最近和朋友包括一些国产数据库的研发人员交流,很多程序员认为 Oracle 已经过时,开源数据库或者他们研发的国产数据库才代表数据库发展的未来。甚至在很多交流会议上拿出自家产品的某一个功能点和 Oracle 对比就觉得已经遥遥领先。

实际上数据库系统的发展是一个动态的过程,通常需要与用户和应用场景的实际需求相适应。这就是为什么大多数成功的通用数据库系统都经历了长期多个版本和演化阶段,在不断地改进和完善以满足不断变化的用户和应用场景的需求。
为什么很多朋友和客户都觉得 Oracle 数据库的内部设计非常复杂,那是因为很多应用场景如果你从没碰到过,你都完全想象不出来,更不可能靠几个研发人员能提前设计出来,而是 Oracle 在四十多年的实践过程中被各种各样的用户需求和应用场景不断打磨出来的。
虽然中国在部分关键科技领域取得了革命性的突破,但是美国仍然保持着全局性和关键性的优势。
实际上大型通用数据库之所以成为卡脖子的核心技术之一,就是因为数据库在中国信息技术基础设施和各行各业中扮演着关键数据存储和查询修改的核心角色,数据库系统的处理性能、可用性和可扩展性对整个国家和社会的健康运行和正常运转具有非常重要的影响,主要体现在:

-
数据量持续增长:随着时间的推移,政府、企业和组织的数据量正在不断加速增长。这包括政府机关政务系统的核心处理数据,电力、民航、高铁、船舶、车辆交通运输控制系统数据,银行、保险、证券、金融交易数据,国家安全、警务、司法系统数据,财政、民政、税务、安监系统数据、广电、卫星、通信、卫生、疾控、医院部门核心系统数据,企业自动化生产、仓储、物流系统数据等等。
数据库必须能够有效地管理和存储这些庞大的数据集。如果数据库无法及时有效地处理这么多种类大规模数据的增删查改,轻则导致交通、生产事故和人身伤亡事故,重则危及社会基础设施运行和国家安全。
-
复杂查询需求:许多核心业务应用需要执行复杂的数据库查询,如连接多个表、聚合数据、执行复杂的过滤和排序。如果数据库查询引擎不足够高效或者数据库设计不合理,查询性能将受到影响,成为瓶颈。
-
高并发访问:政府、企业、组织的核心应用程序通常需要支持大量并发用户。例如,12306订票网站、社保网站、税务网站、电子商务网站、社交媒体平台在高峰期都面临着数以千万计甚至上亿计的用户同时访问数据库的挑战。数据库必须能够有效地处理并发访问请求,否则会导致性能卡顿或应用崩溃。
-
事务处理要求:数据库是事务性应用的核心。金融交易、交通指挥、库存管理、订单处理等领域的应用程序要求数据库保证事务的完整性和一致性。如果数据库无法有效地处理事务,可能导致数据错误和不一致。
-
数据安全性和合规性:数据安全性和合规性要求对数据库进行适当的保护和审计。加密、访问控制、审计功能等都需要在数据库中得到支持。如果数据库无法提供足够的安全性和合规性,可能会面临数据泄露和法律问题。
-
