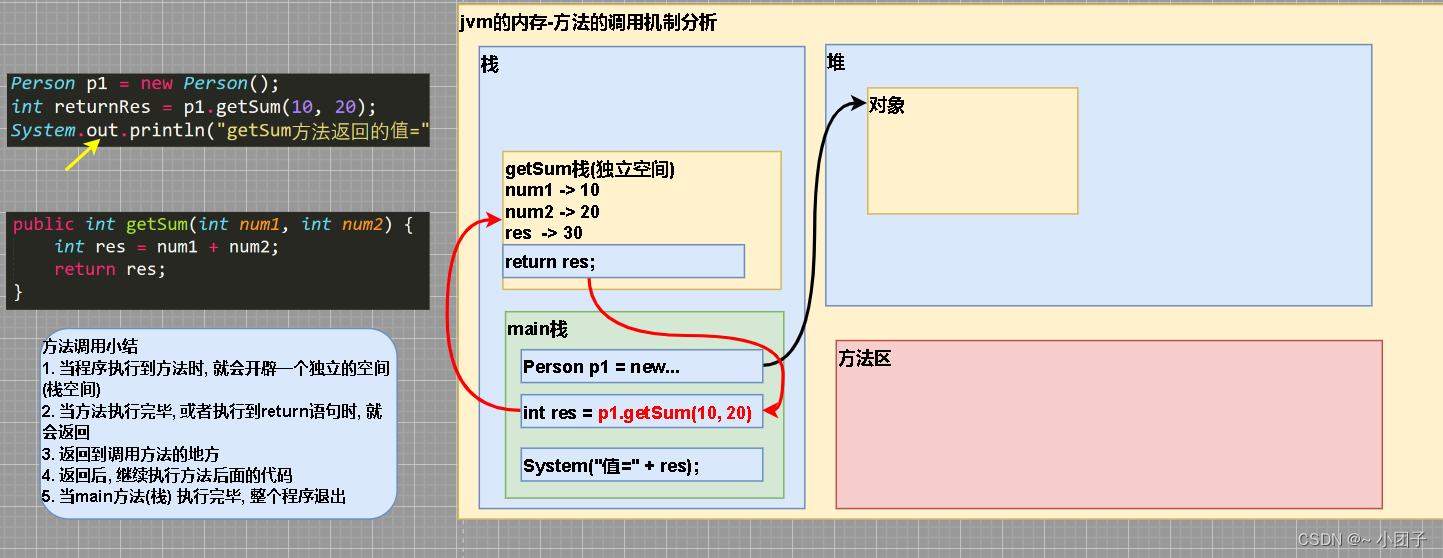
预加载一个3D数字人物模型(Digital Mark),该模型可以通过音频驱动进行面部动画。
用户上传音频文件作为输入。
将音频输入馈送到预训练的深度神经网络中。
Audio2Face加载预制的3d人头mesh
3D数字人物面部模型由大量顶点组成,每个顶点都有xyz坐标。
深度神经网络输入音频特征,输出是这些顶点在每个时刻的(载预制的3d人头)位移量(delta x, delta y, delta z)。
将网络输出的顶点位移量应用到人物面部模型的原始顶点位置上,就可以得到每个时刻面部形状变化后的新顶点坐标。
这样预制的人头mesh就被声音信号驱动了。
Audio2Face是如何实现retarget的?
Audio2Face就可以使用retarget技术将这些表情映射到目标角色上。它会自动分析源角色和目标角色的面部结构和特征,找出它们之间的对应关系,然后将源角色的面部表情映射到目标角色上。这样,目标角色就能够呈现出与源角色相同的面部表情。
需要注意的是,retarget技术的效果取决于源角色和目标角色之间的相似程度。如果它们之间的面部结构和特征差异较大,那么retarget后的效果可能会出现一些失真或不准确的情况。



![web:[SUCTF 2019]EasySQL](https://img-blog.csdnimg.cn/33c51131f7e84bfa95266d6cc34ee095.png)
![P1540 [NOIP2010 提高组] 机器翻译(模拟)](https://img-blog.csdnimg.cn/21b83901ff544bee8d82e15e20eae000.png)