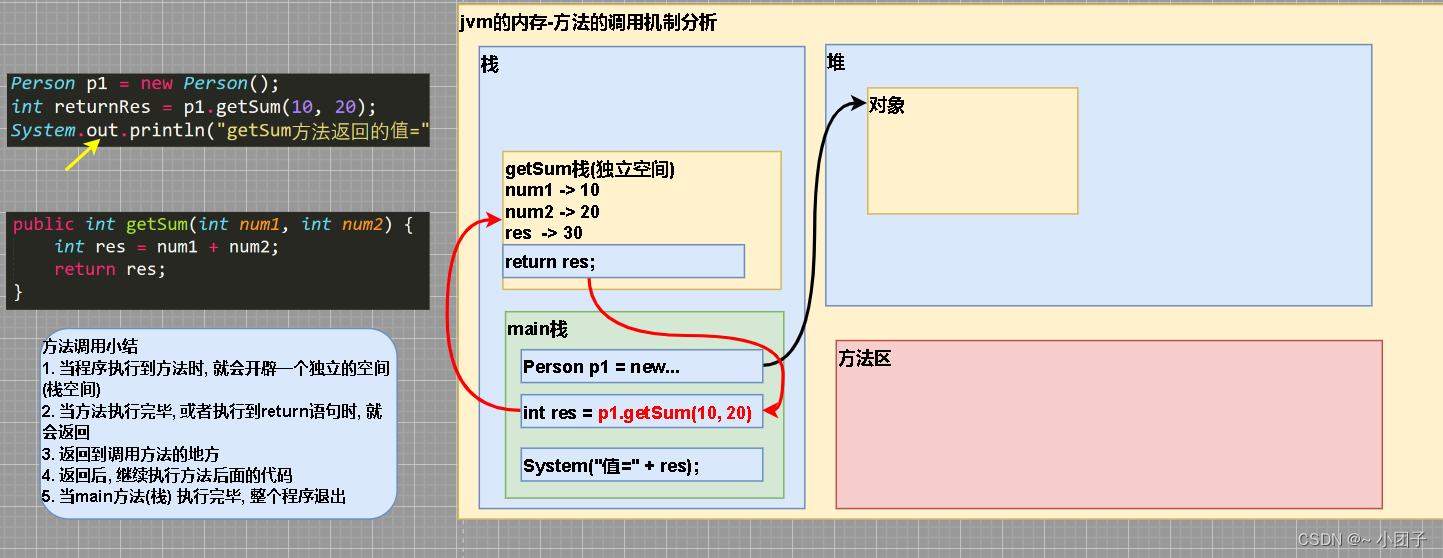
#爬取csdn个人首页中的所有封面
import requests
import json
import re
url='https://blog.csdn.net/community/home-api/v1/get-business-list?'
headers={'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.43'
}
img_mycsdn=[] #空列表存储所有封面网址
for pageNum in range(1,4):
params={
'page': pageNum,
'size': '20',
'businessType': 'lately',
'noMore': 'false',
'username': 'naozibuok',
}
resp=requests.get(url=url,headers=headers,params=params)
page_text=resp.text
#print(page_text)
with open ('D:\\Programming\\Microsoft VS Code Data\\WebCrawler\\data\\csdn\\'+str(pageNum)+'.json',
'+a',
encoding='utf-8'
) as fp:
json.dump(obj=page_text,fp=fp,ensure_ascii=False) #将对象page_text序列化为 json 格式并写入文件
print(pageNum,'页数据加载成功!')
