目录
1 LSTM网络介绍
1.1 LSTM概述
1.2 LSTM网络结构
1.3 LSTM门机制
1.4 双向LSTM
2 Pytorch LSTM输入输出
2.1 LSTM参数
2.2 LSTM输入
2.3 LSTM输出
2.4 隐藏层状态初始化
3 基于LSTM实现情感分析
3.1 情感分析介绍
3.2 数据集介绍
3.3 基于pytorch的代码实现
3.3.1 数据集加载
3.3.2 模型构建
3.3.3 模型训练
3.3.4 模型验证
3.3.5 模型预测
3.4 运行结果
3.5 完整代码
4 总结
1 LSTM网络介绍
1.1 LSTM概述
长短时记忆网络(Long Short Term Memory Network, 简称LSTM),是一种特殊的RNN,LSTM为解决RNN网络存在的长序列数据处理中的梯度消失和梯度爆炸问题而提出。它最早由Hochreiter&Schmidhuber于1997年提出,后经众多专家学者提炼和推广,现在因性能出色已经被广泛使用。
LSTM许多领域都有广泛的应用,典型的应用场景如下所示:
- 自然语言处理(NLP)。在NLP领域,LSTM可以用于文本分类、情感分析、机器翻译等任务。通过对文本序列进行建模,LSTM能够捕捉到文本中的长期依赖关系,从而提高模型的准确率。
- 语音识别(Speech Recognition)。在语音识别中,LSTM网络模型可以用于声学模型和语言模型的建模。通过对语音信号和语言模型进行联合建模,LSTM能够提高语音识别的准确率。
- 股票走势预测。LSTM可以应用于股票市场的预测,通过分析历史数据,可以帮助投资者预测未来的股票走势。
1.2 LSTM网络结构
LSTM主要依靠引入“门”机制来控制信息的传播。与循环神经网络RNN相比,LSTM的网络结构要复杂的多。在LSTM网络中,通过引入三个门来控制信息的传递,这三个门分别为遗忘门(forget gate),输入门(input gate)和输出门(output gate)。门机制是LSTM中重要的概念,那么什么是“门”以及门机制在LSTM中是如何解决长距离依赖的问题的。
RNN是一个包含大量重复神经网络模块的链式形式,在标准RNN里,这些重复的神经网络结构往往也非常简单,比如只包含单个tanh层:
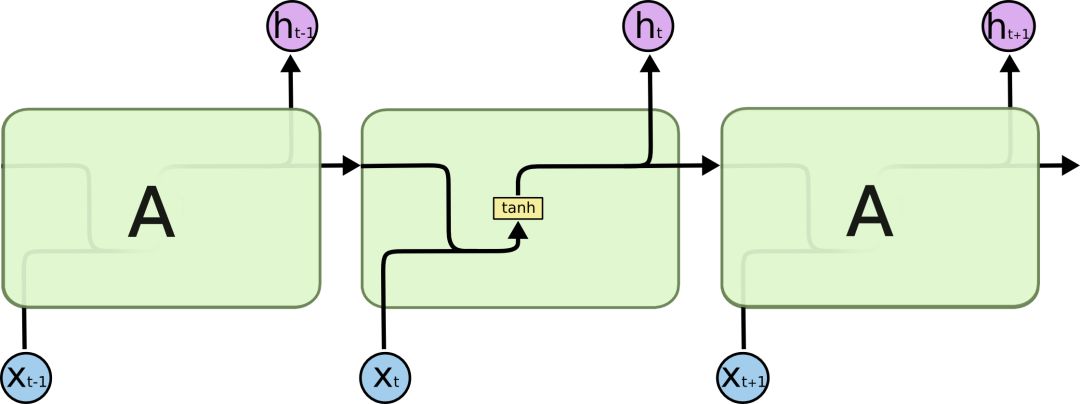
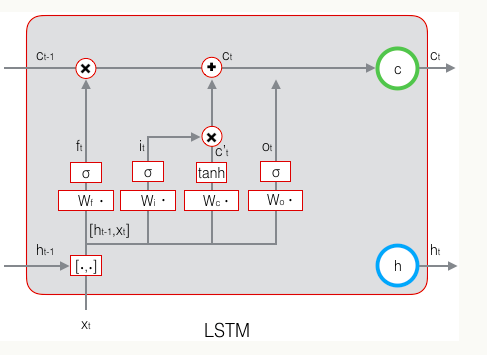
标准RNN中只包含单个tanh层的重复模块,LSTM也有与之相似的链式结构,但不同的是它的重复模块结构不同,是4个以特殊方式进行交互的神经网络。LSTM示意图如下:

图中的符号含义如下:

在示意图中,从某个节点的输出到其他节点的输入,每条线都传递一个完整的向量。粉色圆圈表示pointwise操作,如节点求和,而黄色框则表示用于学习的神经网络层。合并的两条线表示连接,分开的两条线表示信息被复制成两个副本,并将传递到不同的位置。
LSTM的内部结构图如下:
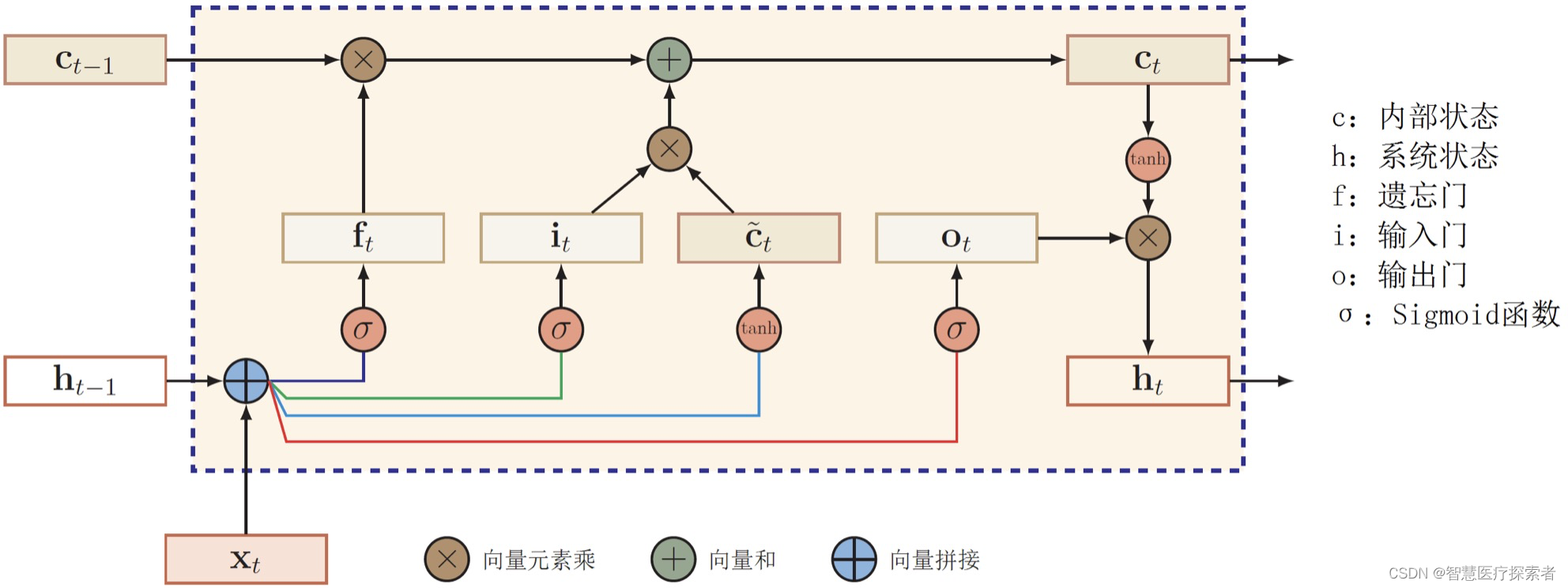
图中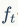 代表遗忘门,
代表遗忘门,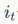 代表输入门,
代表输入门,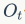 代表输出门。
代表输出门。是memroy cell,存储记忆信息。
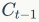 代表上一时刻的记忆信息,
代表上一时刻的记忆信息,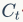 代表当前时刻的记忆信息,
代表当前时刻的记忆信息,是LSTM单元的输出,
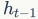 是前一刻的输出。
是前一刻的输出。
原始RNN的隐藏层只有一个状态,即h,它对于短期的输入非常敏感。那么,假如我们再增加一个状态,即c,让它来保存长期的状态,如下图所示:
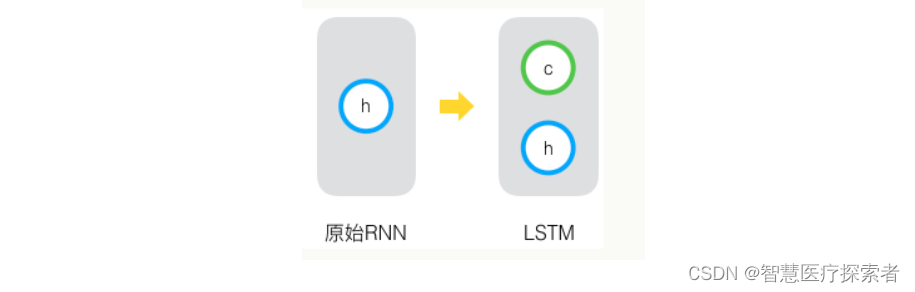
新增加的状态c,称为单元状态(cell state)。把上面的图按照时间维度展开:

在每个时刻t,LSTM的输入有三个:当前的输入值x(t),前一时刻LSTM的输出值h(t-1),前一时刻的单元状态c(t-1)。LSTM的输出有两个,当前时刻LSTM的输出值h(t),当前时刻的单元状态c(t)。
LSTM的关键,就是怎样控制长期状态c。在这里,LSTM的思路是使用三个控制开关。
- 第一个开关,负责控制继续保存长期状态c;
