原文链接:https://arxiv.org/abs/2307.02270
1. 引言
目前的从单目相机生成伪传感器表达的方法依赖预训练的深度估计网络。这些方法需要深度标签来训练深度估计网络,且伪立体方法通过图像正向变形合成立体图像,会导致遮挡区域的像素伪影、扭曲、孔洞。此外,特征级别的伪立体图生成很难直接应用,且适应度有限。
那么如何绕过深度估计,在图像层面设计透视图生成器呢?和GAN相比,扩散模型有更简单的结构、更少的超参数和更简单的训练步骤,但目前没有关于3D目标检测伪视图生成的研究。
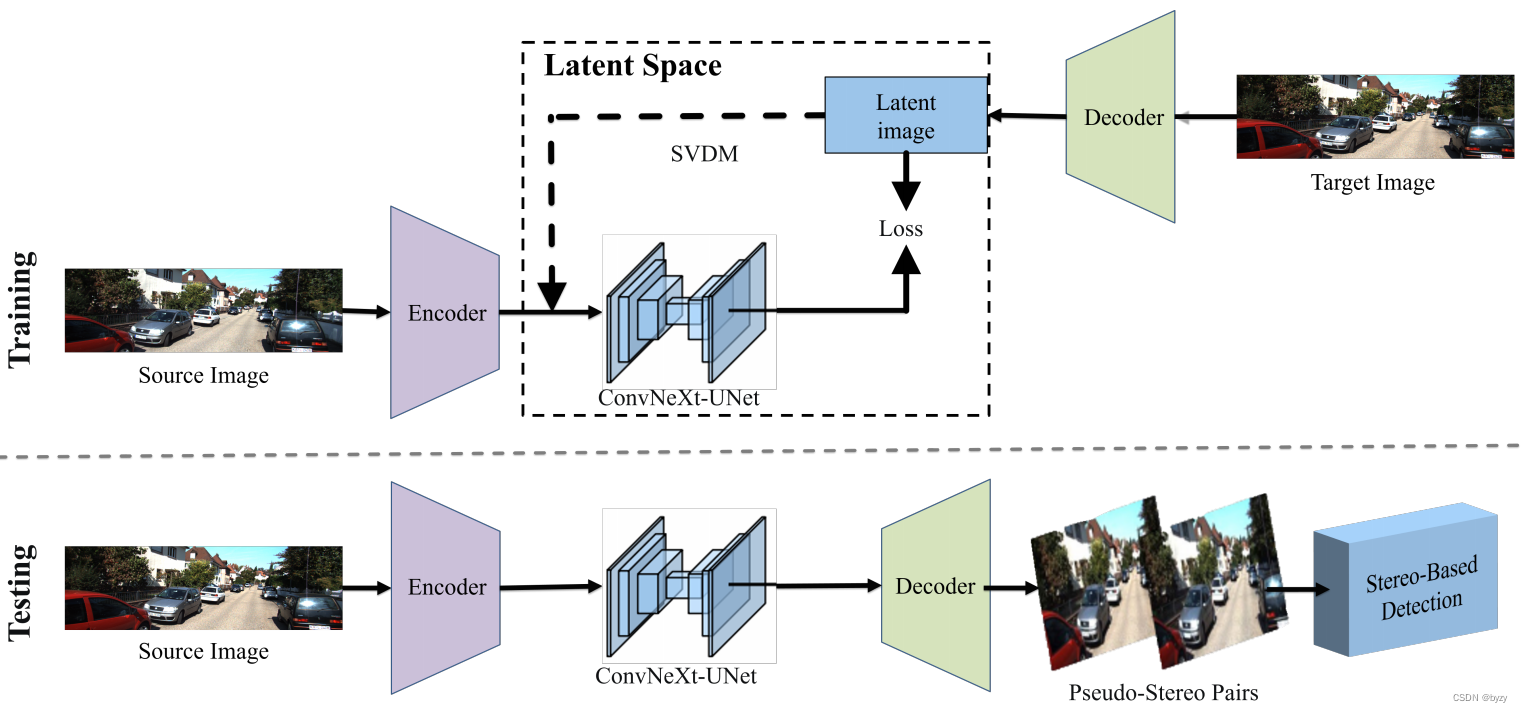
本文设计单一视图扩散模型(SVDM)进行伪视图合成。SVDM假设已知左视图图像,将高斯噪声替换为左图像素,并逐渐扩散右图像素到全图。由于立体图像细微的视差,仅使用很少的步骤就能产生不错的结果。SVDM不使用深度真值,且能端到端训练。
3. 方法
3.1 准备知识
3.1.a 立体3D检测器
可分为3类:只需要立体图像训练的模型(如Stereo R-CNN)、需要额外深度真值训练的模型(YOLOStereo3D)和基于体积网格的模型(如LIGA-Stereo)。
3.1.b 去噪扩散概率模型(DDPM)
详见扩散模型(Diffusion Model)简介。DDPM的目标是最优化置信下限(ELBO)。多数条件扩散模型保留了扩散过程,并将条件 y y y插入训练目标中: E t , x 0 , ϵ [ ∥ ϵ − ϵ θ ( x t , y , t ) ∥ 2 2 ] \mathbb{E}_{t,x_0,\epsilon}[\|\epsilon-\epsilon_\theta(x_t,y,t)\|_2^2] Et,x0,ϵ[∥ϵ−ϵθ(xt,y,t)∥22] 但由于 p ( x t ∣ y ) p(x_t|y) p(xt∣y)没有显式地出现在训练目标中,要保证扩散模型能学到期望的条件分布是很困难的。
3.2 单一视图扩散模型
本模型将新视图生成任务视为基于扩散模型的、图像到图像(I2I)的转换任务。本文的方法如下图所示,包含3种扩散模型方法:高斯噪声操作器、视图图像操作器和一步生成。
3.2.a 高斯噪声操作器
为了学习两个视图域之间的变换,根据BBDM,本文使用布朗桥扩散过程而非DDPM方法。
布朗桥过程是连续时间随机模型,其中扩散过程中的概率分布是以起始状态和终止状态为条件的。记起始状态为
x
0
∼
q
d
a
t
a
(
x
0
)
x_0\sim q_{data}(x_0)
x0∼qdata(x0),终止状态为
x
T
x_T
xT,则布朗桥扩散过程的状态分布为
q
B
B
(
x
t
∣
x
0
,
y
)
=
N
(
x
t
;
(
1
−
m
t
)
x
0
+
m
t
y
,
δ
t
I
)
q_{BB}(x_t|x_0,y)=\mathcal{N}(x_t;(1-m_t)x_0+m_ty,\delta_tI)
qBB(xt∣x0,y)=N(xt;(1−mt)x0+mty,δtI)其中
m
t
=
t
/
T
m_t=t/T
mt=t/T,
δ
t
\delta_t
δt为方差。为避免方差过大导致无法训练,使用下列方差调度:
δ
t
=
s
[
1
−
(
(
1
−
m
t
)
2
+
m
t
2
)
]
=
2
s
(
m
t
−
m
t
2
)
\delta_t=s[1-((1-m_t)^2+m_t^2)]=2s(m_t-m_t^2)
δt=s[1−((1−mt)2+mt2)]=2s(mt−mt2)其中
