2022k,e]。例如,Fifty等人[2023]将分子表示为图,并使用大量模拟数据对GNN模型进行预训练,以预测分子与蛋白质靶标之间的相互作用的结合能。与典型的预训练方法相比,Fifty等人[2023]展示了分子基础模型在更广泛的下游任务中的潜力,包括少样本对接和性质预测。最近的工作还展示了在适当编码的情况下,基于3D分子图构建的基础模型在多任务能力方面的潜力。具体来说,Flam-Shepherd和Aspuru-Guzik [2023]将3D分子相关任务构建为原子的序列化3D坐标上的自回归生成。这个框架使得可以在多个任务上使用语言模型架构,包括分子生成、材料生成和蛋白质结合位点预测。另一方面,现有的工作,如ChemGPT [Frey等人2022]、ChemBERTa [Chithrananda等人2020;Ahmad等人2022]、MolBert [Fabian等人2020]、Schwaller等人[2021]、MegaMolBart [NVIDIA Corporation 2022] 和Tysinger等人[2023],关注了分子的字符串表示,并从大量这些字符串的集合中采用了语言模型的预训练技术,进行分子表示学习。已经显示出语言模型能够通过生成SMILES字符串来生成分子。然而,由于SMILES字符串并不是专门为生成建模而设计的,因此许多生成的SMILES字符串在化学上无效。已经提出了新的字符串表示[Grisoni 2023],用于生成目的,如DeepSMILES [Krenn等人2020],它避免了环和括号关闭的问题,以及SELFIES [Krenn等人2020],它提出了一种正式的语法方法来确保有效性。SELFIES已经扩展到包括群体[Cheng等人2023a],以更好地捕获有意义的分子基序。这些基于字符串的研究是首次尝试探索大语言模型的能力,已经在各种任务中显示出巨大潜力。尽管使用了语言模型,但这些研究侧重于分子的单一模态,并不涉及自然语言的指导和知识。
**自然语言引导的科学发现:** 将语言模型应用于科学领域正变得越来越流行,因为它具有加速科学发现的潜力[Hope等人2022]。一个自然的问题是为什么我们要将语言整合到科学发现过程中。除了从文献中提取信息这一显而重要的任务之外,还有许多其他引人注目的原因。首先,语言使得没有计算机专业知识的科学家能够利用人工智能的进步。其次,语言可以在设计新颖的工件时实现对复杂属性的高级控制(例如,从低级的“logP”到高级的“抗疟疾”药物设计)。第三,当数据稀缺时,语言可以作为各种模态之间(例如,细胞途径和药物)的“桥梁”。除了这三个原因,语言已经被开发成为人类抽象地思考世界的方法。就像科学通常依赖自然现象(例如,青霉素)来进行创新一样,我们可以依赖语言现象来进行抽象和联系。
传统上,自然语言处理(NLP)已经以翻译和情感分析等核心任务为重点进行了开发。在科学领域,NLP任务主要集中在从文献中提取信息,例如命名实体识别[Li等人2016d]、实体链接[Lai等人2021a]、关系提取[Wei等人2016;Lai等人2021b]和事件提取[Zhang等人2021]。近年来,NLP模型取得了快速进展,因此产生了可以轻松应用于大多数NLP任务的强大基础模型[Devlin等人2019;Raffel等人2020;Brown等人2020]。此外,这些系统在一定程度上具备常识[Bian等人2023]和推理[Wei等人2022;Yao等人2023a;Huang和Chang 2022]能力,这可能进一步推动科学领域的人工智能研究。然而,科学文本的多样性和复杂性仍然对这些系统提出了挑战。因此,已经付出了相当多的努力,构建了领域特定的语言模型变体[Beltagy等人2019;Liu等人2021c;Michalopoulos等人2021;Gu等人2021;Meng等人2021;Yasunaga等人2022;Gupta等人2022;Luo等人2022;Taylor等人2022],以利用其中包含的有价值的信息。在这些基础模型的基础上,已经推动了一系列应用的发展,从大规模信息检索系统[Google 2004;Fricke 2018]到知识图谱构建[Wang等人2020a;Zhang等人2021],再到用于科学创造力的类比搜索引擎[Kang等人2022]和科学论文生成[Wang等人2018, 2019a]。尽管这些应用各不相同,但它们的共同主题是试图理解过多的科学信息。最近,一些工作通过将人工构建的数据库中的外部知识引入到现有模型中[Lu等人2021a;Lai等人2023]、应用蒸馏进行数据增强[Wang等人2023a]以及通过检索增强模型[Naik等人2021;Zamani等人2022],进一步改进了这些科学语言模型。
目前,用于科学的大型语言模型的最新进展通常集中在解决两个关键挑战。首先,科学发现问题通常涉及复杂的数据模态,例如粒子系统的几何状态。因此,开发有效的方法来对科学模态进行编码和集成到语言模态中至关重要。其次,由于各种任务的制定以及有限的数据和模型可用性,将通用型大型语言模型适应到科学领域在学习任务制定和范式方面并不是一件简单的事。在本节中,我们从上述两个角度讨论了现有工作实例化的科学语言模型的框架和技术。
**多模态科学与语言:** 为了解决利用科学数据模态的挑战,开始研究在科学领域将自然语言与模态进行对齐。虽然有些情况探讨了原始模态的不同变化,例如分子字符串表示[Guo等人2021],但在过去两年中,对这些自然存在的模态和自然语言的整合引起了极大的兴趣,以实现对科学发现过程的高级控制。这在很大程度上受到了CLIP [Radford等人2021](对比学习)和DALL-E [Ramesh等人2021](联合序列建模)等模型的成功启发。将语言与其他模态集成的高级目标是实现高级功能控制(例如,品味),而不是低级属性特定控制(例如,溶解度)。总体建议是,科学领域中同样能力的模型将通过使科学家能够以功能为导向而不是以形式为导向来大大加速发
现过程的许多方面。此外,语言本质上是组合的[Szabó 2020;Partee等人1984;Han等人2023],因此有望用于组合这些高级属性[Liu等人2022d]。这种组合性在由Edwards等人[2021, 2022];Su等人[2022];Liu等人[2022d]评估的科学任务中已经得到了证明。