- 第二个开关,负责控制把即时状态输入到长期状态c;
- 第三个开关,负责控制是否把长期状态c作为当前的LSTM的输出。
三个开关的作用如下图所示:

1.3 LSTM门机制
现实中的“门”通常解释为出入口,在LSTM网络的门也是一种出入口,但是是控制信息的出入口。门的状态通常有三种状态,分别为全开(信息通过概率为1),全闭(信息通过概率为0)以及半开(信息通过概率介于0和1之间)。在这里,我们发现对于全开,全闭以及半开三种状态下的信息通过可以通过概率来表示,在神经网络中,sigmoid函数也是一个介于0和1之间的表示,可以应用到LSTM中门的计算中。
开关在算法中用门来实现,门实际上就是一层全连接层,它的输入是一个向量,输出是一个0到1之间的实数向量。假设W是门的权重向量,b是偏置项,那么门可以表示为:
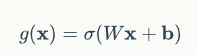
门的使用,就是用门的输出向量按元素乘以我们需要控制的那个向量。因为门的输出是0到1之间的实数向量,那么,当门输出为0时,任何向量与之相乘都会得到0向量,这就相当于啥都不能通过;输出为1时,任何向量与之相乘都不会有任何改变,这就相当于啥都可以通过。因为σ(也就是sigmoid函数)的值域是(0,1),所以门的状态都是半开半闭的。
LSTM一共有三个门,LSTM用两个门来控制单元状态c的内容:
- 遗忘门(forget gate):它决定了上一时刻的单元状态c(t-1)有多少保留到当前时刻c(t);
- 输入门(input gate):它决定了当前时刻网络的输入x(t)有多少保存到单元状态c(t)。
- 输出门(output gate):它来控制单元状态c(t)有多少输出到LSTM的当前输出值h(t)。
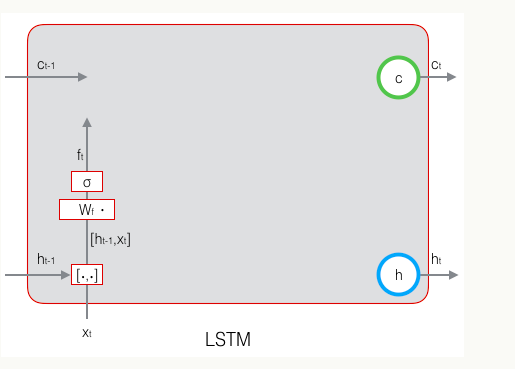
遗忘门:控制上一时刻的单元状态
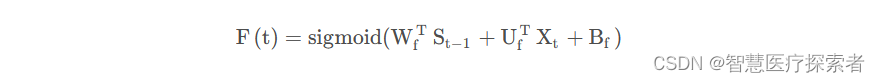
遗忘门的主要作用是用来决定当前的状态需要丢弃之前的那些信息。遗忘门是由前一个时刻的输出h和这个时刻的输入x决定的,遗忘门的计算传播如下图:
输入门:控制当前时刻的输入门

输入门也是由上一时刻的输出h和这个时刻的输入t决定的,计算传播如下图:
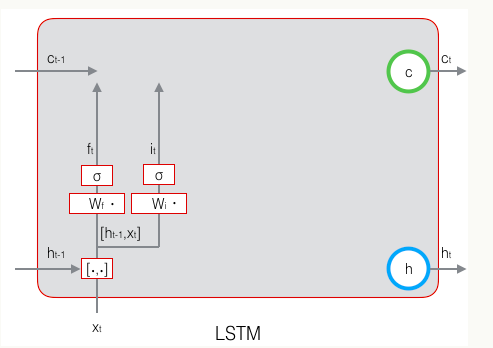
除了遗忘门、输入门,还有当前时刻的单元状态c(这只是一个临时值,描述当前输入,由输入门控制)也是由前一时刻的输出h和这个时刻的输入x决定的,计算公式如下:
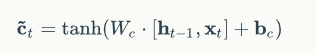
计算传播如下:

最终的要传到下一层的当前时刻的单元状态c,由遗忘门、输入门、描述输入的单元状态临时值、前一个时刻的最终单元状态共同决定。
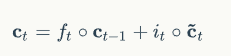
圆圈表示按元素乘,计算规则如下图:
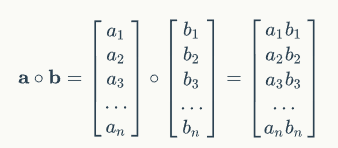
作用于一个向量和一个矩阵时广播。
前一个时刻的最终单元状态由遗忘门决定,当前单元状态的临时值由输入门决定,通过遗忘门和输入门将当前的记忆和长期的记忆组合在一起,形成最终的当前时刻的单元状态。
由于遗忘门的控制,它可以保存很久很久之前的信息,由于输入门的控制,它又可以避免当前无关紧要的内容进入记忆。

输出门:控制当前时刻的单元状态
当前时刻LSTM的输出由输出门控制,输出门控制了长期记忆对当前输出的影响,与当前时刻的输入x和前一时刻的输出h有关,计算公式如下:
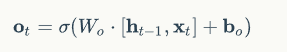
输出门的计算传播如下:
最终输出的计算由当前时刻的最终单元状态c和输出门共同决定,最终单元状态不仅包括此时的记忆,还包括之前的记忆。计算公式如下:

LSTM的最终计算如下图:

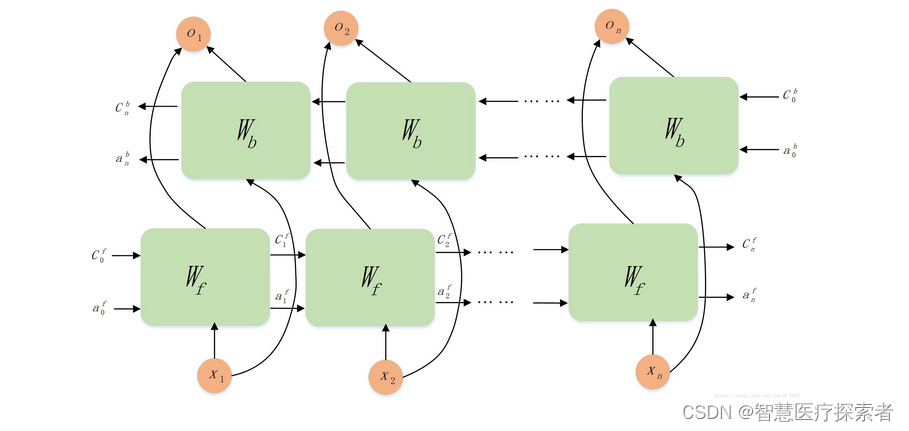
1.4 双向LSTM
双向LSTM,由两个普通LSTM组成,能够同时利用过去和未来时刻的信息,推导当前时刻的信息。双向LSTM可以在序列中处理上下文上的信息,从而更好地进行处理。双向LSTM可以通过查看序列中的前后文本来预测每个时间步长的输出。
以自然语言处理为例,双向LSTM模型能比单向LSTM模型获得更好的语言模型。在NLP中,人们常常使用双向LSTM来捕捉词汇上下文信息和句子结构信息,提高语言模型的性能。具体网络结构如下:

2 Pytorch LSTM输入输出
2.1 LSTM参数
torch.nn.LSTM(*args, **kwargs)
Parameters:
input_size – The number of expected features in the input x
