文章目录
- 1.层次聚类法原理简介
- 2.层次聚类法基础算法演示
- 2.1.Single-linkage的计算方法演示
- 2.2.Complete-linkage的计算方法演示
- 2.3.Group-average的计算方法演示
- 3.层次聚类法拓展算法介绍
- 3.1.质心法原理介绍
- 3.2.基于中点的质心法
- 3.3.Ward方法
- 4.层次聚类法应用实战
- 4.1.层次聚类法聚类应用
- 4.2.层次聚类法聚类树绘制
- 4.2.1.Single-linkage连接方法
- 4.2.2.Complete-linkage连接方法
- 4.2.3.Group-average连接方法
- 4.2.4.Centroid连接方法
- 4.2.5.Ward连接方法
- 5.致谢
1.层次聚类法原理简介
#聚合聚类(层次聚类方法)
"""
1.层次聚类顾名思义就是按照某个层次对样本集进行聚类操作,这里层次并非是真实的层次,实际上指的就是某种距离定义,(我们其实已经学过了很多的距离定义了)
2.层次聚类方法的目标就是采用自下而上的方法去去消除类别的数量,类似与树状图的由叶子结点向根结点靠拢的过程。
3.更简单的说,层次聚类是将初始化的多个类簇看做树节点,每一次迭代都会两两距离相近的类簇进行合并,如此反复,直至最终只剩一个类簇(也就是根结点)。
"""
2.层次聚类法基础算法演示
层次聚类法的三种不同方法:
依据对相似度(距离)的不同定义,将层次聚类法的聚类方法分为三种:
1.Single-linkage:要比较的距离为元素对之间的最小距离。
2.Complete-linkage:要比较的距离为元素对之间的最大距离。
3.Group average:要比较的距离为类之间的平均距离。
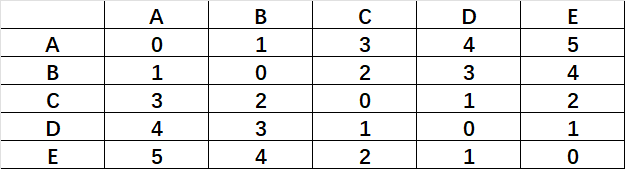
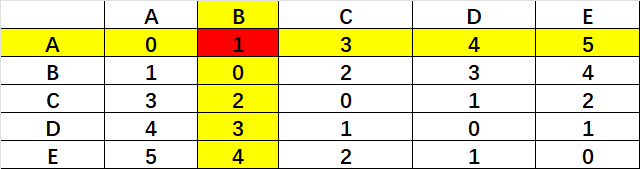
我们首先拿出几个数据进行计算演示一番这最基础的算法,如图所示,这是ABCDE五个点的相互之间的距离:
2.1.Single-linkage的计算方法演示
Single-linkage:要比较的距离为元素对之间的最小距离。所以我们需要找到每个点对应的最小距离。
第一步:A的最小距离是B,所以AB先合并,记作{AB}。
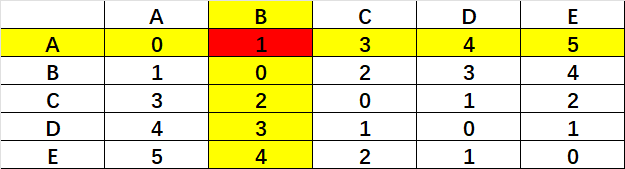
第二步:以AB为整体进行对C合并的研究。
最后发现CD最短,合并记作{CD}。
第三步:以{AB}/{CD}为整体进行对E合并的研究。
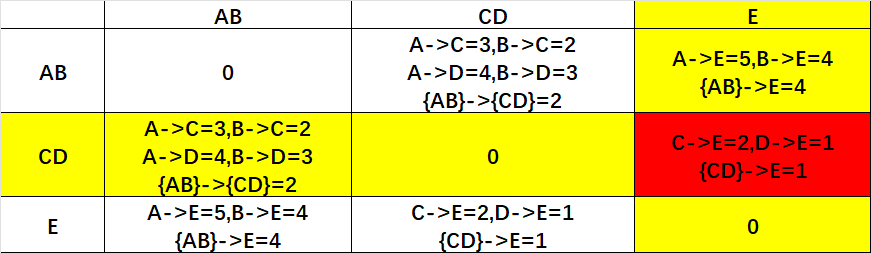
最后发现CD->E最短,合并记作{CDE}。
第四步:合并最后的两个簇即可,即{AB}{CDE}合并。
2.2.Complete-linkage的计算方法演示
2.Complete-linkage:要比较的距离为元素对之间的最大距离。所以我们需要找到每个点对应的最大距离。
第一步:A与各个元素之间的最大距离的最小距离是B,所以AB先合并,记作{AB}。
第二步:
C与各元素的最大距离的最小值如下所示:

所以C的各元素的最大距离的最小值是D,合并CD并且记作{CD}。
第三步:以{AB}/{CD}为整体进行对E合并的研究。
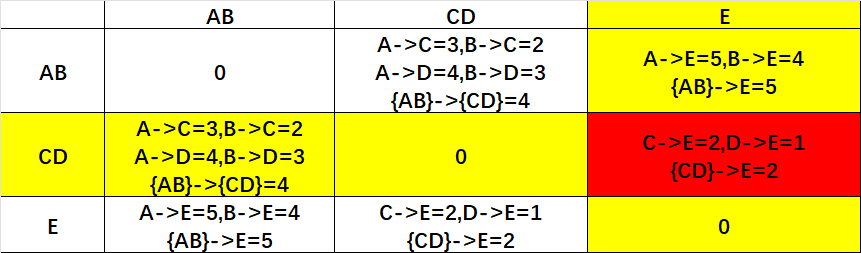
最后发现CD->E最短,合并记作{CDE}。
第四步:合并最后的两个簇即可,即{AB}{CDE}合并。
2.3.Group-average的计算方法演示
Group-average要比较的距离为元素对之间的最平均距离。所以我们需要找到每个点对应的最平均距离。
第一步:A与各个元素之间的最大距离的最小距离是B,所以AB先合并,记作{AB}。
第二步:
C与各元素的平均距离的最小值如下所示:

所以C的各元素的最平均距离的最小值是D,合并CD并且记作{CD}。
第三步:以{AB}/{CD}为整体进行对E合并的研究。

最后发现CD->E的平均距离最短,合并记作{CDE}。
第四步:合并最后的两个簇即可,即{AB}{CDE}合并。
3.层次聚类法拓展算法介绍
来源:https://blog.csdn.net/huangguohui_123/article/details/106995538
3.1.质心法原理介绍

如果两个族群合并之后,下一步合并时的最小距离反而减小(质心在不断变化),我们则称这种情况为倒置(Reversal/Inversion),在系统树图中表现为交叉(Crossover)现象。
在一些层次聚类方法中,如简单连接、完全连接和平均连接,倒置不可能发生,这些距离的度量是单调的(monotonic)。显然质心方法并不是单调的。
3.2.基于中点的质心法