备份和恢复:数据库的备份和恢复是关键的数据管理任务。如果没有有效的备份和恢复策略,数据库出现故障时可能会导致数据丢失或错误,以至于应用程序长时间的宕机。
-
数据库设计和索引优化:数据库的设计和索引优化对于性能至关重要。不合理的数据库设计、缺乏索引或不正确的索引选择都可能导致性能问题。
-
新技术的应用:随着新技术的不断涌现,适配的数据库系统需要不断适应并集成这些新技术,在提供更好的性能和功能的同时满足稳定性和可靠性。
-
业务需求的变化:政府、企业、组织的业务需求和应用场景一直在不断变化。数据库系统必须能够灵活地适应这些新的需求和变化,灵活做出调整,否则可能会出现应用崩溃或者满足不了新的功能。
综上所述,数据库成为卡脖子技术的原因多种多样,通常是由于复杂的需求、大规模的数据、高并发访问、性能限制以及不足的数据库管理和优化策略等因素的综合影响。解决这些问题需要综合考虑数据库设计、硬件和软件配置、性能优化、容错和灾难恢复等多个方面,以确保数据库能够满足整个国家和社会不断发展的需求,是一件难度非常之大的事情,不是靠人多力量大就能解决的。
在当前环境下,多学习成熟的 Oracle 是国产数据库发展的一条捷径,Oracle 四十多年在全球多个国家和企业的大规模应用所获得的经验是十分值得我们现阶段去学习的。
今天我们来看看ORACLE Redo Log Buffer 重做日志缓冲区机制的设计。
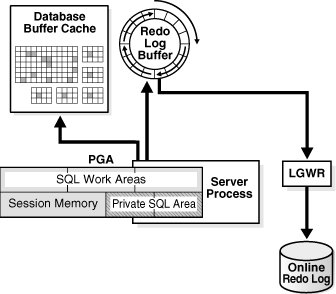
重做日志缓冲区(Redo Log Buffer)虽然是Oracle数据库SGA(System Global Area)中最小的一个内存结构,但却是一个非常关键的组件,其结构和用途都非常重要。
它的主要功能是记录用户进程执行的SQL语句对数据库内存块缓冲区的数据所做的更改操作,这些更改被称为重做日志条目。
在需要数据库恢复的情况下,这些条目包含了重建由INSERT、UPDATE、DELETE、CREATE、DROP或ALTER等操作所做的更改所需的多组信息。
重做日志缓冲区是一个循环使用的内存缓冲区,当它写满时,新的重做日志条目将从缓冲区的起始位置开始写入,覆盖旧的数据。
在Oracle数据库中,重做日志条目(Redo Log Entries)是由用户进程生成的,
用户进程包括了执行SQL语句的进程,如执行INSERT、UPDATE、DELETE等数据操作语句的会话。
当用户进程执行这些SQL语句时,它们会生成相应的重做日志条目,这些条目记录了执行的数据操作、事务信息等。
用户进程生成的重做日志条目用于保证数据的一致性和持久性。
当用户进程生成重做日志条目后,它们首先被存储在重做日志缓冲区中,然后由LGWR(Log Writer)进程负责将重做日志缓冲区中的数据定期写入磁盘上的联机重做日志组(Online Redo Log),这个过程确保了操作事务过程中数据的持久性和一致性,即使数据库发生故障,也可以通过重做日志文件来恢复数据。
