9 偏微分方程的人工智能
在本节中,我们详细介绍了用于解决偏微分方程(Partial Differential Equations,PDEs)的人工智能领域的进展。我们在第9.1节中概述了PDE建模的一般形式,并阐述了在这个背景下使用机器学习方法的动机。我们在第9.2节讨论正向问题,第9.3节讨论反向问题。
9.1 概述
作者:Jacob Helwig,Ameya Daigavane,Tess Smidt,Shuiwang Ji
PDE在数学上通过未知的多变量函数及其偏导数来描述系统的行为。PDE经常被应用于各种学科,以模拟物理过程的时空演化,例如使用Navier-Stokes方程来模拟翼型周围的气流[L
i et al. 2022b; Bonnet et al. 2022],使用浅水方程来模拟全球气象模式[Gupta and Brandstetter 2022],或使用Maxwell方程来进行光学设计[Brandstetter et al. 2023]。PDE建模的其他现实世界应用包括天气预测[Pathak et al. 2022]、二氧化碳储存[Wen et al. 2022, 2023]、地震波传播[Yang et al. 2021a; Sun et al. 2022; Yang et al. 2023a; Sun et al. 2023]、材料科学和火山活动[Rahman et al. 2022a]。在许多现实世界应用中,获得PDE解的函数形式可能是棘手的,因此必须通过数值方法来求解PDE。由于PDE建模的广泛应用,已经有一个世纪的时间用于开发数值PDE求解器[Brandstetter et al. 2022c]。
经典求解器依赖于对导数的离散数值近似[Quarteroni and Valli 2008; Bartels 2016],例如形式如下的前向差分逼近:

这些逼近方法在步长 Δ𝑥 减小到0时精度提高。这将将PDE简化为一组(可能是非线性的)方程,可以明确求解 - 在这种情况下,时间 𝑡 的解是使用先前时间 𝑡 ′ < 𝑡 的解来确定的 - 或者隐式求解 - 在这种情况下,解被一次性计算出所有时间。明确的方案比隐式的方案更容易实现,但通常需要更小的步长才能达到类似的精度,甚至对于可能出现尖锐不连续性的刚性问题,为了收敛也可能需要更小的步长 [Courant et al. 1928]。
虽然已经证明了像有限元法(Finite Element Method,FEM)和有限差分法(Finite Difference Method,FDM)[Quarteroni and Valli 2008;Bartels 2016]这样的经典方法是有效的,但它们需要高计算工作量。此外,它们通常需要根据PDE解的行为因方程和设置的不同而在任务基础上进行仔细调整,以确保数值稳定性。在PDE建模的工业应用中普遍存在的大型系统可能需要大量的计算资源,甚至需要数百甚至数千个CPU小时[Lam et al. 2022]。
为了解决这些缺点,深度学习模型已经成为一个通用框架,可以比它们的数值对应物快上数个数量级地生成解。这种效率主要通过神经网络在推断过程中能够采用更大的时间步长、在更粗糙的空间离散化上进行学习,以及使用明确的前向方法而不是隐式方法来实现的[Pfaff et al. 2021; Stachenfeld et al. 2021]。
与隐式方案的耗时迭代方法不同,神经求解器学习了从过去状态到未来状态的直接映射,对数据的分辨率没有那么多限制[Kochkov et al. 2021b]。此外,神经求解器可以轻松地通过并行化的GPU操作进行优化和评估,而与其迭代性质相比,GPU兼容的经典求解器的设计可能提供有限的好处,而且还需要对复杂的数值方法有深入的了解。最重要的是,这些模型具有适应手头任务的能力,并可以经过训练以概括初始条件[Li et al. 2021b;Gupta and Brandstetter 2022]和PDE参数[Brandstetter et al. 2022c;Tran et al. 2021]。此外,与经典求解器不同,神经求解器可以直接从观察到的数据中学习动态,这一能力在底层方程未知的情况下特别有用[Lienen and Günnemann 2022]。
受到它们在PDE建模的工业应用中的突出地位以及它们的挑战性质的激发,许多研究致力于为时间演化型PDE类别设计神经求解器。形式上,时间演化型PDE是一组方程,关联了一个未知函数 𝑢 : 𝑈 → R𝑚 在空间和时间上的导数[Olver 2014],其中 𝑈 = X×T 包括空间域 X 和时间域 T。给定 𝑈,我们考虑由一组方程给出的时间演化型PDE[Brunton and Kutz 2023;Evans 2022]。
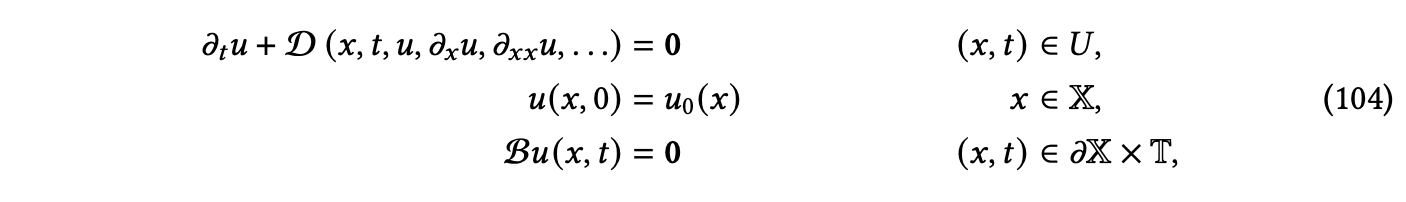
在这里,D 是一个运算符,它关联了空间-时间域 U 上解 u 的偏导数,B 是一个微分运算符,它关联了空间域边界 ∂X 上的导数,u0 是描述 t = 0 时刻 u 的初始条件。要解决这个偏微分方程,我们必须找到一个函数 u(x, t; γ),满足方程(104)中的约束,可以是解析形式或数值形式,其中 γ = (u0, B, γP) 表示描述初始条件 u0、边界条件 B 和偏微分方程参数 γP 的 PDE 配置。有几种深度学习框架用于逼近这个解。在第9.2节中讨论的前向问题的方法利用了一个预测模型作为一个学习的求解器,将过去的数值解映射到未来的解。另外,第9.3节详细讨论了反问题和反向设计,考虑了相反的方向,任务是从观察到的解数据映射到底层方程的初始条件、边界条件或偏微分方程参数,或者基于某些准则来优化系统的设计。
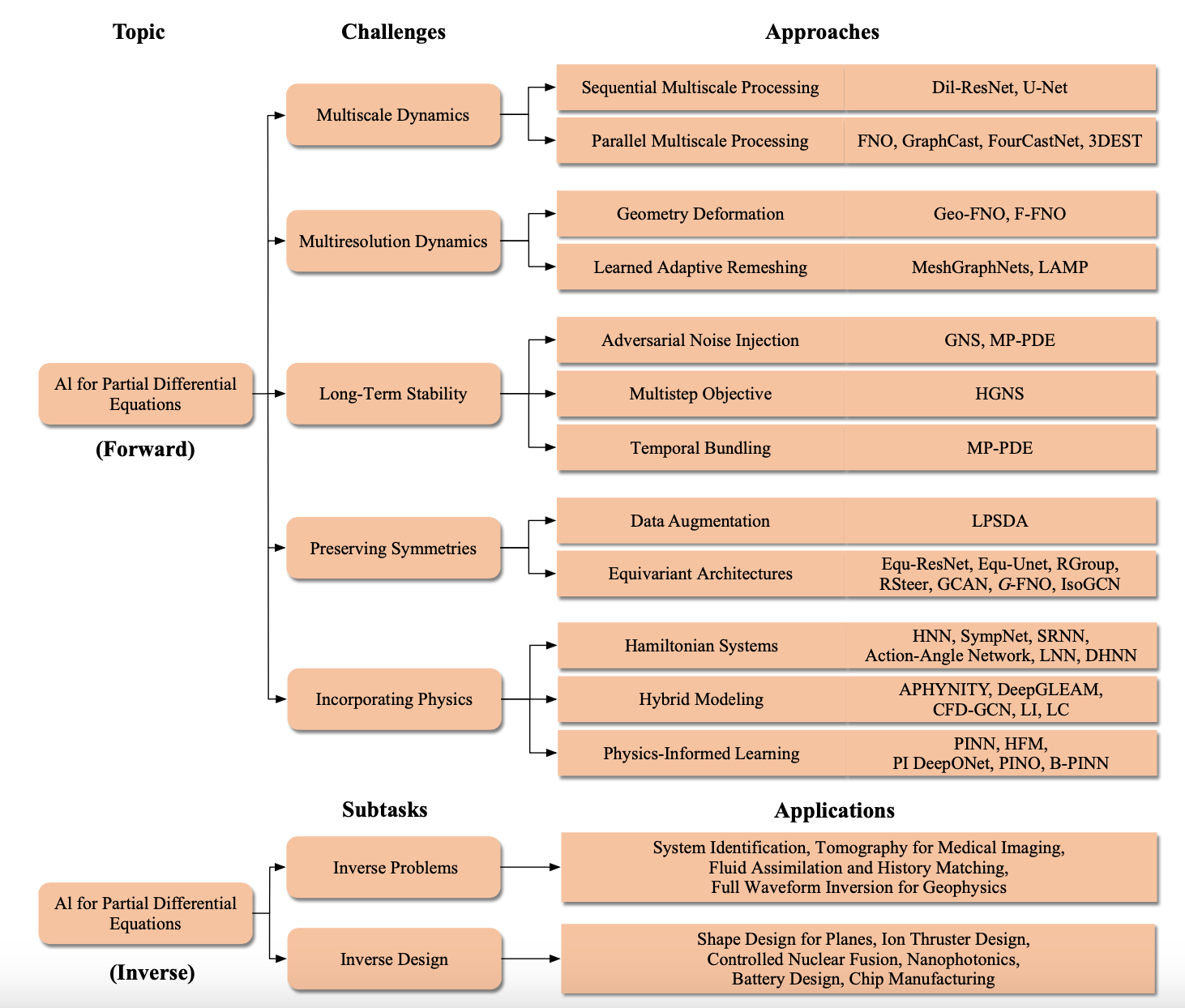
图32. 偏微分方程(PDEs)的前向建模和反向建模的人工智能概览。在第9.2节中,我们考虑前向建模任务,即从PDE的数值解的初始时间步到后续时间步的映射。我们确定并详细介绍了定义神经PDE求解器发展的四个基本挑战。多尺度动态出现在物理学在从局部到全局尺度的连续演化的系统中[Stachenfeld et al. 2021; Gupta and Brandstetter 2022; Li et al. 2021b; Liu et al. 2022b; Lam et al. 2022; Pathak et al. 2022; Bi et al. 2022; Rui Wang 2020; Li et al. 2021c],而多分辨率动态出现在具有快速演化的孤立区域的系统中,这些区域需要更多资源来进行稳定的模拟[Li et al. 2022b; Tran et al. 2021; Pfaff et al. 2021; Wu et al. 2022a]。使用明确方案的求解器,在这种方案中,系统在下一个时间步的状态是从当前时间步计算出来的,会遇到由先前预测引入的输入误差,因此必须考虑维持推出稳定性的方法[Sanchez-Gonzalez et al. 2020; Brandstetter et al. 2022c; Wu et al. 2022c]。等变结构和训练技术强制执行系统的对称性,从而实现了改进的泛化和样本复杂性[Brandstetter et al. 2022b; Wang et al. 2021a, 2022i; Ruhe et al. 2023; Horie et al. 2021; Helwig et al. 2023]。最后,将物理学引入架构中可以使预测保持物理一致性,并降低了学习任务的难度,否则模型将被赋予从训练数据中提取物理定律的任务[Greydanus et al. 2019; Jin et al. 2020; Chen et al. 2020b; Daigavane et al. 2022; Cranmer et al. 2020; Sosanya and Greydanus 2022; Yin et al. 2021; Wu et al. 2021; Belbute-Peres et al. 2020; Kochkov et al. 2021b; Tompson et al. 2017; Raissi et al. 2019, 2020; Wang et al. 2021b; Li et al. 2021g; Yang et al. 2021b]。在第9.3节中,我们考虑了反向建模任务,包括反问题和反向设计。具体而言,反问题考虑的任务是在观察到的动态基础上推断系统的未知参数,而反向设计的任务是基于预定义的目标来优化系统。这两个反向建模的子任务在科学和工程领域有各种各样的应用。