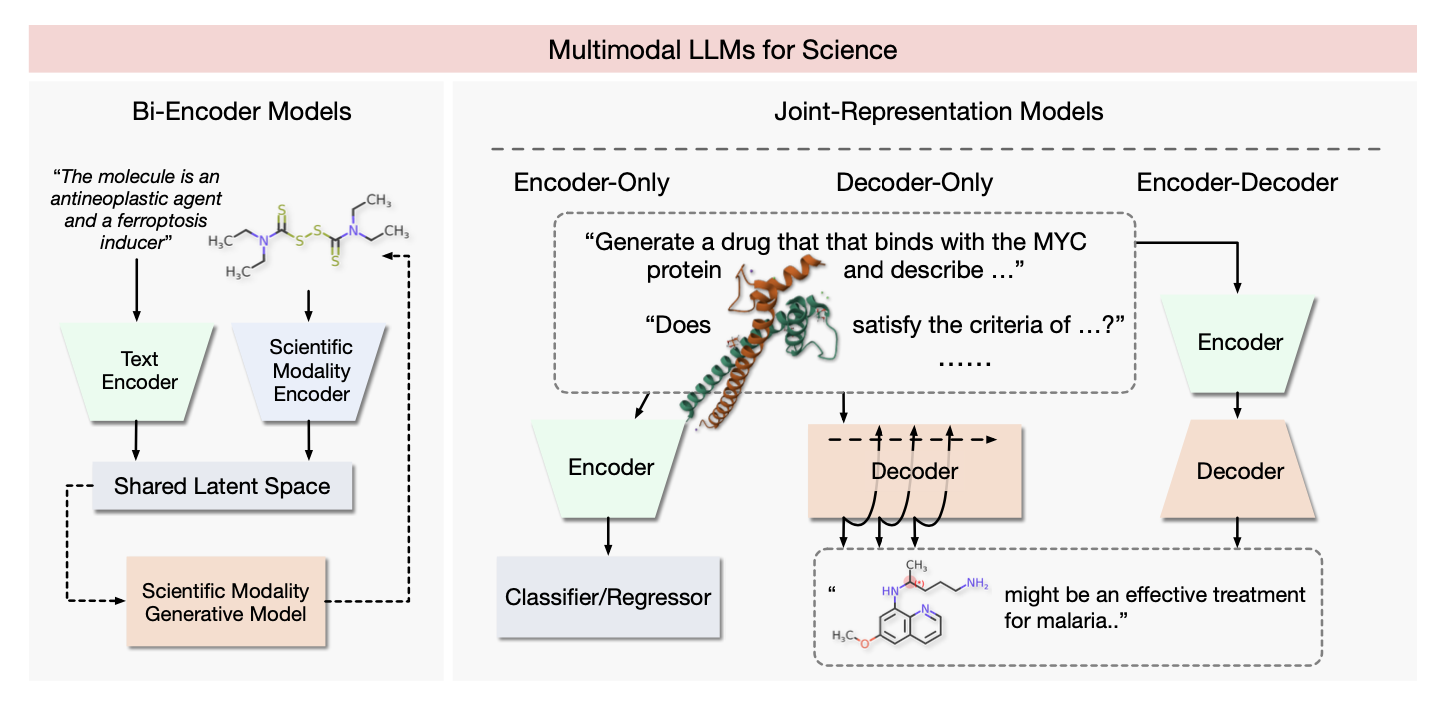
图37. 多模态科学自然语言处理的高级架构。以分子和语言的多模态性为例。双编码器图中的虚线表示可能扩展为生成框架。示例输入和输出显示了“代码切换”的模态性(即它们被整合成单一序列)。编码器用于生成可用于检索、分类、回归等任务的输出表示。解码器模型通常用于生成建模应用程序。在某些情况下,可以使用非LLM组件(例如在编码器-解码器模型的解码器中)。需要注意的是,通过工具扩展通用目的的LLM是另一种方法,本图未显示。
**多模态科学与语言 - 确定模态:** 为了确定适用于特定应用程序的问题制定和模型设计,首先需要确定相关的输入和输出模态。例如,如果想要从文献中提取反应信息,那么文本到文本模型[Vaucher等人2020]应该足够。然而,为了对我们提取的反应进行上下文理解,我们可能还需要加入图像(视觉)和分子结构。在药物分子的生成和编辑与高级指令的情况下,将语言作为输入也是合适的[Edwards等人2022;Liu等人2023c;Fang等人2023]。在检索有关药物的相关文献的情况下,我们可以选择分子图作为输入,用于从文献库中检索。一般来说,如果有足够的训练数据,将模态添加到语言中通常会有所帮助,因为这样可以将模型的理解与现实世界联系起来。然而,在实践中获取多模态数据可能具有挑战性。可以根据以下三个问题来判断是否从单模态解决方案转向多模态:1)多模态是否是我的任务的核心部分,例如分子字幕?2)我是否应该在第10.3.2节的任务中添加语言?换句话说,我是否需要自然语言提供的控制和抽象级别;或者是否有作为文本可用的互补信息?以及3)除了语言之外,我是否会从其他模态获得有意义的好处,或者我需要的所有信息都表达为文本?
**多模态科学与语言 - 整合模态:** 现在,一旦决定采用多模态方法来处理应用程序,就至关重要地制定一个整合模态的框架。如图37所示,有两种常见的方法,即双编码器模型和联合表示模型。这里可以绘制与信息检索中跨编码器和双编码器之间的区别相类似的类比[Reddy等人2023];双编码器允许快速比较,而且在训练时可能需要更少的数据,但交叉编码器允许模态之间更精细的交互。我们现在详细讨论这两种方法。双编码器模型由一个文本编码器分支和一个用于其他模态(例如分子和蛋白质)的分支组成。它们的优点在于不需要直接的、早期的两种模态的整合,允许集成现有的单模态模型。代表性示例包括Text2Mol [Edwards等人2021],它提出了从自然语言查询中检索分子的新任务,以及CLAMP [Seidl等人2023],它学习比较分子和药物活性预测的生物活性测定的文本描述。BioTranslator [Xu等人2023b]将这一极端推向了极致,通过学习文本、药物、蛋白质、表型、细胞途径和基因表达之间的潜在表示。一般来说,这些双编码器模型对于跨模态检索是有效的[Edwards等人2021;Su等人2022;Liu等人2022d;Zhao等人2023],但它们也可以集成到分子[Su等人2022;Liu等人2022d]和蛋白质[Liu等人2023f]生成框架中。
Joint-Encoder Models 另一方面,旨在模拟在同一网络分支内多个模态之间的相互作用。这些可以根据是否包含解码器来分类。仅编码器模型可用于预测、回归和(可能较慢的)检索,但无法执行生成建模。一个例子是KV-PLM [Zeng et al. 2022],它在文献数据上训练了一个仅编码器语言模型,其中分子名称被SMILES字符串替换。第二个类别是编码器-解码器模型 [Edwards et al. 2022; Christofidellis et al. 2023] 或仅解码器模型 [Liu et al. 2023e]。这些可以用于跨模态生成任务,例如由Edwards等人提出的分子和语言之间的“翻译”,其中分子是根据给定的文本描述生成的,反之亦然。还出现了使用语言来编辑现有分子以进行药物优化的兴趣[Liu et al. 2022d, 2023c]。其他工作考虑了反应序列[Vaucher等人 2020, 2021]或蛋白质[Gane等人 2022]。
使LLM适应科学领域:现有的LLM主要是为了通用目的而进行研究和开发的。这些LLM可以利用并适应特定的科学领域甚至特定的任务,充分利用其固有的知识和先验知识。在执行这种适应时,必须在任务推断期间或之前,精心设计科学任务的公式,将关键的领域特定上下文和知识纳入LLM。此外,鉴于领域特定的数据有限,必须在通用领域的不相关知识和适应期间的推理能力之间进行权衡。
适应LLM到科学领域 — 学习任务的公式:LLM是基于序列的模型,因此构建不同任务公式(如预测、检索和生成)的输入和输出序列并不是一件简单的事。然而,作为一种一般趋势,当前科学领域中的大多数语言模型会从核心NLP(例如BERT [Devlin等人 2019]或GPT [Radford等人 2018])中采用预训练过程(例如,KV-PLM [Zeng等人 2022]或 GPT [Radford等人 2018])。因此,未来的工作可能会在新的语言模型培训目标[Tay等人 2023]中找到好处。然而,一些工作已经尝试使用来自已知属性的额外信号[Ahmad等人 2022]。在设计多模态学习公式时,通常需要进行额外的工作,以缓解数据稀缺性带来的挑战。策略包括多语言[Edwards等人 2022]和多任务[Christofidellis等人 2023]学习。除了训练多模态任务的模型外,还可以将现有的单模态模型与多模态扩展整合,以避免制定新的学习目标。例如,可以将双编码器模型与流[Su等人 2022]或序列生成模型[Liu等人 2022d,2023c]相结合。此外,还可以在现有的生成模型中使用分类器指导[Ingraham等人 2022]。适应LLM到科学领域 - 学习范式:现有的工作已经探讨了适应LLM用于各种特定应用的方法。在考虑到数据可用性和模型可访问性不同程度的情况下,这些适应可以通过几种范式[Liu等人 2023d; Wang等人 2023c]来实现。