hidden_size – The number of features in the hidden state h
num_layers – Number of recurrent layers. E.g., setting
num_layers=2would mean stacking two LSTMs together to form a stacked LSTM, with the second LSTM taking in outputs of the first LSTM and computing the final results. Default: 1bias – If
False, then the layer does not use bias weights b_ih and b_hh. Default:Truebatch_first – If
True, then the input and output tensors are provided as (batch, seq, feature) instead of (seq, batch, feature). Note that this does not apply to hidden or cell states. See the Inputs/Outputs sections below for details. Default:Falsedropout – If non-zero, introduces a Dropout layer on the outputs of each LSTM layer except the last layer, with dropout probability equal to
dropout. Default: 0bidirectional – If
True, becomes a bidirectional LSTM. Default:Falseproj_size – If
> 0, will use LSTM with projections of corresponding size. Default: 0
LSTM总共有七个参数,其中只有前三个是必须的。由于大家普遍使用PyTorch的DataLoader来形成批量数据,因此batch_first也比较重要。LSTM的两个常见的应用场景为文本处理和时序预测:
- input_size:输入特征维度
(1)文本处理:在文本处理中,由于一个单词没法参与运算,因此我们得通过Word2Vec来对单词进行嵌入表示,将每一个单词表示成一个向量,此时input_size=embedding_size。比如每个句子中有五个单词,每个单词用一个100维向量来表示,那么这里input_size=100;
(2)时序数据处理:在时间序列预测中,比如需要预测负荷,每一个负荷都是一个单独的值,都可以直接参与运算,因此并不需要将每一个负荷表示成一个向量,此时input_size=1。 但如果我们使用多变量进行预测,比如我们利用前24小时每一时刻的[负荷、风速、温度、压强、湿度、天气、节假日信息]来预测下一时刻的负荷,那么此时input_size=7。
- hidden_size:隐藏层节点个数。可以根据实际情况设置。
- num_layers:层数。nn.LSTMCell与nn.LSTM相比,num_layers默认为1。
- batch_first:默认为False。
LSTM默认batch_first=False,即默认batch_size这个维度是在数据维度的中间的那个维度,即喂入的数据为【seq_len, batch_size, hidden_size】这样的格式。此时:
lstm_out:【seq_len, batch_size, hidden_size * num_directions】
lstm_hn:【num_directions * num_layers, batch_size, hidden_size】当设置batch_first=True时,喂入的数据就为【batch_size, seq_len, hidden_size】这样的格式。此时:
lstm_out:【 batch_size, seq_len, hidden_size * num_directions】
lstm_hn:【num_directions * num_layers, batch_size, hidden_size】2.2 LSTM输入
 可以看到,输入由两部分组成:input、(初始的隐状态h_0,初始的单元状态c_0) 其中input:
可以看到,输入由两部分组成:input、(初始的隐状态h_0,初始的单元状态c_0) 其中input:
input(seq_len, batch_size, input_size)当设置batch_first=True时:
input(batch_size, seq_len, input_size)- seq_len:在文本处理中,如果一个句子有7个单词,则seq_len=7;在时间序列预测中,假设我们用前24个小时的负荷来预测下一时刻负荷,则seq_len=24。
- batch_size:一次性输入LSTM中的样本个数。在文本处理中,可以一次性输入很多个句子;在时间序列预测中,也可以一次性输入很多条数据。
- input_size:输入特征维度。
(h_0, c_0):
h_0(num_directions * num_layers, batch_size, hidden_size)
c_0(num_directions * num_layers, batch_size, hidden_size)h_0和c_0的shape一致。
- num_directions:如果是双向LSTM,则num_directions=2;否则num_directions=1。
- num_layers:层数。
- batch_size:一次性输入LSTM中的样本个数。
- hidden_size:隐藏层节点个数。
总结如下:
输入数据包括input,(h_0,c_0):
- input就是shape==(seq_length,batch_size,input_size)的张量,batch_first默认为False
- h_0的shape==(num_layers×num_directions,batch,hidden_size)的张量,它包含了在当前这个batch_size中每个句子的初始隐藏状态,num_layers就是LSTM的层数,如果
- bidirectional=True,num_directions=2,否则就是1,表示只有一个方向,
- c_0和h_0的形状相同,它包含的是在当前这个batch_size中的每个句子的初始细胞状态。
- h_0,c_0如果不提供,那么默认是0
- batch_first=True, 就是让batch在输入和输出放在最前面的维度
2.3 LSTM输出
 输出也由两部分组成:output、(隐状态h_n,单元状态c_n),其中output的shape为:
输出也由两部分组成:output、(隐状态h_n,单元状态c_n),其中output的shape为:
output(seq_len, batch_size, num_directions * hidden_size)当设置batch_first=True时:
output(batch_size, seq_len, num_directions * hidden_size)h_n和c_n的shape保持不变
总结如下:
输出数据包括output,(h_n,c_n):`
- output的shape==(seq_length,batch_size,num_directions×hidden_size),它包含的LSTM的最后一层的输出特征(h_t),t是batch_size中每个句子的长度。batch_first默认为False。
- h_n是包含了所有层的信息。shape==(num_directions × num_layers,batch,hidden_size)
- c_n.shape==h_n.shape
- h_n包含的是句子的最后一个单词的隐藏状态,c_n包含的是句子的最后一个单词的细胞状态,所以它们都与句子的长度seq_length无关。
- output[-1]与h_n是相等的,因为output[-1]包含的正是batch_size个句子中每一个句子的最后一个单词的隐藏状态,注意LSTM中的隐藏状态其实就是输出,cell state细胞状态才是LSTM中一直隐藏的,记录着信息。
2.4 隐藏层状态初始化
在LSTM网络训练过程中,每个batch都会将隐藏层重新初始化。
for epoch in range(epochs):
for index, (x_train, y_train) in enumerate(train_loader):
cur_batch = len(x_train)
h = model.init_hidden(cur_batch) # 初始化第一个Hidden_state
x_train, y_train = x_train.to(device), y_train.to(device)
step += 1 # 训练次数+1h与c是状态,不是参数,每个batch中都需要初始化为0,LSTM 中的参数是W,b。而LSTM网络中训练的是参数,不是状态。

每个batch训练,都要重新开始进行传播,不考虑两个batch之间的关系,所以都要进行隐藏状态的初始化。
3 基于LSTM实现情感分析