9.2 前向建模
作者:Jacob Helwig,Ameya Daigavane,Rui Wang,Kamyar Azizzadenesheli,Anima Anandkumar,Rose Yu,Tess Smidt,Shuiwang Ji
在这一节中,我们概述了为前向PDE问题开发的机器学习模型的进展。在第9.2.1节中,我们为神经PDE求解器正式定义了前向任务,然后在第9.2.2节中概述了塑造其发展的主要挑战。在第9.2.3到第9.2.7节中,我们讨论了应对这些挑战而出现的模型和技术,以及这些模型的数据集和基准测试,然后在第9.2.8节中总结了余下的挑战和未来方向的讨论。
9.2.1 问题设置
在前向问题中,模型的任务是根据初始条件或历史观测作为输入,预测系统的未来状态[Kovachki et al. 2021;Li et al. 2021g, c;Brandstetter et al. 2022c;Gupta and Brandstetter 2022;Li et al. 2021b;Sanchez-Gonzalez et al. 2020;Stachenfeld et al. 2021;Wen et al. 2023;Yang et al. 2023a]。模型在一组数值解𝑢(𝑗)𝑛上进行训练,其中𝑢(𝑗)(𝑥,𝑡)B𝑢(𝑥,𝑡;𝛾(𝑗)),而PDE配置𝛾(𝑗)因 𝑗=1 设置而异。例如,𝛾 ( 𝑗 ) 可以对应于不同的初始条件[Li et al. 2021b;Rahman et al. 2022b;Gupta and Brandstetter 2022] 或 PDE 参数[Li et al. 2020b;Yang et al. 2021a;Brandstetter et al. 2022c;Tran et al. 2021]。
数值PDE解将解域 𝑈 离散成一组有限的配点,求解器将在这些点上近似解函数的值。对于PDE解𝑢,将𝑢𝑡表示为时间域𝑇的均匀离散化中的第 𝑡 个时间步,即,𝑢𝑡 (𝑥) B 𝑢(𝑥,𝑡Δ𝑇 ),其中𝑥是空间域 X 离散化的任何点。此外,让连续时间点上的PDE解被表示为𝑢𝑘:(𝑘+𝐾) B {𝑢𝑘,𝑢𝑘+1,...,𝑢𝑘+𝐾}。然后,动态预测任务被定义为:
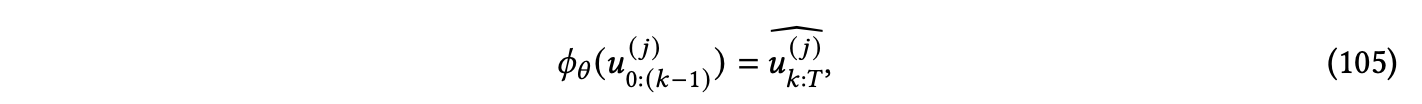
其中,𝜙𝜃 是根据适当选择的损失 L 进行优化的。
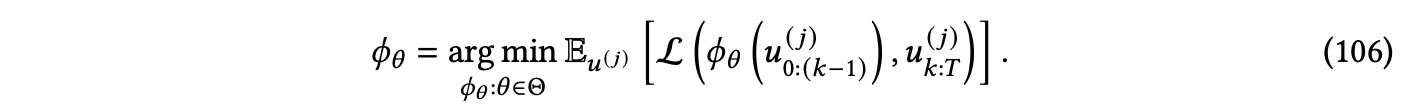
在许多情况下,PDE的形式会产生一个解集,它在对称群 𝐺 的作用下是封闭的。也就是说,如果 𝑢 是满足方程(104)的函数,那么对于所有的群元素 𝑔 ∈ 𝐺 ,𝐿𝑔𝑢 也满足方程(104),其中对于一个函数 𝑓 ,𝐿𝑔 𝑓 (𝑥) B 𝑓 (𝑔−1𝑥) 表示通过 𝑔 转化的 𝑓 。在这种情况下,希望限制模型的搜索空间,以使这些对称性能够自动受到尊重,即 𝜙𝜃 𝐿𝑔𝑢0 = 𝐿𝑔𝜙𝜃 (𝑢0)。已经证明,通过在等变体系结构中明确编码这些约束,如等变CNNs[Wang et al. 2021a;Helwig et al. 2023]和等变GCNs[Horie et al. 2021],以及通过数据增强[Brandstetter et al. 2022b],可以提高学习求解器的泛化能力和样本复杂性。我们将在第9.2.6节中进一步讨论这一点。
9.2.2 技术挑战
接下来,我们将识别出在前向建模环境中神经求解器所遇到的五个关键挑战,每一个挑战都引发了各种解决方案,塑造了PDE建模领域机器学习研究的发展。
多尺度动态(第9.2.3节):由于物理现象在多个空间尺度上演化,因此在产生高质量的PDE数值解时,捕获每个尺度上的动态内部和动态之间的相互作用至关重要。然而,在全局尺度上有效地做到这一点是具有挑战性的,尤其是在不过多牺牲计算效率或在局部尺度上性能的情况下。
多分辨率动态(第9.2.4节):许多系统具有快速演化动态的孤立区域,这些区域需要相对于其他区域更高分辨率的离散化来保持求解器的稳定性。因此,模拟不规则几何形状的能力平衡了在空间和时间上动态分配资源的准确性与计算工作量之间的权衡。
长期稳定性(第9.2.5节):在多个时间步中演化系统可能导致误差的累积,从而使预测的结果与实际情况发散。由于这种误差积累通常不会在测试时自然发生,因此很难使模型在推断时保持稳定。
保持对称性(第9.2.6节):许多PDE具有固有的对称性,通常用于找到降低阶模型并提高解的效率。对于机器学习来说,对称性可以用作归纳偏好,以减小学习任务的难度并缩小模型搜索空间的大小。此外,诺特定理[Halder et al. 2018;Noether 1971]建立了对称性和守恒定律之间的联系,这意味着遵守对称性的模型可以产生具有物理一致性的预测。
融合物理学(第9.2.7节):由于机器学习模型从根本上是统计模型,因此在仅根据数据进行训练而没有明确约束的情况下,它们容易产生不符合科学原理的预测。因此,利用已知的物理原理来引导深度学习模型非常关键,以便学习正确的底层动态,而不仅仅是拟合观测数据,这些数据可能包含虚假的非物理趋势。这可以通过对损失函数和体系结构的设计加以约束,或者通过适当地将传统的基于物理的模型与神经网络进行增强来实现。
在接下来的章节中,我们将更详细地讨论上述挑战,并讨论之前的工作如何应对这些挑战,这些工作在图32中有概述。

图33. 多尺度动态。许多系统表现出由各种尺度的相互作用组件组成的动态过程,尺度从局部到全局。一个主要的例子是湍流流动,它具有一系列涡旋,这些涡旋衰减到最小尺度,称为科尔莫哥洛夫尺度[Pope 2000]。因此,构建具有多尺度处理机制的机器学习模型对于高保真度的模拟至关重要。这些机制汇总了每个尺度上的信息,以更新每个网格点的潜在表示。在这里,我们可视化了一个按顺序执行每个尺度的聚合和更新机制,如Stachenfeld等人[2021]和Gupta and Brandstetter [2022]所考虑的,然而,Li等人[2021b]和Lam等人[2022]提出的机制是并行执行的。
9.2.3 现有方法:多尺度动态。
在许多物理系统中,动态过程在多个尺度上演变和相互作用。例如,湍流流动展示了不同尺度的局部湍流运动区域的层次结构,称为涡旋,其中能量从一个尺度传播到下一个较小的尺度的涡旋[Pope 2000]。虽然粒子的行为通常与附近的粒子最为密切相关,但仅考虑局部信息的层次化结构,如ResNets [He et al. 2016],依赖于许多层来传播远程信号,因此在演化动态方面表现出较差的性能[Li et al. 2021b; Gupta and Brandstetter 2022; Ruhe et al. 2023]。因此,通过机器学习进行忠实和高效的模拟的主要因素是整合多尺度处理机制[Li et al. 2020b; Gupta and Brandstetter 2022; Rahman et al. 2022b; Wen et al. 2023],以平衡复杂性的权衡,同时保持足够的局部信息流。