在科学领域,有三种典型的适应范式,包括从头开始培训领域特定的LLM、微调通用目的的LLM以及通过提示进行少/零-shot学习。它们的学习框架、数据集构建和模型访问在图38中进行了比较,并在以下讨论。LLM架构本身通常包含某种关于推理的先验知识。鉴于有效的LLM架构,从头开始培训领域特定的LLM与高度定制的数据构建训练数据集变得自然。这种方法允许模型的固定容量内学习更好的领域特定知识,并且可以在特定的下游任务中进一步使用这些模型。然而,为了达到所需的性能,需要付出大量的努力来构建包含大量文本的训练数据集。例如,Galactica [Taylor等人 2022]从论文、代码、知识库等收集数据构建了一个大型科学语料库。然后,LLM在收集的领域特定数据上以自监督的方式[Devlin等人 2019; Radford等人 2018]进行训练,能够对数学方程、SMILES、蛋白质和DNA字符串进行标记。这些方法能够执行多个下游任务,如药物发现、再利用和相互作用预测。利用预训练语言模型的一般推理能力,最近的工作还探讨
了在通用LLM上进行领域特定数据集的微调。BioMedLM [Bolton等人 2022]和med-PALM [Singhal等人 2023]是从通用LLM GPT- 2 [Radford等人 2019]和PaLM [Chowdhery等人 2022]中微调的生物医学领域的示例。它们在医学问题回答任务上表现出了良好的性能。微调还可以通过以监督方式使用更少数量但成对的数据来进行。例如,DrugChat [Liang等人 2023]构建了一个包含超过143k个手工制作的问题-答案对和涵盖了10000多种药物化合物的说明调优数据集。LLM然后与构建的数据集上的GNN模块一起进行训练。
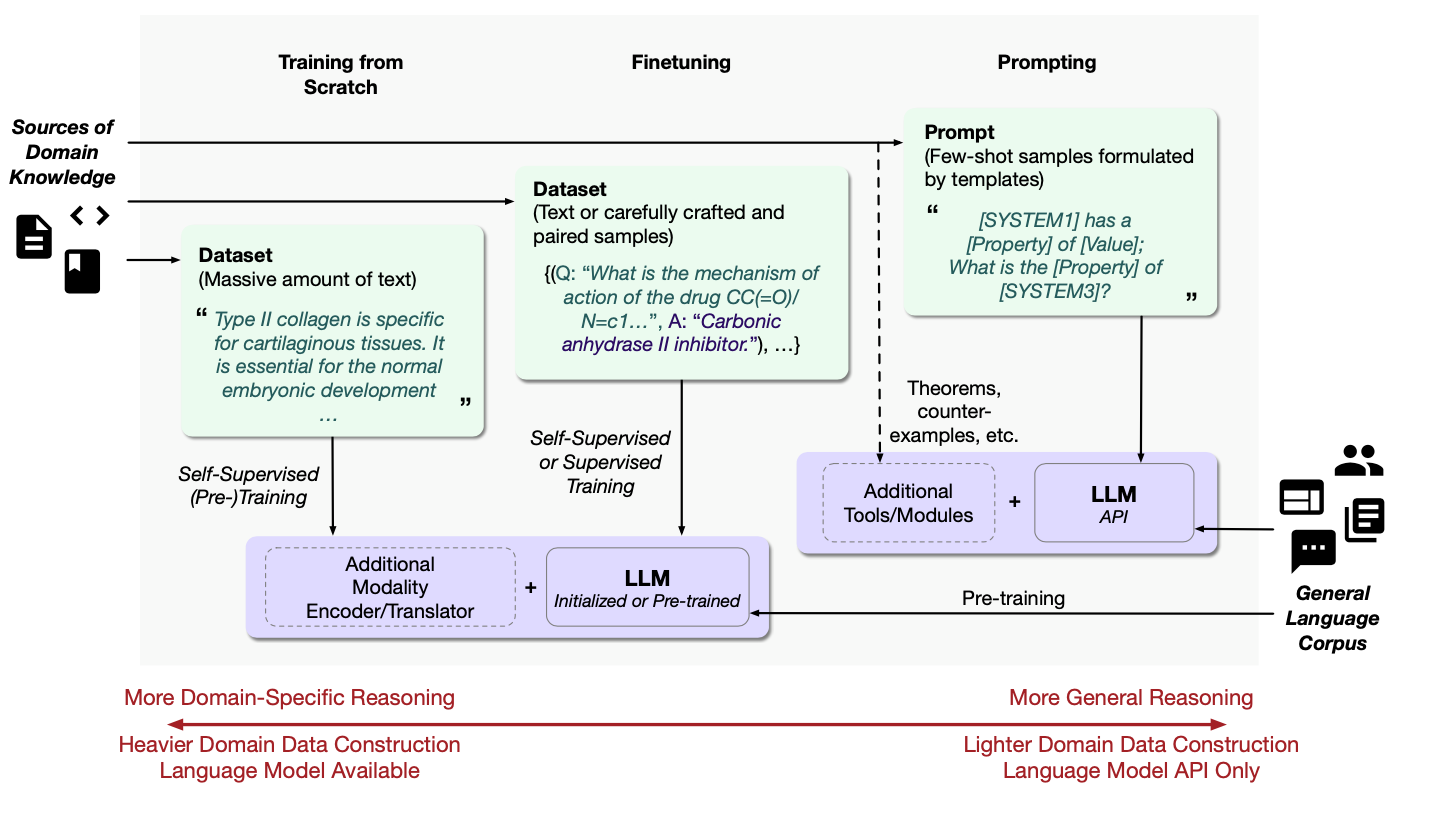
图38. 适应LLM到科学领域的三种范例。一个可以构建包含大量科学领域文本的数据集,并以自监督方式从头开始训练LLM。经过训练的模型可以直接使用,也可以进一步微调以用于特定任务。或者,可以使用较少数量的文本数据,以自监督或监督方式,从科学领域获得预训练的通用LLM。在具有API访问权限的专有LLM的情况下,可以通过使用精心设计的模板提示来适应模型,其中领域知识作为提示中的少数样本或作为具有附加工具或模块的显式知识提供。数据集示例分别来自Galactica [Taylor等人 2022]和ChEMBL [Liang等人 2023]。
由于最先进的LLM(如GPT-4 [OpenAI 2023])最近取得的成功和受欢迎程度,已经开始将这些通用指令调整型模型用于最具挑战性的科学发现。由于这些先进的LLM大多是专有的,具有API可用性,因此它们的科学领域适应通常是通过提示的方式实现的,这被称为上下文学习的少量或零量学习。具体而言,领域知识可以以理论、事实或示例的形式作为提示中的上下文提供。这种范式在社会科学[Zhong et al. 2023]和天文学[Sotnikov and Chaikova 2023]等学科中已经证明了其有效性。在分子领域,已经探索了这些模型中包含的关于语言[Castro Nascimento and Pimentel 2023]和代码生成[Hocky and White 2022; White et al. 2023]方面的化学知识。Guo等人[2023b]在化学领域的多项任务上对先进的LLM进行了基准测试,并展示了它们与专门用于任务的机器学习方法相比的竞争性性能。最近的工作,如CancerGPT [Li et al. 2023d]和SynerGPT [Edwards et al. 2023],还探讨了语言模型用于药物协同作用预测的应用。SynerGPT提出了用于上下文学习的新型LLM训练策略,以探索细胞中药物分子之间的更高级别的“相互作用”,并将其模型扩展到逆药物设计和标准化分析的上下文优化。所提出的训练策略可能会启用一种基于药物相互作用的新型基础模型。此外,一种特别有前途的途径是使用外部工具增强LLM,以便使复杂任务变成文本[Schick et al. 2023; Yao et al. 2023b],科学示例包括使用国家生物技术信息中心(NCBI)的Web API回答基因组学问题[Jin et al. 2023]。现有的LLM仅从非结构化文本进行预训练,无法捕获一些领域知识。近期为了赋能领域知识的LLM的解决方案包括开发轻量级的适配器框架,以选择和集成结构化领域知识以增强LLM [Lai et al. 2023],以及从通用领域到化学领域的知识蒸馏的数据增强 [Wang et al. 2023a]。外部领域工具还可以集成到语言模型提示中,允许这些“代理”访问外部领域知识[Bran et al. 2023; Boiko et al. 2023; Liu et al. 2023c]。具体来说,ChatDrug [Liu et al. 2023c]通过为LLM配备检索和领域反馈模块,使LLM能够以少量示例进行药物编辑。在回归和分类方面也进行了少量示例的工作[Jablonka et al. 2023],以及贝叶斯优化 [Ramos et al. 2023]。将这种范式推向极端,还有不同科学领域通常依赖于实际中以非常不同的模态呈现的数据,这使得LLM在许多应用中无法直接发挥作用。
基于基础和大型语言模型进行科学发现仍然存在一些挑战。我们确定并讨论了以下三个挑战和机会。
基础模型的数据获取:在为科学应用程序开发SSL和基础模型时,大规模数据获取面临重大挑战,主要是由于科学数据相对于通用互联网数据的专业性质而没有简单的方法解决。已经有一些现有的工作,比如从互联网收集特定领域的文本、从PubMedCentral的OpenAccess子集获取图像标题对[Lin et al. 2023e],以及从arXiv获取带标题的科学图像[Hsu et al. 2021]。然而,大多数这些工作集中在图像和文本模态上,与Web数据大部分重叠。需要更多工作来策划更多多样性模态的现实科学数据,比如感知数据和表格数据,以支持构建更定制的科学基础模型。数据稀缺性是基于语言的科学多模态的关键挑战,比如在分子-文本对上训练的模型。现有的工作已经尝试通过应用多语言预训练策略[Edwards et al. 2022]或使用实体链接从文献中提取大量嘈杂的分子-句子对来缓解这一挑战[Zeng et al. 2022; Su et al. 2022]。然而,从文献中提取出更少嘈杂、更完整的数据将极大地有益于这些任务。[Yang et al. 2023b]研究了使用语言模型从文献中提取额外的药物协同训练元组。
