ACM MM
Point-aware Interaction and CNN-induced Refinement Network for RGB-D Salient Object Detection
code
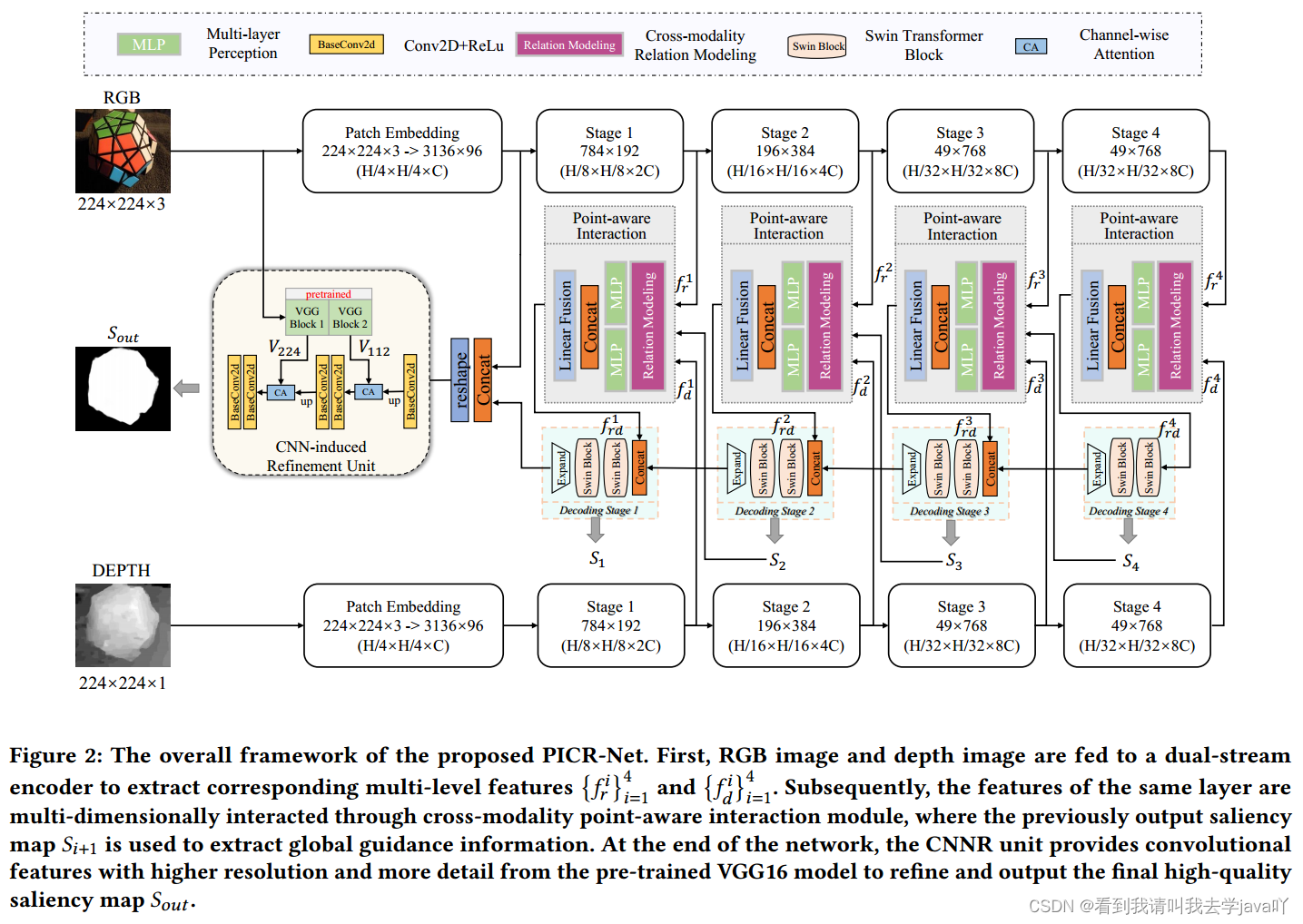
Abstacrt:近年来,CNN在特征提取和跨模态交互中得到了充分的利用,但在自模态和跨模态的全局远程依赖关系建模方面仍存在不足。因此,本文引入了CNN辅助的Transformer架构,并提出了点感知交互和CNN诱导细化的RGB-D网络,即PICR-Net。考虑到RGB和深度图之间的先验相关性,本文设计了一个注意力触发的跨模态点感知交互模块,即CmPI,探索不同模态在位置约束下的特征交互;为缓解Transformer的块效应和细节破坏问题,本文设计了CNN诱导细化单元,即CNNR,对内容进行细化和补充。