Stachenfeld等人[2021]在他们的Dil-ResNet中实现了这一机制,使用具有顺序递增的扩张率的卷积层块来处理从局部到全局尺度的信息,然后使用顺序递减的扩张率来处理从全局到局部的信息。根据相似的理念,Gupta和Brandstetter[2022]研究了U-Net架构[Ronneberger et al. 2015]的几种变体,该架构使用下采样和上采样来代替扩张以在局部和全局尺度之间进行遍历。在这两种情况下,该机制通过增加固定核大小的感受野来依次处理局部和全局信息,如我们在图33中可视化的那样。
与顺序处理机制不同,Li等人[2021b]提出的Fourier神经操作器(FNO)以并行方式处理多尺度信息[Gupta and Brandstetter 2022]。神经操作器是函数空间之间的映射[Kovachki et al. 2021],是处理涉及PDE的科学计算和物理现象的事实上的模型。与前面讨论的表示在物理域中参数化的Dil-ResNet和U-Net不同,神经操作器的子集被设计为在理论上是离散不变的[Kovachki et al. 2021]。此外,理论上,运算符的通用逼近定理保证了神经运算符以任意精度在Banach空间之间逼近任何连续运算符的能力[Kovachki et al. 2021]。在神经操作器架构中,FNO使用Fourier基进行内部积分,适用于具有复杂域的任意函数空间[Li et al. 2022b]。当处理规则的网格和域时,Fourier基积分通常使用快速傅立叶变换(FFT)进行,使FNO成为计算效率最高的神经运算符模型之一。FNO已成功应用于许多大规模应用,包括天气预测[Pathak et al. 2022]和气候减缓行动[Wen et al. 2023]。在傅立叶空间中,低频模式代表全局尺度上的信息,高频模式包含局部信息,因此,多尺度处理在频率域中通过傅立叶卷积固有的逐点乘法并行进行。为了管理复杂性,超过固定截止值的频率模式被设置为零,从而减少了操作和参数的数量。
Guibas等人[2022]将FNO扩展到视觉变换器框架,后来由Pathak等人[2022]应用于全球天气预测任务。为了有效利用注意力作为多尺度处理机制,Guibas等人[2022]使用傅立叶变换作为廉价的令牌混合器。Bi等人[2022]还在天气预测中建立了视觉变换器,但是他们使用了3D Earth Specific Transformer (3DEST)中的补丁嵌入来管理由注意力引起的二次复杂性。Lam等人[2022]在相同的设置中提出了GraphCast,这是一个在表示全球天气状态的图上运行的GNN,边集包含七种不同长度的边,用于有效地传递长距离消息,从跨越长距离的少数边到数十万个本地化的短边。由于天气现象从局部暴风雪到跨越多个大陆的热浪[Gupta and Brandstetter 2022],并且训练数据跨足了近半个世纪[Hersbach et al. 2020],因此,高效的多尺度处理对于这些工作所考虑的任务尤为重要。在很大程度上由于有效选择了这一处理机制,这些模型在各种任务上都优于目前用于提供现实世界预测的数值天气预测模型,而成本仅为一小部分[Bi etal. 2022; Lam et al. 2022; Pathak et al. 2022]。
9.2.4 现有方法:多分辨率动态。
对于平衡计算成本和解决方案准确性之间的权衡,能够对PDE域进行非均匀离散化的能力非常重要。经典的数值求解器依赖于这样一个假设,即解在关联点之间足够平滑以保持稳定性[Kochkov et al. 2021b]。然而,现象,如激波和妨碍流动的固体物体,如我们在图34中所示,引入了陡峭梯度的局部区域,需要昂贵的高分辨率离散化来保持这种平滑性[Berger和Oliger 1984]。均匀的离散化在这些孤立区域需要高分辨率的情况下,甚至在动态较慢演变的区域分配相同的高分辨率,会产生浪费[Wu et al. 2022a]。为了解决这个局限性,非均匀网格在高梯度区域分配了精细的分辨率,并在其他地方分配了粗糙的分辨率。此外,网格的几何形状可以随着高梯度区域在空间中的移动而调整,这在时变PDEs中通常是常见的[Berger和Oliger 1984]。
虽然已经证明机器学习方法允许比数值方法更粗糙的离散化,因为它们能够学习直接映射[Kochkov et al. 2021b; Stachenfeld et al. 2021],但神经网络仍然受益于解空间中一定程度的连续性。除了在高梯度孤立区域动力学方面的低效率之外,建立在CNN架构上的替代模型,如Stachenfeld等人[2021]和Gupta和Brandstetter[2022]所探索的模型,不能直接模拟非矩形域,例如围绕圆柱的流体流动。这些限制导致出现了多种在非均匀网格上建模动态和学习网格适应的方法。
与经典CNN类似,FNO [Li et al. 2021b] 使用离散傅立叶变换(DFT)将模型限制为带有定期间隔网格点的矩形域。因此,Li等人[2022b]提出了Geo-FNO,该框架后来由Tran等人[2021]扩展为F-FNO。

图34. 多分辨率动态,数据来自Pfaff等人[2021]。具有快速演化局部区域的系统,例如圆柱周围的流体流动(左侧)或翼型周围的气流(右侧),需要在这些区域进行高分辨率的离散化,以便能够稳定地解决动态。通过在梯度高的区域分配高分辨率和在其他地方分配粗分辨率,不规则的域离散化可以管理这种成本。然而,由于不规则离散化的函数不能由CNN等架构建模,因此已经呼吁使用GNN来模拟动态[Pfaff等人,2021]。此外,这些高梯度区域在空间中的位置可以随着系统的演变而变化,因此需要动态调整离散化。虽然传统的重新网格化算法可能很昂贵,但Pfaff等人[2021]和Wu等人[2022a]提出了用于自适应网格细化的学习替代方法,从而降低了这种成本。
这些架构首先将输入网格变形为潜在空间中的矩形均匀网格,以进行快速傅立叶变换(FFT)的傅立叶卷积,然后应用反向变形以在不规则网格上生成输出。然而,这种基于变形的方法包括离散不变性属性[Kovachki等,2021]。此外,保持域的几何形状是在卷积架构中实现有效泛化和学习的主要因素[Cohen等,2018]。
GNN提供了一种在不规则网格上学习函数的保持几何性质的机制[Kipf和Welling,2017; Gilmer等,2017],将输入网格视为PDE解在每个节点上进行预测的图形。图神经算子(GNO)[Li等,2020a]是GNN的神经算子概括,在这种情况下提供了理论上的离散不变方法。Pfaff等人[2021]采用了类似的方法,使用其MeshGraphNets框架,其中还包括第二个GNN,用于预测每个节点的尺寸张量。然后,自适应网格细化算法使用预测的尺寸张量来更新网格几何形状随着动态的演变。请注意,将网格几何形状更新以在梯度更高的区域分配更多资源与Li等人[2022b]的方法不同,后者会将域的表示变形为潜在空间中的网格点形成矩形均匀网格。然而,这种重新网格化算法很昂贵,而且可能不会以在解的精确性和网格成本之间的权衡方面产生最佳几何形状[Wu等,2022a]。因此,Wu等人[2022a]提出了学习可控多分辨率物理模拟(LAMP),这是一种更快速、数据驱动的重新网格化方法,使用强化学习。他们联合优化动态GNN和网格细化策略,其中策略是通过同时最小化动态GNN的误差和网格中的节点数量来选择的。
9.2.5 存在的方法:长期稳定性。