3.1 情感分析介绍
文本情感分析(Sentiment Analysis)是自然语言处理(NLP)方法中常见的应用,也是一个有趣的基本任务,尤其是以提炼文本情绪内容为目的的分类。它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。
本文将介绍情感分析中的情感极性(倾向)分析。所谓情感极性分析,指的是对文本进行褒义、贬义、中性的判断。在大多应用场景下,只分为两类。例如对于“喜爱”和“厌恶”这两个词,就属于不同的情感倾向。
本文将详细介绍如何使用深度学习模型中的LSTM模型来实现文本的情感分析。
3.2 数据集介绍
以某电商网站中某个商品的评论作为语料(corpus.csv),该数据集一共有4310条评论数据,文本的情感分为两类:“正面”和“反面”,其中正面数据1908条,负面数据2375条。
evaluation,label
用了一段时间,感觉还不错,可以,正面
电视非常好,已经是家里的第二台了。第一天下单,第二天就到本地了,可是物流的人说车坏了,一直催,客服也帮着催,到第三天下午5点才送过来。父母年纪大了,买个大电视画面清晰,趁着耳朵还好使,享受几年。,正面
电视比想象中的大好多,画面也很清晰,系统很智能,更多功能还在摸索中,正面
不错,正面
用了这么多天了,感觉还不错。夏普的牌子还是比较可靠。希望以后比较耐用,现在是考量质量的时候。,正面
物流速度很快,非常棒,今天就看了电视,非常清晰,非常流畅,一次非常完美的购物体验,正面
非常好,客服还特意打电话做回访,正面
物流小哥不错,辛苦了,东西还没用,正面
......
价格给力,买的时候有点贵了,现在便宜了。,负面
价格欺诈,先把价格抬很好,然后降价,刚买了没几天,电视还没怎么体验呢,又降了200。有点心塞。询问客服,客服都不搭理的。物流师傅倒是不错,只是物流公司不按约定时间送货,随意更改。,负面
留意微鲸好久了,一直等待活动入手。可惜越等越贵,今年电视全部都涨价了,6月果断入手。用着还不错,一到跟儿子一起打开,他很开心,可以看巧虎,挂架是找了楼下装空调的师傅打了墙孔,有钻头我就自己搞定了,负面
买的第三台微鲸电视了,效果很好,送货快,推荐哦(????????)哦,就是今年涨价了,去年618 55寸只要2600而且还是lg的屏,今年换成京东方了,负面
买完就降价两百,负面
去nmd京东,说好30天价保。5月24号下单买的3198,6月1日直接给我降到2698!当时安装师傅都说买贵了,我还没在意,现在给我来这一出。去nmlgb的京东,当别人都是傻子吗?!,负面
去年1299元购买一台微鲸W43F,觉得不错。打算再买一台,谁知涨价了。经反复比较觉得还是微鲸性价比高,最后决定升级55寸4K大屏。内存2G+16G,还有语音遥控。悲催的是遥控器可能是坏的,正在申请售后。希望不要出什么麻烦。,负面
去年双十一的时候买了微鲸55寸的电视,使用感觉还可以,后来电视一直涨价,好在这次京东618的价格还算可以,虽然还是相比去年的价格还是上涨了不少,但这个也没办法,显示屏,内存,闪存的那些上游厂家都涨价了,可惜的就是43寸的电视在使用中感觉性能上略有不足,不过普通家庭看电视也可以了,负面
速度快,价格一般速度快,价格一般,负面
微鲸的性价比和操作性一直是比较好的,从去年到现在,给自己和亲戚买了五六个了,虽然液晶面板涨价,但总体来说还是划算的。和市面上大多的智能电视相比,软件安装不受限是个最大的优点,而且蓝牙遥控也很好用,比红外好操作。界面也很友好。,负面
微鲸电视不是第一个人,已经是买第二台了,一直觉得不错。嗯,但是价格比之前买的贵了,希望,又不过趁着618还是很划算的。,负面
微鲸电视超棒(⊙o⊙)哦,就是比去年贵不少,负面数据集的下载地址:corpus.csv
3.3 基于pytorch的代码实现
3.3.1 数据集加载
data_path = 'data/corpus.csv'
df = pd.read_csv(data_path)
x = df['evaluation']
y = df['label']
texts_cut = [jieba.lcut(one_text) for one_text in x]
label_set = set()
for label in y:
label_set.add(label)
label_set = np.array(list(label_set))
labels_one_hot = []
for label in y:
label_zero = np.zeros(len(label_set))
label_zero[np.in1d(label_set, label)] = 1
labels_one_hot.append(label_zero)
labels = np.array(labels_one_hot)