s
s
s控制样本的多样性,默认为1。
正向过程如下:当
t
=
0
t=0
t=0时,
m
t
=
0
m_t=0
mt=0,此时均值为
x
0
x_0
x0,方差为0;当
t
=
T
t=T
t=T时,
m
t
=
1
m_t=1
mt=1,此时均值为
y
y
y,方差为0。中间过程按下式计算:
x
t
=
(
1
−
m
t
)
x
0
+
m
t
y
+
δ
t
ϵ
x_t=(1-m_t)x_0+m_ty+\sqrt{\delta_t}\epsilon
xt=(1−mt)x0+mty+δtϵ其中
ϵ
∼
N
(
0
,
I
)
\epsilon\sim\mathcal{N}(0,I)
ϵ∼N(0,I)。用
t
−
1
t-1
t−1替换上式中的
t
t
t,两式相减得到转移概率:
q
B
B
(
x
t
∣
x
t
−
1
,
y
)
=
N
(
x
t
;
1
−
m
t
1
−
m
t
−
1
x
t
−
1
+
(
m
t
−
1
−
m
t
1
−
m
t
−
1
m
t
−
1
)
y
,
δ
t
∣
t
−
1
I
)
q_{BB}(x_t|x_{t-1},y)=\mathcal{N}(x_t;\frac{1-m_t}{1-m_{t-1}}x_{t-1}+(m_t-\frac{1-m_t}{1-m_{t-1}}m_{t-1})y,\delta_{t|t-1}I)
qBB(xt∣xt−1,y)=N(xt;1−mt−11−mtxt−1+(mt−1−mt−11−mtmt−1)y,δt∣t−1I)其中
δ
t
∣
t
−
1
=
δ
t
−
δ
t
−
1
(
1
−
m
t
)
2
(
1
−
m
t
−
1
)
2
\delta_{t|t-1}=\delta_t-\delta_{t-1}\frac{(1-m_t)^2}{(1-m_{t-1})^2}
δt∣t−1=δt−δt−1(1−mt−1)2(1−mt)2 逆过程从已知视图出发,逐步得到目标视图的分布。即基于
x
t
x_t
xt预测
x
t
−
1
x_{t-1}
xt−1:
p
θ
(
x
t
−
1
∣
x
t
,
y
)
=
N
(
x
t
−
1
;
μ
θ
(
x
t
,
t
)
,
δ
~
t
I
)
p_\theta(x_{t-1}|x_t,y)=\mathcal{N}(x_{t-1};\mu_\theta(x_t,t),\tilde{\delta}_tI)
pθ(xt−1∣xt,y)=N(xt−1;μθ(xt,t),δ~tI)其中
μ
θ
(
x
t
,
t
)
\mu_\theta(x_t,t)
μθ(xt,t)是预测噪声的均值,由神经网络基于极大似然准则估计。
δ
~
t
\tilde{\delta}_t
δ~t为每步噪声的方差,解析形式为
δ
~
t
=
δ
t
∣
t
−
1
δ
t
−
1
δ
t
\tilde{\delta}_t=\frac{\delta_{t|t-1}\delta_{t-1}}{\delta_t}
δ~t=δtδt∣t−1δt−1。
完整的训练和推断过程如下:
BBDM的训练算法
- 采样数据对 x 0 ∼ q ( x 0 ) , y ∼ q ( y ) x_0\sim q(x_0),y\sim q(y) x0∼q(x0),y∼q(y);
- 均匀采样时间 t ∈ { 1 , 2 , ⋯ , T } t\in\{1,2,\cdots,T\} t∈{1,2,⋯,T};