| ~Parting Line~ |
|---|
IEEE TIP
CAVER: Cross-Modal View-Mixed Transformer for Bi-Modal Salient Object Detection
code
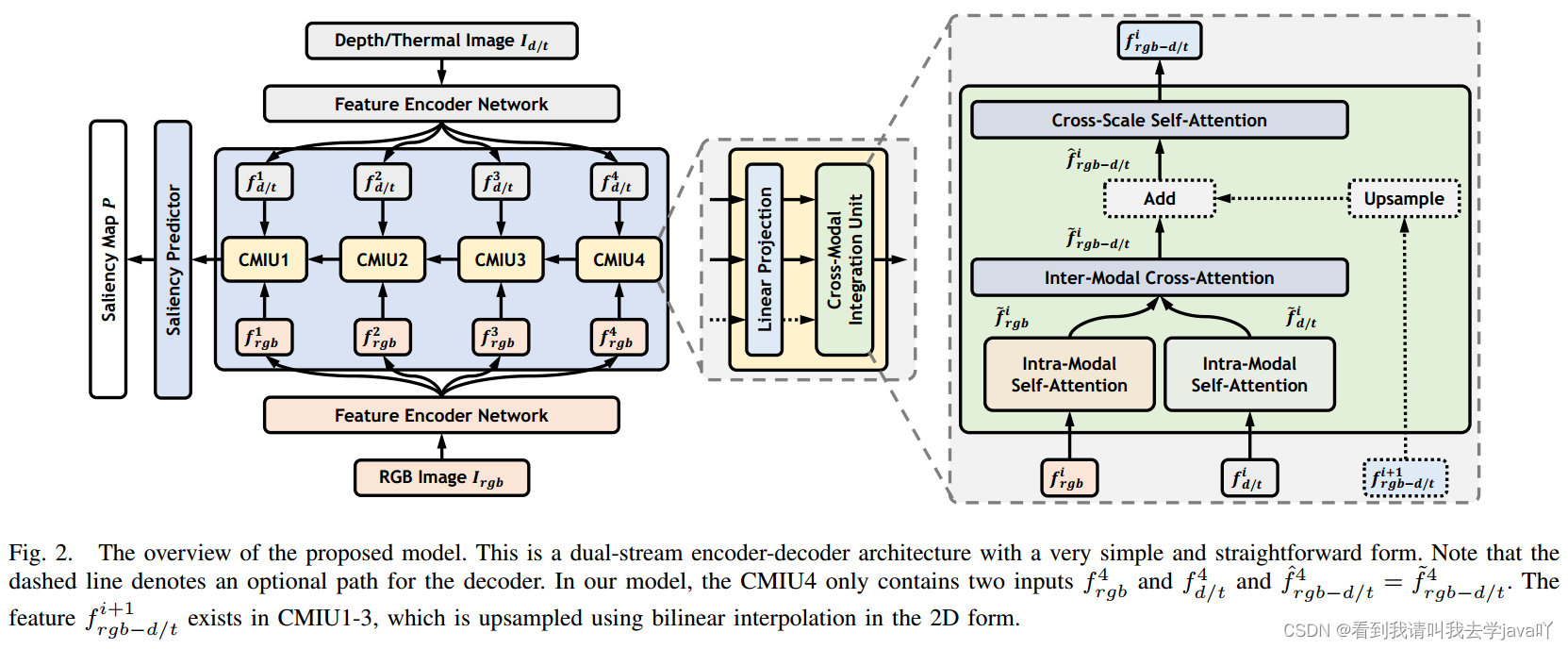
Abstacrt:卷积运算固有的局部连通性限制了双模态(RGB-D和RGB-T)显著性检测的结果。本文提出跨模态视图混合Transformer,即CAVER,串联多个跨模态集成单元,构造自顶向下的基于Transformer的信息传播路径。CAVER将多尺度、多模态特征集成单元作为一种序列到序列的上下文传播和更新过程,构建在一种视图混合注意力机制上。此外,考虑到输入token数量的二次复杂度,本文设计了一个无参数的基于patch的token重嵌入策略,以简化操作。
| ~Parting Line~ |