LGWR 按顺序将数据块写入磁盘,而 DBWR 则将数据块分散写入磁盘。分散写入往往比顺序写入慢得多。由于 LGWR 使用户能够避免等待 DBWR 完成其缓慢写入,因此数据库通过这种设计提供了更高效的处理性能。
为了更清晰地理解用户在修改一行数据时数据库对 Redo Log 相关的一系列操作,我们来看下一步步的过程分析:
-
用户端发出一条更新的SQL语句,这个SQL语句通常是某个事务的一部分,并且Oracle为该事务分配了唯一的事务号。
-
服务器进程负责执行这个SQL语句。在执行之前,服务器进程需要将需要的数据、索引以及还原数据读入内存,并锁定将要更新的行。
-
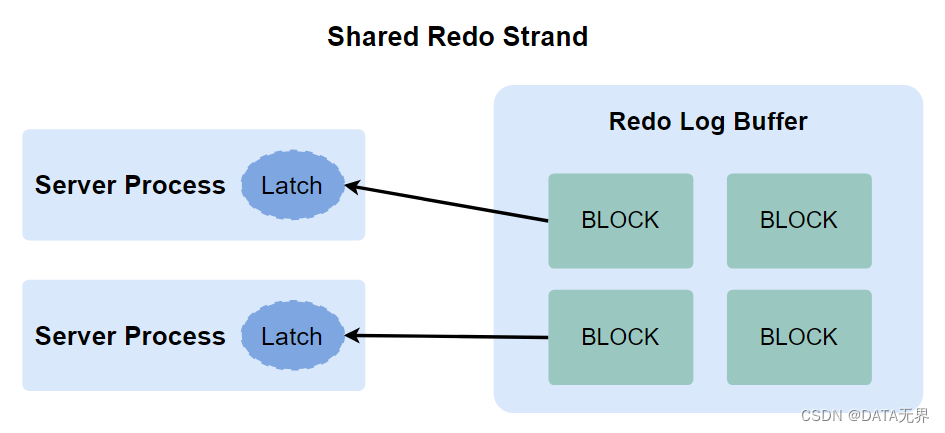
在执行更新操作之前,服务器进程会尝试获得一个重做复制闩锁(Redo Copy Latch)。这个闩锁的作用是确保对重做日志缓冲区的串行访问,以避免多个服务器进程同时更改数据,可能会发生的数据争用,并且导致性能的降低。如果没有空余的闩锁(Latch)可用,其他服务器进程将无法访问重做日志缓冲区,直到 Redo Log Buffer 写入完成,释放闩锁。
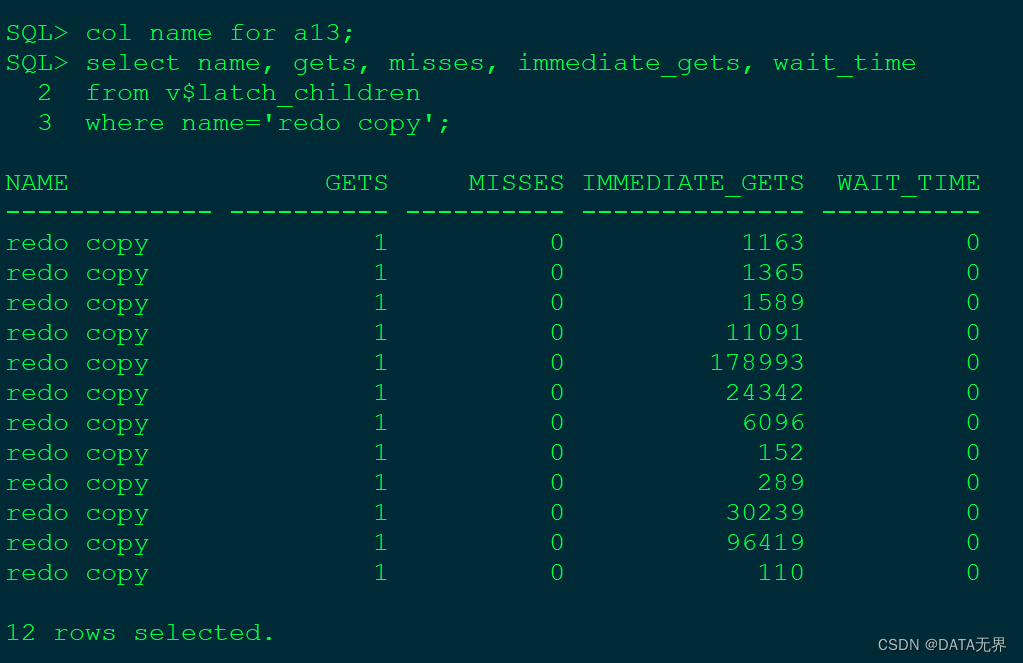
可以按如下方式查看系统的 Redo Copy Latch 当前状态。
SQL> col name for a13;
SQL> select name, gets, misses, immediate_gets, wait_time
2 from v$latch_children
3 where name='redo copy';
- 一旦获得了重做复制闩锁(Redo Copy Latch),服务器进程会再次尝试获得一个重做分配闩锁(Redo Allocation Latch),这个闩锁用于获取重做日志缓冲区中的预留空间,以便写入重做日志条目。一旦获取了重做分配闩锁并成功分配了重做日志缓冲区中的空间后,它会立即释放这个闩锁。
“Redo Allocation Latch”(重做分配闩锁)是Oracle数据库中的一种内部锁机制,用于协调和管理对重做日志缓冲区的分配操作。这个锁的主要作用是确保多个服务器进程(user processes)在向重做日志缓冲区写入新的重做日志条目时能够互斥地分配和使用缓冲区中的空间,以避免数据竞争和混乱。
具体来说,当一个服务器进程需要在重做日志缓冲区中分配一定的空间来存储新的重做日志条目时,它会尝试获取"Redo Allocation Latch",以获得分配的控制权。一旦成功获取了这个锁,服务器进程就可以安全地将新的重做日志条目写入缓冲区,并确保不会与其他进程的操作冲突。