- 采样高斯噪声 ϵ ∼ N ( 0 , I ) \epsilon\sim\mathcal{N}(0,I) ϵ∼N(0,I);
- 正向扩散: x t = ( 1 − m t ) x 0 + m t y + δ t ϵ x_t=(1-m_t)x_0+m_ty+\sqrt{\delta_t}\epsilon xt=(1−mt)x0+mty+δtϵ;
- 计算 ∥ m t ( y − x 0 ) + δ t ϵ − ϵ θ ( x t , t ) ∥ 2 \|m_t(y-x_0)+\sqrt{\delta_t}\epsilon-\epsilon_\theta(x_t,t)\|^2 ∥mt(y−x0)+δtϵ−ϵθ(xt,t)∥2的梯度。
BBDM的采样算法:
- 采样条件输入 x T = y ∼ q ( y ) x_T=y\sim q(y) xT=y∼q(y);
- 从 t = T t=T t=T开始,进行下面的过程直到 t = 1 t=1 t=1:
采样 z ∼ N ( 0 , I ) z\sim\mathcal{N}(0,I) z∼N(0,I)
计算 x t − 1 = c x t x t + c y t y − c ϵ t ϵ θ ( x t , t ) + δ ~ t z x_{t-1}=c_{xt}x_t+c_{yt}y-c_{\epsilon t}\epsilon_\theta(x_t,t)+\sqrt{\tilde{\delta}_t}z xt−1=cxtxt+cyty−cϵtϵθ(xt,t)+δ~tz;- t = 1 t=1 t=1时,计算 x 0 = c x 1 x 1 + c y 1 y − c ϵ 1 ϵ θ ( x 1 , 1 ) x_0=c_{x1}x_1+c_{y1}y-c_{\epsilon1}\epsilon_\theta(x_1,1) x0=cx1x1+cy1y−cϵ1ϵθ(x1,1)。
3.2.b 视图图像操作器
布朗桥扩散模型引入了额外的超参数。本文提出基于视图图像操作器的方法,将目标图像视为特殊噪声,迭代地将目标图像转换为源图像。给定初始状态 x 0 x_0 x0和目标状态 y y y,中间状态 x t x_t xt可写为: x t = α t x 0 + 1 − α t y x_t=\sqrt{\alpha_t}x_0+\sqrt{1-\alpha_t}y xt=αtx0+1−αty与常规的添加噪声过程不同,此处添加的为逐步增加权重的新视图图像。采样过程如下所示:
- 输入源图像 x T x_T xT;
- 从 t = T t=T t=T开始,进行下面的过程直到 t = 0 t=0 t=0:
x 0 ≤ f ( x t , t ) x_0\leq f(x_t,t) x0≤f(xt,t)
x t − 1 = x s − D ( x 0 , t ) + D ( x 0 , t − 1 ) x_{t-1}=x_s-D(x_0,t)+D(x_0,t-1) xt−1=xs−D(x0,t)+D(x0,t−1)(关于该方法的采样算法,原文中用到的符号应该是有问题且欠缺解释的,这里仅能猜测原文的 s s s以及 i i i实际均应为 t t t)
α t \alpha_t αt的调度如下: α t = f ( t ) f ( 0 ) , f ( t ) = cos ( t / T + s 1 + s ⋅ π 2 ) 2 \alpha_t=\frac{f(t)}{f(0)},f(t)=\cos(\frac{t/T+s}{1+s}\cdot\frac{\pi}{2})^2 αt=f(0)f(t),f(t)=cos(1+st/T+s⋅2π)2与线性调度相比,余弦调度添加目标视图更慢。