解决SSL和基础模型的算法挑战:除了数据外,科学领域SSL和基础模型的主要技术挑战通常包括在架构中合并多样化模态,为这些模态设计定制的预训练技术,以及解决域分布漂移问题。最近的方法主要集中在组合文本和图像模态[Liu et al. 2023b; Koh et al. 2023; Alayrac et al. 2022]以及更为广泛研究的科学单元,如分子和蛋白质,而较少关注其他模态,如图形[Huang et al. 2023b]、RNA表达[Rosen et al. 2023],以及更稀有的模态,如细菌基因组和粒子物理学[Tamkin et al. 2021]上的基准。最后,现实科学发现过程中的动态数据变化也迫使预训练模型面临域分布漂移,如Wilds基准[Koh et al. 2021]所示。需要更多基础性工作来设计用于多样化模态的强大SSL算法,以便在实践中应用AI于科学。对于LLMs,由于来自通用领域的知识通常过于庞大,发展超越感知器的更好的融合模型可能是一个有前途的未来方向。
将成功扩展到更广泛的AIRS主题:自监督学习(SSL)和基础模型在小分子、蛋白质和连续力学等领域表现出了有前途的性能。然而,它们在其他领域的方法和应用受到了较少关注。例如,在量子系统的背景下,SSL在探索相对较少。量子系统中的学习任务通常围绕着建模波函数展开,所使用的神经网络体系结构往往特定于点阵结构,使得系统或任务之间的知识转移具有挑战性。尽管如此,SSL在这些领域具有巨大潜力,因为未标记的数据分布可能包含有关底层对称性和物理规则的宝贵信息。SSL可以在这些领域中作为先验知识发挥关键作用,从而促进在各种系统中发现基本原则。此外,通过适应基础模型,还可以为具有有限数据的新兴和较少研究的领域的发现提供另一种有前途的途径。特别是,正如Taylor等人[2022]和Xu等人[2023b]所示,LLMs的文本性质使它们能够更有效、更灵活地捕获和转移不同系统之间的知识,弥合不同领域和数据模态之间的差距。
不确定性量化
作者:王宇澄,钱晓宁
AI用于科学任务中所涉及的复杂系统的特性分析和预测能力使科学发现以及自动生成能力的最优和稳健的决策成为可能。尽管在不同条件下为反向设计开发深度前向预测和生成模型取得了重大进展,但这些受物理约束的预测和生成模型,例如神经ODE [Chen et al. 2019a]和DeepONet [Raissi et al. 2020]中的可靠不确定性量化(UQ)对于保证在数据和模型不确定性下的稳健决策仍需要应用数学、计算科学和AI/ML研究人员的合作调查。这些研究领域已经开发了不同的UQ策略,从传统的贝叶斯模型敏感性分析,重点关注模型参数的子集,到最近的基于集成的深度贝叶斯学习中的UQ。在将这些UQ策略整合到前向预测和反向生成模型中时,可扩展性和效率是最重要的因素,以实现实践中的时效性预测和决策。
10.4.1 不确定性量化:介绍与背景
不确定性量化(UQ)已在应用数学、计算和信息科学的各个领域进行了研究,包括科学计算、统计建模,以及最近的机器学习。传统的UQ旨在定量评估预测不确定性或校准传统的基于物理原理的机械模型和数据驱动的机器学习模型的参数,以解决由于系统复杂性和数据不确定性引起的建模复杂系统的挑战 [Kennedy and O’Hagan 2001; Psaros et al. 2023]。当建模复杂系统时,计算模型的不确定性可以来自多个来源。首先,现实世界复杂系统的动态通常受多种潜在的内部和外部因素的调制。抽象的计算建模通常无法涵盖所有这些因素,要么是因为缺乏信息,要么是因为计算受限。一些影响系统结果的因素可能是未知的,或者被忽略了以进行模型构建。其次,即使包含了所有影响因素,由于缺乏知识,尤其是对于数据驱动的黑盒机器学习模型,所选模型本身可能被错误指定,存在潜在的归纳偏见。第三,要建模的系统动态本身可能是本质上随机的和非平稳的。第四,由于观察到的数据本身不可避免地是嘈杂的,甚至由于固有的传感器噪声或无法控制的环境因素的随机扰动而受损。最后,由于现代数字计算机硬件的有限精度,不同模型的数值结果可能仍然包含错误。所有这些不确定的来源都会为最终系统输出或模型预测的不确定性做出贡献。
Aleatoric和Epistemic Uncertainty: 在计算建模中已经确定并广泛研究的两种不确定性类型是随机不确定性和认知不确定性 [Kendall and Gal 2017; Hüllermeier and Waegeman 2021]。随机不确定性,也称为(a.k.a.)随机不确定性或数据不确定性,是指由于正在调查的物理过程的内在随机性而引起的不确定性。例如,在量子自旋系统中,即使已知系统的量子状态,计算基础的测量通常是随机的。在材料科学实验中,由于传感器测量的噪声几乎无法完全去除,相同条件下的实验结果可能存在一定程度的差异。在分子属性预测中,如果只提供了2D结构信息,由于未考虑实际的3D分子几何结构[Hirschfeld et al. 2020],预测的分子属性可能会有显著的不确定性。即使更多关于复杂系统的知识或补充数据变得可用,这些不确定性也是无法减少的。认知不确定性,也称为系统不确定性或模型不确定性,表示在建模复杂系统时,对其物理过程动态的知识不足所引起的不确定性。随着越来越多的知识或数据变得可用,认知不确定性可以减少或消除,因此已经开发出许多贝叶斯学习[Cohn et al. 1996; Lampinen and Vehtari 2001; Titterington 2004; Xue et al. 2016b; Qian and Dougherty 2016; Gal et al. 2017b; Goan and Fookes 2020; Boluki et al. 2020]、UQ [Yoon et al. 2013; Lakshminarayanan et al. 2017; Huang et al. 2017; Sensoy et al. 2018; Ardywibowo et al. 2019; Amini