时变PDE通过将时间域离散化为时间步长来进行数值求解,在这个时间步长上,求解器会产生解。可以通过显式方案获得此解,其中给定时间点的解是使用前面的解直接计算的,即 𝑢𝑡+1=𝐹(𝑢𝑡) 对于某个函数 𝐹,或者隐式方案,其中涉及到 𝑢𝑡 和 𝑢𝑡+1 的一系列(可能是非线性的)方程的求解[Olver 2014]。尽管显式方案似乎需要的计算工作比隐式方案少,但使用显式方案推进时间的传统求解器可能表现出有条件的稳定性,这意味着必须选择足够细的时间离散化,以防止求解器发散[Courant等人,1928; Olver 2014]。对于显式方法需要比实际解的平滑性更细的时间离散化的这种PDE被称为刚性。因此,传统上更喜欢使用隐式方法来解决刚性PDE。尽管如此,许多神经代理使用显式方案出于方便考虑,已经证明在计算成本较低的粗略离散化上优于传统求解器[Kochkov等,2021b; Stachenfeld等,2021]。然而,显式方案不可避免地会引入到模型输入的错误,因此增强神经求解器对嘈杂输入的鲁棒性对于实现在许多时间步上的稳定预测至关重要。
在这种情况下通常考虑的任务是在𝑇的时间步上进行预测,条件是first𝑘 solutions,也就是说,从时间0的解到剩余的𝑇−1步的映射(𝑢0,𝑢1,...,𝑢𝑘−1)↦→(𝑢𝑘,𝑢𝑘+1,...,𝑢𝑇)。在接下来的内容中,为了简化符号,我们取
𝑘=1,以便学习的映射是从时间0的解到其余的𝑇−1步,但这在一般情况下并不是必要的。对于这样的任务,显式方案会训练𝜙𝜃以在𝑢𝑡的基础上条件地预测𝑢𝑡+1的一步预测,并在测试时通过自回归预测𝑇次来预测完整的演化[Brandstetter等,2022c; Sanchez-Gonzalez等,2020; Stachenfeld等,2021]。这种一步训练策略已经被证明比以前训练的循环策略更有效,以预测完整的演化𝑢1,𝑢2,...,𝑢𝑇 [Tranetal.2021]。然而,它在测试时并不代表任务,因为对于𝑡>1,模型的输入将不再是像在训练中的地面真实𝑢𝑡,而是𝑢𝑡+𝜀𝑡,其中𝜀𝑡是通过自回归预测𝑢𝑡累积的时间𝑡的错误。
一些研究已经采用了各种技术来解决这个问题,包括Sobolev损失和物理性质,如耗散性[Li等人,2021c],Lyapunov正则化器[Zheng等人,2022]和对抗性噪声注入[Sanchez-Gonzalez等人,2020; Brandstetter等人,2022c]。噪声注入方法在训练期间有意地破坏了近似于 𝜀𝑡 的输入。Sanchez-Gonzalez等人[2020]在训练他们的基于图网络的模拟器(GNS)时应用了这种策略,假设 𝜀𝑡 遵循均值为0的高斯分布,方差由超参数选择。虽然这种方法很方便,因为噪声分布可以轻松抽样,但正态性假设可能无效,而且方差超参数必须谨慎调整。Brandstetter等人[2022c]则直接从模型中获取噪声以训练他们的消息传递PDE求解器(MP-PDE),以减小训练噪声和测试噪声之间的分布偏移。他们通过让 𝜀𝑡 = 𝜙𝜃 (𝑢𝑡 −1) − 𝑢𝑡 来实现这一点,从而使模型的输入为 𝑢𝑡 + 𝜀𝑡 = 𝜙𝜃 (𝑢𝑡 −1)。因此,在训练期间添加到输入的噪声直接来自模型,就像在测试期间一样。
尽管这种方法消除了仅有2个时间步骤的演化的分布偏移,但在更长的演化中,分布偏移又会出现。Wu等人[2022c]通过使用多步目标来优化他们的混合图网络模拟器(HGNS),在递归地预测多个步骤之前进行加权和总损失,其中一步损失的权重最大,因此优化首先针对短期预测,然后再进行长期预测的微调。与完全的递归预测相比,这种方法更稳定,因为它只预测几个步骤,而不是完整的演化。
虽然先前讨论的架构仅预测1个时间步骤,但Brandstetter等人[2022c]提出了这样的观察,即由于每次前向传播都会引入一些误差,减少调用模型所需的次数可以减小累积误差。他们的模型不仅预测1个时间步长,如𝜙𝜃(𝑢𝑡)=𝑢ˆ𝑡+1,还训练模型以预测𝑙个时间步长,通过一个前向传播,如𝜙𝜃(𝑢𝑡)=(𝑢ˆ𝑡+1,𝑢ˆ𝑡+2,...,𝑢ˆ𝑡+𝑙)。例如,要使用𝑙=2预测10个时间步长,只需要5次前向传播,而不是10次。
9.2.6 存在的方法:保持对称性。
动态系统受物理定律的控制,系统的对称性与这些定律通过诺特定理[Noether 1971; Wang等人,2021a]相关联。PDE的对称性群表征了在这些变换下解保持解的变换,例如,对于具有旋转对称性的PDE,旋转解函数会产生一个同样是解的函数。其他对称性,如平移不变性,出现在具有无限域或周期边界的PDE中[Holmes等人,2012]。强制执行对称性的先验条件可以通过减小解空间的大小来提高泛化性能和样本复杂性[Raissi等人,2019; Wang等人,2021a; Brandstetter等人,2022b]。
作为灌输学习等变性的一种方法,Brandstetter等人[2022b]建议使用根据PDE的对称性进行数据增强。然而,尽管数据增强可以用于实现近似等变体系结构,但一般情况下内部表示不会是等变的[Worrall等人,2017],这是等变体系结构有效学习的主要因素之一。此外,许多系统都具有数据增强无法捕获的局部对称性[Worrall等人,2017]。
等变CNN由卷积层组成,可以自动编码所需的对称性[Cohen和Welling 2016、2017b;Weiler等人,2018a;Weiler和Cesa 2019a;Worrall和Welling 2019],解决了这两个缺点。Wang等人[2021a]在构建他们的Equ-ResNet和Equ-Unet以进行动态预测时考虑了各种对称性,包括精确的尺度和旋转对称性。然而,由于外部力量等原因,动态通常只具有近似对称性[Wang等人,2022i]。因此,Wang等人[2022i]在构建其RGroup和RSteer CNN时在构建近似等变群和可转动卷积时放宽了等变性约束[Cohen和Welling 2016,2017b]。
Ruhe等人[2023]没有采用可转动或群卷积,而是采用了不同的方法来编码对称性。他们建立在Clifford神经层[Brandstetter等人,2023]的基础上,提出了几何Clifford代数网络(GCANs),在实现等变性时利用了所有等距变换(平移、旋转和反射)都可以分解为一系列反射的事实。除了在第9.2.3节中讨论的多尺度处理方面带来的好处外,这还允许与物理参数化替代方案相比更好地泛化到具有不同分辨率的离散化[Li等人,2021b]。
与先前讨论的CNN在物理空间中执行等变卷积不同,Helwig等人[2023]将群等变卷积[Cohen和Welling 2016]扩展到了频率域参数化,使用了𝐺 -FNO架构。除了多尺度处理方面的好处,正如第9.2.3节中讨论的,这还允许相对于物理参数化的替代方案更好地泛化到不同分辨率的离散化[Li等人,2021b]。
9.2.7 存在的方法:融合物理学。
尽管深度神经网络是通用函数逼近器,但实际操作中,人们经常对物理系统的行为有深刻的见解。通过精心设计架构,以自动遵守这些系统遵循的物理定律,可以简化学习任务,并提高网络在类似系统上的泛化能力。这是因为这些规则通常很难直接从数据中学习,特别是在小数据情况下。此外,编码物理定律通常会增加网络输出的可解释性,因为它们可以直接与从业人员熟悉的概念相关联,这与通常将神经网络视为黑匣子建模工具的做法形成鲜明对比。
哈密顿神经网络(HNNs)[Greydanus等人,2019]以哈密顿力学的形式融入了物理知识,以忠实地建模哈密顿系统。一般来说,这些系统由位置 𝑞(𝑡) 和规范动量 𝑝(𝑡) 描述,它们按照哈密顿方程随时间演化,如下所示:
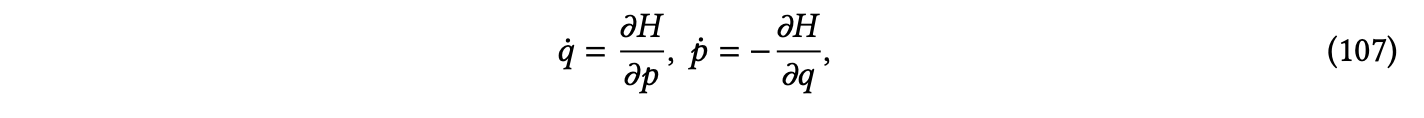
其中,𝑞¤ 和𝑝¤ 分别是𝑞和𝑝关于时间的导数。哈密顿系统无处不在 - 行星在重力作用下的运动,受电磁力影响的粒子以及附有弹簧的块都遵循哈密顿力学。哈密顿系统的一个关键属性是随着系统随时间演化,哈密顿量 𝐻(𝑞(𝑡),𝑝(𝑡)) 是守恒的,即它保持不变。简而言之,哈密顿量 𝐻 捕捉了系统中的能量量。HNNs [Greydanus等人,2019] 提出直接从动力学数据中学习这个哈密顿量 𝐻。然后,通过使用4阶的显式龙格-库塔方法,通过随时间数值积分方程(107)来计算哈密顿系统的时间演化。HNN 模型可以准确地学习简单哈密顿系统的时间演化,例如不会耗散能量的振荡摆动,从而进行能够与哈密顿方程保持一致性的预测。相比之下,使用相同数据训练的标准全连接神经网络无法学习守恒 𝐻 的轨迹,导致物理上不合理的预测。
