目录
- 位图概念
- 位图应用
- 布隆过滤器
- 简介
- 布隆过滤器的优缺点
- 布隆过滤器应用场景
- 布隆过滤器实现
- 布隆过滤器误判率分析
- 总结
位图概念

位图是一种数据结构,用于表示一组元素的存在或不存在,通常用于大规模数据集的快速查询。它基于一个位数组(或位向量),其中每个位代表一个元素,位的值表示该元素的存在或不存在。通常来说,位图中的每个元素都与一个唯一的整数索引相关联,通过这个索引来设置或检查相应的位。
位图的主要优点包括通过映射快速判断一个元素的两种状态,例如在一堆数据里面查询某一个数存不存在,这样就只需要查看这个数的映射位置判断0和1(用0和1来表示存不存在)。通常可以在常量时间内完成,因此具有非常高的查询性能。用位图来映射大量数据可以节省大量空间,因为在位图中不要用将原始数据进行存储,只需要将该数映射到某一个比特位,用这个比特位的0和1来表示这个数据的存在与否。因此对于包含大量元素的数据集,位图通常比使用其他数据结构(如哈希表)更节省内存。
但是,位图也有自己的一些限制,例如需要固定范围的整数索引,位图适用于需要表示整数范围内的元素集合,如果索引不是整数或者需要处理非常大的范围,可能不太适合。并且不支持元素的重复,每个元素在位图中只能表示存在或不存在,不能计数重复的元素。尽管如此,位图在生活的应用还是非常的广泛,位图通常用于各种应用,包括数据库管理、网络路由表、数据压缩和位集合运算等领域,它们在需要高效的集合操作时非常有用。
位图应用
当我们遇到这样一个问题,有40亿个不重复的无符号整数,并且没有排过序。现在给一个无符号整数,如何快速判断一个数是否在这40亿个数中?如果使用整形将数据进行存储然后遍历的话,那这个内存的消耗无疑是巨大的,可以粗略的计算下需要的空间,在32位系统下40亿个无符号整数大概占据160亿个字节,约等于16G。因此使用整型进行存储不是一个好的方案,这时候使用位图就会是一个很好的解决方案。
使用一个比特位的0和1来表示这个数的存在与不存在,用这个比特位的位置来映射这个数。因为一个字节有8个比特位,在32位系统下一个整型4个字节,即32个比特位,也就是一个整型可以映射32个整数,所以用位图的话只需要用大概512M的空间即可将所有数据进行映射。根据上述思路可以定义出如下的类:
template <size_t N>
class bits_set
{
public:
bits_set()
:_bits(N / 8 + 1)
{}
~bits_set()
{}
void set(size_t n)
{
size_t i = n / 8;
size_t j = n % 8;
_bits[i] |= (1 << j);
}
void reset(size_t n)
{
size_t i = n / 8;
size_t j = n % 8;
_bits[i] &= ~(1 << j);
}
bool test_bits(size_t n)
{
size_t i = n / 8;
size_t j = n % 8;
return (_bits[i] >> j) & 1;
}
private:
vector<char> _bits;
};
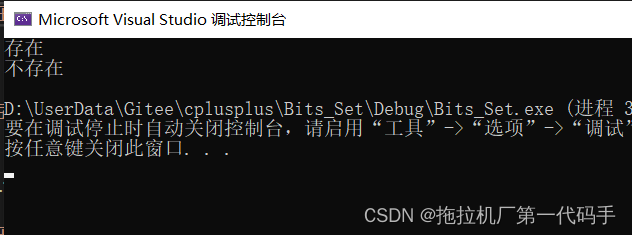
在定义时可以给出数据范围,然后对象自己开辟出相应的空间。类中提供了3个方法,set方法是将数字映射的位置置1,表示该数字读取到了,reset方法是将数字映射位置置0,表示该数字删除掉了,test_bits方法表示检查该数字是否存在。如下测试:
bits_set<10> bits;
bits.set(5);
bits.set(1);
bits.set(10);
if (bits.test_bits(10))
{
cout << "存在" << endl;
}
else
{