num_words = 3000
tokenizer = Tokenizer(num_words=num_words)
tokenizer.fit_on_texts(texts=texts_cut)
num_words = min(num_words, len(tokenizer.word_index) + 1)
sentence_len = 64
texts_seq = tokenizer.texts_to_sequences(texts=texts_cut)
texts_pad_seq = pad_sequences(texts_seq, maxlen=sentence_len, padding='post', truncating='post')
# 拆分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(texts_pad_seq, labels, test_size=0.2, random_state=1)
train_dataset = TensorDataset(torch.from_numpy(x_train), torch.from_numpy(y_train))
test_dataset = TensorDataset(torch.from_numpy(x_test), torch.from_numpy(y_test))
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=True)3.3.2 模型构建
import torch.nn as nn
import torch
class SentimentNet(nn.Module):
device = torch.device('cuda') if torch.cuda.is_available() else torch.device("cpu")
def __init__(self, vocab_size, input_dim, hid_dim, layers, output_dim):
super(SentimentNet, self).__init__()
self.n_layers = layers
self.hidden_dim = hid_dim
self.embeding_dim = input_dim
self.output_dim = output_dim
drop_prob = 0.5
self.lstm = nn.LSTM(self.embeding_dim, self.hidden_dim, self.n_layers,
dropout=drop_prob, batch_first=True)
self.fc = nn.Linear(in_features=self.hidden_dim, out_features=self.output_dim)
self.sigmoid = nn.Sigmoid()
self.dropout = nn.Dropout(drop_prob)
self.embedding = nn.Embedding(vocab_size, self.embeding_dim)
def forward(self, x, hidden):
x = x.long()
embeds = self.embedding(x)
lstm_out, hidden = self.lstm(embeds, hidden)
out = self.dropout(lstm_out)
out = self.fc(out)
out = self.sigmoid(out)
out = out[:, -1, :]
out = out.squeeze()
out = out.contiguous().view(-1)
return out, hidden
def init_hidden(self, batch_size):
hidden = (torch.zeros(self.n_layers, batch_size, self.hidden_dim).to(self.device),
torch.zeros(self.n_layers, batch_size, self.hidden_dim).to(self.device))
return hidden3.3.3 模型训练
model = SentimentNet(num_words, 256, 128, 8, 2)
lr = 0.0001
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
criterion = nn.BCELoss()