理论上,哈密顿系统的当前状态𝑢(𝑡) = (𝑞(𝑡),𝑝(𝑡))完全决定了其将来的任何时间𝑡′ >𝑡的状态𝑢(𝑡′)。基于这个动机,SympNets[Jin等人,2020]直接学习从当前系统状态 𝑢 (𝑡 ) 到未来系统状态 𝑢 (𝑡 ′ ) 的映射,使用辛正则流来避免随时间积分。这使得 SympNets 在更长时间内的推演中更加高效,因为它们避免了在数值积分过程中存在的数值误差的累积。辛循环神经网络[Chen等人,2020b]进一步改进了哈密顿神经网络,通过使用辛积分器(如跃进法)来更好地适应哈密顿系统,因为它们明确匹配了方程(107)的形式。因此,在时间上积分到数值精度时,辛积分器将保持学习到的哈密顿量 𝐻 不变。此外,Chen等人[2020b]提出通过采样模型以递归方式而不是单步预测所产生的更长推演来进行训练。这有助于避免在每个时间步中从模型的预测中递归采样时固有的分布偏移问题,如第9.2.5节所讨论的。最后,为了考虑系统可观测值中的噪声,Chen等人[2020b]通过梯度下降来更新初始状态 𝑢0 = (𝑞0, 𝑝0)。这些修改提高了 HNN 在建模嘈杂的真实系统时的准确性。
与哈密顿系统相反,拉格朗日神经网络(LNN)[Cranmer等人,2020]模拟拉格朗日系统,其中规范动量 𝑝 的形式不一定已知。相反,拉格朗日力学提供了必要的见解,以将位置 𝑞 的时间演化联系起来。

其中,𝑞¤ 和𝑞¥ 分别是位置 𝑞 关于时间的一阶和二阶导数,𝐿(𝑞,𝑞¤) 是系统的拉格朗日量。类似于使用哈密顿量 𝐻 的 HNNs,LNNs 通过神经网络对拉格朗日量 𝐿 进行建模。然后,通过数值积分方程 (108),可以获得𝑞(𝑡) 的时间演化。
最后,Sosanya 和 Greydanus [2022] 对 HNN 进行了扩展,额外预测了一个雷利耗散函数 𝐷 和哈密顿量 𝐻 。这使得网络能够捕捉外部力,如摩擦力,它们会耗散能量。在原始 HNN 框架中无法捕捉这些力,因为 HNN 学习的是能量守恒的动力学。耗散性 HNN 在预测阻尼弹簧-块系统的时间演化和海洋表面流速场方面表现出了更好的性能。
尽管哈密顿力学可以描述许多物理系统,但在许多现实世界的情景中,系统可能没有足够好的理解,或者只能部分观察到。如果描述系统的基础 PDE 仅部分已知,则可以在混合设置中利用物理知识。在这种情况下,可以将深度神经网络与基于 PDE 的方法结合使用,以学习假设的控制方程与观测数据之间的残差。一个代表性的例子是由 Yin 等人[2021]提出的 APHYNITY 框架,该框架的基本理念是动力学可以分解为物理(已知)和增强(残差)两个部分,如下所示:
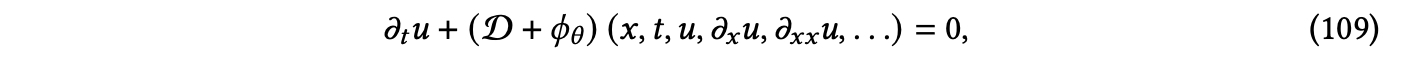
其中,𝜙𝜃 代表补充已知运算符 D 的数据驱动组件。在学习 𝜙𝜃 的参数时,使用数值积分来生成基于 D + 𝜙𝜃 的初始状态的各个步骤的预测。更重要的是,它以高效的方式将深度数据驱动网络与物理模型相结合,使数据驱动模型仅对物理模型无法捕获的部分进行建模。为了实现这一点,除了预测损失之外,还对 𝜙𝜃 引入了额外的 L2 范数项 ∥𝜙𝜃 ∥2。这避免了神经网络可以捕获所有或大多数动态并且物理模型对学习贡献甚少的情况。
类似地,DeepGLEAM [Wu et al. 2021] 是一种用于预测 COVID-19 死亡率的方法,它直接将机械流行病模拟模型 GLEAM 与神经网络相结合。GLEAM [Balcan et al. 2009] 是一个基于 PDE 的模型,根据元人口年龄结构的分区模型来描述复杂的流行病动态。DeepGLEAM 使用 DCRNN [Li et al. 2017b] 来学习 GLEAM 的误差,从而提高了预测未来一周 COVID-19 死亡人数的性能。
除了应用于观测到的动态数据之外,混合方法还可用于替代经典求解器中计算密集型的组件,或者学习对应用于低成本但会引入误差的粗散布的经典求解器的纠正。Belbute-Peres 等人[2020]提出了一种称为 CFD-GCN 的新方法,它将图卷积神经网络与计算流体动力学(CFD)模拟器相结合。这种混合方法旨在生成高分辨率流体流动的准确预测。它在粗三角网格上运行快速的 CFD 模拟器,生成较低保真度的模拟,然后使用最近邻插值技术将其上采样到更细的网格,最后,图卷积神经网络对细粒度模拟进行处理,进一步改进了对特定物理性质的预测。类似地,Kochkov 等人[2021b]利用 CNN 对由经典数值求解器产生的粗速度分量进行了学习插值和学习校正,从而大大加速了模拟高分辨率流体速度场的过程。此外,Tompson 等人[2017]用卷积网络替换了求解泊松方程的数值求解器,这是传统欧拉流体模拟程序中最耗时的步骤,这种方法实现了显著的加速,并展现了强大的泛化能力,同时保持了物理上的一致性预测。
与以前讨论的方法将数值 PDE 解的逼近不同,物理信息神经网络(PINNs)的目标是通过将神经网络 𝜙𝜃 参数化为 PDE 解来逼近分析解[Raissi 等人 2019]。使用反向传播,可以精确评估方程(104)中的空间和时间导数,并将其用作正则化代理,以确保方程(104)规定的约束被近似满足。因此,对于定义为的操作员 T:
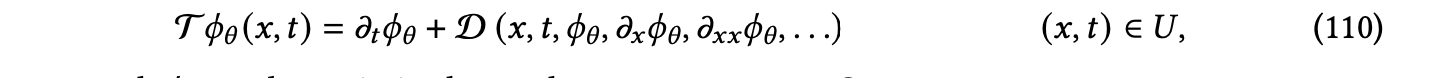
网络 𝜙𝜃 可以在参数空间 Θ 上进行优化,如下所示:
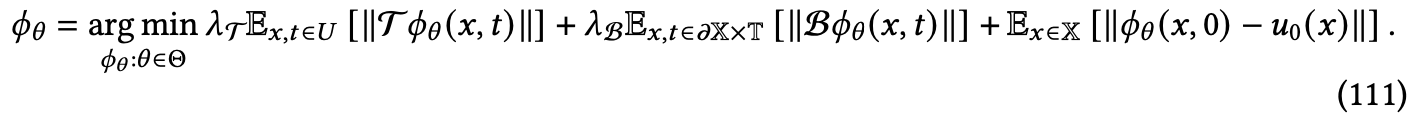
𝜆T 和 𝜆𝐵 是用于平衡不同损失项的系数,需要仔细调整。PINNs 在血液流动的生物医学分析中找到了实际应用,使用了 Hidden Fluid Mechanics 框架 [Raissi et al. 2020],并与神经操作员架构如 Physics-Informed DeepONet [Wang et al. 2021b] 和 Physics-Informed Neural Operator [Li et al. 2021g] 结合,以提高样本复杂性,甚至允许完全自监督训练。Yang 等人 [2021b] 进一步提出了 B-PINNs,将 PINNs 的概念扩展到贝叶斯框架中。在这种方法下,将 PINN 用作解决偏微分方程 (PDEs) 的先验,同时使用汉密尔顿蒙特卡洛方法从生成的后验分布中抽取样本。与 PINNs 相比,B-PINNs 不仅提供不确定性量化,而且由于其避免过度拟合的能力,还能更准确地预测噪声数据。
9.2.8 数据集和基准。
神经 PDE 求解器的兴起引发了许多用于前向 PDE 建模的数据集,其中我们在这里突出显示一些,并在表 32 中总结。Takamoto 等人 [2022a] 提出了 PDEBench,其中包含具有不同空间维度的 8 种不同 PDE 的数值解数据。除了前向问题,Takamoto 等人 [2022a] 还考虑了逆问题,我们将在第 9.3 节中讨论这个任务。也许最具挑战性的 PDEBench 数据集是可压缩 Navier Stokes 方程,用于建模可压缩流体的密度、压力和速度场,Takamoto 等人 [2022a] 将其包含在一维、二维和三维空间中。速度接近或超过声速的流体必须被视为可压缩流体,即具有非恒定的密度 [Anderson 2017]。因此,Takamoto 等人 [2022a] 发布了具有初始马赫数的数据,用于量化流体速度与流体声速之比 [Anderson 2017],马赫数可以高达 1。此外,Takamoto 等人 [2022a] 考虑到低粘度会产生高度湍流的动力学,必须在小尺度上进行稳定模拟 [Kochkov et al. 2021b]。