cout << "不存在" << endl;
}
bits.reset(10);
if (bits.test_bits(10))
{
cout << "存在" << endl;
}
else
{
cout << "不存在" << endl;
}
如果是40亿个整数,可以直接用0xFFFFFFFF或者-1来表示,如下:
bits_set<0xFFFFFFFF> bits;
//bits_set<-1> bits;
布隆过滤器

简介
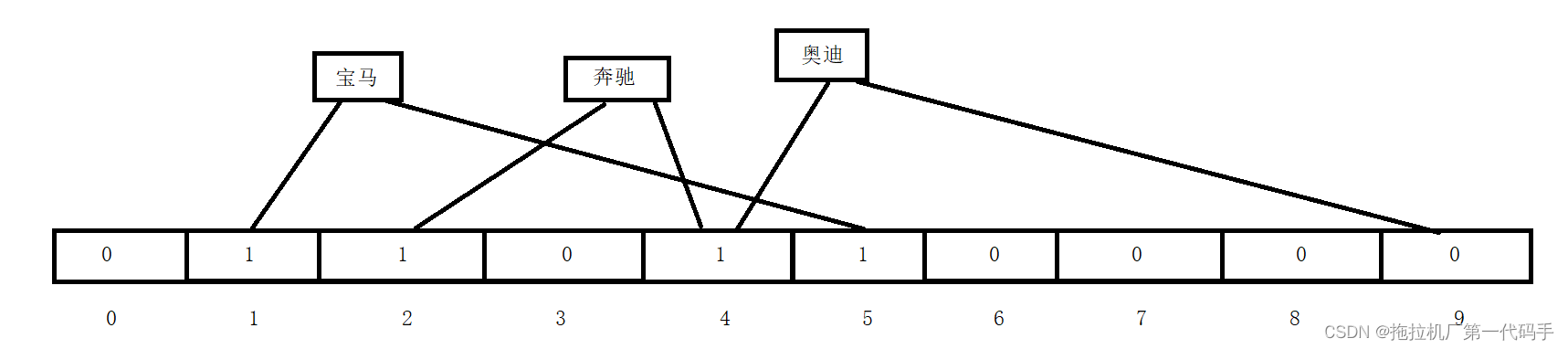
布隆过滤器(Bloom Filter)是由布隆于1970年提出的,是一种用于快速检查一个元素是否属于一个集合的概率型数据结构。它的设计初衷是为了解决数据库中的快速查找问题,特别是在大规模数据集合中判断一个元素是否存在。布隆过滤器的关键思想是使用多个哈希函数将元素映射到一个位数组中,通过多个哈希函数的多次映射,使得位数组中的多个位可能被设置为1。当查询一个元素时,同样的哈希函数会将该元素映射到相同的位上,如果所有对应的位都被设置为1,就认为元素可能存在。简单来说,布隆过滤器就是哈希和位图的有机结合。
布隆过滤器的优缺点
优点:
-
快速查询:布隆过滤器能够以常数时间复杂度进行元素的查询操作,无需遍历整个数据集合。
-
节省内存:相比于存储原始数据集合,布隆过滤器通常占用更少的内存空间,特别在处理大规模数据集合时,内存占用有显著优势。
-
高效的元素排除:它可以迅速排除大部分不可能存在的元素,减轻后续查询或操作的负担,提高系统性能。
-
保密性:布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势
限制:
-
误判率:布隆过滤器具有一定的误判率,即有可能判断一个元素存在于集合中,但实际上并不存在。误判率随着哈希函数数量和位数组大小的选择有关。
-
不支持删除操作:一般情况下一旦元素被添加到布隆过滤器中,就无法从中删除。这对于需要支持删除操作的应用不适用。
-
精确性限制:它不能提供精确的元素存在性检查,只能提供概率性的结果。
-
哈希函数依赖:布隆过滤器的性能高度依赖于哈希函数的选择和质量。
总的来说,布隆过滤器在某些特定场景下是非常有用的,特别是在需要快速查询和内存效率的应用中。然而,在应用时需要谨慎考虑误判率以及不支持删除操作等限制。
布隆过滤器应用场景
因为误判率的存在,布隆过滤器适合能够容忍一些误判的场景下来使用,例如注册界面下对一些用户感知不到的并且影响不大的信息处理就可以使用布隆过滤器,例如用户昵称。
布隆过滤器可以对用户的昵称进行快速筛选,因为布隆过滤器判断不存在是不会出现误判的,判断存在才会出现误判,所以布隆过滤器在这些场景下进行快速筛选的应用是非常广泛的。例如:
-
网络爬虫,用于快速排除已经爬取的网页或URL,避免重复爬取相同内容。
-
缓存系统,用于判断某个数据是否已经在缓存中,以减少数据库或文件系统的访问次数,提高性能。
-
防止重复提交:在Web应用中,用于防止用户重复提交表单或请求。
-
垃圾邮件过滤:用于过滤垃圾邮件,快速排除已知的垃圾邮件。
-
数据库查询优化:用于快速判断一个数据库中是否存在某个记录,减少昂贵的数据库查询操作。
-
资源管理:用于管理资源池中的资源,快速判断资源是否可用。
布隆过滤器实现
因为布隆过滤器是哈希和位图的有机结合,因此可以用上述的位图代码做布隆过滤器的底层容器。除此之外还需要提供哈希函数用来计算数据的映射,如下代码:
template<size_t N, size_t X = 5, class K = string,
class HashFunc1 = BKDRHash,
class HashFunc2 = APHash,
class HashFunc3 = DJBHash>
class BloomFilter
{
public:
void set(const K& key)
{
size_t len = X * N;
size_t hash1 = HashFunc1()(key) % len;
_bs.set(hash1);
size_t hash2 = HashFunc2()(key) % len;
_bs.set(hash2);
size_t hash3 = HashFunc3()(key) % len;
_bs.set(hash3);
}
bool test(const K& key)
{
size_t len = X * N;
size_t hash1 = HashFunc1()(key) % len;
if (!_bs.test_bits(hash1))
{
return false;
}
size_t hash2 = HashFunc2()(key) % len;
if (!_bs.test_bits(hash2))
{
return false;
}
size_t hash3 = HashFunc3()(key) % len;
if (!_bs.test_bits(hash3))
{
return false;
}
//可能误判
return true;
}
private:
bits_set<N * X> _bs;
};
这段代码定义了一个布隆过滤器类 BloomFilter,其中N是布隆过滤器的位数组大小。X是一个倍数,用于计算位数组的实际大小,即 X * N。K 是要插入和测试的元素的类型,默认为 string。HashFunc1、HashFunc2 和 HashFunc3 是哈希函数的类型,默认分别为 BKDRHash、APHash 和 DJBHash。
BKDRHash是一种简单的哈希函数,最初由Brian Kernighan和Dennis Ritchie提出。它的设计目标是快速计算字符串的哈希值,通常用于散列和哈希表中。BKDRHash的基本思想是将字符串中的每个字符都映射到一个32位整数,并通过一系列位运算来组合这些整数,最终得到字符串的哈希值。
struct BKDRHash
{
size_t operator()(const string& s)
{
size_t value = 0;
for (auto ch : s)
{
value *= 31;
value += ch;
}
return value;
}
};
APHash也称作Adler-32哈希,是一种非常快速的哈希函数,通常用于计算字符串的哈希值。它最初是Adler-32校验和算法的一部分,但后来被广泛用于哈希表和布隆过滤器等数据结构。APHash的核心思想是通过一系列位运算和异或操作来组合字符串的字符以生成哈希值。
struct APHash
{
size_t operator()(const string& s)
{
size_t hash = 0;
for (long i = 0; i < s.size(); i++)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ s[i] ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ s[i] ^ (hash >> 5)));
}
}
return hash;
}
};
DJBHash是一种哈希函数,它由Daniel J. Bernstein于1991年设计。DJBHash使用了一个常数5381作为初始哈希值,然后对字符串中的每个字符进行迭代处理。对于每个字符c,哈希值通过以下公式进行更新:hash = ((hash << 5) + hash) + c。最后,返回最终的哈希值。
struct DJBHash
{
size_t operator()(const string& s)
{
size_t hash = 5381;