et al. 2020; Wang et al. 2022b]、实验设计方法 [Kushner 1964; Mockus 2012; Mariet et al. 2020; Zhao et al. 2020; Lei et al. 2021; Griffiths 2023]作为有效和高效的解决方案策略。
不确定性量化的重要性:不确定性量化问题在各种学科中对复杂系统建模和科学发现至关重要。了解与某种预测相关的不确定性将有助于我们开发更可靠的模型,并做出更好的决策,特别是对于一些安全关键应用[McAllister 2017]。由于一些现代机器学习模型,如深度神经网络具有很大的逼近能力和表达能力,因此需要特别注意随机不确定性,以避免过拟合。此外,在线机器学习策略,如贝叶斯主动学习[Cohn et al. 1996; Gal et al. 2017b; Zhao et al. 2021a,c,b]和贝叶斯优化[Kushner 1964; Mockus 2012],可以与反向不确定性量化相结合,以促进新材料和化合物的发现[Solomou et al. 2018; Talapatra et al. 2018, 2019; Lei et al. 2021]。
10.4.2 计算科学中的不确定性量化
在计算科学中,不确定性的量化通常被分为前向不确定性传播和反向不确定性量化两类。前向不确定性传播的目标,又称为敏感性分析[Razavi et al. 2021; Rochman et al. 2014; Peherstorfer et al. 2018],是测量某个输入的随机性会导致系统输出的不确定性有多大。通过将输入因素或模型参数建模为具有相应概率分布的随机变量,可以通过前向不确定性传播来捕获系统输出的随机性或不确定性。在许多情况下,当计算模型过于复杂,以至于输出随机变量没有闭合形式的概率分布时,前向不确定性通常通过蒙特卡罗(MC)抽样来估计。其他用于减轻MC抽样高计算成本的前向UQ方法包括Taylor近似[Fornasini 2008]和其他代理建模策略[Box and Draper 2007],这些方法已扩展到深度学习中的UQ,如下一节所讨论的。
另一方面,反向不确定性量化,也称为模型校准[Malinverno and Briggs 2004; Nagel and Sudret 2016; Nagel 2019],旨在衡量我们对系统模型的相应参数或调节系统基础物理过程的输入因素的不确定性有多大,并进一步降低相关的不确定性。
解决反向UQ问题的一种强大方法是贝叶斯建模。与频率主义方法将参数建模为确定性变量并根据观测数据导出最佳拟合所选模型的点估计相比,贝叶斯方法将模型参数视为随机变量,并解决贝叶斯反问题以更新相应的概率,以得出遵循贝叶斯定理的某个结果的预测后信念。作为一个简单的例子,假设我们想量化系统输入𝑋的不确定性,并将相应的系统输出表示为𝑌,该输出可能带有噪声。贝叶斯定理表明:
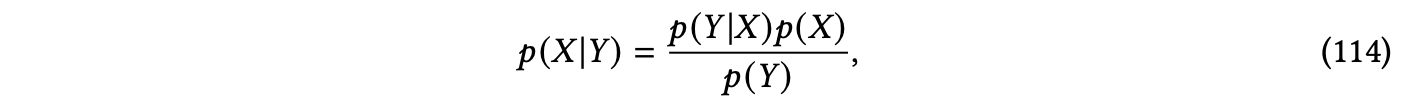
其中𝑃(𝑋)是先验分布,表示我们在没有任何观测𝑌的情况下对𝑋的先验信念,𝑃(𝑌|𝑋)是似然性,即在采用的模型假设下,给定𝑋的情况下系统输出为𝑌的概率分布。分母𝑃(𝑌)通常称为证据,即在𝑌的随机性上的边际分布𝑃(𝑌) = ∫𝑃(𝑌|𝑋)𝑃(𝑋)𝑑𝑋。后验分布𝑝(𝑋|𝑌)捕获了在观察到系统输出𝑌后我们对𝑋的更新信念。相同的思想可以应用于量化系统参数的不确定性。我们可以通过贝叶斯推断来量化反向不确定性,根据贝叶斯定理得出相应系统输入或模型参数的概率分布。
其他不确定性概念:尽管贝叶斯不确定性长期以来一直是各种应用中的主要不确定性概念,因其在应用数学和概率论中的简单性和稳健性,但除了贝叶斯不确定性之外,还有许多其他不确定性概念。这些包括其他具有概率预测的方法[Nix and Weigend 1994],制定区间预测[Koenker 2005; Angelopoulos and Bates 2021],为每个预测分配置信分数[Jumper et al. 2021],以及基于距离的不确定性[Sheridan et al. 2004; Liu and Wallqvist 2018; Hirschfeld et al. 2020]。最近,提出了一种称为第四类不确定性量化(UQ4K)的贝叶斯不确定性量化方法的变体[Bajgiran et al. 2022],旨在缓解“贝叶斯推断的脆弱性”,这是一种现象,即贝叶斯推断可能对先验的选择敏感[Owhadi et al. 2015]。在UQ4K中,作者在博弈论框架下开发了不确定性量化方法。通过在模型参数估计和先验分布之间的风险上进行一次最小最大游戏,作者提出了一种假设测试的不确定性概念,消除了先验的选择,并且不受“贝叶斯脆弱性”的影响。尽管与贝叶斯UQ方法相比,这些UQ方法探索较少,但它们可以在某些具有相应优势的应用中发挥作用,例如更低的计算成本、更好的可扩展性以及具有理论保证的解属性。
10.4.3 深度学习中的不确定性量化。
在机器学习中,大多数现有的UQ方法基于贝叶斯统计和概率论。一个具体的例子是贝叶斯线性回归[Box and Tiao 2011],它是线性回归的贝叶斯适应。贝叶斯线性回归类似地考虑了从输入𝒙到输出𝑦的线性参数化模型,具有观测噪声𝜖,但模型参数𝒘被视为具有贝叶斯推断的随机向量,以更新相应的后验分布,而不是求解确定性点估计。对于训练数据{𝒙,𝑦}𝑁,后验更新规则如下:
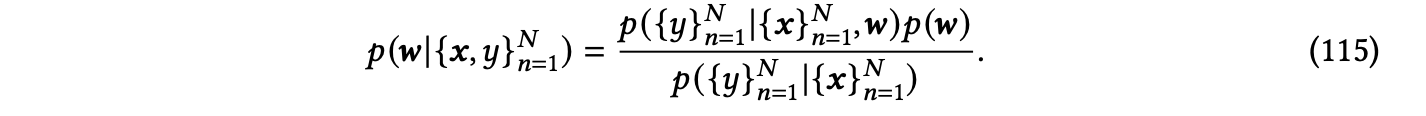
这种不确定性在𝒘的后验分布中得以很好地保留,可以进一步用于给定新的测试点𝒙ˆ的后验预测分布𝑦ˆ。将𝒙投影到核空间后,我们还可以进一步扩展到另一种流行的贝叶斯学习方法:高斯过程回归(Gaussian process regression,GPR)[Rasmussen and Williams 2006],它是核岭回归的贝叶斯适应。尽管许多机器学习模型在传统的频率学派方式下隐含地导出,但大多数模型都可以通过具备不确定性量化能力的贝叶斯对应模型来适应。