device = torch.device('cuda') if torch.cuda.is_available() else torch.device("cpu")
epochs = 32
step = 0
model.train() # 开启训练模式
for epoch in range(epochs):
for index, (x_train, y_train) in enumerate(train_loader):
cur_batch = len(x_train)
h = model.init_hidden(cur_batch) # 初始化第一个Hidden_state
x_train, y_train = x_train.to(device), y_train.to(device)
step += 1 # 训练次数+1
x_input = x_train.to(device)
model.zero_grad()
output, h = model(x_input, h)
# 计算损失
loss = criterion(output, y_train.float().view(-1))
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), max_norm=5)
optimizer.step()
if step % 32 == 0:
print("Epoch: {}/{}...".format(epoch + 1, epochs),
"Step: {}...".format(step),
"Loss: {:.6f}...".format(loss.item()))
epoch_loss.append(loss)3.3.4 模型验证
model.eval()
loss = 0
for data in tqdm(train_loader):
x_train, y_train = data
x_train, y_train = x_train.to(device), y_train.to(device)
cur_batch = len(x_train)
h = model.init_hidden(cur_batch) # 初始化第一个Hidden_state
x_input = x_train.long()
x_input = x_input.to(device)
output, h = model(x_input, h)
loss += criterion(output, y_train.float().view(-1))
print("test Loss: {:.6f}...".format(loss))3.3.5 模型预测
test_text_cut = [jieba.lcut("商品质量相当不错,点赞"),
jieba.lcut("什么破东西,简直没法使用")]
test_seq = tokenizer.texts_to_sequences(texts=test_text_cut)
test_pad_seq = pad_sequences(test_seq, maxlen=sentence_len, padding='post', truncating='post')
h = model.init_hidden(len(test_pad_seq))
output, h = model(torch.tensor(test_pad_seq), h)
print(output.view(-1, 2))
3.4 运行结果
Epoch: 1/32... Step: 108... Loss: 73.786831...
Epoch: 2/32... Step: 216... Loss: 64.638946...
Epoch: 3/32... Step: 324... Loss: 62.405033...
Epoch: 4/32... Step: 432... Loss: 55.636972...
Epoch: 5/32... Step: 540... Loss: 47.018067...
Epoch: 6/32... Step: 648... Loss: 42.855574...
Epoch: 7/32... Step: 756... Loss: 38.990385...
Epoch: 8/32... Step: 864... Loss: 36.197353...
Epoch: 9/32... Step: 972... Loss: 38.080607...
Epoch: 10/32... Step: 1080... Loss: 35.610960...
Epoch: 11/32... Step: 1188... Loss: 33.048675...
Epoch: 12/32... Step: 1296... Loss: 31.463715...