|---|
ICME
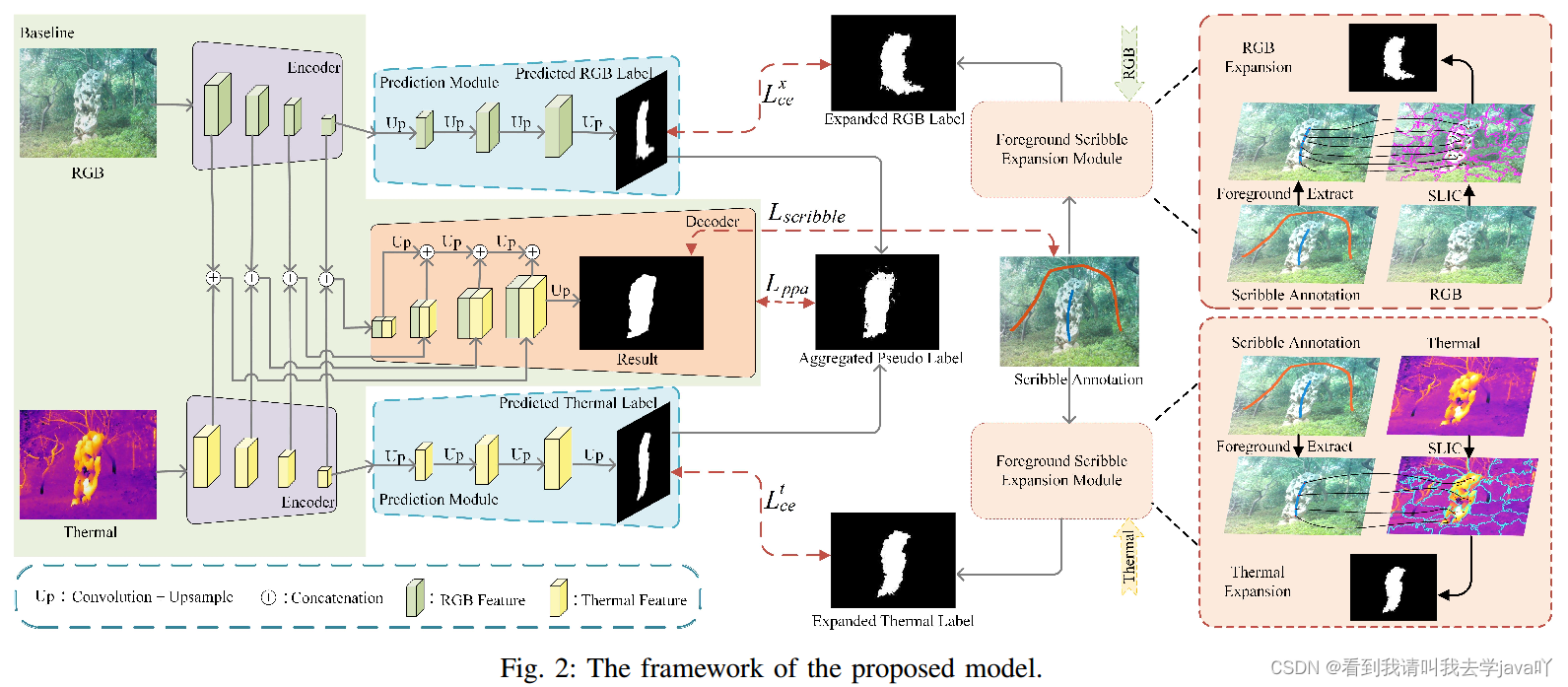
Scribble-Supervised RGB-T Salient Object Detection
code
Abstacrt:RGB和热图像为显著性检测提供了互补信息,而涂鸦标注则减轻了大量的人工劳动。因此,本文提出了涂鸦监督的RGB-T显著性检测模型。通过四步求解(展开、预测、聚合和监督),解决了涂鸦监督方法的标签稀疏问题。为扩展涂鸦注释,本文收集了RGB和热图像前景涂鸦所经过的超像素。扩展的多模态标签提供了粗略的边界。为进一步优化扩展后的标签,本文提出了一个预测模块来缓解边界的尖锐性。为利用两种模式的互补作用,本文将这两种模式合并为聚合的伪标签。
| ~Parting Line~ |
|---|
Information Fusion
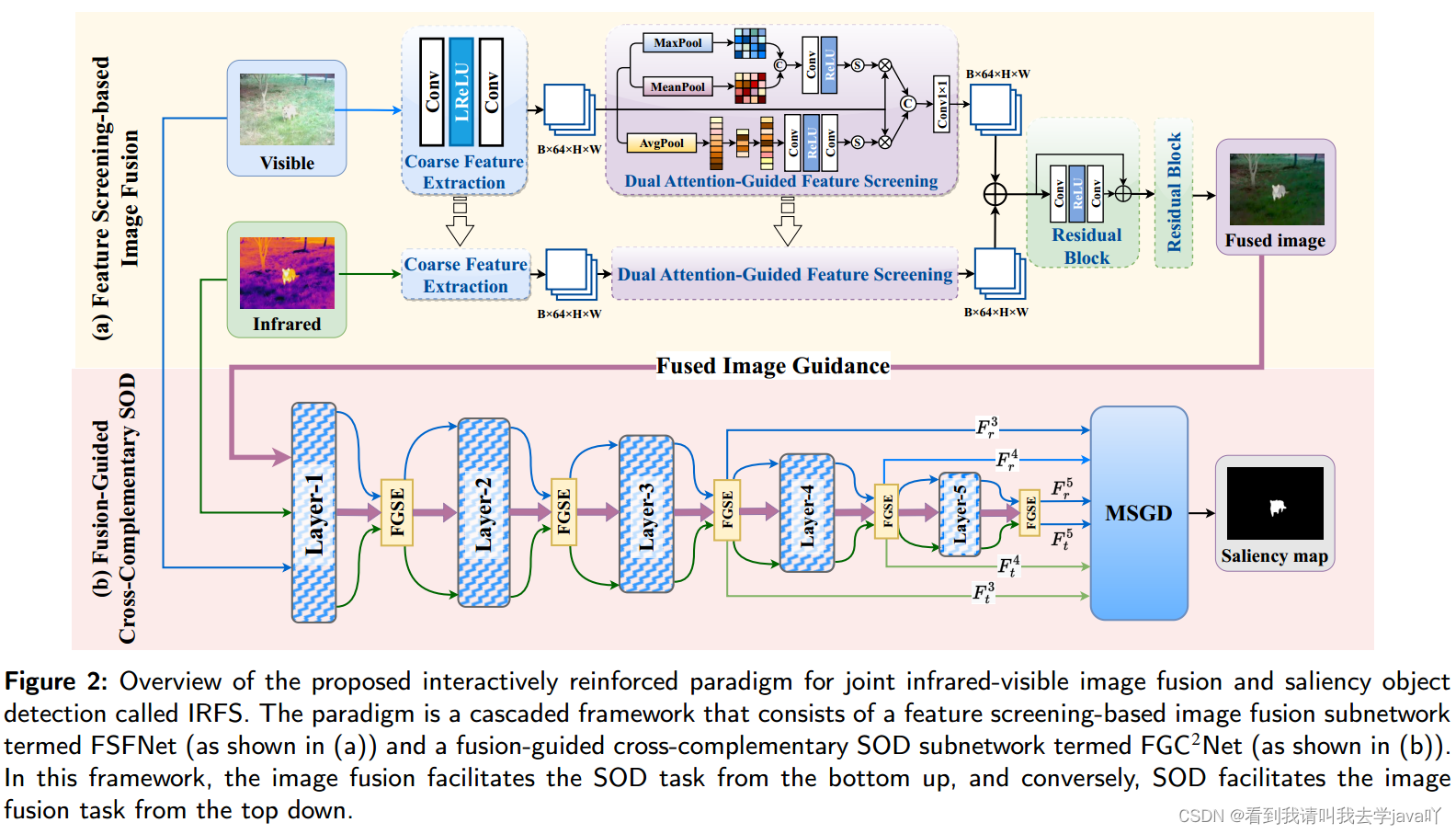