机器学习中还有其他非贝叶斯的不确定性量化方法,包括符合预测[Angelopoulos and Bates 2021]和分位数回归[Koenker 2005],其目标是预测结果预测的区间,而不是推导点估计或更新分布。
具备贝叶斯神经网络(Bayesian neural networks,BNNs)[Lampinen and Vehtari 2001; Titterington 2004; Goan and Fookes 2020]是贝叶斯训练人工神经网络(ANNs)的贝叶斯对应模型,通过将网络参数或激活建模为随机变量来实现。我们在这里使用一个回归问题来说明主要思想,并假设模型参数𝜽被建模为随机变量。
给定一个数据点𝒙和𝑓𝜽,𝑓𝜽是具有模型参数𝜽的预定的神经网络架构𝑓,通常将随机噪声𝝐添加到神经网络输出𝒚 = 𝑓𝜽 (𝒙)中,这隐含地指定了𝑝(𝒚|𝜽,𝒙,𝑓)分布,并在某些独立性假设下进一步表示为𝑝({𝒚}𝑁 |𝜽,{𝒙}𝑁 ,𝑓)。
噪声𝝐通常被建模为均值为零的高斯随机变量,其噪声可以是超参数,也可以是通过神经网络的数据相关的,这也被称为均值方差估计(mean variance estimation,MVE)[Nix and Weigend 1994]。
另一方面,认知不确定性是在有限的训练数据{𝒙,𝒚}𝑁 给定情况下模型参数𝜽的不确定性。根据贝叶斯定理,模型参数𝜽的后验分布可以推导为:
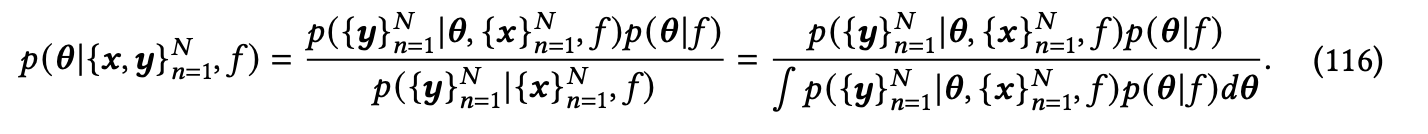
给定一个新的测试数据点𝒙ˆ,模型的预测是𝒚ˆ的边际分布:
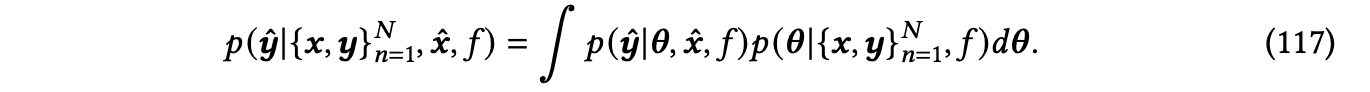
不确定性可以用模型参数𝜽的后验分布来进一步量化。给定新的测试数据点𝒙ˆ,模型预测是𝒚ˆ的边际分布:
𝒚ˆ|{𝒙,𝒚}𝑁,𝒙ˆ,𝑓 ~ 𝑝(𝒚ˆ|{𝒙,𝒚}𝑁,𝒙ˆ,𝑓)
其中,𝑝(𝒚ˆ|{𝒙,𝒚}𝑁,𝒙ˆ,𝑓)是给定已有数据{𝒙,𝒚}𝑁、新测试数据𝒙ˆ以及模型𝑓的情况下,𝒚ˆ的条件概率分布。其中,𝑁表示数据点的数量。
总的前向预测不确定性是指𝑝(𝒚ˆ|{𝒙,𝒚}𝑁,𝒙ˆ,𝑓)的不确定性,可以用不同的度量标准来量化,例如方差或(可微分的)熵。然而,计算𝑝(𝜽|{𝒙,𝒚}𝑁,𝑓)的分母∫ 𝑝({𝒚}𝑁|𝜽,{𝒙}𝑁,𝑓)𝑝(𝜽|𝑓)𝑑𝜽通常难以处理,这使得计算𝑝(𝜽|{𝒙,𝒚}𝑁,𝑓)变得困难。针对这个挑战,已经开发了多种基于马尔可夫链蒙特卡罗(MCMC)抽样及其梯度的变种方法,以及变分推断等不同的推断方法。关于不同近似推断方法的综合评述,我们建议读者参考Jospin等人的综述文章[Jospin et al. 2022]。
在现代深度神经网络(DNN)结构中,随着模型参数数量的增加,贝叶斯推断变得更具挑战性。许多最近的研究工作旨在扩展近似推断算法,特别是用于DNN架构的高效贝叶斯推断。一些常用的近似不确定性估计方法包括Bayes-by-backprop(BBB)[Blundell et al. 2015]、Monte Carlo dropout(MC dropout)[Gal and Ghahramani 2016; Gal et al. 2017a]和深度集成(ensemble)[Lakshminarayanan et al. 2017; Huang et al. 2017]。BBB是一种优化技巧,可以与反向传播算法和自动微分训练无缝耦合,当将神经网络参数建模为具有可重参数化的变分分布的随机变量时使用。MC dropout是一种简单而高效的方法,可以为任何使用了dropout的模型提供不确定性估计,而dropout是一种随机关闭部分神经元的正则化技术。通过在训练和测试时都执行dropout,MC dropout已被证明能够对随机神经网络权重进行近似推断。深度集成是另一种启发式策略,通过组合来自随机初始化或训练过程中多个“快照”的不同局部最优模型,实现了有效的预测不确定性估计。深度集成及其变种已被证明具有贝叶斯视角的解释。一些其他启发式方法进一步扩展了基于BNN推断的规模,方法包括将BNN与频率神经网络训练相结合。例如,Bayesian last layer(BLL)[Brosse et al. 2020]由于只将最后一层网络参数建模为随机变量而显著简化,因此在保留其他参数的点估计的前提下,可以显著减少不确定参数的数量,前提是早期层执行特征提取,而后期层执行最终的预测任务。这些近似推断方法可以单独使用,也可以组合在一起,以实现更好的不确定性估计和改进的可扩展性和计算效率。
Evidential Deep Learning(EDL)[Sensoy et al. 2018; Amini et al. 2020]是一种基于证据理论的深度学习的新兴不确定性估计策略。EDL明确考虑了缺乏证据的不确定性,即对于某种预测,没有数据支持的程度。在没有证据支持的情况下,测试数据的网络输出被鼓励成为预先定义的先验,而不是自信的预测。为了建模认知不确定性,EDL不同于将模型参数𝜽视为随机变量,而是引入了一个随机向量𝝅,其中预测分布现在变成了:
𝑝(𝒚ˆ|{𝒙,𝒚}𝑁,𝒙ˆ,𝑓) ~ 𝑝(𝒚ˆ|{𝒙,𝒚}𝑁,𝒙ˆ,𝑓,𝝅)
在这个情况下,不支持证据的测试数据的网络输出被鼓励成为预定义的先验,而不是自信的预测。这种方法可以用于建模认知不确定性。
在深度学习中,𝑝(𝒚ˆ|𝝅)通常是分类问题的分类分布,回归问题的高斯分布,与大多数现有的深度神经网络模型类似。随机向量𝝅的先验分布通常是𝑝(𝒚ˆ|𝝅)的共轭先验,然后神经网络模型是𝝅的似然:𝑝(𝒙ˆ|𝝅,𝜽,𝑓)。训练过程与通常的神经网络训练类似,除了额外的惩罚项,该项随着𝝅的后验分布远离先验分布而增加。一些EDL模型[Sensoy et al. 2018]也可以解释为在最后一层激活上执行摊销变分推断的BNN的特殊情况。EDL框架已经被证明在各种分类[Sensoy et al. 2018; Stadler et al. 2021]和回归任务[Amini et al. 2020]中,特别适用于检测分布之外的数据。在图学习中的不确定性量化:在建模不同系统组件之间的依赖性时,已经开发了图神经网络(GNN),在材料科学、分子生物学和量子力学等各种应用中取得了成功,如前面章节所述。专门为图学习开发的现有不确定性量化方法包括图DropConnect(GDC)[Hasanzadeh et al. 2020]、贝叶斯图卷积神经网络(BGCNN)[Zhang et al. 2019b; Pal et al. 2020]、图卷积网络的变分推断(VGCN)[Hasanzadeh et al. 2019; Hajiramezanali et al. 2019; Elinas et al. 2020]、图后验网络(GPN)[Stadler et al. 2021]、带图卷积的高斯过程
