1.为什么要选择基于“外观”这一特性来作为回环检测的方案?
朴素思路复杂度高,不利于实时性;基于“里程计”的方案需要知道相机处于何位置下才能发生检测,这与我们需要知道的准确位置相矛盾
基于“外观”的方案与前端和后端均无关,是一个独立的模块。
这也为其过程可以加入除去视觉、惯性第三者数据提供了条件。
2.为什么不能直接用两张图像“相减”来计算相似度?
1.相机运动过程中受光照影响很大,即使两张同位置的图像,在不同光照下,其矩阵也就是计算机能读懂的信息相差也很大
2.相机在高速拍摄的过程中,同一位置相机视角肯定有微小变动,这对于计算机视觉来说影响是巨大的
3.解释准确率/召回率的理解
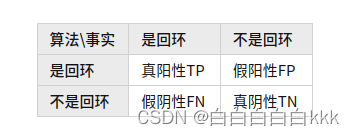
回环检测中更看重的是准确率,就是要将假阳性FP控制到最低!简而言之:漏判可以,错判不行
在算法中通过阈值来体现我们的“容忍度”。当提高某个阈值,算法会变的更加“严苛”,很多位置很难被判定为回环帧,于是准确率肯定会有所上升,同时由于检测到回环变少,难免会将现实中是回环的位置漏掉,因此召回率有所下降。反之,当降低了某个阈值,算法会更加“宽容”,其中将一些“模棱两可”的位置判断为回环帧,这样难免准确率会下降,但是召回率会上升。
通过上述可以看出,如果提供的数据比较多,Precision-Recall曲线是一个类似于反比例函数的模样
为了评价算法的好坏,我们会测试它在各种配置下的P和R值,然后做Precision-Recall曲线。当召回率为横轴,用准确率为纵轴时,我们会关心整条曲线偏向右上方的程度、100%准确率下召回率或者50%召回率时的准确率,作为评价的指标。
不过请注意,除了一些“天壤之别”的算法,通常不能一概而论地说算法A就是优于算法B的。我们可能会说A在准确率较高时还有很好的召回率,而B在70%召回率的情况下还能保证较好的准确率,诸如此类。
4.TF-IDF是什么?
词频-逆向文本概率,根据权重来区分单词的。前者是在图片中存在的数量,后者是在字典中存在的数量
词频(TF):某个单词在一张图片中出现的概率很高,是这张图片中的丰富元素,说明该单词区分度高
例如:一张图片中有100辆轿车,则含有50辆以下的图片很明显不是与之相似,80辆以上的图片存在更多相似的可能性
逆向文本概率(IDF):某个单词在一整本字典中出现次数很少,说明更“罕见、独特”。当这个单词在第一张图片和第十张图片中同时存在时,我们更可能觉得这两张图片更可能是相似的



![P1541 [NOIP2010 提高组] 乌龟棋(4维背包问题)](https://img-blog.csdnimg.cn/d9a4e663e5c4435c9aa9d606503f814c.png)







![[Linux] 4.常用初级指令](https://img-blog.csdnimg.cn/11dc8a0f42b04eb5ac3aae7ee1b0c4e8.png)