An Interactively Reinforced Paradigm for Joint Infrared-Visible Image Fusion and Saliency Object Detection
code
Abstacrt:通过实证分析,红外和可见光图像融合IVIF使难以发现的目标变得明显,而多模态显著目标检测能找到图像中目标的精确空间位置。本文首次通过交互式增强多任务范式IRFS探索IVIF和SOD的协作关系。本文开了一个基于特征筛选的融合子网络,即FSFNet,来筛选源图像中的干扰特征,从而保留与显著性相关的特征。通过FSFNet生成融合图像后,将其作为第三种模式输入到融合引导交叉互补自网络,即
F
C
2
N
e
t
FC^2Net
FC2Net,利用融合图像中获得的互补信息来驱动显著性图的精确预测。除此之外,本文还开发了一种交互式循环学习策略,以更短的训练周期和更少的网络参数实现IVIF和SOD任务的相互强化。
| ~Parting Line~ |
|---|
TCSVT
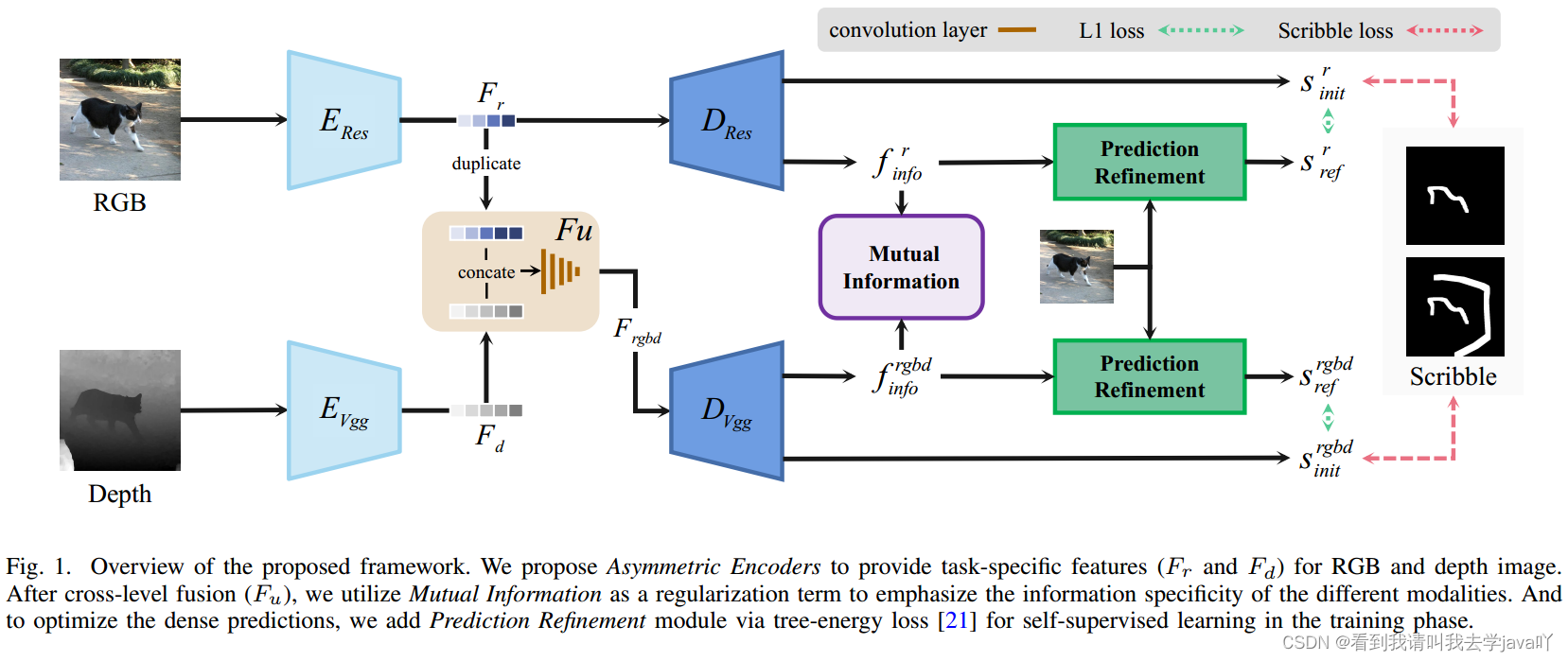
Mutual Information Regularization for Weakly-supervised RGB-D Salient Object Detection
code
Abstacrt:本文提出一个基于涂鸦监督的弱监督RGB-D显著性检测模型。作为一个多模态的学习任务,本文关注的是通过模态内互信息正则化进行有效的多模态表示学习。遵循解耦表示学习,本文引入带有互信息最小化正则器的互信息上界,以激发每个模态的解耦表示。基于多模态学习框架,本文引入了一个非对称特征提取器,其次还引入多模态变分自编码器作为随即预测的细化技术,该技术以第一训练阶段的伪标签作为监督,生成精细化预测。