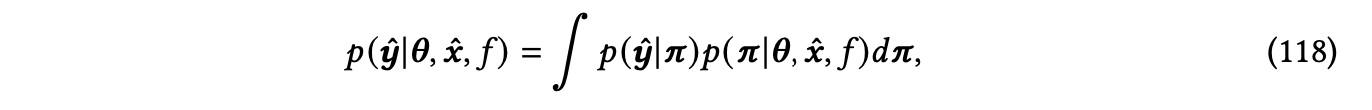
图39所示为分子能量预测任务上不同不确定性量化方法的示意图,其中 𝑦ˆ 表示给定分子的预测能量。这些方法包括:
- (a) Monte Carlo Dropout:通过将神经网络的权重建模为伯努利随机变量,Monte Carlo Dropout提供了不确定性量化的能力。
- (b) Bayesian Neural Network:贝叶斯神经网络将神经网络参数视为随机变量,并使用贝叶斯推断来量化参数的不确定性。
- (c) Mean Variance Estimation (MVE):MVE 是一种用于神经网络的不确定性估计的方法,结合了贝叶斯神经网络和均值方差估计,可以捕获随机不确定性和认知不确定性。
- (d) Graph Gaussian Process with Graph Convolution (GPGC):GPGC 是一种图高斯过程模型,其核函数定义在深层图卷积神经网络上,并通过变分引导点学习其参数。
- (e) Conformalized Graph Neural Network (CF-GNN):CF-GNN 是一种将符合性预测方法扩展到基于图的模型的方法,用于分类和回归任务,具有理论上的有效性条件。
这些方法用于量化模型预测的不确定性,有助于更可靠地评估模型的性能和可信度。
图39. 对分子能量预测任务上不同不确定性量化方法的示意图,其中𝑦ˆ表示给定分子的预测能量。请注意,(c) 贝叶斯神经网络可以进一步与均值方差估计结合使用,以捕获随机不确定性和认知不确定性。
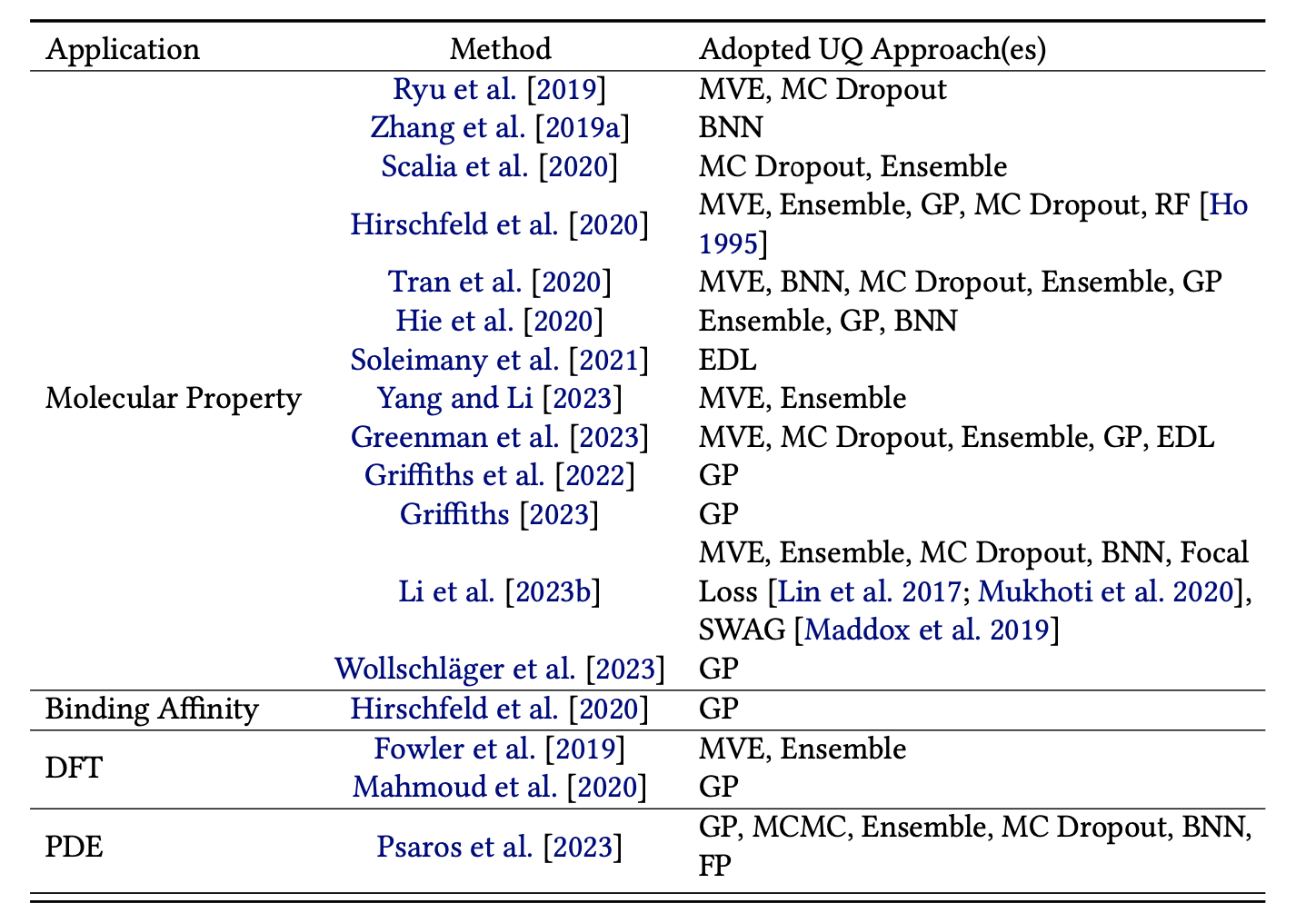
表33列出了关于偏微分方程代理解、密度泛函理论(DFT)相关任务、分子性质预测和化合物-蛋白质结合预测的不确定性量化研究和基准研究的现有研究和基准研究。
虽然之前的努力针对图学习中的不同不确定性进行了处理,但很少有研究实际量化和分析估计的不确定性。尽管最近在材料和蛋白质性质预测等各种图学习任务中取得了成功,但对于图学习中不确定性的适当处理仍然是一个未经深入探讨的领域。
10.4.4 AI在科学中的不确定性量化
与计算机视觉和自然语言处理等其他机器学习应用相比,科学AI中的数据稀缺性问题更加严重,因为实验通常昂贵且耗时,难以进行以收集有意义的数据。与任何现有的数据驱动的黑盒模型一样,基于深度神经网络(DNN)的科学AI模型可能对未见输入数据进行错误但过于自信的预测[Hein et al. 2019],而且对于对抗性攻击尤为脆弱[Goodfellow et al. 2014b]。因此,越来越多的人对这些科学AI模型进行不确定性量化的研究充满兴趣。已经进行了许多不同的基准研究和研究工作,以测试使用高斯过程(GP)[Hie et al. 2020; Mahmoud et al. 2020; Hirschfeld et al. 2020; Tran et al. 2020; Griffiths et al. 2022; Griffiths 2023; Wollschläger et al. 2023; Li et al. 2023b; Psaros et al. 2023; Greenman et al. 2023]、深度集成[Scalia et al. 2020; Hirschfeld et al. 2020; Tran et al. 2020; Yang and Li 2023; Mariet et al. 2020; Hie et al. 2020; Greenman et al. 2023; Li et al. 2023b]、MC Dropout [Ryu et al. 2019; Zhang et al. 2019a; Scalia et al. 2020; Hirschfeld et al. 2020; Tran et al. 2020; Greenman et al. 2023; Li et al. 2023b]、贝叶斯神经网络[Zhang et al. 2019a; Tran et al. 2020; Hie et al. 2020; Li et al. 2023b]和EDL[Soleimany et al. 2021; Greenman et al. 2023]来量化分子性质预测[Ryu et al. 2019; Zhang et al. 2019a; Scalia et al. 2020; Hirschfeld et al. 2020; Tran et al. 2020; Hie et al. 2020; Soleimany et al. 2021; Griffiths et al. 2022; Yang and Li 2023; Greenman et al. 2023; Griffiths 2023; Li et al. 2023b; ?]、化合物-蛋白质结合预测[Hirschfeld et al. 2020]、基态密度预测任务[Fowler et al. 2019; Mahmoud et al. 2020],以及具有物理信息的神经网络(PINN)的PDE代理预测任务[Psaros et al. 2023],以及地震反演[Smith et al. 2020, 2022]。我们总结了适用于上述学科的现有UQ研究和基准研究,采用的UQ方法如表33所示。