3.3.Ward方法

4.层次聚类法应用实战
4.1.层次聚类法聚类应用
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.cluster import AgglomerativeClustering
from scipy.cluster.hierarchy import dendrogram, linkage
#%%
# 读取数据
data = pd.read_excel('Clustering_5.xlsx')
# 提取特征和标签
X = data.iloc[:, :2].values
y = data['y'].values
# 创建凝聚聚类模型
n_clusters = 5
agg_clustering = AgglomerativeClustering(n_clusters=n_clusters)
# 进行聚类
labels = agg_clustering.fit_predict(X)
#%%
# 绘制聚类结果
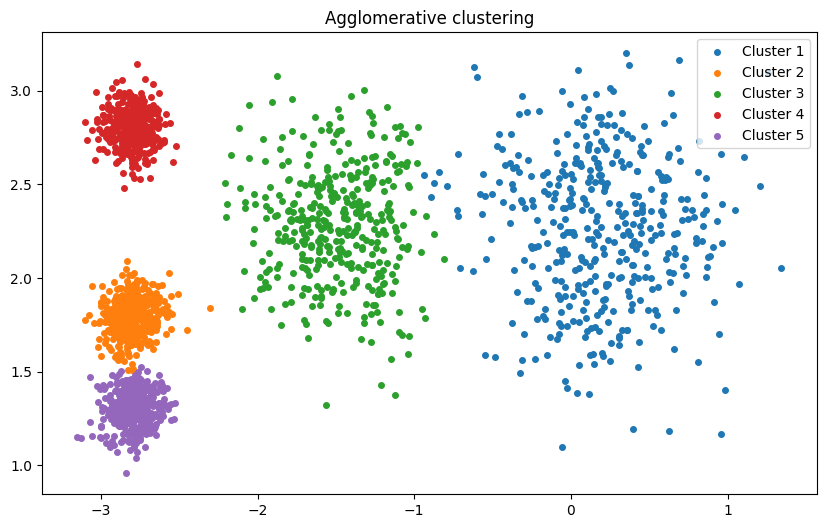
plt.figure(figsize=(10, 6))
for i in range(n_clusters):
cluster_points = X[labels == i]
plt.scatter(cluster_points[:, 0],
cluster_points[:, 1], label=f'Cluster {i + 1}',s=16)
plt.title('Agglomerative clustering')
plt.legend()
plt.show()
聚类效果比较不错
4.2.层次聚类法聚类树绘制
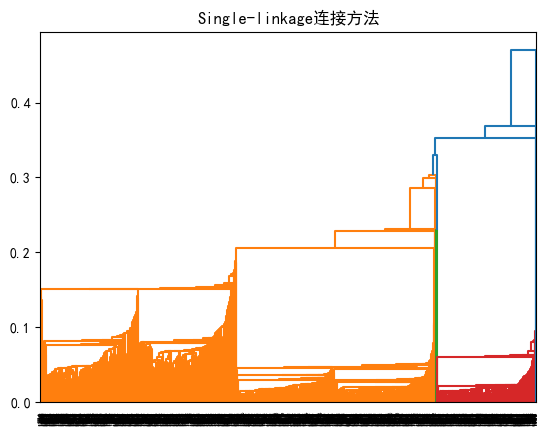
4.2.1.Single-linkage连接方法
#%%
linked = linkage(X, 'single') # 使用ward方法计算链接
dendrogram(linked, orientation='top',
distance_sort='descending', show_leaf_counts=True)
plt.title('Single-linkage连接方法')
plt.show()
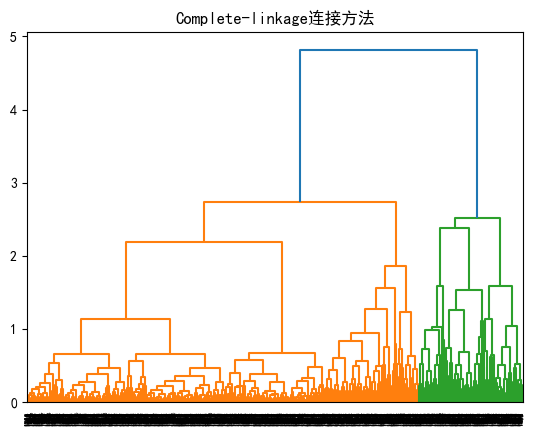
4.2.2.Complete-linkage连接方法
#%%
linked = linkage(X, 'complete') # 使用ward方法计算链接
dendrogram(linked, orientation='top',
distance_sort='descending', show_leaf_counts=True)
plt.title('Complete-linkage连接方法')
plt.show()
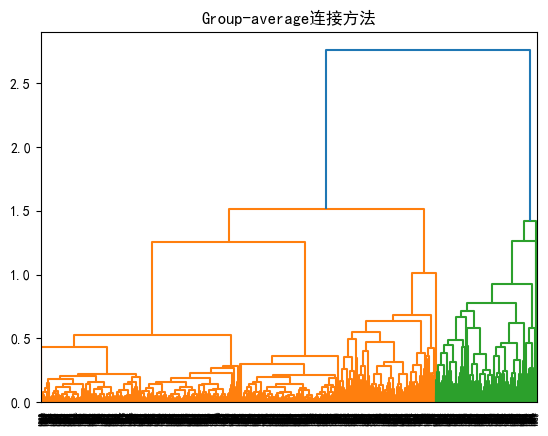
4.2.3.Group-average连接方法
#%%
linked = linkage(X, 'average') # 使用ward方法计算链接
dendrogram(linked, orientation='top',
distance_sort='descending', show_leaf_counts=True)
plt.title('Group-average连接方法')
plt.show()
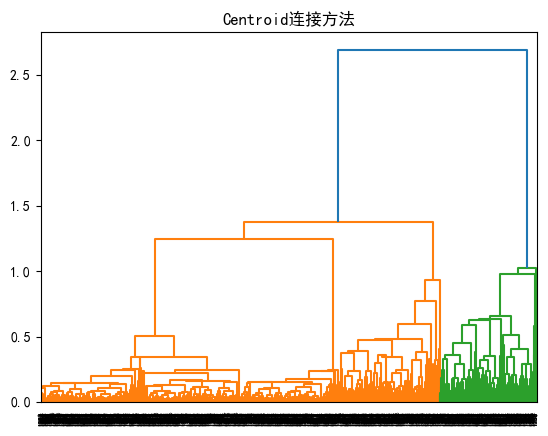
4.2.4.Centroid连接方法
#%%
linked = linkage(X, 'centroid') # 使用ward方法计算链接
dendrogram(linked, orientation='top',
distance_sort='descending', show_leaf_counts=True)
plt.title('Centroid连接方法')
plt.show()
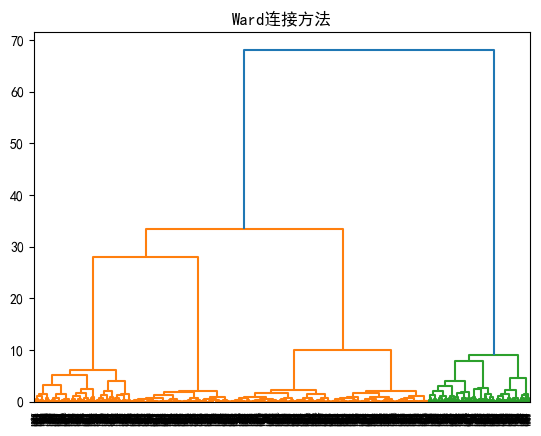
4.2.5.Ward连接方法
# 绘制树状图(聚类树)
linked = linkage(X, 'ward') # 使用ward方法计算链接
dendrogram(linked, orientation='top',
distance_sort='descending', show_leaf_counts=True)
plt.title('Ward连接方法')
plt.show()
5.致谢
本章内容的完成离不开以下大佬文章的启发和帮助,在这里列出名单,如果对于内容还有不懂的,可以移步对应的文章进行进一步的理解分析。
1.层次聚类法的基础算法演示https://blog.csdn.net/qq_40206371/article/details/123057888
2.层次聚类法的进阶算法演示https://blog.csdn.net/huangguohui_123/article/details/106995538
在文章的最后再次表达由衷的感谢!!