目录
1、FlinkSQL客户端的功能
2、FlinkSQL客户端启动参数配置
2.1 基本语法
2.2 相关参数([MODE]):
2.3 相关参数(embedded [OPTIONS]):
3、启动Flink的sql-client
3.1 启动时使用初始化脚本
3.2 启动时指定依赖的jar包
3.3 基于yarn-session模式 启动
4、FlinkSQL客户端中的常用配置
4.1 查询结果显示模式配置
4.2 并行度配置
4.3 指定状态的TTL(状态空闲时间)
4.4 指定执行模式
4.5 指定自定义JobName
1、FlinkSQL客户端的功能
提供一个客户端,不需要写一行java或scala代码,只需通过写SQL的方式就能向Flink集群提交流式计算任务。
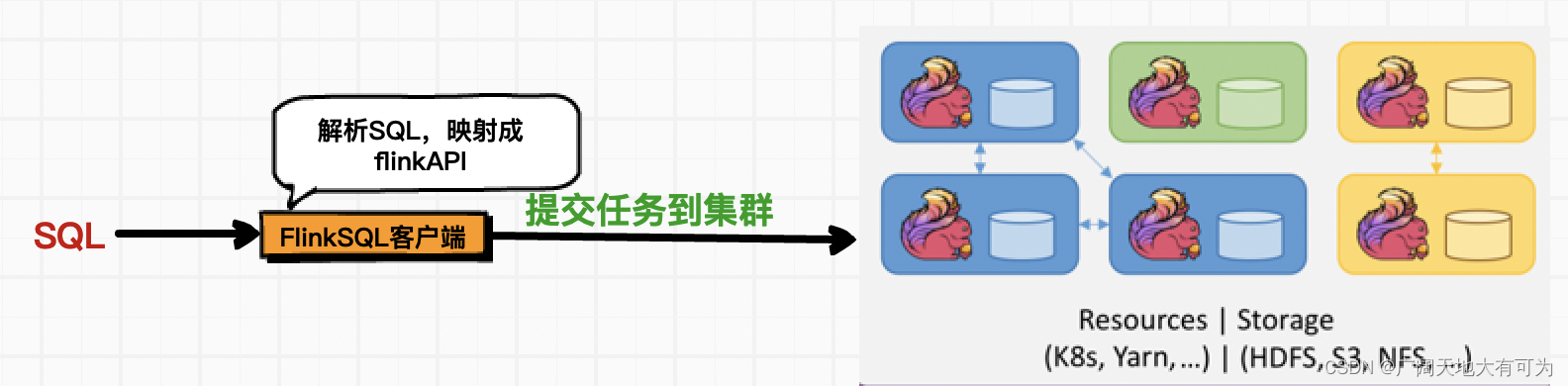
2、FlinkSQL客户端启动参数配置
2.1 基本语法
./sql-client [MODE] [OPTIONS]2.2 相关参数([MODE]):
MODE = embedded
默认选项 表示从本地机器提交Flink作业
MODE = gateway
表示通过SQL网关进行提交2.3 相关参数(embedded [OPTIONS]):
-f,--file <script file>
运行指定的SQL脚本,注意:在此模式下,客户端无法打开交互终端
-hist,--history <History file path>
指定保存历史命令(交互终端)的文件,不指定时,将生成在默认位置 /home/.flink-sql-history
-i,--init <initialization file>
指定初始化客户端的SQL脚本,如果SQL报错客户端将退出
注意:这个文件里不允许添加查询或插入语句
-j,--jar <JAR file>
指定依赖的jar包
-s,--session <session identifier>3、启动Flink的sql-client
3.1 启动时使用初始化脚本
bin/sql-client.sh -i init.sql3.2 启动时指定依赖的jar包
bin/sql-client.sh -j /xxx/FlinkAPI1.17-1.0-SNAPSHOT.jar
3.3 基于yarn-session模式 启动
不指定 -s yarn-session,默认为 standlone模式
# step1:启动yarn-session
bin/yarn-session.sh -d
# step2:启动Flink的sql-client
bin/sql-client.sh embedded -s yarn-session4、FlinkSQL客户端中的常用配置
4.1 查询结果显示模式配置
表格模式(table mode):
在内存中实体化结果,并将结果用规则的分页表格可视化展示出来
SET 'sql-client.execution.result-mode' = 'table';
变更日志模式(changelog mode):
不会实体化和可视化结果,而是由插入(+)和撤销(-)组成的持续查询产生结果流。
SET 'sql-client.execution.result-mode' = 'changelog';
Tableau模式(tableau mode)- 推荐:
更接近传统的数据库,会将执行的结果以制表的形式直接打在屏幕之上。具体显示的内容会取决于作业 执行模式的不同(execution.type):
SET 'sql-client.execution.result-mode' = 'tableau';
流执行模式:streaming
 批执行模式:batch
批执行模式:batch

4.2 并行度配置
指定默认并行度(默认为1):
# TODO 指定并行度
set parallelism.default=1;指定最大并行度:
# TODO 指定最大并行度
SET 'pipeline.max-parallelism' = '10';4.3 指定状态的TTL(状态空闲时间)
# TODO 指定状态的TTL(状态空闲时间)
set table.exec.state.ttl=1000;4.4 指定执行模式
# TODO 指定执行模式(批执行模式:batch、流执行模式:streaming) 默认为streaming模式
set execution.runtime-mode=batch;4.5 指定自定义JobName
# TODO 定义自定义作业名称
SET 'pipeline.name' = 'kafka-to-hive';