重要的是,一旦分配操作完成,服务器进程通常会立即释放"Redo Allocation Latch",以便其他进程也可以获取并使用重做日志缓冲区中的空间。这种机制允许多个并发进程在数据库中进行写操作,同时维护了数据的一致性和完整性。
“Redo Allocation Latch”(重做分配闩锁)可以通过以下方式查看:
SQL> select count(*) from v$latch_children where name='redo allocation';

-
接下来,服务器进程使用获得的重做复制闩锁,将重做项写入重做日志缓冲区。重做项包括了更新数据的原始值、操作类型、事务号等信息。完成写入后,服务器进程释放重做日志复制闩锁。
-
与此同时,服务器进程还会将还原信息写入与该事务相关的还原段。这个还原段在用户使用ROLLBACK指令进行回滚操作时会被使用。
-
最后,服务器进程完成对数据的更新,将需要的原始值和对数据所做的修改写入数据库高速缓冲区。这些数据被标记为脏数据,因为此时内存中的数据与磁盘中的数据不一致了。
在理解了重做日志缓冲区的工作原理和上述过程后,我们可以进一步分析LGWR(Log Writer)进程何时将重做日志缓冲区中的重做数据写入重做日志文件。
深刻理解这些操作对于优化重做日志缓冲区的性能非常重要。
LGWR 进程会在以下任何一种情况发生时把缓冲区数据刷新(Flush)写入磁盘:
- 1、每3秒钟一次;
- 2、发生提交(COMMIT)或者回滚(ROLLBACK)请求时;
- 3、要求LGWR切换日志文件(Redo Log File)时;(alter system switch logfile;)
- 4、重做缓冲区(Redo_Log_Buffer)用满1/3,或者缓存重做日志数据达到 1MB 时;
由于上面的这些原因,如果重做日志缓冲区的大小超过几十MB,对大部分系统来说就没什么意义了。
除非是一个拥有大量并发事务的大型系统,或许较大的重做日志缓冲区才会对它有利,因为LGWR这个负责将重做日志缓冲区刷新输出到磁盘的进程,在将日志从缓冲区输出到磁盘时,其他会话也可能需要同时向缓冲区中填入新的数据。
一般而言,如果有一个事务长时间运行并生成大量重做日志,这种情况下采用大于常规的日志缓冲区是有好处的,因为在LGWR 将重做日志缓冲区里的数据刷新输出到磁盘的同时,这种长事务也会不断地向缓冲区里写入数据。事务越大、越长,大日志缓冲区的好处就越显著。
重做日志缓冲区的默认大小由 LOG_BUFFER 参数控制,并随不同操作系统、数据库版本和其他参数设置会有很大变化。
可以通过以下语句查询当前数据库 LOG_BUFFER 配置的大小约为 7MB 左右。(SGA为 8GB )。
SQL> show parameter log_buffer
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
log_buffer big integer 7312K