ex='\\"picList\\":\[\\"([^"]*)\\"\]'# 正则表达式匹配每一页中的图片网址
page_img=re.findall(ex,page_text) # 使用正则表达式 ex 在 page_text 中匹配所有符合条件的子字符串,并将它们存储在 page_img 列表中
img_mycsdn+=page_img #将每一页的图片网址加入总列表
#print(img_mycsdn)
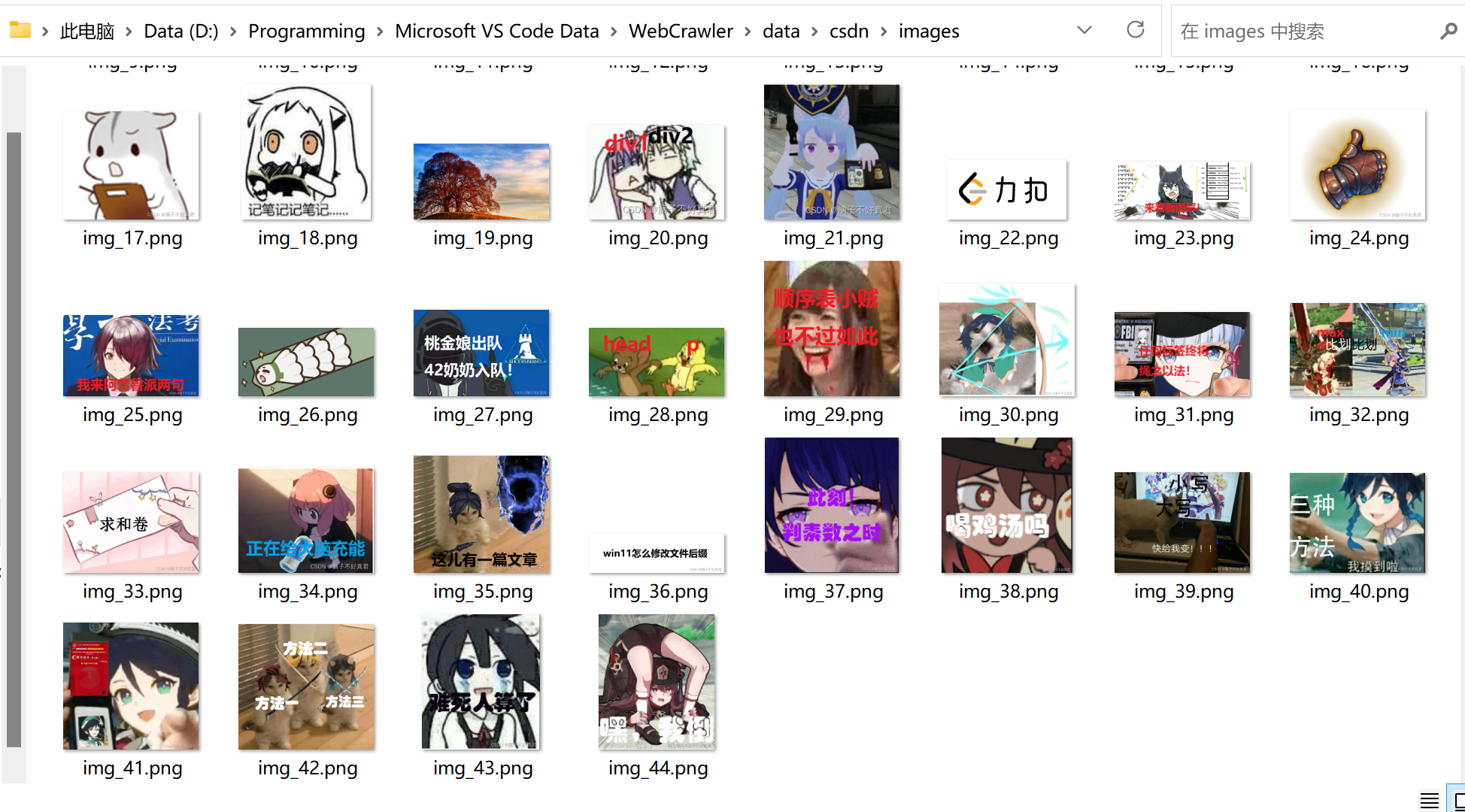
i=1 #i自加动态命名图片
for img_url in img_mycsdn:
final_img=requests.get(url=img_url).content #图片以二进制形式存储
img_name='img_'+str(i)
with open ('D:\\Programming\\Microsoft VS Code Data\\WebCrawler\\data\\csdn\\images\\'+img_name+'.png',
'ab',
) as fp:
fp.write(final_img)
print(img_name,'下载成功!')
i+=1
![P1540 [NOIP2010 提高组] 机器翻译(模拟)](https://img-blog.csdnimg.cn/21b83901ff544bee8d82e15e20eae000.png)