Gupta 和 Brandstetter [2022] 考虑了使用由 Klöwer 等人 [2022] 开发的全球大气模型生成的浅水方程的特别困难的实现。这个 PDE 是通过深度积分 Navier-Stokes 方程导出的,尽管名字中带有“水”,但可以像 Navier-Stokes 方程一样模拟水以外的流体 [Vreugdenhil 1994]。Gupta 和 Brandstetter [2022] 的数据集包括了 5,000 多条轨迹,模拟了全球的压力、风速和风涡度场。Gupta 和 Brandstetter [2022] 考虑了将系统每隔 48 小时推进一次的任务,这是一种特别具有挑战性的粗映射任务,对学习来说尤为具有挑战性。Gupta 和 Brandstetter [2022] 还发布了使用 ΦFlow 求解器 [Holl et al. 2020] 生成的不可压缩 Navier-Stokes 方程的数据,并考虑了一个有趣的条件任务,在这个任务中,学习的求解器根据不同的时间步长和强迫项条件对未来时间步长进行预测。在类似的情况下,Tran 等人 [2021] 也提供了用于建模流体涡度场的数据,使用不可压缩 Navier-Stokes 方程进行建模,同时对粘度系数和强迫项进行泛化。
表32. 用于前向建模的选择性PDE数据集。我们突出显示了从神经PDE求解器基准[Takamoto等人2022a;Gupta和Brandstetter 2022]以及引入方法[Tran等人2021;Pfaff等人2021]中产生的具有挑战性的数据集。这些数据集在1、2和3个空间维度上模拟了各种领域,并包括了快速运动和湍流动力学、大时间步长预测、条件预测和不规则几何形状等具有挑战性的任务。
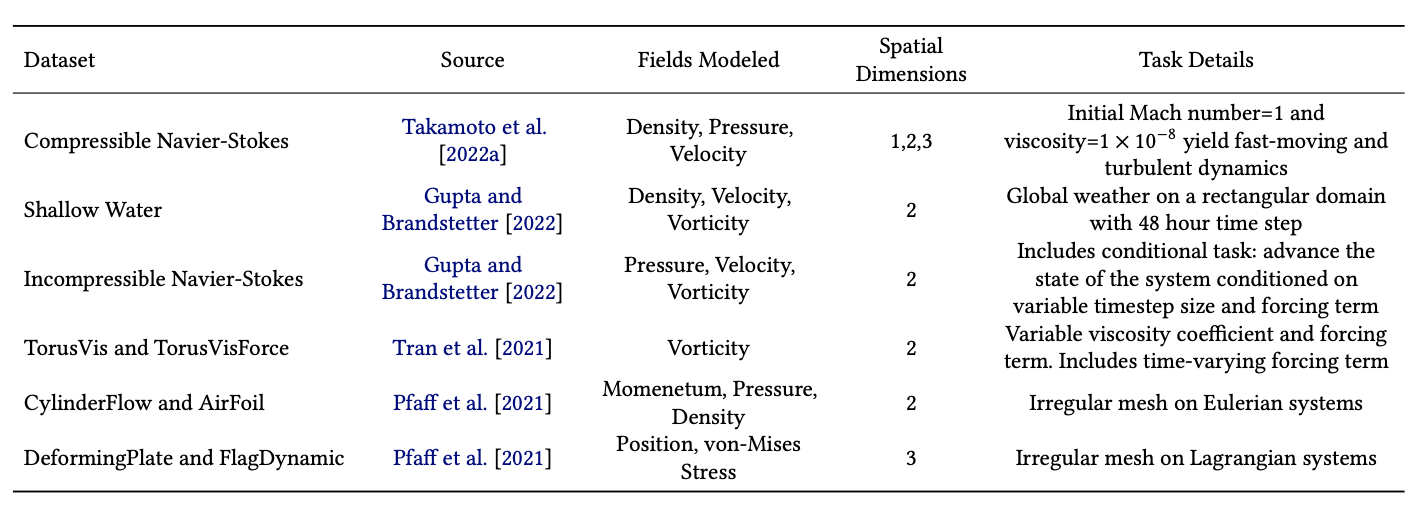
最后,针对在不规则几何形状上建模的偏微分方程(PDEs),Pfaff等人[2021]发布了多个数据集,涵盖了拉格朗日和欧拉系统。欧拉系统的数据包括围绕圆柱体的流体流动和围绕翼型的空气流动,如图34所示,与拉格朗日系统不同之处在于网格是固定的。相比之下,拉格朗日数据集中,网格会随系统的变形而变化,其中包括了飘动的旗帜和可变形的金属板。
需要注意的是,虽然这些工作精选了一系列具有挑战性的PDEs,这些PDEs对于数值求解器的研究至关重要,但在这些任务上表现良好的求解器可能不会立即很好地推广到PDE建模的实际应用中。在工业环境中遇到的动态问题可能涉及与复杂外部力的相互作用,并且出现在大型不规则形状的领域中。在这种情况下,多尺度处理(第9.2.3节)、多分辨率建模(第9.2.4节)和滚动稳定性(第9.2.5节)等先前讨论的挑战在难度和重要性上都会增加。未来的基准测试应该设计任务,以更真实的场景中明确探讨这些领域。此外,我们还注意到,尽管所有这些数据集都侧重于时变的PDEs,但建模稳态问题是一个相关但尚未充分探索的领域,Bonnet等人[2022]提出了稳态Navier-Stokes方程的初始数据。
9.2.9 开放性研究方向。
在结束前向建模部分的讨论时,我们将讨论当前工作尚未解决的神经求解器面临的挑战。
学习求解器的一个主要限制是需要由昂贵的数值求解器生成足够数量的训练数据[Raissi等人,2019; Brandstetter等人,2022b],这在工业规模上尤为棘手。因此,改进学习求解器的泛化能力和复杂性抽样对于证明和降低其适应实际环境的成本是必要的。为实现这一目标,学习求解器文献中应该发展一个更丰富的子领域,专注于处理分布外(OOD)动态的技术。与许多当前的工作不同,这些工作将求解器训练成能够准确推断超出训练集观察到的动态。在这种OOD设置中表现出色的模型将允许训练集中的PDE解的跨度成为测试集中跨度的子空间,从而提高了抽样复杂性。OOD设置已经在文献中进行了研究,例如Kochkov等人[2021b]研究了他们的混合经典 - 神经求解器在OOD领域大小、外部作用力和PDE参数下的性能。Stachenfeld等人[2021]类似地研究了OOD领域大小,以及OOD的初始条件和滚动长度。然而,在OOD动态领域的文献中存在一些空白,尚未形成在OOD动态领域开发原则性方法的工作。在这一领域的初步工作将微分方程的参数视为元学习中的环境,并训练一个可以在测试时进行跨领域微调以适应未见的OOD环境的模型[Wang等人,2022j; Mouli等人,2023; Kirchmeyer等人,2022]。
第二个限制应用的因素是,尽管在工业应用中三维问题非常普遍,但大部分文献都集中在只有一到两个空间维度的问题上。虽然本节讨论的许多架构可以立即扩展到三个空间维度,但在实践中,三维建模面临着必须谨慎处理的有限内存等障碍[Wu等人,2022c; Lam等人,2022; Bi等人,2022]。除了内存要求外,三维模型的优化自然而然地比其二维对应物更具挑战性,因为搜索空间的大小增加了。此外,在三维中,可能会引入在低维度中不存在的具有挑战性的动态问题,比如湍流流动的典型情况,三维转换引入了一种在二维流动中由于能量级联而看不到的程度的混沌,有关此点可以参考第9.2.3节中讨论的能量级联[Lienen等人,2023]。因此,未来的工作应该致力于设计神经求解器,既可扩展到三个空间维度,又具有足够的归纳偏见,以有效地导航搜索空间,同时保持足够的表现力来忠实地建模更具挑战性的动态问题。
此外,由于神经网络难以建模非光滑函数,因此建模具有突变变化的系统,例如球撞墙的轨迹,仍然是一个挑战。这些问题代表了刚度的极端情况,因为这种剧烈交互的时间尺度比推进系统的通常时间步长小了几个数量级。Chen等人[2020b]提出了一种方法,通过在其积分器的更新方程中增加一个反弹模块来处理这种类型的一次性交互。Kim等人[2021]提出了计算神经ODE梯度和适当归一化的高效方法,以建模刚度系统。然而,仍然需要找到更一般的解决方案来建模刚度系统。
最后,我们发现来自第9.2.3至9.2.6节讨论的挑战交叉领域中的一些设置是相关但研究不足的问题。在多尺度发展(第9.2.3节)和具有高梯度局部区域(第9.2.4节)的动态系统需要能够在不规则离散化的函数上进行操作,并具有多尺度处理机制的模型。Janny等人[2023]已经在这个设置中迈出了初步步伐,他们的网格变压器使用图注意力作为多尺度处理机制,并在计算注意力分数之前将相邻节点汇集在同一邻域中以管理复杂性。此外,多尺度处理机制(第9.2.3节)已经被引入到等变神经求解器(第9.2.6节)中,Wang等人[2021a]提出了他们的等变U-net,Helwig等人[2023]提出了他们的频域中的群卷积。未来的工作可以探索将等变注意力[Fuchs等人,2020; Liao和Smidt 2023]作为神经求解器中的多尺度处理机制。最后,可以在不规则结构输入上运行的等变神经求解器(第9.2.4节)是一个有趣的方向,Horie等人[2021]已经在这个领域开展了初步工作,他们的IsoGCN。
9.3 逆问题和逆设计
作者:Tailin Wu、Xuan Zhang、Cong Fu、Rui Wang、Jacob Helwig、Rose Yu、Shuiwang Ji、Jure Leskovec
在第9.2节中,我们深入探讨了用于模拟PDE的前向演化的神经PDE求解器的进展和挑战。反向方向同样令人兴奋,包括(1)逆问题,其中任务是在观察到(部分)动态的情况下推断系统的未知参数或状态,以及(2)AI辅助的逆设计,其中任务是根据预定义的目标优化系统(参数或组件,如初始条件或边界条件)。这两个任务在科学和工程中都是普遍存在的。在图35中,我们概念化了前向问题、逆问题和逆设计。