特别是对于化学和蛋白质分子性质预测任务,Ryu等人[2019]已经表明,基于MVE和MC Dropout的UQ方法可以用于评估数据质量。在Zhang等人[2019a]的研究中,实施了Stein变分梯度下降(SVGD)[Liu and Wang 2016]推断算法,用于BNN训练以建模认知不确定性,并表明这种实施可以用于减轻潜在的数据集偏差,并集成到主动学习循环中,以进一步提高数据效率。Soleimany等人[2021]进一步测试了通过EDL建模认知不确定性的想法,量化的不确定性与预测误差相关。Yang和Li[2023]还测试了基于MVE和Deep Ensemble的UQ在分子性质预测任务中的效果,证明了其在数据噪声识别和OOD数据检测方面的有效性。Griffiths等人[2022]和Griffiths[2023]使用GP来模拟分子性质预测和分子发现任务中不同类型的不确定性,这些任务已经进一步扩展为一个开源软件包,以促进现实世界的科学应用。
在与DFT相关的量子力学计算任务中,Fowler等人[2019]使用MVE和深度集成估计了不同类型的不确定性,用于预测基态电子密度,并表明量化的不确定性有助于检测不准确的预测。Mahmoud等人[2020]使用稀疏高斯过程来量化使用准粒子能级预测电子态密度的不确定性,并表明预测的不确定性可以识别有问题的测试结构。Tran等人[2020]在给定原子结构的情况下预测材料的吸附能量的任务中进行了UQ的基准研究,最佳性能模型
是在卷积神经网络的末端添加的GP。Wollschläger等人[2023]为分子力场提出了UQ的六个期望,进一步介绍了局部神经核(LNK),这是一种基于GNN的深度核,用于基于GP的不确定性量化,这是第一个满足六个期望的方法。
对于用于解决PDE问题的深度模型作为代理模型,Psaros等人[2023]通过在PINN和DeepONet上应用不同的UQ方法进行了全面研究,使用前向PDE问题、已知和未知噪声的混合PDE以及运算符学习问题的各种评估指标。作者还提出了将生成对抗网络(GAN)和GP组合为功能先验(FP)的方法,以利用历史数据并降低计算成本。尽管不同任务中不同方法的相对性能有所不同,但量化的不确定性被证明对于预测误差具有指示作用,并且有助于检测OOD数据。
还有一些基准研究旨在比较不同的UQ方法,包括信息对错误的信息性、数据拟合的可靠性和分子性质预测任务中的校准性。Scalia等人[2020]已经对化学分子性质预测任务的不同UQ方法进行了基准测试,结果有利于基于集成的UQ方法。在Hirschfeld等人[2020]的研究中,测试了小有机分子性质预测的不同UQ方法,结果显示基于GNN特征的随机森林(RF)[Ho 1995]和GP预测器可以提供最佳的UQ性能。Greenman等人[2023]对蛋白质性质预测的UQ进行了另一项基准研究,结果表明没有UQ方法可以始终比其他竞争性方法表现更好。Li等人[2023b]还对分子性质预测的UQ方法进行了基准测试,包括不同的训练方案、网络架构以及事后校准方法,其结果表明不同的UQ方法在不同的任务和不同的实验设置下可能优于其他方法。
总之,通过整合不同的UQ方法,现有的科学AI模型可以在不损害预测性能的情况下获得合理的不确定性。此外,量化的不确定性可以用于OOD数据检测[Fowler et al. 2019; Mahmoud et al. 2020; Yang and Li 2023]、数据噪声识别[Yang and Li 2023],并有潜力纳入主动学习[Zhang et al. 2019a; Soleimany et al. 2021; Hie et al. 2020]和贝叶斯实验设计[Hie et al. 2020]循环中,以进行数据高效模型训练和新分子发现。
10.4.5 开放性研究方向
不确定性量化(UQ)的评估:科学AI建模与其他机器学习任务的主要区别之一是,通常情况下,AI/ML模型被视为基于物理原理的计算代价更高的机械模型的替代品。尽管现有的研究和基准研究已经考虑了AI/ML代理的不同不确定性方面,设计了各种UQ评估指标,但由于模拟所有潜在的随机场景的计算成本过高,全面的UQ评估仍然具有挑战性。构建基于相应高保真计算方法的新基准数据集,并开发UQ评估指标,以帮助标准化科学AI的UQ并保证性能,可能至关重要。
具备领域知识的UQ方法的开发:正如许多现有的基准研究[Scalia et al. 2020; Hirschfeld et al. 2020; Psaros et al. 2023]所指出的,尽管某些UQ方法在特定任务上可能表现相对良好,但目前没有一种UQ方法可以始终在不同的评估指标和不同设置下胜过其他方法。由于没有普遍适用的UQ方法,许多现有的具有UQ能力的科学深度模型是通过经验性地测试不同的现有UQ方法来开发的。缺乏考虑物理或生物过程性质的UQ方法。未来的研究方向之一是开发具有集成领域知识的新的科学AI模型的UQ方法。
大规模模型的可扩展UQ方法:大多数现有的用于深度神经网络的UQ方法要么过于简单和受限以达到令人满意的UQ性能,例如MC dropout,要么在实践中计算成本过高,例如深度集成和BNN。随着具有数十亿参数的大型模型在自然语言处理和计算机视觉中占据越来越多的任务,越来越多的人对将这些大型模型应用于科学发现感兴趣。因此,开发新的UQ方法是一个有前途的研究方向,这些方法可扩展用于大型模型,并可以更好地在计算复杂性和量化不确定性质量之间进行权衡。已经开发了各种类型的近似启发式方法、随机梯度采样变种以及变分推断技术[Graves 2011; Welling and Teh 2011; Li et al. 2016b; Blundell et al. 2015; Shi et al. 2017; Gal and Ghahramani 2016; Gal et al. 2017a; Boluki et al. 2020; Dadaneh et al. 2020]。新的近似策略,包括最近的基于子空间的方法[Izmailov et al. 2019; Zhou et al. 2019; Dusenberry et al. 2020; Chen and Ghattas 2020; Boluki et al. 2023],可能有助于进一步扩大大型模型的UQ规模。