文章目录
- 环境
- 文件准备
- 项目代码
- 模型相关文件
- 运行
- 准备工作
- 运行demo
- Tips
环境
系统版本:Windows 10 企业版
版本号:20H2
系统类型:64 位操作系统, 基于 x64 的处理器
处理器:Intel® Core™ i7-13700K CPU @ 3.40GHz
机带 RAM:16.0 GB
显卡:NVIDIA RTX 4080(16G)
Python版本:3.10.11
文件准备
项目代码
Git地址:https://github.com/QwenLM/Qwen
创建好归档的文件夹,直接克隆即可:
git clone https://github.com/QwenLM/Qwen.git
模型相关文件
地址:https://huggingface.co/Qwen/Qwen-14B-Chat-Int4
注意:从huggingface.co上克隆,需要魔法、cmd命令行设置代理
魔法软件端口信息:
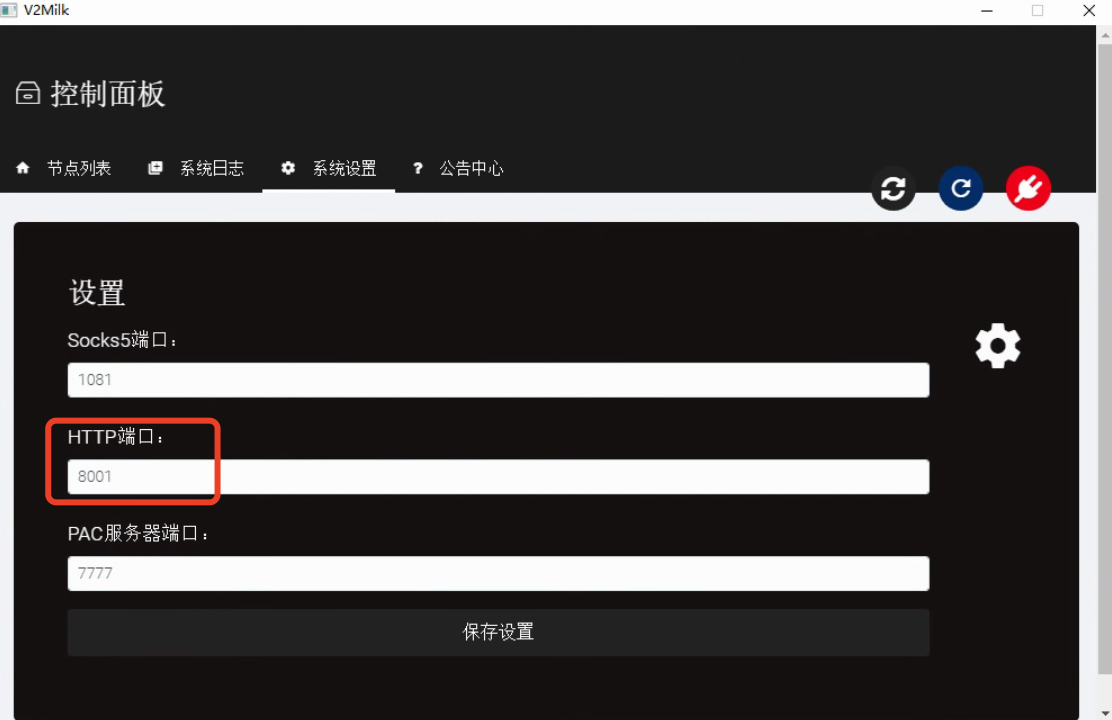