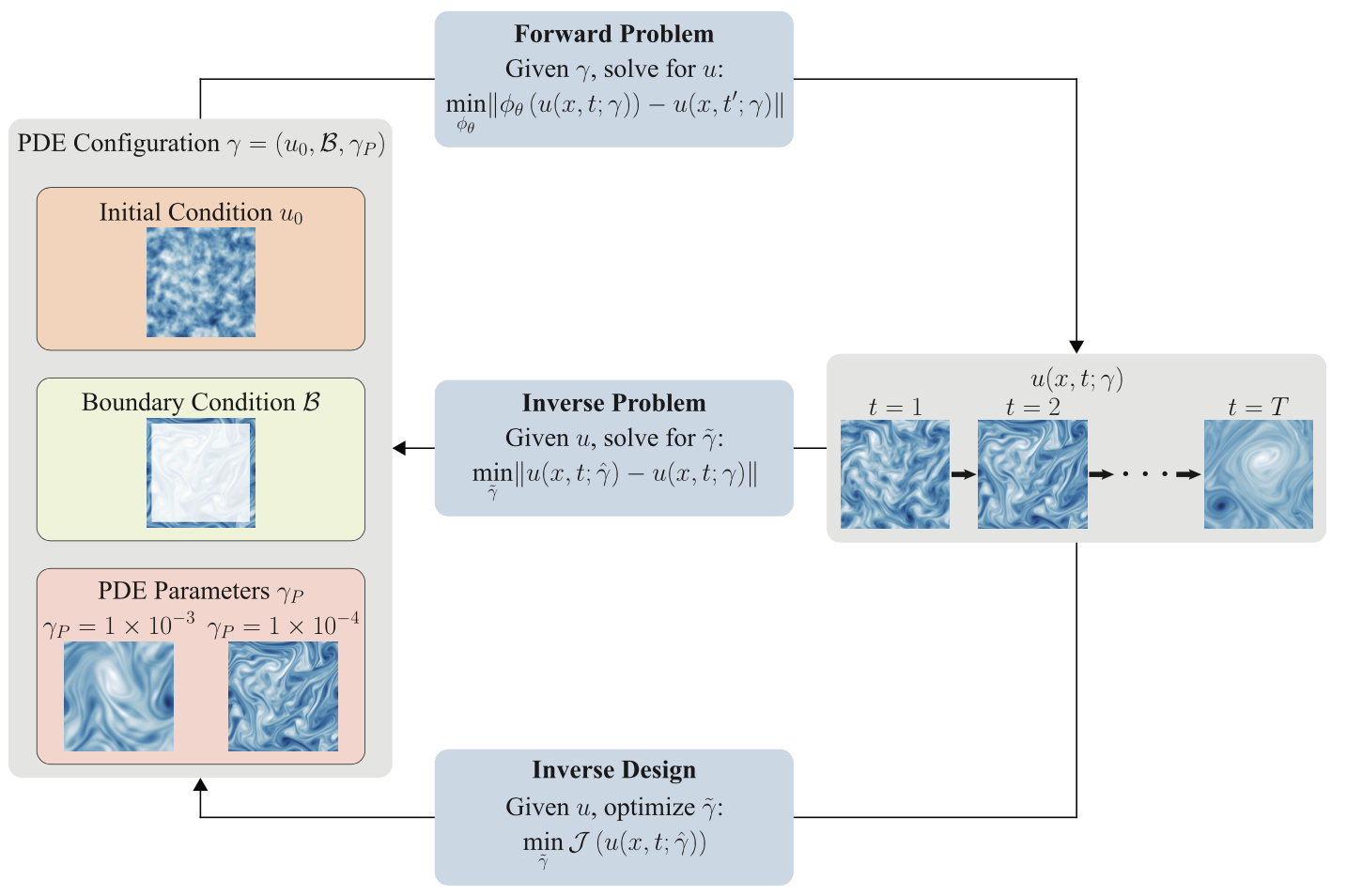
图35. 描绘了前向问题、逆问题和逆设计的示意和比较。PDE的解𝑢(𝑥,𝑡;𝛾),在离散化时空的网格点(𝑥,𝑡)上采样,由PDE配置𝛾 = (𝑢0,B,𝛾𝑃)诱导,描述了初始条件𝑢0、边界条件B和PDE参数𝛾𝑃。在前向问题中,任务是学习从先前时间步𝑡到后续时间步𝑡 ′ > 𝑡的解的映射,该解是由𝛾的特定选择在较早时间步𝑡上诱导的,使用预测模型𝜙𝜃。相反,在逆问题中,考虑的任务是识别PDE配置𝛾 ̃ ⊂ 𝛾的一个子集,例如生成观察到的滚动数据的初始条件𝑢0。假设数据来自前向模型𝑢(𝑥,𝑡;𝛾),并且通过最小化𝑢(𝑥,𝑡;𝛾ˆ)与观察数据𝑢(𝑥,𝑡;𝛾)之间的差异来优化估计的配置𝛾ˆ,其中𝛾ˆ表示配置𝛾 ̃的估计组件与已知组件的联合。最后,逆设计涉及识别𝛾 ̃ ⊂ 𝛾,以使生成的滚动𝑢(𝑥,𝑡;𝛾ˆ)优化某个准则J,例如识别最小化阻力的飞机机翼形状。
9.3.1 问题设置。
让𝑢(𝑥,𝑡;𝛾)表示描述物理过程的前向模型,由PDE配置𝛾 = (𝑢0, B,𝛾𝑃 )诱导,描述了初始条件𝑢0、边界条件B和PDE参数𝛾𝑃 。此外,让𝛾 ̃ ⊂ 𝛾表示要恢复(在逆问题中)或要优化的设计参数(在逆设计中)。最后,让J是评估恢复或设计质量的目标函数。逆问题和逆设计可以被表述为一个优化问题[Lu等人,2021b],如下所示:
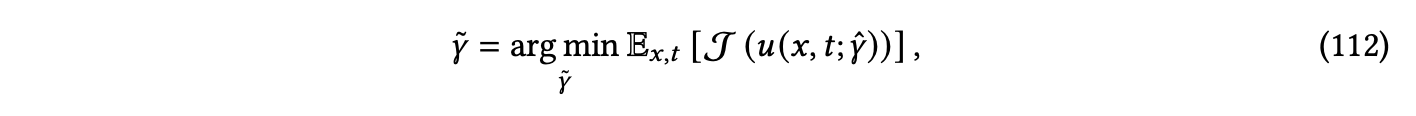
其中𝛾ˆ代表了待估计的PDE配置𝛾 ̃的组件与假定已知的其余组件的并集。例如,在建模动态系统时,𝑢通常定义了在给定某种初始条件和边界条件时滚动将是什么样子,而J则度量了由𝛾ˆ诱导的模拟滚动与观察到的或目标滚动之间的差异。在上述公式中,𝑢是固定的,可以使用传统的PDE求解器进行建模。为了加速和改进优化,𝑢也可以是一个学习模型,并且可以使其可微分。在这种情况下,可能需要对𝑢添加额外的约束以确保物理一致性,因此,𝛾 ̃和𝑢的联合优化受到了约束,如下所示:
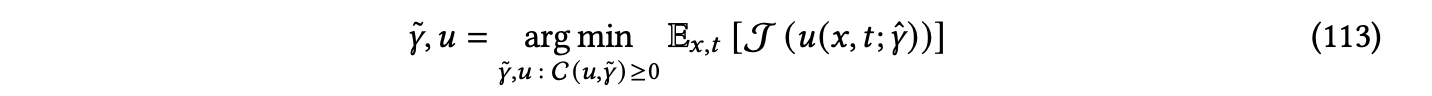
其中C可以是来自PDE或多目标优化的其他约束[Lu等人,2021b]。
逆问题与逆设计:尽管它们的名称暗示了相似性,但在PDE的背景下,逆问题和逆设计具有不同的含义。逆问题是指某些或全部PDE的初始条件、边界条件或系数未知的情况,其目标是从观察到的数据中确定或恢复这些未知值。逆问题通常假设观察到的数据在物理上是合理的,并代表了PDE的解。例如,在流体力学中,观察到的数据可能是涡度场,只有初始条件是未知的。然后,逆问题是确定会产生这样的涡度场的初始条件𝑢0。相反,逆设计更具体地指的是一种设计或优化方法,在该方法中给定了预定义的目标,目标是根据目标来优化系统配置。例如,假设给定了一个可以模拟前向流体动力学的代理模型𝑢,目标可能是设计一个表面,可以引导流体流向所需的位置。对于逆设计,不一定需要存在精确的解,但我们仍然希望优化提出的解决方案以尽可能满足目标。从某种意义上说,逆设计也可以被视为逆问题的一种特殊类型,其中的目标不仅仅是确定未知参数或系数,而是设计一个以特定方式行为的系统。
逆问题的应用:在这里,我们描述了几个逆问题的例子,这些问题为AI创造了新机会,我们在图32中概述了这些机会。
• 流体动力学基础:学习流体动力学的代理模型通常需要使用昂贵的传统求解器来获取训练数据。另一种方法是考虑逆问题,其中任务是仅基于三维动态流体场的多视角视频来推断底层动态[Guan等人,2022]。
• 系统识别:传统上,估计物体的物理属性需要进行许多物理实验并使用专门设计的算法。这里一个有前景的逆问题是直接从视觉观察中推断物理属性[Li等人,2023c]。
• 地球物理学的全波形反演:在地球物理学中,地下性质如密度或波速可以从地表上地震波的测量中推断出来,这个问题被称为全波形反演[Lin等人,2023c]。这些地下性质对于能源勘探或地震预警等应用非常重要,否则由于问题的大规模而难以测量。
• 流体同化和历史拟合:流体同化旨在从时空域中的稀疏观测中恢复整个流体场[Zhao等人,2022]。流体同化可以应用于地下流模型。地质模型会进行调整,以使其预测与历史观测相匹配,这个任务被称为历史拟合[Tang等人,2021]。
• 医学成像的层析成像:层析成像旨在仅使用表面测量来恢复物体的内部结构。例如,在医学成像中,电阻抗层析成像(EIT)[Guo等人,2023a]可以通过测量注入电流时皮肤上的电压分布来推断内部器官的状态,从而避免侵入性测量或辐射暴露。
逆设计的应用:在这里,我们识别了一些应用领域,AI辅助逆设计可以发挥重要作用,并存在广阔的机会。
• 飞机形状设计:在空气动力学中,一个重要的挑战是设计飞机的形状以减小阻力[Athanasopoulos等人,2009]。这涉及到模拟空气流体动力学以及其与飞机边界形状的相互作用。
• 离子推进器设计:在航空航天工程中,设计高效推进器非常重要。例如,霍尔效应推进器(HET)是最具吸引力的电推进(EP)技术之一,因为它具有高比冲和高推力密度。一个关键问题是如何设计推进器的形状和材料排列,考虑到其复杂的等离子体动力学[Hara 2019]。
• 控制核聚变:解决控制核聚变可以为无限清洁和廉价能源铺平道路。在磁约束与托卡马克中的受控核聚变的两种主要方法之一,一个关键挑战是优化外部磁场和壁设计,以将等离子体塑造成具有良好稳定性、约束和能量排放的配置[Ambrosino等人,2009; Degrave等人,2022]。
• 芯片制造:芯片制造中的许多过程涉及逆设计。其中一个重要的应用是等离子体沉积。具体问题是如何设计电介质单元的形状,以使等离子体沉积到基板上尽可能平滑[Hara等人,2023]。
• 水下机器人的形状设计:在水下机器人中,一个重要问题是设计机器人的形状以实现多个目标,包括减小阻力、提高能源效率、改善操纵性和改善某些声学特性[Saghafi和Lavimi 2020]。
• 应对气候变化:逆设计可以在应对气候变化的许多方法中发挥重要作用,包括改进建筑材料、优化碳捕获、太阳地球工程和碳信用和政策的设计[Rolnick等人,2022]。
• 纳米光子学:纳米光子学专注于设计与电磁波波长接近的结构。开发为与光相互作用的微米尺度结构、纳米尺度结构或拓扑图案的设计方法在激光发生、数据存储、芯片设计和太阳能电池设计等应用中具有重要意义[Molesky等人,2018]。
• 电池设计:深度学习启用的逆设计在电池设计方面具有巨大潜力。例如,它可以用于电池界面的逆设计,这对于开发高性能可充电电池至关重要[Bhowmik等人,2019]。除了电池本身,机器学习中的超参数搜索技术可以用于加速锂离子电池高循环寿命充电协议的实验探索[Attia等人,2020],这对于电动汽车至关重要。
9.3.2 技术挑战。
共同挑战:逆问题和逆设计涉及前向建模任务,用于评估方程(112)和(113)中的𝑢(𝑥,𝑡;𝛾),通常也存在于第9.2.2节中讨论的前向问题中遇到的挑战。在逆问题和逆设计中的另一个共同挑战是对抗模式。当使用基于深度学习的代理模型来推断或设计高维参数时,可能会出现带有噪声的对
抗模式,这些模式在物理上不合理,但可以获得出色的损失[Zhao等人,2022]。接下来,我们将说明几个独特的挑战。
逆问题的挑战
• 目标不匹配:当前向模型和逆问题的目标共同优化时,前向模型可能会牺牲底层PDE给出的物理约束,以换取逆问题目标的增加优化性,从而产生物理不一致的解决方案。
• 不适定性:在许多应用中,通常不会提供完整的测量数据,这使得逆问题不适定且解不唯一。例如,在建模流体时,不可行跟踪每个流体元素的运动。因此,必须使用稀疏的测量。另一个例子是层析成像,该问题基本上是不适定的,因为我们试图仅从边界上的测量中推断内部结构。