或者查询 SGA
SQL> SHOW SGA
Total System Global Area 8589930576 bytes
Fixed Size 8945744 bytes
Variable Size 1476395008 bytes
Database Buffers 7096762368 bytes
Redo Buffers 7827456 bytes // LOG_BUFFER当前配置
当LGWR(Log Writer)将重做日志缓冲区中的重做条目写入重做日志文件或磁盘时,用户进程可以继续在内存中写入磁盘的条目上复制新的重做条目。这是因为在Oracle的重做日志机制中,重做日志缓冲区是一个循环的结构,新的重做条目可能会覆盖已经安全写入磁盘的较旧条目。
这个机制确保了内存中的重做日志缓冲区保持了最新的更改。即使在LGWR将条目写入磁盘的同时,用户进程生成的新的重做条目也有可能覆盖已经写入磁盘的旧条目。
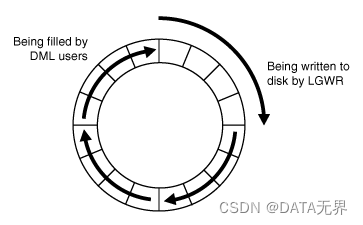
这种设计保证了数据库在需要恢复时,可以使用重做日志文件重新应用用户进程最近的更改。
LGWR(Log Writer)的主要任务之一是确保重做日志缓冲区中始终有足够的空间来容纳新生成的重做条目,即使这个缓冲区经常被访问。如果重做日志缓冲区的空间不足,LGWR会在需要时将重做日志条目写入磁盘,以释放空间供新的条目写入。这种情况下,LGWR会不断地将重做记录刷新到磁盘,以确保缓冲区保持足够的空间。
数据库初始化参数 Log_Buffer 定义了重做日志缓冲区的大小,默认值是 DB_BLOCK_SIZE 的四倍。通常,较大的 Log_Buffer 值会减少重做日志文件 I/O,尤其是在事务较长或事务数多的情况下。
在高事务负载的生产数据库中有一个重要的优化策略是增加重做日志缓冲区的大小(Log_Buffer 的值设置得足够大)。如果重做日志缓冲区足够大,那么它更有可能在不频繁刷新到磁盘的情况下容纳新的重做记录。这不仅提高了性能,还减少了频繁的重做日志文件I/O操作,因为写入磁盘通常比写入内存更耗时。
重做日志组是循环使用的,当前的重做日志文件已满并覆盖以前的文件时,如果数据库处于归档模式,归档进程(ARCH)会自动将被覆盖的重做日志文件的内容复制到归档日志文件中。
要优化数据库性能,需要考虑以下几个因素:
1. 适当设置 Log_Buffer 参数的大小,以减少重做日志文件I/O操作,特别是在高事务负载情况下。
2. 确保重做日志文件的大小和数量足够,以容纳数据库的活动,避免频繁的重做日志切换。
3. 监控数据库的性能指标,如等待事件,特别是与重做相关的性能问题,如"log buffer space"等待事件,以及通过适当的配置来解决这些问题。