3.2.c 加速采样和一步生成
由于扩散概率模型通常会需要大量步数采样,为加速推断过程,本文提出两种方法:一是添加高阶求解器引导DPM采样,二是引入一步生成方法。
加速采样:与DDIM的基本思想相似,BBDM也可以在使用非马尔科夫过程的同时,保持和马尔科夫推断过程有相同的边沿分布。
给定
{
1
,
2
,
⋯
,
T
}
\{1,2,\cdots,T\}
{1,2,⋯,T}的长为
S
S
S的子序列
{
T
1
,
T
2
,
⋯
,
T
S
}
\{T_1,T_2,\cdots,T_S\}
{T1,T2,⋯,TS},推断过程可由隐变量的子集
{
x
T
1
,
x
T
2
,
⋯
,
x
T
S
}
\{x_{T_1},x_{T_2},\cdots,x_{T_S}\}
{xT1,xT2,⋯,xTS}定义:
q
B
B
(
x
T
s
−
1
∣
x
T
s
,
x
0
,
y
)
=
N
(
(
1
−
m
T
s
−
1
)
x
0
+
m
T
s
−
1
+
δ
T
s
−
1
−
σ
T
s
2
δ
T
s
(
x
T
s
−
(
1
−
m
T
s
)
x
0
−
m
T
s
y
)
,
σ
T
s
2
I
)
q_{BB}(x_{T_{s-1}}|x_{T_s},x_0,y)=\mathcal{N}((1-m_{T_{s-1}})x_0+m_{T_{s-1}}+\frac{\sqrt{\delta_{T_{s-1}}-\sigma_{T_s}^2}}{\sqrt{\delta_{T_s}}}(x_{T_s}-(1-m_{T_s})x_0-m_{T_s}y),\sigma_{T_s}^2I)
qBB(xTs−1∣xTs,x0,y)=N((1−mTs−1)x0+mTs−1+δTsδTs−1−σTs2(xTs−(1−mTs)x0−mTsy),σTs2I)
一步生成:目标是不牺牲迭代细化优势的情况下进行一步生成。这些优势包括能平衡计算和质量,以及零样本数据编辑的能力。该方法建立在连续时间扩散模型概率流常微分方程(ODE)的基础上,其轨迹平滑地从数据分布转变为可处理的噪声分布。使用一个模型学习将任意步骤上的点映射到轨迹的起点,这样模型有自我一致性(即同一条轨迹上的点会被映射到相同的起点)。
一致性模型能在一次网络评估中将随机噪声向量(ODE轨迹的终点,
x
T
x_T
xT)转变为数据样本(ODE轨迹的起点,
x
0
x_0
x0)。通过多步连接一致性模型的输出,能用更多的计算提高样本质量并进行零样本数据编辑,从而保持迭代细化的优势。
3.3 网络结构
根据隐式扩散模型(LDM),SVDM在隐空间而非原始像素空间内进行生成学习以减小计算。
LDM使用预训练的VAE编码器
E
E
E将图像
v
∈
R
3
×
H
×
W
v\in\mathbb{R}^{3\times H\times W}
v∈R3×H×W编码为隐式嵌入
z
=
E
(
v
)
∈
R
c
×
h
×
w
z=E(v)\in\mathbb{R}^{c\times h\times w}
z=E(v)∈Rc×h×w。其前向过程逐渐向
z
z
z加入噪声,逆过程去噪以预测
z
z
z。最后,LDM使用预训练的VAE解码器
D
D
D解码
z
z
z,得到高分辨率图像
v
=
D
(
z
)
v=D(z)
v=D(z)。VAE的编码器和解码器在训练和推断时均保持固定,而由于
h
<
H
,
w
<
W
h<H,w<W