• 间接观测:在某些情况下,难以或昂贵地对物体或解决方案场的物理状态进行直接测量。相反,我们可能只能拍摄物体在环境中移动和互动的视频。然后,仅从视觉观察中推断未知参数是一个重大挑战。
• 结合物理:正如将物理原理纳入前向问题中具有挑战性一样,同样重要的是确保逆模型符合所需的物理定律。关键是从建立良好的理论中提取相关的物理知识,并将其纳入逆模型的设计中,同时保持样本和训练效率以及准确性不受任何妥协。
逆设计的挑战
• 复杂的设计空间:逆设计的一个基本挑战,尤其是对于实际应用,是设计空间是分层的、异构的,并且由许多组件组成,这些组件可以以许多不同的方式组合。以火箭设计为例。在高层次上,火箭由机身、推进系统和有效载荷组成,每个部分都可能包含数百个零件。因此,表示复杂的设计空间并针对所选择的表示进行优化是一个重大挑战。
• 多个(相互矛盾的)目标:实际工程设计问题通常具有多个可能相互矛盾的目标。例如,为了设计手机电池,我们同时希望电池具有长寿命并且轻量化。这两个目标相互矛盾,因此,我们必须找到一个平衡的权衡。
• 多个目标的时间上不断变化的重要性:在不同的情景下,各个目标的重要性可能不同。例如,当一枚火箭发射并从地面转向太空时,它将遇到截然不同的环境,导致对其空气阻力、燃油效率和结构耐久性等目标的重要性有所变化。
9.3.3 现有方法。
逆问题:最近,神经辐射场(NeRF)[Guan等人,2022]已被应用于流体动力学基础和系统识别。 NeuroFluid通过联合训练粒子过渡模型和粒子驱动的神经渲染器,从顺序视觉观察中推断基础流体动力学。 PAC-NeRF [Li et al. 2023c]设计了神经辐射场的混合欧拉-拉格朗日表示,结合可微分模拟器,用于从顺序视觉观察中估计动态对象的物理属性和几何形状。
Zhao等人[2022]解决了来自稀疏流体展开观测的流体同化问题,以及完整波形反演问题。其目标是找到一个初始条件,使模拟的展开与稀疏测量位置上的观察展开接近。为了实现自适应空间分辨率,在与学习的GNN模型[Pfaff等人,2021]一起使用的情况下,采用基于网格的数据表示,作为从初始条件预测动力学的前向模型。为了解决不适定性,Zhao等人[2022]建议从整个流场的潜在向量中学习,然后从潜在向量和网格坐标的连接中推断出每个网格点要恢复的数量。
解决逆问题的另一类重要方法是物理信息神经网络(PINNs)[Raissi等人,2019]。 PINNs是一类同时解决前向问题和逆问题的方法。它们将解函数参数化为神经网络,使用反向传播进行优化,其目标包括数据损失和物理信息损失,数据损失惩罚神经网络解与观察数据的不一致性,物理信息损失惩罚所提供的PDE的违反。在训练过程中,还可以学习PDE或系统的未知参数。此外,Lu等人[2021b]开发了一种新的具有硬约束的PINN方法(hPINN),用于解决PDE约束的逆设计问题,同时避免了PINN中常见的优化问题[Krishnapriyan等人,2021]。 hPINN方法利用两种不同的技术来强制执行PINN上的硬约束。一种是惩罚方法,通过逐渐增加边界条件和PDE的损失项的系数来实现。第二种技术涉及增广拉格朗日方法,该方法在每次迭代中使用精心选择的乘数来有效地强制执行约束。
在需要识别实际问题解的准确控制方程的情况下,各种尝试已经基于观察数据导出了准确的数学公式。传统方法[Schaeffer 2017; Brunton等人,2016; Kaiser等人,2018]通常涉及从潜在的候选函数词典中选择并找到最小化模型预测与观察数据之间差异的子集组合。最近,许多研究还利用神经网络来扩展候选函数词典或捕获这些函数之间更复杂的关系。例如,Rudy等人[2017]利用神经网络作为预定义基函数之外的补充候选函数,以建模更复杂的动态。 Martius和Lampert[2016]; Sahoo等人[2018]引入了EQL,它利用神经网络从观察数据中识别复杂的控制方程。他们不仅依赖于传统的激活函数,还采用了预定义的基本函数,包括身份和三角函数。此外,他们在框架中集成了自定义的除法单元,以捕获潜在控制方程内的除法关系。然而,该研究领域中
的通用性和过度依赖高质量测量数据仍然是关键问题。
逆设计:过去解决逆设计问题的方法主要基于领域特定的经典求解器,这些求解器计算成本极高。最近,随着神经PDE求解器的成功,AI辅助的逆设计也开始出现,但大部分仍未被探索。一个值得注意的工作是由Allen等人[2022]进行的,该工作使用整个可微分物理模拟的时间反向传播(BPTT)来设计基于粒子的模拟的边界。然而,该方法仍然计算成本高昂,因为它必须在输入空间中的数百个模拟步骤中计算梯度三次。Wu等人[2022a]引入了潜在空间中的BPTT来进行逆设计,与输入空间中的逆设计相比,这提高了运行时和准确性。对于Stokes流动,Du等人[2020]开发了一种方法,用于模拟和优化由不同类型边界条件规定的满足设计规范的Stokes系统。Li等人[2022a]进一步引入了一种各向异性本构模型,用于拓扑优化,可以生成与初始形状截然不同的新拓扑特征,并实现自由滑动和无滑动边界条件的灵活建模。
上述AI辅助逆设计的初步工作局限于相对简单和理想化的场景。因此,这些工作考虑的任务与实际工程领域中的任务之间存在巨大差距,涉及以下方面:(1)物理复杂性:实际系统中的物理可能是多分辨率的,甚至是多尺度的,这使得高效和准确的模拟变得困难。 (2)设计的复杂性:实际系统由许多部分组成,要求系统以更分层和结构化的方式进行设计。 (3)泛化性和多样性:上述测试的任务限制在特定领域,对于跨多个学科测试方法的普遍性不足。这些挑战为开发提出改进设计的新型神经表示和方法提供了巨大机会。Degrave等人[2022]的相关工作首次采用深度强化学习(RL)来塑造聚变等离子体,证明深度RL能够控制这种复杂系统。这项工作进一步证明了这种方法在复杂物理系统上的可行性,并激发了社区致力于解决更具挑战性的问题,这些问题有可能对人类产生长期有益的影响。
9.3.4 数据集与基准
对于与NeRF相关的逆问题,数据集是由仿真引擎生成的动态场景或物体的多视图图像,例如MLS-MPM [Hu等人,2018,2019a]和DFSPH [Bender和Koschier,2015]。在流体同化的背景下,可以使用诸如Zhao等人使用的有限元方法求解器[Logg等人,2012]来模拟展开数据。
在逆设计领域,正如第9.3.3节所介绍的,不同的工作使用了各自领域特定的数据集来测试其方法,例如由Allen等人[2022]考虑的用于设计翼型和粒子流体流动表面的数据集,以及[Wu等人2022a]用于设计边界以控制流体流中的烟雾的数据集。然而,目前还没有标准基准来系统评估不同的逆设计方法。此外,与实际工程任务相比,当前的数据集在物理复杂性和设计任务的难度方面明显不足。这为社区提供了一个绝佳的机会,引入更多关于物理和设计任务的复杂性的多样化基准。
9.3.5 开放性研究方向
对于逆问题,有一些可能的未来方向可以探索:(1) 不确定性量化:许多逆问题是不适定的,这种不稳定性可能导致解的不确定性增加。因此,在这些情况下,不确定性量化至关重要,因为它可以帮助描述与解相关的不确定性。(2) 改进的训练技术:复杂或不适定的逆问题在训练深度神经网络方面存在困难,这促使未来研究开发新的训练策略和正则化技术。
对于逆设计,挑战(第9.3.2节)和当前工作的局限性(第9.3.3节)也指向了令人兴奋的未来方向。我们确定了一些令人兴奋的机会。(1) 开发新的表示:分层、异构和复杂的设计空间提供了充分的机会来设计合适的表示,以平衡准确性和效率。(2) 开发新的优化方法:设计空间通常是混合的,包括离散变量(例如每个部分的数量)和连续变量(例如每个部分的形状以及如何组成部分)。这个复杂的空间为开发新的优化方法提供了令人兴奋的机会。(3) 开发跨领域更通用的方法:多样性的现实世界任务还需要更通用的方法来解决多个领域的问题。