还有一种优化方法就是启用"私有重做并行模式"(Private Redo Parallelism)或"零拷贝重做"(Zero Copy Redo)功能。
通过启用Oracle数据库内部参数 "_LOG_PRIVATE_PARALLELSIM"参数控制数据库引擎启用或禁用零拷贝重做优化功能。当该参数被设置为TRUE时,数据库引擎会尝试使用零拷贝技术来提高重做日志操作的性能。
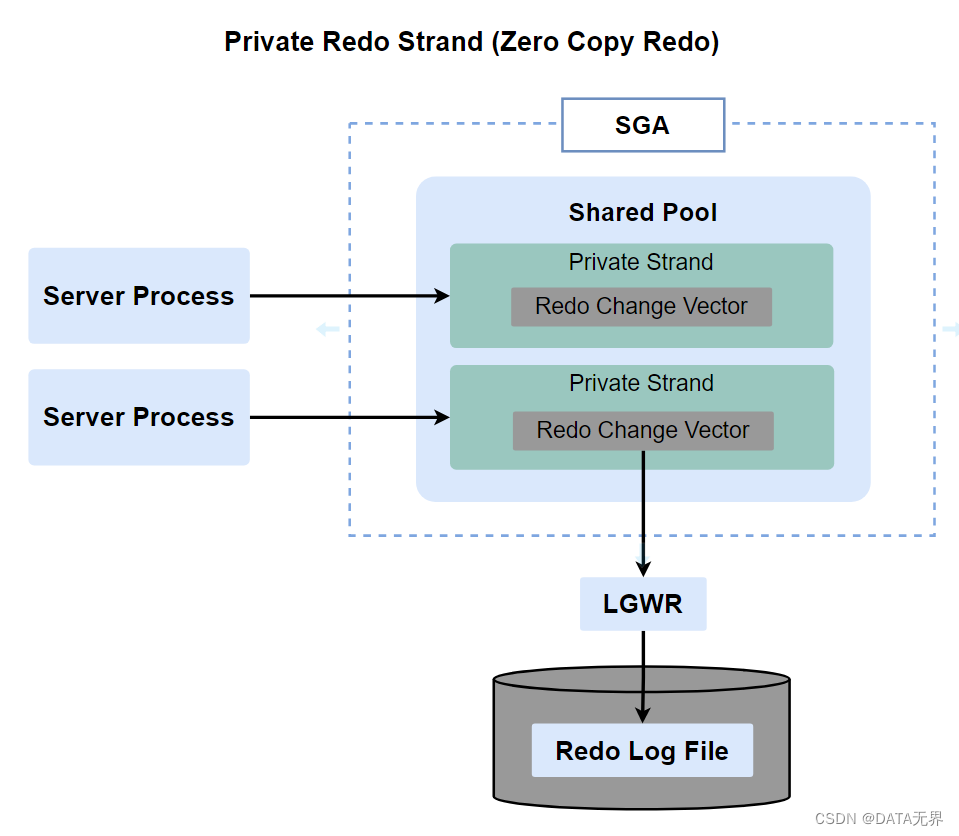
零拷贝重做优化功能可以将Shared Pool分割为多个部分,为每个服务器进程创建一个独立的专用空间,并在每个专用空间创建重做更改向量(Redo Change Vector)的数据结构,用于存储每个服务器进程重做日志的更改。
然后,LGWR进程可以直接将这个**重做更改向量(Redo Change Vector)写入磁盘上的重做日志文件,而无需将它复制到重做日志缓冲区。**这种优化可以提高性能并减少不必要的资源开销。
然而,“零拷贝重做”(Zero Copy Redo)功能的实际可行性取决于每个数据库的特定的运行环境和实际生产需求。在考虑应用这些策略时,需要仔细评估数据库的工作负载、硬件资源和数据库管理员的经验,并在非生产环境中进行详细地测试和评估,以确保它们对数据库的性能产生正面影响而不会引入不必要的风险。
重做日志缓冲区在Oracle数据库中扮演着关键的角色,用于记录和保护数据更改,同时也需要仔细配置和监视以确保数据库的高性能和可靠性。理解它的结构和用途对于数据库管理和性能优化至关重要。

最后想说,在基础核心软件研发领域,绝对不能孤立自己,关起门来造轮子,往往是自嗨,除了感动自己,更多的是走错了方向,方向错了,越努力只会离目标越远。如果不积极与其他国家的研发者交流合作,眼界通常受限,思维容易僵化。
在数据库领域,虚心请教和学习发达国家的成熟软件是非常关键的一部分。尤其是要借鉴欧美国家在软件领域的先进经验。这些国家在软件研发方面拥有丰富的经验和资源,他们的方法、技术、产品常常是业界的佼佼者。因此,与他们保持联系,向他们请教、学习他们的最佳实践,可以帮助我们在核心软件研发中不断进步。
与欧美国家的专家和团队保持合作关系,参与国际性的开源项目或国际标准制定,也是一种增长见识、提升软件开发水平的有效途径。通过与他们共同工作,可以深入了解国际软件领域的最新趋势和发展方向,从而更好地满足国内用户和市场的需求。
总之,基础核心软件研发需要开放的思维和广泛的合作。与他人共同学习、探讨问题,特别是借鉴欧美国家的先进经验,将有助于提高我们的软件研发水平,最终解决“卡脖子”的问题。

![2023年全球接口IP市场发展趋势分析:市占率第二IP品类,受大数据及计算需求推动高速增长[图]](https://img-blog.csdnimg.cn/img_convert/8c39703e60caa4bfb6385c3111a43947.png)