在cmd命令行执行:
set https_proxy=https://127.0.0.1:8001
完成上述配置后可以开始克隆了
模型文件比较大,需要使用git-lfs,下载git-lfs并安装:https://git-lfs.com,安装完配置好环境变量,
完成上述配置后,执行:
git lfs install
git clone https://huggingface.co/Qwen/Qwen-14B-Chat-Int4
运行
准备工作
安装所需的依赖,进入下载好的项目代码代码根目录,执行:
pip install -r requirements.txt
pip install auto-gptq optimum
所有文件下载完成后,修改web_demo.py中模型文件路径:

运行demo
尝试执行:python web_demo.py,看看是否会报错,如果报错,就根据提示改:
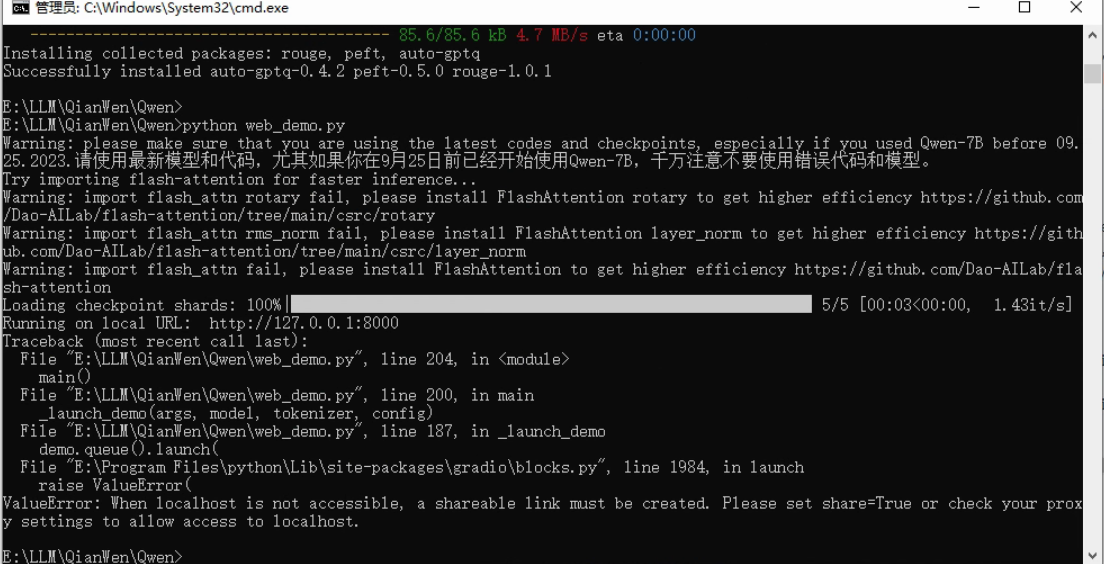
提示需要设置share=True,在web_demo.py中找到对应位置:

再运行试试:
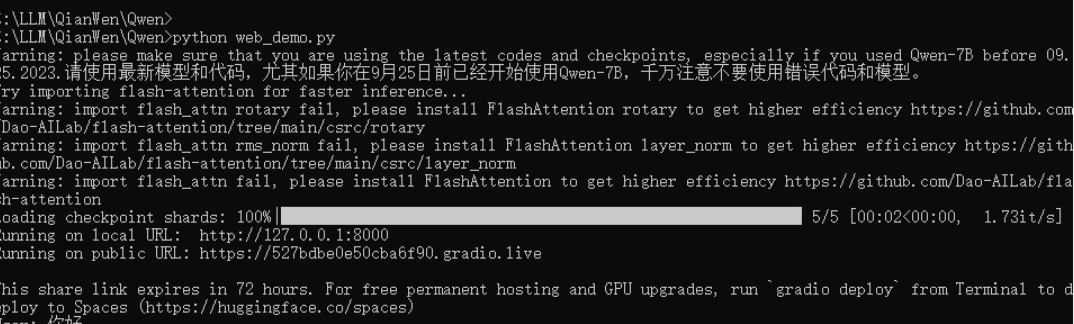
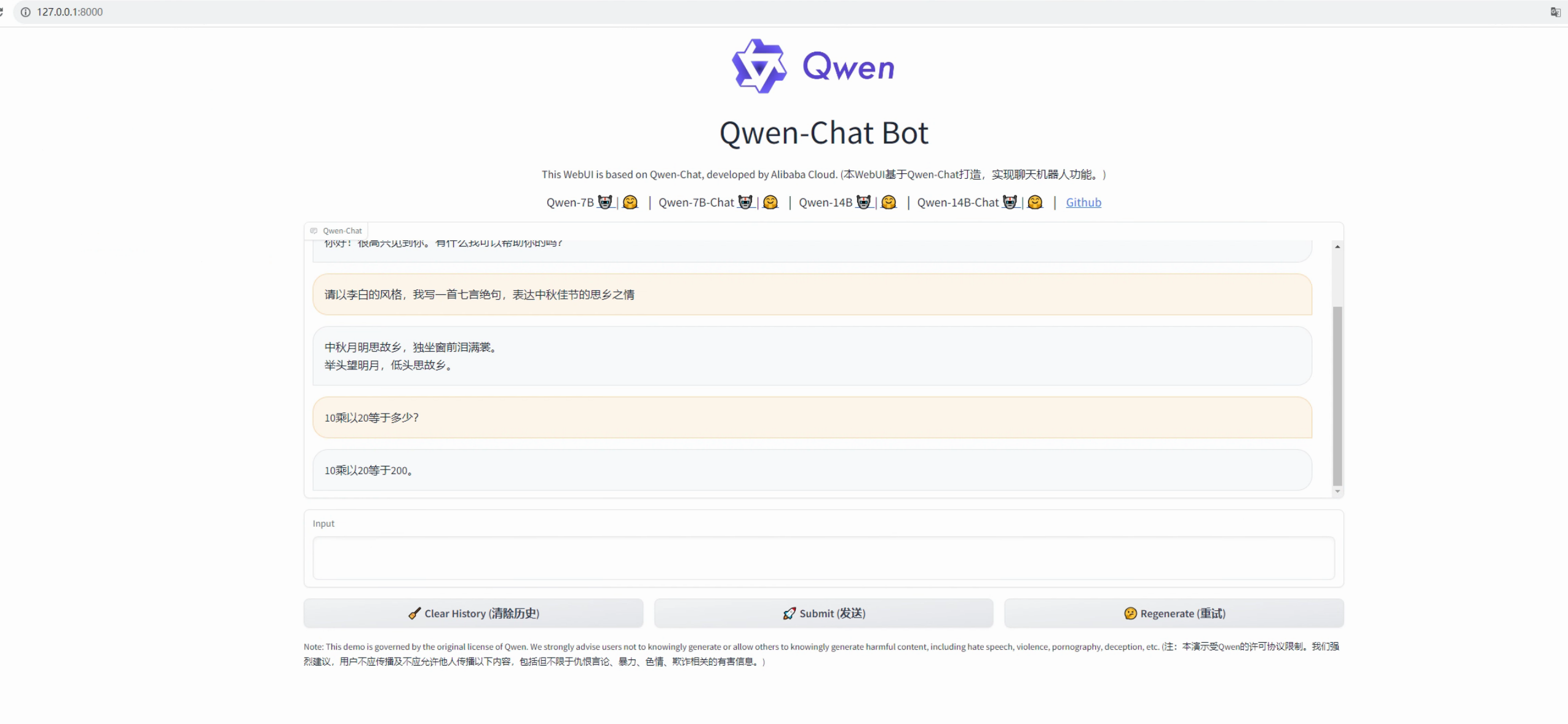
日志显示已启动成功,打开页面,可以正常进行问答,运行比较流畅:
Tips
从别的机器上访问,连接是拒绝的,查看日志,生成了一个临时的分享地址,可以提供给局域网内其他人使用
Running on local URL: http://127.0.0.1:8000
Running on public URL: https://527bdbe0e50cba6f90.gradio.live
This share link expires in 72 hours. For free permanent hosting and GPU upgrades, run `gradio deploy` from Terminal to deploy to Spaces (https://huggingface.co/spaces)