Python3
Python——ASCII编码与Unicode(UTF-8,UTF-16 和 UTF-32)编码
文章目录
- Python3
- 一、编码与编码格式
- 二、ASCII编码与UTF-8编码(UTF-16 和 UTF-32编码)
- 三、ASCII 字符串和 Unicode 字符串
最近看Python程序的文件头部声明时发现Python2中默认的编码格式为ASCII码格式,Python3中默认的编码格式为UTF-8格式,那么为什么随着Python的迭代,会改变其编码方式呢,两种编码方式的区别又有哪些呢?
一、编码与编码格式
- 编码:编码简单而言就是一种翻译的过程,将机器能够理解的语言转换为我们人类可以理解的语言。
- 编码方式:编码格式就是翻译的方式,根据对存储空间与编码效率的要求来选择不同的编码格式。
- 常见的编码格式:ASCII、ISO-8859-1、GB2312、GBK、UTF-8、UTF-16、UTF-32 等。
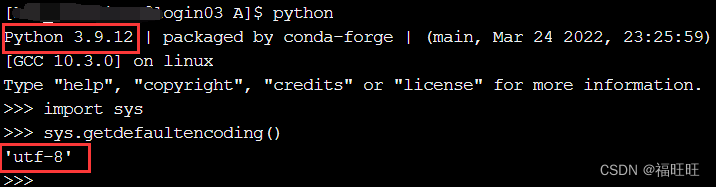
- 查看当前python环境下的默认编码格式:进入python后,在控制台下输入以下命令。
>>import sys
>>sys.getdefaultencoding()
//python2 为>>'ascii',python3 为>>'utf-8'
二、ASCII编码与UTF-8编码(UTF-16 和 UTF-32编码)
- ASCII 编码、UTF-8 编码、UTF-16 编码和 UTF-32 编码都是字符编码方式,用于表示文本字符在计算机中的存储和传输。
-
ASCII 编码(American Standard Code for Information Interchange):
- ASCII 编码最早于 1963 年发布,是一种基于 7 位二进制编码的字符集,用于表示英文字母、数字、标点符号和一些控制字符。
- ASCII 编码仅包含 128 个字符,使用 7 位二进制(0-127)表示。这包括了标准的英语字母、数字和一些常见符号。
- 由于其限制性,ASCII 主要适用于英语和一些西欧语言。
-
UTF-8 编码(Unicode Transformation Format - 8-bit):
- UTF-8 是一种变长字符编码,广泛用于表示 Unicode 字符集中的字符。
- UTF-8 使用 8 位字节(1 到 4 个字节)来表示字符,可以表示几乎所有的 Unicode 字符。
- ASCII 字符在 UTF-8 编码中与原始 ASCII 完全兼容,因此 ASCII 文本在 UTF-8 中也是有效的。
- UTF-8 是最常用的 Unicode 编码方式,因为它在表示英语和拉丁字符时非常高效,同时也可以表示各种语言的字符。
-
UTF-16 编码(Unicode Transformation Format - 16-bit):
- UTF-16 使用 16 位字节(2 个字节或 4 个字节)来表示字符,它是一种定长或变长编码方式,可以表示 Unicode 字符。
- UTF-16 可以有效地表示大多数 Unicode 字符,但对于一些罕见字符,需要使用 4 个字节。
- UTF-16 在处理多语言文本和大型字符集时比 UTF-8 效率更高,但相对于 ASCII 文本来说更占用存储空间。
-
UTF-32 编码(Unicode Transformation Format - 32-bit):
- UTF-32 使用 32 位字节(4 个字节)来表示每个字符,它是一种定长编码方式,能够表示 Unicode 字符。
- UTF-32 对于表示 Unicode 字符非常直观,每个字符都占用相同的存储空间。
- 由于每个字符都占用 4 个字节,UTF-32 编码通常占用更多的存储空间,但在某些特定应用中可能更方便。
- 总结:ASCII 编码适用于英语和一些西欧语言,而 UTF-8、UTF-16 和 UTF-32 是 Unicode 编码,用于支持全球范围内的多语言和字符集。UTF-8 是最常用的 Unicode 编码,因为它具有较高的效率和广泛的支持。UTF-16 和 UTF-32 精确性更高,但对存储空间的需求也更大,这两者在特定应用中也有用途,具体取决于字符需求和存储空间考虑。
- 为了代码更好的泛用性和移植性,所以Python3将编码方式从ASCII升级为UTF-8。
三、ASCII 字符串和 Unicode 字符串
关于ASCII和Unicode,两个版本中,其字符串的类型也有所变化。
- Python 2 中有 ASCII 字符串和 Unicode 字符串,分别用
str和unicode表示。 - Python 3 中默认的字符串类型是 Unicode 字符串,用
str表示,而 ASCII 字符串使用bytes表示。
- 区别
ASCII 字符串和 Unicode 字符串是两种不同的字符编码方式,它们之间有一些重要的区别:
-
字符集和编码方式:
- ASCII 字符串:ASCII(American Standard Code for Information Interchange)是一种最早的字符编码标准,最初设计用于英语和其他西欧语言。ASCII 字符集包含 128 个字符,包括英文字母、数字、标点符号和一些控制字符。ASCII 使用 7 位二进制来表示这些字符。
- Unicode 字符串:Unicode 是一个更广泛的字符编码标准,旨在涵盖世界上几乎所有的字符和符号,包括各种语言、符号、表情符号等。Unicode 字符集包含数千个字符,每个字符都有唯一的 Unicode 编码,可以使用不同的编码方式来表示,如 UTF-8、UTF-16 和 UTF-32。
-
字符表示:
- ASCII 字符串:ASCII 字符串中的字符是单字节的,即每个字符占用 8 位(1 字节)的内存空间。ASCII 字符集中的字符可以使用其对应的 ASCII 值来表示。
- Unicode 字符串:Unicode 字符串中的字符可以是多字节的,取决于所使用的编码方式。不同的编码方式会占用不同数量的字节,例如,UTF-8 使用变长编码,一个字符可以占用 1 到 4 个字节。
-
字符范围:
- ASCII 字符串:ASCII 字符集仅包含基本的英文字母、数字和一些常见符号,局限于英语和西欧语言的字符。
- Unicode 字符串:Unicode 包含了全球各种语言的字符,因此能够表示更多语言和符号,包括亚洲语言、阿拉伯字母、希腊字母、数学符号、表情符号等。
-
应用领域:
- ASCII 字符串:适用于英语和一些西欧语言的应用,通常用于较老的系统和传统的应用程序。
- Unicode 字符串:广泛用于现代应用程序、国际化应用、互联网和多语言环境中,能够处理多语言和多文化的字符需求。
- 总结,ASCII 字符串和 Unicode 字符串之间的主要区别在于字符集的范围和字符的表示方式。Unicode 提供了更广泛、更多样化的字符集,以满足全球化和多语言环境的需求,但可能需要更多的存储空间来表示字符,具体取决于所使用的编码方式。在现代应用程序中,使用 Unicode 编码通常是首选,以支持多语言和国际化需求。