for (auto ch : s)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
类中的 set 函数用于将元素插入布隆过滤器,它使用三个不同的哈希函数对元素进行哈希,并将对应的位数组位置设置为 1。test 函数用于测试元素是否存在于布隆过滤器中,它同样使用三个不同的哈希函数对元素进行哈希,并检查对应的位数组位置是否为 1。如果有任何一个位置为 0,则返回 false,表示元素不在布隆过滤器中;否则,返回 true,表示元素可能存在于布隆过滤器中。(可能存在误判)bits_set<N * X> 是一个位数组,用于存储布隆过滤器的位信息。
布隆过滤器误判率分析
因为布隆过滤器的误判是不可避免的,但是可以尽量去降低误判率,为了方便查看误判率,可以写一个程序来查看,如下代码:
const size_t N = 10000;
BloomFilter<N> bf;
vector<string> v1;
string url = "https://blog.csdn.net/wzh18907434168?spm=1010.2135.3001.5343";
for (size_t i = 0; i < N; ++i) {
v1.push_back(url + to_string(i));
}
for (const auto& str : v1) {
bf.set(str);
}
vector<string> v2;
for (size_t i = 0; i < N; ++i) {
std::string url = "https://blog.csdn.net/wzh18907434168?spm=1010.2135.3001.5343";
url += to_string(999999 + i);
v2.push_back(url);
}
size_t n2 = 0;
for (const auto& str : v2) {
if (bf.test(str)) {
++n2;
}
}
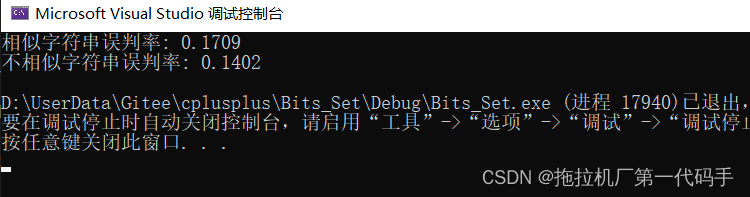
cout << "相似字符串误判率: " << (double)n2 / (double)N << endl;
vector<string> v3;
for (size_t i = 0; i < N; ++i) {
std::string url = "www.com";
url += to_string(i + rand());
v3.push_back(url);
}
size_t n3 = 0;
for (const auto& str : v3) {
if (bf.test(str)) {
++n3;
}
}
cout << "不相似字符串误判率: " << (double)n3 / (double)N << endl;
这段代码创建了一个布隆过滤器对象 bf,并进行了相似字符串集和不相似字符串集的测试。当X设置为4的时候,误判率如下:
当X设置为5的时候,误判率如下:

当X设置为6的时候,误判率如下:

可以看到,当X设置的值越大误判率就越低,但也并不是X设置的越大越好,X设置的越大空间开的就越大,误判率还跟提供的哈希函数有关,具体详情可以跳转详解布隆过滤器的原理,使用场景和注意事项。
总结
文章中介绍了位图和布隆过滤器的特点,应用场景,以及实现。总的来说,位图是一种存储和处理二进制数据的高效数据结构,特别适用于需要快速集合操作和大规模数据的应用。但需要谨慎选择使用场景,因为它不适用于所有类型的数据处理需求。布隆过滤器是一种用于快速估计元素存在性的数据结构,适用于某些特定的应用场景,但需要注意其误判率和容量的控制。没有那种数据结构可以适应所有的应用场景,只有它自己适用的场景,因此,选择合适的数据结构也是非常重要的。