Epoch: 13/32... Step: 1404... Loss: 31.872352...
Epoch: 14/32... Step: 1512... Loss: 32.763812...
Epoch: 15/32... Step: 1620... Loss: 28.785963...
Epoch: 16/32... Step: 1728... Loss: 29.832949...
Epoch: 17/32... Step: 1836... Loss: 27.506568...
Epoch: 18/32... Step: 1944... Loss: 25.992162...
Epoch: 19/32... Step: 2052... Loss: 23.530551...
Epoch: 20/32... Step: 2160... Loss: 25.915338...
Epoch: 21/32... Step: 2268... Loss: 24.821649...
Epoch: 22/32... Step: 2376... Loss: 21.365095...
Epoch: 23/32... Step: 2484... Loss: 21.001188...
Epoch: 24/32... Step: 2592... Loss: 19.786633...
Epoch: 25/32... Step: 2700... Loss: 18.771839...
Epoch: 26/32... Step: 2808... Loss: 18.928787...
Epoch: 27/32... Step: 2916... Loss: 18.087029...
Epoch: 28/32... Step: 3024... Loss: 17.189056...
Epoch: 29/32... Step: 3132... Loss: 16.458333...
Epoch: 30/32... Step: 3240... Loss: 15.939349...
Epoch: 31/32... Step: 3348... Loss: 15.498337...
Epoch: 32/32... Step: 3456... Loss: 15.064007...
100%|██████████| 27/27 [00:01<00:00, 21.16it/s]
test Loss: 9.794393...
tensor([[0.9946, 0.0059],
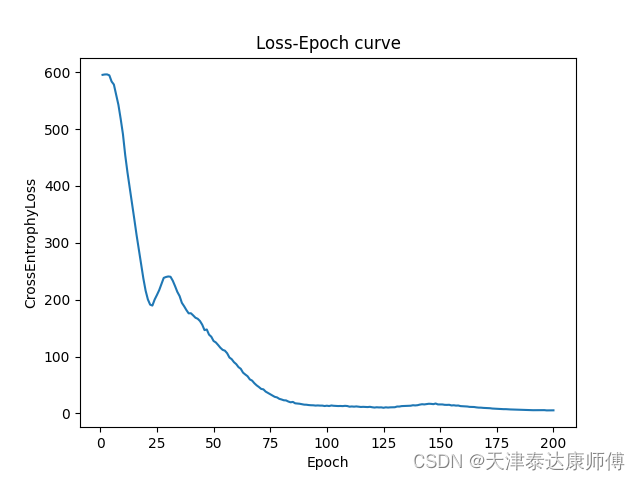
[0.0509, 0.9495]], grad_fn=<ViewBackward0>)loss值变化曲线:
x = [epoch + 1 for epoch in range(epochs)]
plt.plot(x, epoch_loss_list)
plt.xlim(0, 32)
plt.ylim(0, 100)
plt.show()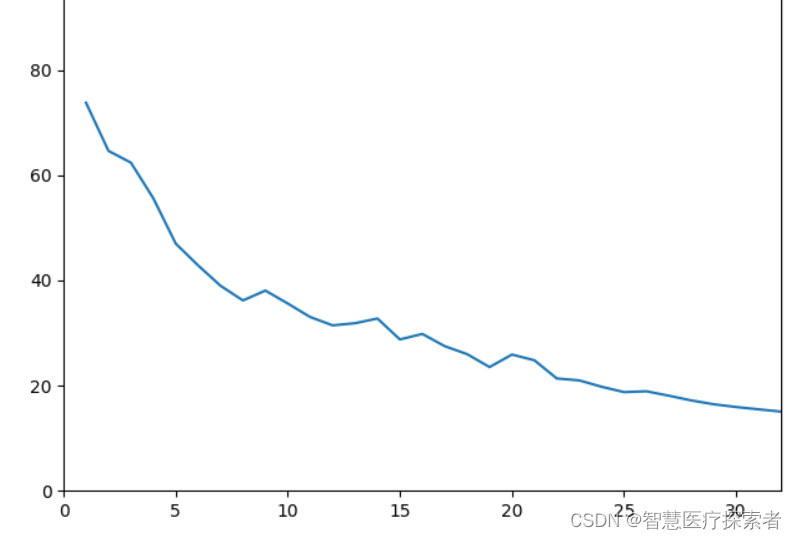
3.5 完整代码
代码:https://gitcode.net/ai-medical/lstm_sentiment_analyse
4 总结
LSTM通过其内部的门控机制,能够有效地处理长序列数据并捕捉序列中的长期依赖关系,因此在各种序列数据建模任务中具有广泛的应用前景。







![[React] 性能优化相关 (一)](https://img-blog.csdnimg.cn/715adda780f14b599d911c4465ead2b5.png)