h<H,w<W,在低分辨率隐空间内扩散比在像素空间扩散更高效。本文的方法类似,给定从域
A
A
A中采样的图像
I
A
I_A
IA,首先提取隐特征
L
A
L_A
LA,然后进行SVDM过程,将
L
A
L_A
LA映射到相应的、域
B
B
B内的隐式表达
L
A
→
B
L_{A\rightarrow B}
LA→B。最后使用预训练的VQGAN的解码器生成图像
I
A
→
B
I_{A\rightarrow B}
IA→B。
SVDM模型沿通道维度连接两张图像,并使用标准的U-Net结构和Conv-NeXt残差块进行上下采样,以达到大感受野获取上下文信息。此外,还在不同分辨率下引入注意力块,因为全局交互能大幅提高重建质量。
3.4 损失函数
损失函数包含3项:RGB L1损失,RGB SSIM损失与感知损失。
3.4.a RGB L1损失与SSIM损失
L1损失与SSIM损失如下: L L 1 = 1 3 H W ∑ ∣ I ^ t g t − I t g t ∣ L s s i m = 1 − S S I M ( I ^ t g t , I t g t ) \mathcal{L}_{L1}=\frac{1}{3HW}\sum|\hat{I}_{tgt}-I_{tgt}|\\\mathcal{L}_{ssim}=1-SSIM(\hat{I}_{tgt},I_{tgt}) LL1=3HW1∑∣I^tgt−Itgt∣Lssim=1−SSIM(I^tgt,Itgt)其中 I ^ t g t \hat{I}_{tgt} I^tgt与 I t g t I_{tgt} Itgt分别为像素通道的预测值和真实值。
3.4.b 感知损失
基于过去的工作,感知损失通过强制局部真实性确保重建约束于图像流形,且避免了仅依赖RGB损失引入的模糊。 L l a t e n t = 1 2 ∑ j = 1 J [ ( u j 2 + σ j 2 ) − 1 − log σ j 2 ] \mathcal{L}_{latent}=\frac{1}{2}\sum_{j=1}^J[(u_j^2+\sigma_j^2)-1-\log\sigma_j^2] Llatent=21j=1∑J[(uj2+σj2)−1−logσj2]
4. 实验
4.4 基于单一图像的视图合成结果
定量结果:本文的方法在PSNR指标上能超过SotA,但SSIM和LPIPS指标略低于SotA。
定性结果:可视化表明,本文的方法能生成更真实的图像,有更小的扭曲和伪影。这表明本文的方法有能力建模复杂场景的几何和纹理。
4.5 3D目标检测结果
定量结果:实验表明,SVDM在使用BBDM的情况下,能超过大多数先进方法。使用视图扩散方法能进一步提升性能,这表明视图结构在3D目标检测上有更好的泛化能力。
此外,虽然不能完全超过SotA,SVDM在困难物体的检测上有更好的性能。简单物体性能较差的原因可能是有限的约束。背景和障碍物都不可避免地干扰了新视图生成。ConvNeXt-UNet结构能在一定程度上减轻此问题,但并不完美。
4.3 消融研究
行人和自行车的3D检测结果:由于样本数量少,行人和自行车的检测比汽车的检测更加困难。但本文的方法能在几乎所有难度上超过SotA。
5. 结论和未来展望
目前,SVDM的一个缺点是不能端到端训练。











![[NOIP2012 提高组] 开车旅行](https://img-blog.csdnimg.cn/img_convert/2408bbe8f583f9f4498a48180a20c617.png)